








是什么
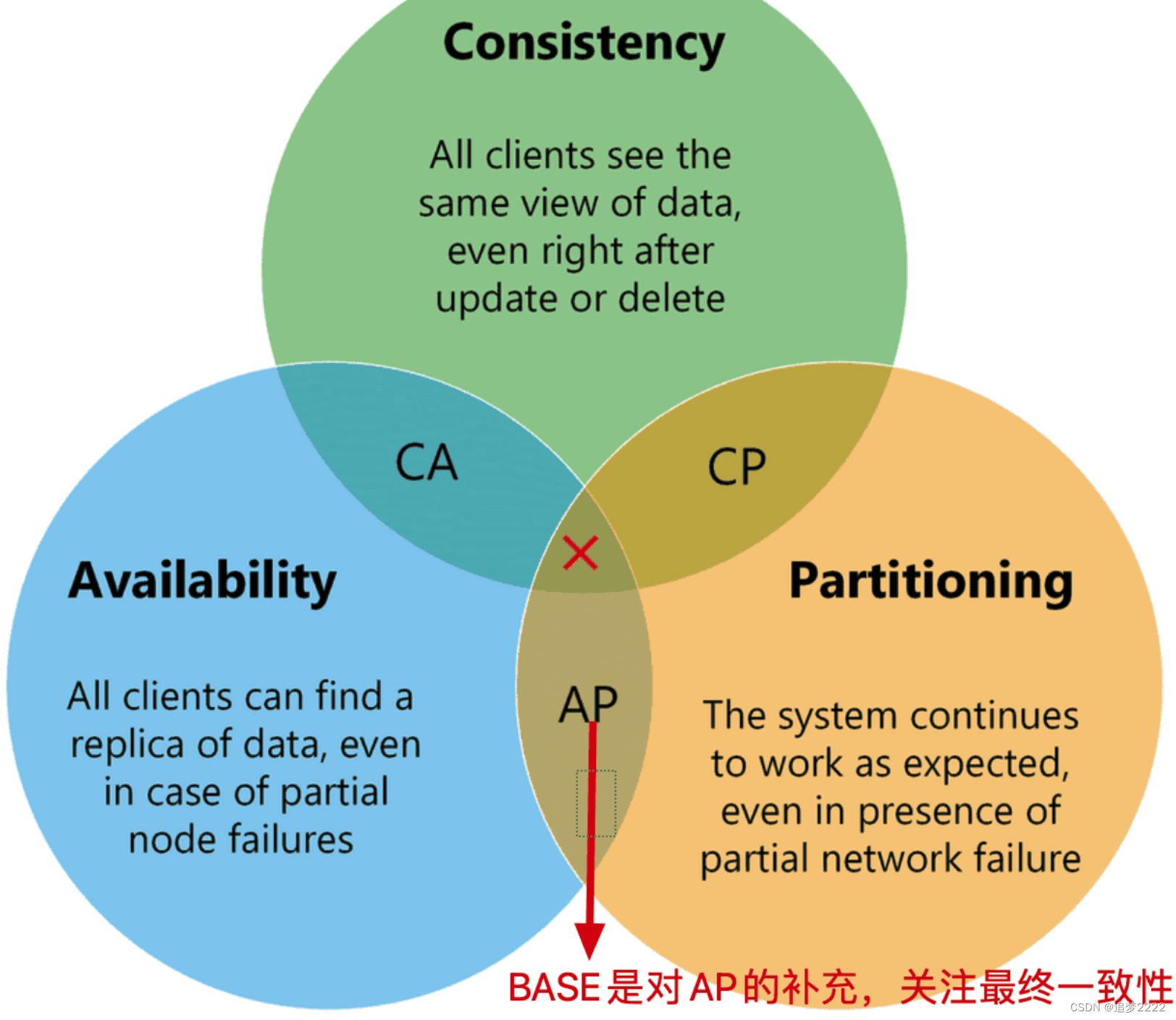
- BASE 理论是对 CAP 理论的进一步扩展
- 主要强调在分布式系统中,
为了获得更高的可用性和性能,可以放宽对一致性的要求,是对 CAP 中 AP 方案的一个补充。 BA(Basically Available):基本可用,系统在面对分区故障时,允许牺牲部分可用性(比如响应时间延长点,系统的非核心功能暂不可用),并不是不可用。S(Soft State):软状态,允许系统中存在一种软状态(短时间内的数据不一致状态,如果是实时一致则为硬状态)E(Eventual consistency):最终一致性,虽然系统中存在数据不一致的状态,但是经过固定的时间间隔后,必须数据一致。也就是最终必须是一致的。
BASE 与 CAP,ACID 的区别
- ACID 是事物的基本特性,属于单体系统的范畴,同时由于是本地事务,可以归属于强一致性模型
- CAP 和 BASE 都是分布式系统的基本理论,BASE 又是 CAP 的进一步发展
- CAP 中的一致性也可归属到强一致性模型,BASE 可以归属到弱一致性模型,BASE理论面向的是大型高可用、可扩展的分布式系统。
BASE 和 Paxos 类共识算法的区别
- 一个是描述数据一致性的模型,一个是描述共识的模型
数据一致性的目标是确保系统中的数据副本具有一致的状态,即任何时候任何节点的数据都是一致的。
共识的目标是在面对部分节点故障或网络分区的情况下,使得系统能够就某个值或顺序达成一致,以保证系统的正确性和可用性。
相关问题
- 数据一致性和共识的区别
- 强一致性和弱一致性
- 共识算法















 1223
1223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









