







问题
- 样本读取线程数是什么?
- block问题
- .pkl文件
- ptn
关于PyCharm环境的配置
创建pytorch Anaconda虚拟环境
- 打开Anaconda prompt,输入命令:
conda create -n pytorch python=3.8,输入y,对pytorch进行安装。
启动pytorch Anaconda虚拟环境
- 打开Anaconda prompt,输入命令:
activate pytorch,但是会出现错误:‘chcp’ 不是内部或外部命令,也不是可运行的程序或批处理文件。 - 在系统变量的path中,追加*;C:\Windows\System32*即可解决上面那个问题‘chcp’ 不是内部或外部命令解决方法
安装pytorch环境
pytorch官网:https://pytorch.org/

PyTorch安装慢的解决方法
- 查看是否配置镜像:
conda config --show(其他参数详见官网https://conda.io/projects/conda/en/latest/commands/config.html),channels中使用的是默认下载路径,没有配置镜像
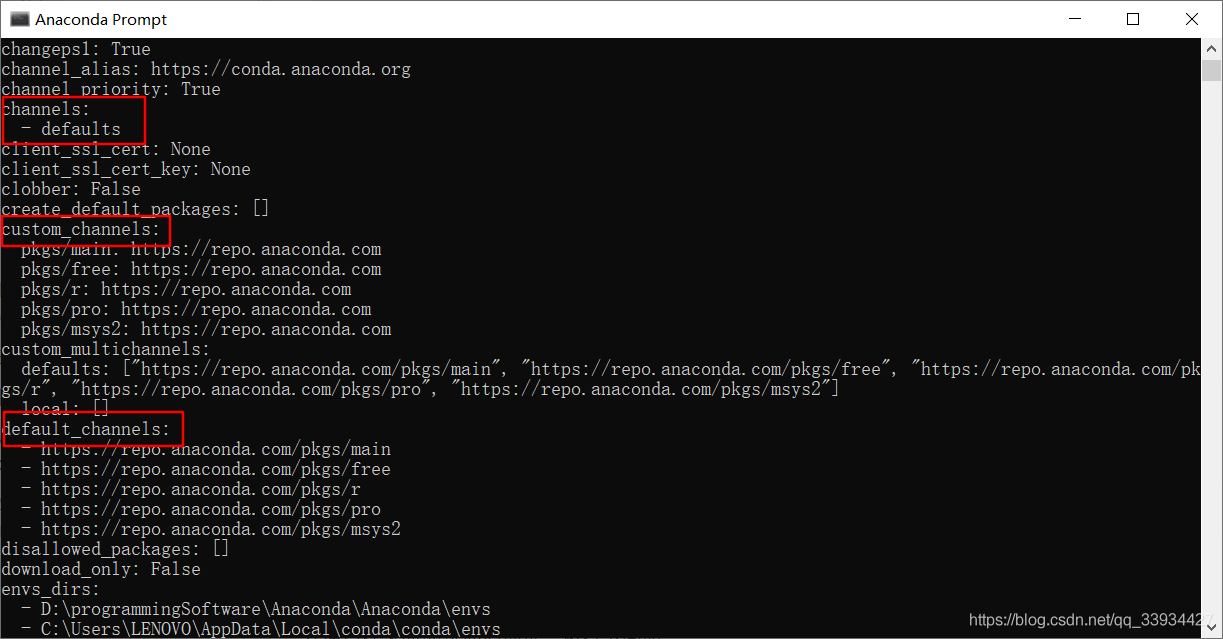
- 配置镜像:输入
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ - 修改安装pytorch命令:如果你的安装命令是:
conda install pytorch torchvision cudatoolkit=10.1 -c pytorch,将其修改成conda install pytorch torchvision cudatoolkit=10.1,因为conda install -c channel,如果是-c pytorch,则是使用pytorch官网,而非镜像来下载。
pip --default-timeout=1000 install --index-url https://mirrors.aliyun.com/pypi/simpleinstall torch==1.7.0+cpu torchvision==0.8.1+cpu torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
opencv-python安装慢的解决方法
pip install opencv-python -ihttps://pypi.tuna.tsinghua.edu.cn/simple
将Anconda新建的环境添加到pycharm中
conda list可以查看装了什么库,同时可以看到新建环境安装位置。
File --> Settings --> 搜索Project Interpreter
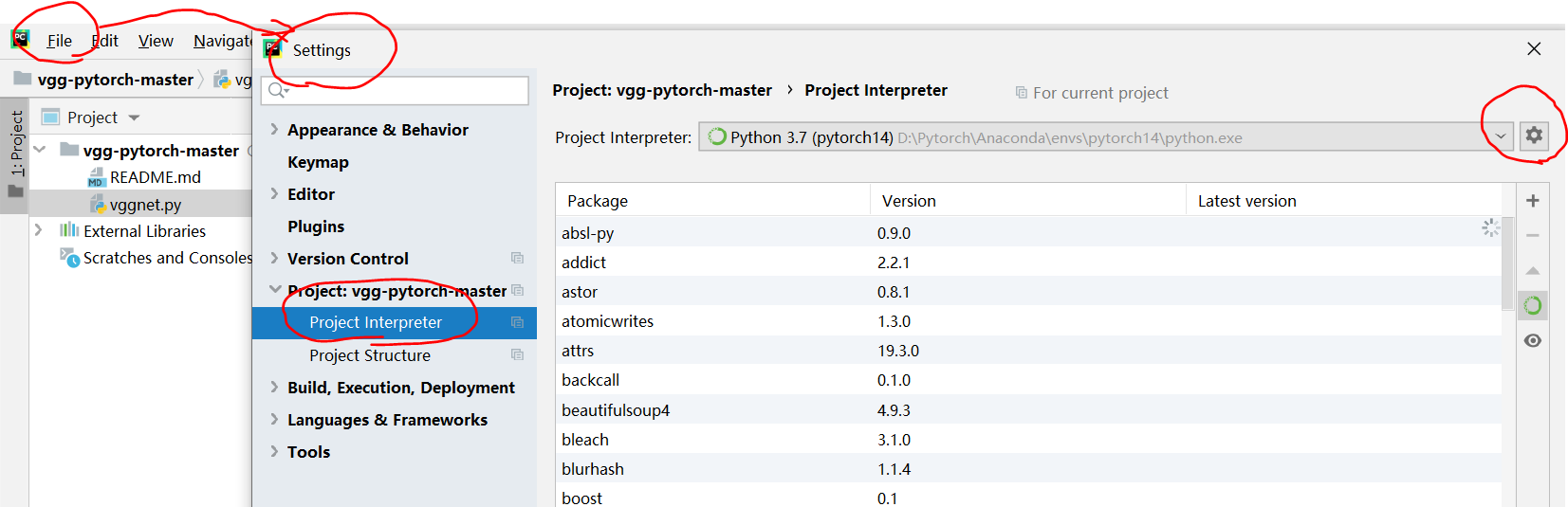
进入添加Interpreter的对话框,选择左侧的Virtualenv Environment
再选择右侧的Existing environment
新建环境的目录,在你安装Anaconda目录下的envs文件夹下(本人Anaconda安装在E盘,故路径如下图所示)
然后点击OK按钮
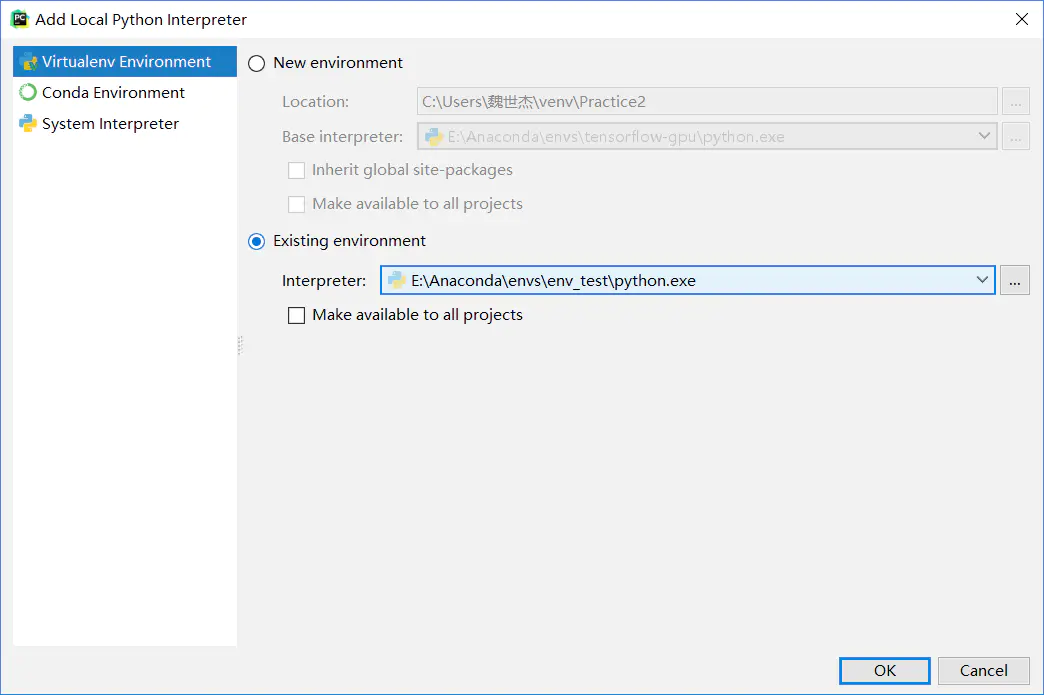
再点击如下图所示的Apply按钮和OK按钮
Tensorboard
……
CIFAR-10数据集
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。
数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。训练批次以随机顺序包含剩余图像,但一些训练批次可能包含来自一个类别的图像比另一个更多。总体来说,五个训练集之和包含来自每个类的正好5000张图像。
以下是数据集中的类,以及来自每个类的10个随机图像:

python:
for in zip遍历
list_1 = [1, 2, 3, 4]
list_2 = ['a', 'b', 'c']
for x, y in zip(list_1, list_2):
print(x, y)
os.path.join()路径拼接
连接两个或更多的路径名组件
print("1:",os.path.join('aaaa','/bbbb','ccccc.txt'))
#以字符串中含有 / 的第一个开始拼接:
1: /bbbb/ccccc.txt
os.listdir()
返回指定路径下的文件和文件夹列表。
关于with
with是python中上下文管理器,简单理解,当要进行固定的进入,返回操作时,可以将对应需要的操作,放在with所需要的语句中。比如文件的写入(需要打开关闭文件)等。
关于with torch.no_grad():
在使用pytorch时,并不是所有的操作都需要进行计算图的生成(计算过程的构建,以便梯度反向传播等操作)。而对于tensor的计算操作,默认是要进行计算图的构建的,在这种情况下,可以使用with torch.no_grad():,强制之后的内容不进行计算图构建。
以下分别为使用和不使用的情况:
(1)使用with torch.no_grad():
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
print(outputs)
运行结果:
Accuracy of the network on the 10000 test images: 55 %
tensor([[-2.9141, -3.8210, 2.1426, 3.0883, 2.6363, 2.6878, 2.8766, 0.3396,
-4.7505, -3.8502],
[-1.4012, -4.5747, 1.8557, 3.8178, 1.1430, 3.9522, -0.4563, 1.2740,
-3.7763, -3.3633],
[ 1.3090, 0.1812, 0.4852, 0.1315, 0.5297, -0.3215, -2.0045, 1.0426,
-3.2699, -0.5084],
[-0.5357, -1.9851, -0.2835, -0.3110, 2.6453, 0.7452, -1.4148, 5.6919,
-6.3235, -1.6220]])
此时的outputs没有 属性。
(2)不使用with torch.no_grad():
而对应的不使用的情况
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
print(outputs)
结果如下:
Accuracy of the network on the 10000 test images: 55 %
tensor([[-2.9141, -3.8210, 2.1426, 3.0883, 2.6363, 2.6878, 2.8766, 0.3396,
-4.7505, -3.8502],
[-1.4012, -4.5747, 1.8557, 3.8178, 1.1430, 3.9522, -0.4563, 1.2740,
-3.7763, -3.3633],
[ 1.3090, 0.1812, 0.4852, 0.1315, 0.5297, -0.3215, -2.0045, 1.0426,
-3.2699, -0.5084],
[-0.5357, -1.9851, -0.2835, -0.3110, 2.6453, 0.7452, -1.4148, 5.6919,
-6.3235, -1.6220]], grad_fn=<AddmmBackward>)
可以看到,此时有grad_fn=<AddmmBackward>属性,表示,计算的结果在一计算图当中,可以进行梯度反传等操作。但是,两者计算的结果实际上是没有区别的
切片
import numpy as np
a=np.random.rand(5)
print(a)
[ 0.64061262 0.8451399 0.965673 0.89256687 0.48518743]
print(a[-1]) ###取最后一个元素
[0.48518743]
print(a[:-1]) ### 除了最后一个取全部
[ 0.64061262 0.8451399 0.965673 0.89256687]
print(a[::-1]) ### 取从后向前(相反)的元素
[ 0.48518743 0.89256687 0.965673 0.8451399 0.64061262]
print(a[2::-1]) ### 取从下标为2的元素翻转读取
[ 0.965673 0.8451399 0.64061262]
文件处理
“r” 以读方式打开,只能读文件 , 如果文件不存在,会发生异常
“w” 以写方式打开,只能写文件, 如果文件不存在,创建该文件;如果文件已存在,先清空,再打开文件
“rb” 以二进制读方式打开,只能读文件 , 如果文件不存在,会发生异常
“wb” 以二进制写方式打开,只能写文件, 如果文件不存在,创建该文件;如果文件已存在,先清空,再打开文件
列表推导法

>>>[ x for x in range(1,8) if x%2 == 0 ] # 'for' and 'if' sentence used together
[2 4 6]
isinstance(object, classinfo)
描述
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
参数
- object – 实例对象。
- classinfo – 可以是直接或间接类名、基本类型或者由它们组成的元组。
返回值
如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False。
pop()
pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
语法:list.pop(obj=list[-1]) //默认为 index=-1,删除最后一个列表值。
obj – 可选参数,要移除列表元素的对象。
list.pop(0)删除第一个元素。所有剩余的元素都必须上移一级
init, call
init: 当一个类实例被创建时, init() 方法会自动执行,在类实例创建完毕后执行,类似构建函数。init() 可以被当成构建函数,不过不象其它语言中的构建函数,它并不创建实例–它仅仅是你的对象创建后执行的第一个方法。它的目的是执行一些该对象的必要的初始化工作。通过创建自己的 init() 方法,你可以覆盖默认的 init()方法(默认的方法什么也不做),从而能够修饰刚刚创建的对象__init__()需要一个默认的参数self,相当于this。
call: Python中有一个有趣的语法,只要定义类型的时候,实现__call__函数,这个类型就成为可调用的。换句话说,我们可以把这个类的对象当作函数来使用,相当于重载了括号运算符。为了弄明白python中__setattr__, getattr, delattr, __call__的作用,重写dict,扩展其功能。
PyTorch
深度学习方面
Stride
stride,实质上就是filter在原图上扫描时,需要跳跃的格数,默认跳一格;
stride,通过跳格,减少filter与原图做的扫描时的重复计算,提升效率;
stride,太小,重复计算较多,计算量大,训练效率降低;
stride,太大,会造成信息遗漏,无法有效提炼数据背后的特征;
残差
观测值与拟合值的偏离.
BN层(Batchnorm)
BN层的三个作用:

- 加快网络的训练和收敛的速度
- 控制梯度爆炸防止梯度消失
- 防止过拟合
分析:
(1)加快收敛速度:在深度神经网络中中,如果每层的数据分布都不一样的话,将会导致网络非常难收敛和训练,而如果把 每层的数据都在转换在均值为零,方差为1 的状态下,这样每层数据的分布都是一样的训练会比较容易收敛。
(2)防止梯度爆炸和梯度消失:
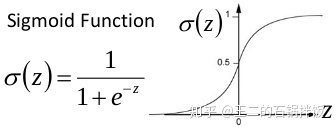
以sigmoid函数为例,sigmoid函数使得输出在[0,1]之间,实际上当x道了一定的大小,经过sigmoid函数后输出范围就会变得很小
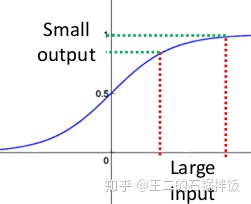
梯度消失:在深度神经网络中,如果网络的激活输出很大,其对应的梯度就会很小,导致网络的学习速率就会很慢,假设网络中每层的学习梯度都小于最大值0.25,网络中有n层,因为链式求导的原因,第一层的梯度将会小于0.25的n次方,所以学习速率相对来说会变的很慢,而对于网络的最后一层只需要对自身求导一次,梯度就大,学习速率就会比较快,这就会造成在一个很深的网络中,浅层基本不学习,权值变化小,而后面几层网络一直学习,后面的网络基本可以表征整个网络,这样失去了深度的意义。(使用BN层归一化后,网络的输出就不会很大,梯度就不会很小)
梯度爆炸:第一层偏移量的梯度=激活层斜率1x权值1x激活层斜率2x…激活层斜率(n-1)x权值(n-1)x激活层斜率n,假如激活层斜率均为最大值0.25,所有层的权值为100,这样梯度就会指数增加。(使用bn层后权值的更新也不会很大)
BN算法防止过拟合:在网络的训练中,BN的使用使得一个minibatch中所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果,即同样一个样本的输出不再仅仅取决于样本的本身,也取决于跟这个样本同属一个batch的其他样本,而每次网络都是随机取batch,这样就会使得整个网络不会朝这一个方向使劲学习。一定程度上避免了过拟合。
Q: 为什么BN层一般用在线性层和卷积层后面,而不是放在非线性单元后
因为非线性单元的输出分布形状会在训练过程中变化,归一化无法消除他的方差偏移,相反的,全连接和卷积层的输出一般是一个对称,非稀疏的一个分布,更加类似高斯分布,对他们进行归一化会产生更加稳定的分布。其实想想也是的,像relu这样的激活函数,如果你输入的数据是一个高斯分布,经过他变换出来的数据能是一个什么形状?小于0的被抑制了,也就是分布小于0的部分直接变成0了,这样不是很高斯了
https://blog.csdn.net/wzy_zju/article/details/81262453
argparse.ArgumentParser()用法
argparse是一个Python模块:命令行选项、参数和子命令解析器。
主要有三个步骤:
创建 ArgumentParser() 对象
调用 add_argument() 方法添加参数
使用 parse_args() 解析添加的参数
1. 创建解析器
parser = argparse.ArgumentParser(description='Process some integers.')
1
使用 argparse 的第一步是创建一个 ArgumentParser 对象。
ArgumentParser 对象包含将命令行解析成 Python 数据类型所需的全部信息。
2. 添加参数
parser.add_argument('integers', metavar='N', type=int, nargs='+', help='an integer for the accumulator')
3. 解析参数
>>> parser.parse_args(['--sum', '7', '-1', '42'])
Namespace(accumulate=<built-in function sum>, integers=[7, -1, 42])
ArgumentParser 对象
class argparse.ArgumentParser(prog=None, usage=None, description=None, epilog=None, parents=[], formatter_class=argparse.HelpFormatter, prefix_chars='-', fromfile_prefix_chars=None, argument_default=None, conflict_handler='error', add_help=True, allow_abbrev=True)
prog - 程序的名称(默认:sys.argv[0])
usage - 描述程序用途的字符串(默认值:从添加到解析器的参数生成)
description - 在参数帮助文档之前显示的文本(默认值:无)
epilog - 在参数帮助文档之后显示的文本(默认值:无)
parents - 一个 ArgumentParser 对象的列表,它们的参数也应包含在内
formatter_class - 用于自定义帮助文档输出格式的类
prefix_chars - 可选参数的前缀字符集合(默认值:’-’)
fromfile_prefix_chars - 当需要从文件中读取其他参数时,用于标识文件名的前缀字符集合(默认值:None)
argument_default - 参数的全局默认值(默认值: None)
conflict_handler - 解决冲突选项的策略(通常是不必要的)
add_help - 为解析器添加一个 -h/–help 选项(默认值: True)
allow_abbrev - 如果缩写是无歧义的,则允许缩写长选项 (默认值:True)
add_argument() 方法
ArgumentParser.add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
1
name or flags - 一个命名或者一个选项字符串的列表,例如 foo 或 -f, --foo。
action - 当参数在命令行中出现时使用的动作基本类型。
nargs - 命令行参数应当消耗的数目。
const - 被一些 action 和 nargs 选择所需求的常数。
default - 当参数未在命令行中出现时使用的值。
type - 命令行参数应当被转换成的类型。
choices - 可用的参数的容器。
required - 此命令行选项是否可省略 (仅选项可用)。
help - 一个此选项作用的简单描述。
metavar - 在使用方法消息中使用的参数值示例。
dest - 被添加到 parse_args() 所返回对象上的属性名。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









