







1、Commond类型多job执行
1)、编辑job内容
第一个job(bar.jab)内容如下,依赖foo.job
# bar.job
type=command
dependencies=foo
command=echo bar第二个job(foo.job)内容如下
# foo.job
type=command
command=echo foo2)、两个job打到一个zip包中(foobar.zip)
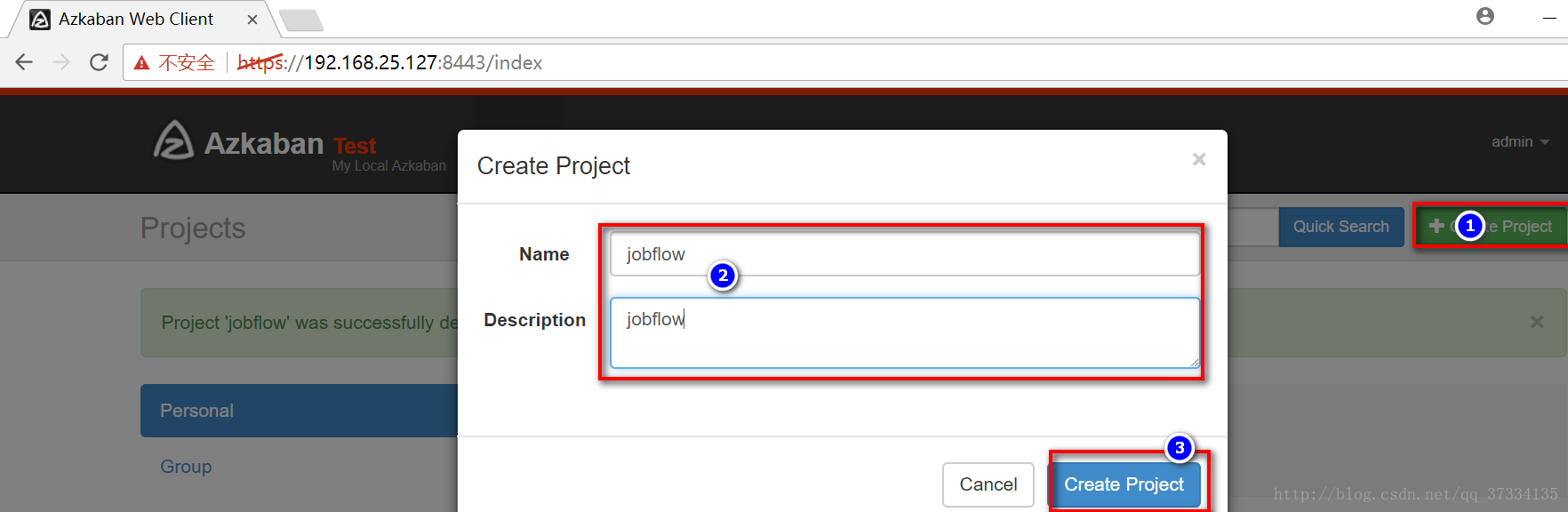
3)、在azkaban的web管理界面创建工程并上传zip包
这里演示一遍后面就不演示了
创建project
选择刚打好的foolbar.zip上传
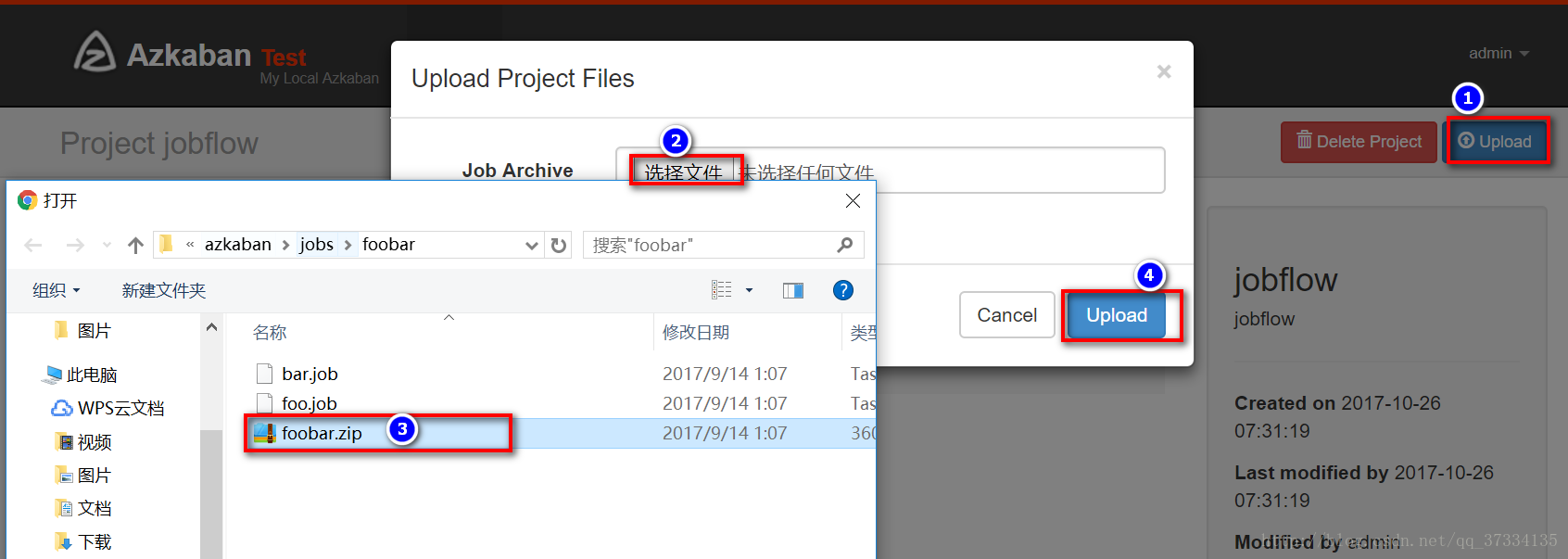
上传后选择执行

一个是调度,一个是立即执行,这里立即执行
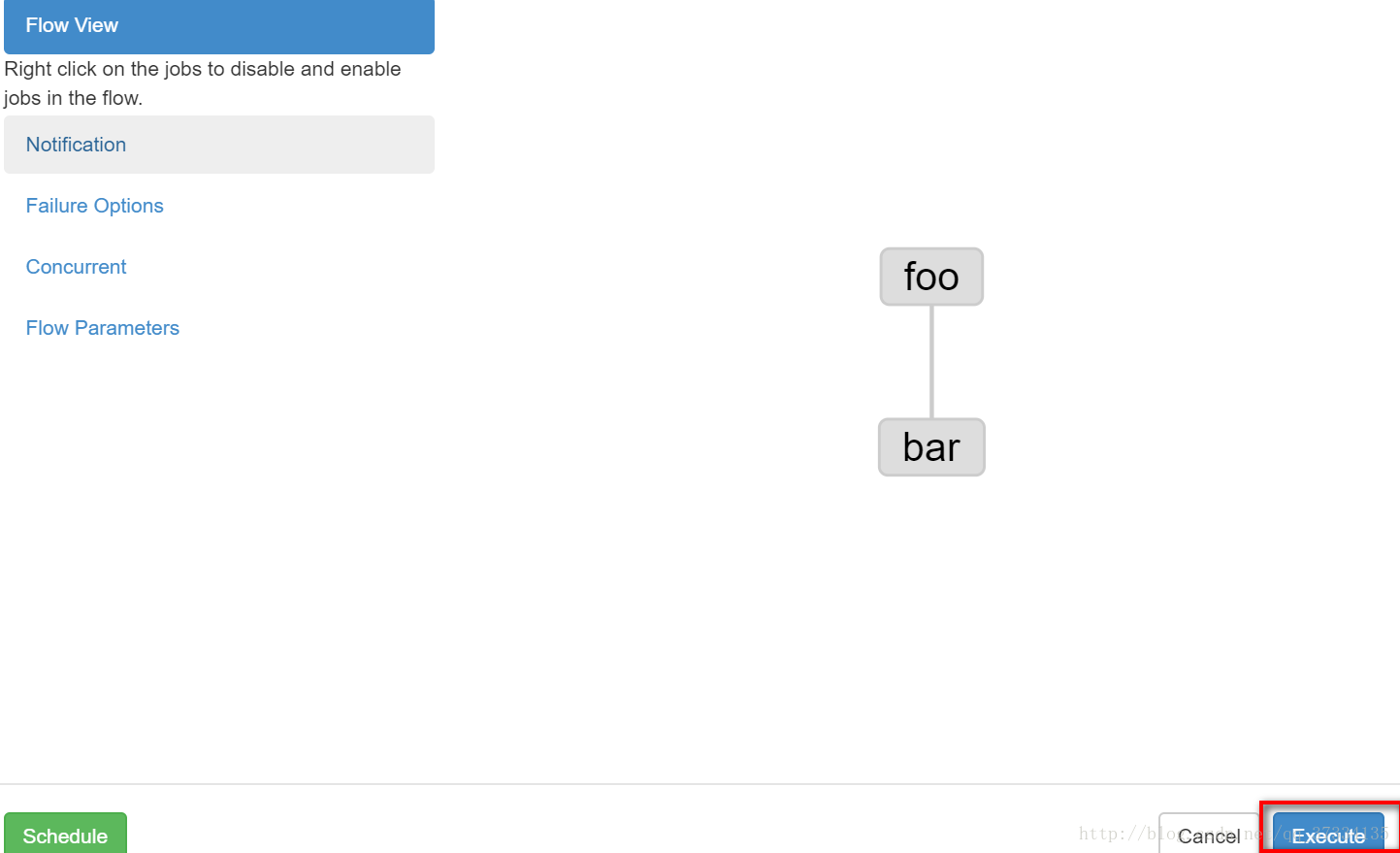
已经提示成功了
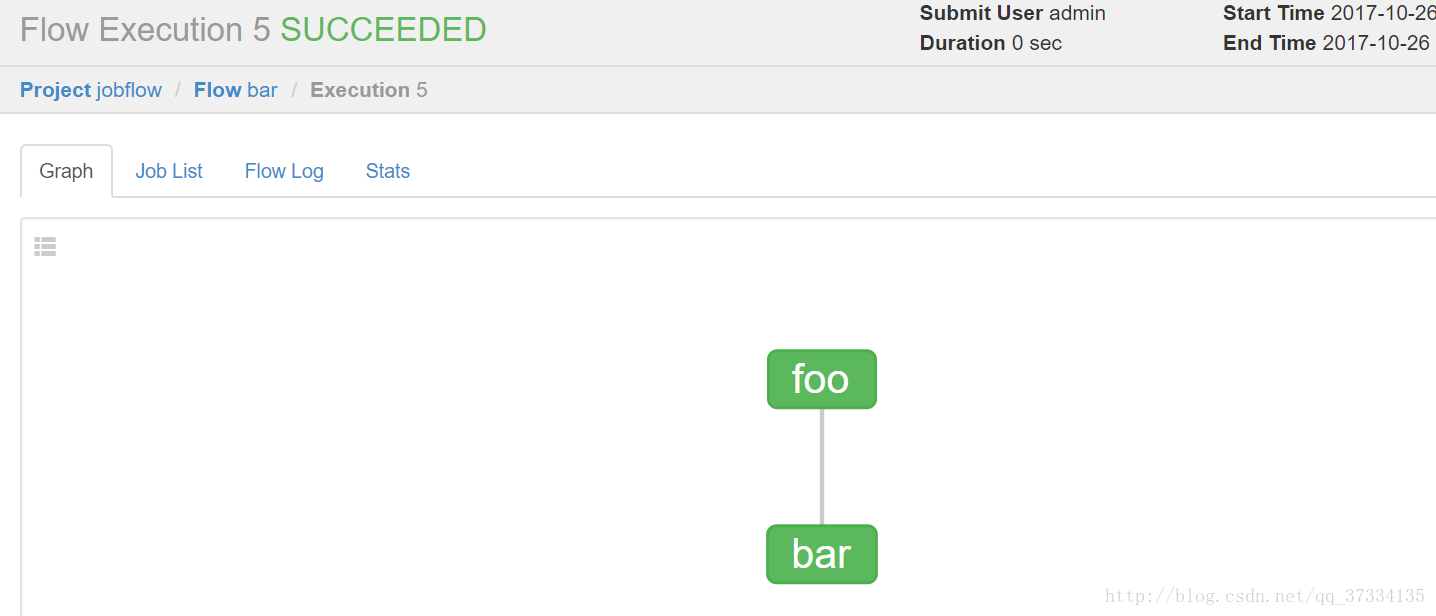
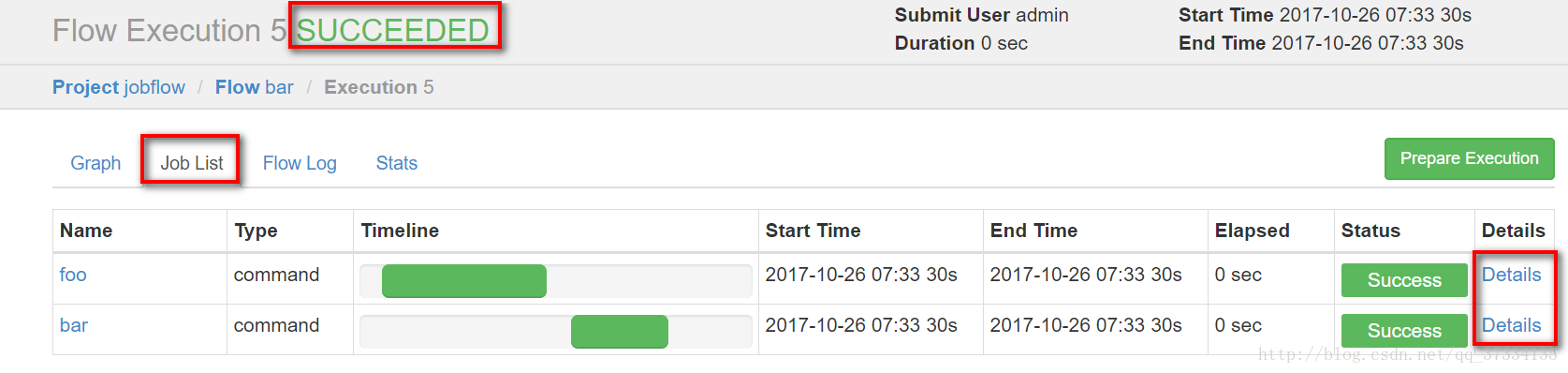
点击details能看到执行详情
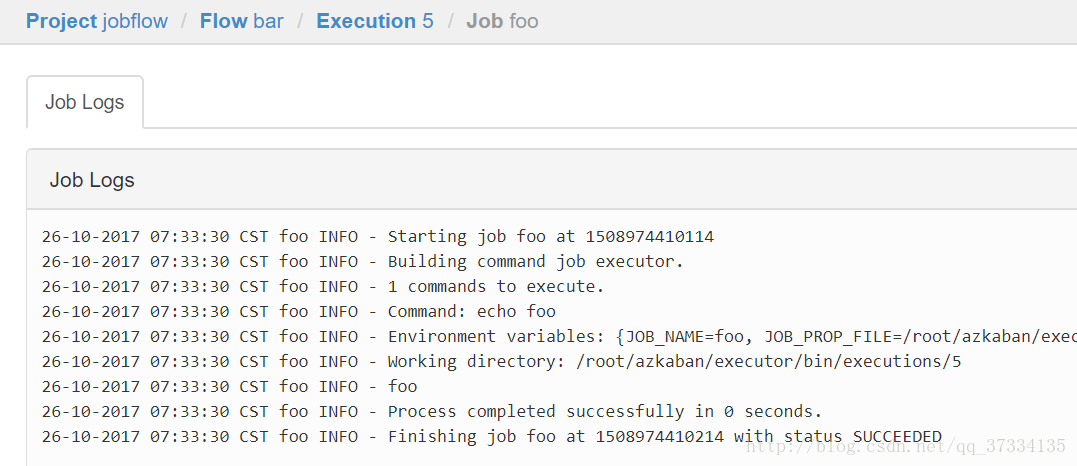
2、HDFS操作任务
1)、创建job(fs.job)内容如下
# fs.job
type=command
command=/root/apps/hadoop-2.6.4/bin/hadoop fs -mkdir /azaz注:执行的是hadoop命令,需要写清楚位置在哪,可以使用which来查看
[root@mini1 ~]# which hadoop
/root/apps/hadoop-2.6.4/bin/hadoop2)、打成fs.zip
3)、在azkaban的web管理界面创建工程并上传zip包
4)、执行该job
注:hadoop集群需要起来才能跑,能创建该文件夹的话
执行之后初始是running状态接着会显示succeed,出错了也会提示错误信息。跑完之后页面查看是否在hdfs上创建了azaz目录
使用hadoo命令创建文件夹成功了,那么其它操作基本也不会有问题就不演示了。
3、跑Mapreduce程序
Mr任务依然可以使用command的job类型来执行
1)、创建mrwc.job内容如下(wordcount程序)
# mrwc.job
type=command
command=/root/apps/hadoop-2.6.4/bin/hadoop jar hadoop-mapreduce-examples-2.6.1.jar wordcount /wordcount2/input /wordcount2/azout2)、打wc.zip包
注:要将能进行单词统计程序所在的jar包也一起打进去
但是还需要准备工作,创建好目录,传进入需要统计的单词所在的文件。
[root@mini1 ~]# vi c.txt
hello tom
hello jack
jack lucy
[root@mini1 ~]# hadoop fs -mkdir -p /wordcount2/input
[root@mini1 ~]# hadoop fs -put c.txt /wordcount2/input
3)、在azkaban的web管理界面创建工程并上传zip包
等完成后去页面查看
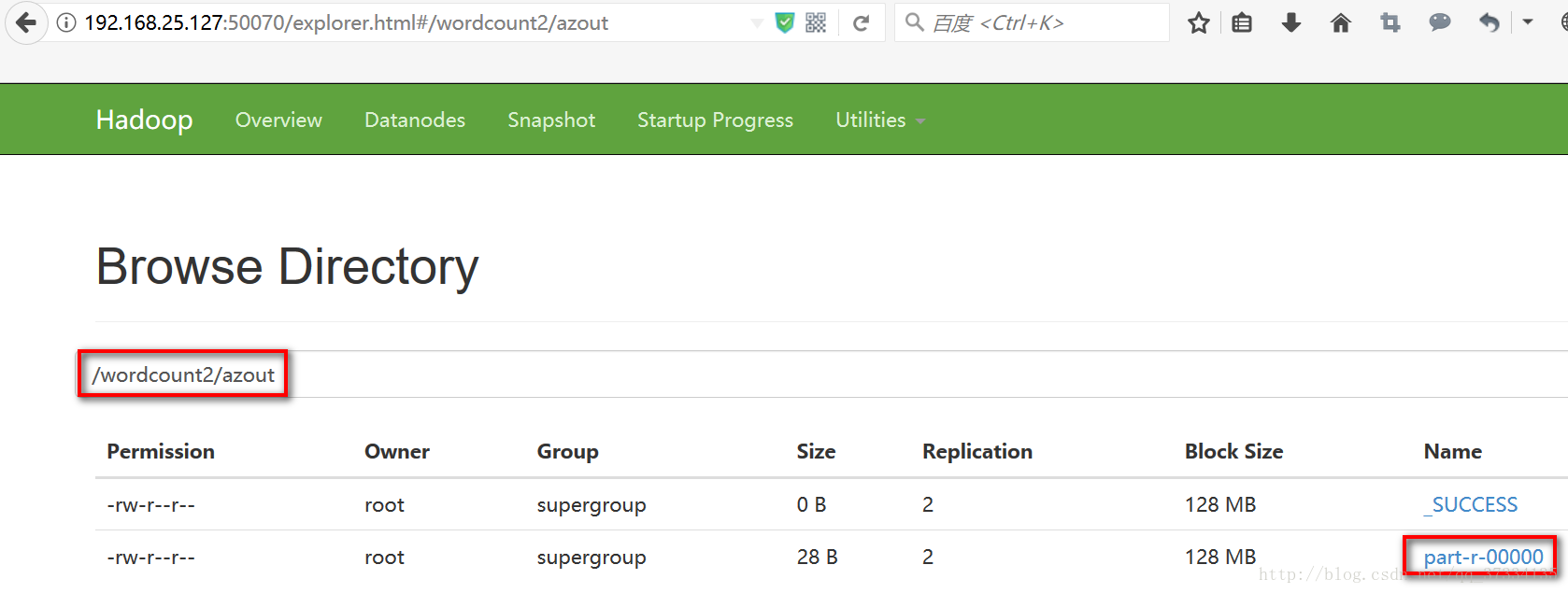
查看统计结果
[root@mini1 ~]# hadoop fs -ls /wordcount2/azout
Found 2 items
-rw-r--r-- 2 root supergroup 0 2017-10-26 08:08 /wordcount2/azout/_SUCCESS
-rw-r--r-- 2 root supergroup 28 2017-10-26 08:08 /wordcount2/azout/part-r-00000
[root@mini1 ~]# hadoop fs -cat /wordcount2/azout/part-r-00000
hello 2
jack 2
lucy 1
Hive脚本任务
hive脚本,test.sql内容如下
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',';
load data local inpath '/root/b.txt' into table aztest;
create table azres as select * from aztest;
insert overwrite local directory '/root/hiveoutput' select count(1) from aztest; job描述文件(hive.jab)如下
# hivef.job
type=command
command=/root/apps/hive/bin/hive -f 'test.sql'
#-f表示执行写在文件里面的sql语句同样是上传执行,完成后查看是否创建了两张表和本地文件/root/hiveoutput/xxxx
hive> select * from aztest;
OK
2 bb
3 cc
7 yy
9 pp
Time taken: 0.067 seconds, Fetched: 4 row(s)
hive> select * from azres;
OK
2 bb
3 cc
7 yy
9 pp
Time taken: 0.179 seconds, Fetched: 4 row(s)
hive>
[root@mini1 ~]# cd hiveoutput/
[root@mini1 hiveoutput]# ll
总用量 4
-rw-r--r--. 1 root root 2 10月 26 08:44 000000_0
[root@mini1 hiveoutput]# cat 000000_0
4
[root@mini1 hiveoutput]#















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









