







认识自己的无知是认识世界最可靠的方法
(`・ω・´) 开局一张图
索引是什么?
做个实验: 问问你周边的小伙伴 索引是什么?
我周边的小伙伴是下面的表情,平时在用的时候大部分人都知道它能够加速查询,但是至于定义嘛,往往被忽略。
MySQL官方:索引(Index)是帮助MySQL高效获取数据的一种数据结构。MySQL的查询本质也就是找数据,如果选择了链表结构的话每次查询的时间复杂度都是O(n)。所以在实现索引时选择合适的数据结构非常重要。
怎么选择合适的数据结构?
要理清楚这个问题需要知道影响查询速度的几个重要因素。
- 索引的存储方式
- 索引的数据结构
存储方式为什么影响查询速度嘞?
Q1:索引存储在内存还是外存 ?
本科阶段有一门课程叫做计算机组成原理,在计算机存储的章节应该介绍了计算机从内存读取数据和从外存读取数据的区别,最为明显的区别就是读取的速度,从内存读取速度远快于从外存读取。我们要知道MySQL的索引是不可能一直存储在内存中的,所以所以的物理存储方式是存储在外存中。可以打开MySQL安装路径文件夹中得到验证

其中【.MYI】结尾的文件存储的就是索引文件。
Q2:外存读取数据的过程 ?

上图所示是磁盘的物理结构,硬盘的读写以扇区为基本单位。磁盘上的每个磁道被等分为若干个弧段,也就是图中磁道上的一小块阴影部分,这些弧段称之为扇区。
特点
- 磁盘I/O是属于机械操作,读取速度 【磁盘 >> 内存】
- 切磁头不能旋转,只能沿着磁盘做斜切向运动来读取扇区部分的数据
- 在读取数据过程中为了确定数据在那个扇区,需要将磁头移动到对应扇区所在的磁道上,这个过程消耗时间叫【寻道时间】
- 接着磁盘通过旋转的方式将目标扇区旋转到磁头下面,这个过程消耗的时间叫【旋转延迟】
为了加快查询的速度我们尽量减少这两个时间,其中 旋转延迟 是由磁盘本身的物理特性决定的,我们能做的就是改变数据的查询方式来减少寻道时间。
扇区是磁盘的物理概念,操作系统是不直接与扇区交互的,而是与多个连续扇区组成的磁盘块进行交互。
局部性原理
局部性原理:在最近的将来将用到的信息很可能与正在使用的信息在空间地址上是临近的。
依据局部性原理,磁盘通常不仅仅是按需读取,每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。
扇区是磁盘最小的物理存储单元,操作系统将相邻的扇区组合在一起,形成一个块也叫作页(page)对块进行管理,一个块(页)的大小通常是4k。
主存和磁盘以页为单位交换数据,预读的长度一般为页(page)的整倍数。
当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
小结 : 因为索引文件是存储在外存的,由于计算机读取外存的机制导致大量时间花费在寻道上。
数据结构的选择?
目标: 选择一种合理的数据结构(存储结构),要求充分利用存储的局部性原理、时间复杂度最低。
Hash
基于哈希表实现,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),并且Hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针。

缺陷:哈希索引数据并不是按照索引列的值顺序存储的, 所以不能利用局部性原理。
BTree
基于BTree的实现意味着所有的值都是按照顺序存储的,从根节点出发到每个叶子节点的距离相同。
下图是BTree的示意图,其中的数字可以理解为索引关键字,但是节点中除了存储索引关键字之外还会存储数据。
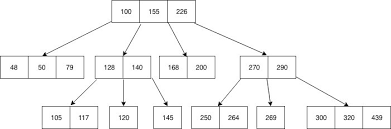
B-Tree 查找时需要从索引的根节点开始进行搜索。根节点的槽中存放了指向子节点的指针,存储引擎根据这些指针向下层查找。
通过比较节点页的值和要查找的值可以找到合适的指针进入下层子节点,这些指针实际上定义了子节点页中值的上限和下限。
最终存储引擎要么是找到对应的值,要么该记录不存在。
缺陷 :因为BTree的每个结点都会存储索引关键字和对应的数据,所以在有海量数据需要存储的时候,一个节点的存储的数据有限,只能通过扩展树的高度来存储数据,所以BTree的树高来越大。意味着需要查找的时间更久。
B+ Tree
基于B+ Tree的实现意同样意味着所有的值都是按照顺序存储的,B+Tree 可以看做是BTree的一种改进。和BTree不同的是
- B+ Tree的非叶子节点不存储数据,只存储索引关键字
- 叶子节点中包含所有节点的关键字信息,且根据关键字从小到大排序,且叶子节点之间存在指针进行连接,就像一个链表

根据上述特性可知:
- 同样的数据量B+Tree的树高会明显低于BTree,因为B+Tree把所有的非叶子节点都用来存关键字,节点的度增大了(一个节点可以分出去的子树更多)从而树的高减小,意味着查找时减少了I/O操作。
- 因为B+Tree所有的数据都是存储在叶子节点上且用链表的形式进行了从小到大的排序,所以更加适合范围查找。
(`・ω・´) 收尾一张表
| 数据结构 | 优点 | 缺点 |
|---|---|---|
| Hash | 查找指定的数据非常快 | 不能利用局部性原理。 |
| BTree | 非叶子结点保存具体数据,在查找某个关键字的时候找到即可返回 | 数据量大的时候树高会很大 |
| Hash | 树高小,效率高,非常适合范围查找 | 叶子结点中会冗余一份非叶子结点的关键字 |
下篇挖坑:面试常问——MySQL中的那几把锁。















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









