









目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于协同过滤的美食店铺推荐系统
课题背景和意义
随叫随到的外卖服务在中国非常流行,美团、大众点评每天的外卖订单超过3000万份,美食平均在30分钟内 送到食客手中。如何推荐出更符合用户喜好的餐厅,成为当下商家和用户较为关心的话题。针对如何对用户推荐符合心 意的餐厅的问题,提出了基于协同过滤的美食店铺推荐算法。如今,随叫随到的外卖服务非常流行。食客可以 浏览在线餐厅市场,选择餐厅并预订他们喜欢的食物 或饮料。但是面对网络数据的爆炸增长,使得用户难 以在海量的数据中快速地找到适合自己的美食,具有 一定的盲目性。通过对现有美食App的调查发现,美食数据排行过于笼统,不能有效地解决用户的个人喜 好等问题。针对以上问题,现阶段的市场提供个性化 推荐服务、提高检索效率、优化用户体验成了广大食 客的诉求。面对这一诉求,根据数据集的用户和餐厅 特征,提出基于协同过滤的美食店铺推荐系统算 法,该算法结合了基于用户的推荐算法、基于餐厅的 推荐算法、基于 SVD 的协同过滤算法以及流行度推 荐算法,并使用准确率和召回率以及 F1这三种指标 与其他算法进行比较,解决推荐餐厅与用户喜好适配度问题。
实现技术思路
一、基于协同过滤的混合推荐算法
构建了融合多因素的美食推荐方法,该方法 统一对用户、餐厅签到记录、餐厅流行度进行建模,通 过餐厅签到记录捕获用户潜在的偏好,并且结合流行 度模型进行餐厅推荐。本文最后在真实世界的数据 集上进行了实验,证明本文提出的方法相比现有的其 他方法能够更加准确地向用户推荐餐厅。
基于流行度的协同过滤算法
所谓“从众”,是指在群体的影响下,放弃自己的 观点,与他人保持一致的社会心理行为。例如,在网 上购物时,用户会习惯性地查看商品的销售量。当销 售量越大时,用户更倾向于购买并给予高分。餐厅的 受欢迎程度极大地影响着用户的决定。换言之,用户 更有可能访问热门餐厅。
提出基于流行度的推荐算法,该基础算法是 根据用户对餐厅点击的热度将当下最热门的内容推 荐给用户,由此对求解基于流行度的推荐算法的算 法思路基本如下:
1)用户-餐厅历史调用记录
通过对历史数据集进行分析,得到了用户集合和 餐厅集合,记用户集合为U,U = { u1,u2,u3,…un}。记餐 厅集合为R,R = { r1,r2,r3,…rm }。记用户餐厅调用记录 矩 阵 Yn × m ,若 用 户 ui 访 问 过 餐 厅 rj ,那 么 yi,j = 1, yi,j ∈ Yn × m 。
2)计算餐厅之间的相似度
利用余弦算法计算餐厅之间的相似度,公式 如下:
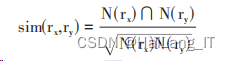
其中,N(rx) 表示喜欢餐厅rx的用户数,N(ry) 表示 喜欢餐厅 ry 的用户数,N(rx) ∩ N(ry)表示同时喜欢餐 厅rx,ry的用户数。
3)计算推荐餐厅推荐列表
采用引入流行度来进行餐厅推荐。记某一餐厅为ra,通过对数据集历史记录进行分析,得到餐 厅 ra 的历史访问人数为 num(ra), 餐厅 ra 的流行度为 pnum(ra),平均流行度为pnum(ra) avg,对流行度进行归 一化,得到公式如下:
![]()
weight(ra ) 表示餐厅ra的流行度权重因子。 利用流行度来改进公式,得到如下公式:
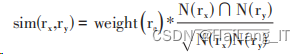
若用户ui访问过餐厅rx,那么依据公式可得到 其余餐厅与rx的相似程度,利用相似程度完成推荐, 得到餐厅推荐列表。
基于SVD的协同过滤算法
通过对基于SVD的协同过滤算法的研究,对矩 阵Y进行SVD分解,得到如下公式:
![]()
其中P为用户特征矩阵,Q为餐厅特征矩阵。其 中,P ∈ Yf × n 的每一行表示用户,每一列表示一个特 征,它们的值表示用户与某一特征的相关性,值越大, 表明特征越明显。Q ∈ Yf × m的每一行表示餐厅,每一 列表示餐厅与特征的关联。
经过SVD分解,得到每一个用户对于每一个餐厅 的偏好程序,公式如下:
![]()
本文使用梯度下降算法来进行训练,公式如下:
![]()
其中,λ 为超参数,λ(||pui || 2 + ||qry || 2 ) 表示计算方 差,衡量模型的稳定性。方差大的模型会过拟合。
总体偏好程度
为了提高推荐的准确性,使用线性框架来结合用 户偏好和流行度影响。本文使用用户对于餐厅的总 体偏好程度来计算餐厅推荐列表,目的就是根据线 性框架来学习用户对不同餐厅的偏好,从而给出用户 感兴趣的餐厅分布 。为了提高推荐算法的准确程 度,将基于SVD与流行度算法相结合,并引入流行度 权重因子α,得到最终结果,公式如下:
![]()
通过对权重因子的测试,获得本推荐算法的最终 结果,从而产生餐厅推荐列表。
二、实验及评估结果
实验数据集
数据来自于和鲸社区美食数据集①,共4万家 餐厅,54万用户,440万条评论数据。首先对数据集进 行数据预处理,删除低于100条的数据记录数,通过整 理最终参与实验一共 4417 家餐厅,3291 用户,76208 条数据。由于用户评价较为主观性,采用归一化处理评价数据。
评估指标
本文使用精确率、召回率和 F1 指标来衡量算法 性能。 精确率。表示符合用户喜爱的推荐物品数在用 户总推荐物品数的比例,定义如下:
![]()
其中 n(B) 为符合用户 B 喜爱的推荐餐厅, m(B) 为用户 B 总喜爱的推荐餐厅,s(B) 为用户 B 总推荐 餐厅。
召回率。表示符合用户喜爱的推荐物品数与用 户总喜爱的推荐物品数的比例 ,定义如下:
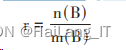
F1指标。代表精确率和召回率的一个综合考量, 两者一起使用才能评价推荐系统的好坏,定义如下:
![]()
基础算法对比
将数据集分为训练集和测试集,通过误差计算, 发现不同参数对应的误差值都不同。这些参数包括 邻居个数,训练,测试集的划分比例。为测试其灵敏 性,分别对训练集、测试集进行数据测试。
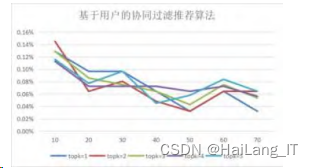
针对基于用户的推荐算法,本文对不同推荐个数 以及邻居个数进行研究,结果如图1所示。图表中数 据显示,邻居个数的增加,基于用户的推荐相似度总 体趋势呈下降状态。并通过对数值反复的模拟计算, 前期topk=5的曲线趋势值要处于相对于中间趋势,但 后期随着邻居个数的增加,取 topk=5 的效果要优于 其他。
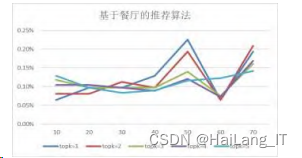
针对基于餐厅的推荐算法对推荐程度的影响,改 变topk和邻居个数的值通过控制变量法,测得数据如图。通过图可以看出在邻居个数位于50左右,基 于餐厅推荐算法的相似度达到一个相对峰值,为相对 优值。
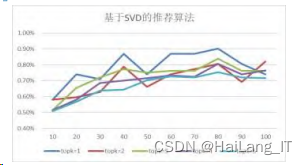
基于上述两种推荐算法引入第三种基于SVD的 推荐算法对实验的影响程度,根据数据得出上述图, 发 现 基 于 SVD 推 荐 总 体 数 据 区 间 位 于 0.50%~ 0.90%,整体相似度相对提高,呈上升趋势,数据波动 较小,在邻居个数处于80左右得到此算法在同一topk 下的相对峰值。
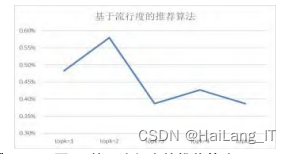
在对流行度进行数据分析,数据波动于 0.4%~ 0.6% 这一区间内,在 topk=2 时处于该算法的峰值 0.58%。
混合算法对比
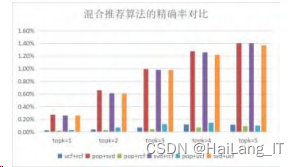
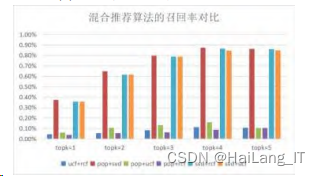
如图5给出了六种混合推荐算法各项指标下的实 验结果,其中UCF为基于用户的协同过滤、RCF为基 于餐馆的协同过滤、SVD 为基于 SVD 的协同过滤、 POP为基于流行度的协同过滤。
混合算法的召回率比较:
混合算法的F1比较:
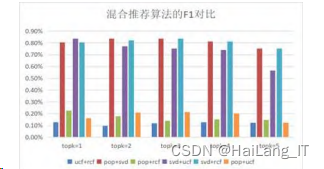
通过对基础算法的改进与融合,对精确率、召回 率、F1的实验结果分析,相比于其他混合算法只有某 一方面的提升,基于POP与SVD的混合推荐算法无论 是在美食餐厅推荐的准确程度、全面度都有了明显的 质量提高,在 topk=5 时达到了实验的峰值,推荐效 果好。
三、总结
基于SVD和基于流行度(POP)的混合 推荐算法,该算法结合了 SVD 算法和 POP 算法的优 点。实验表明,该算法在精确率、召回率和F1三个指 标上要优于其他对比算法。未来,我们计划将神经网 络算法引入到美食推荐中。
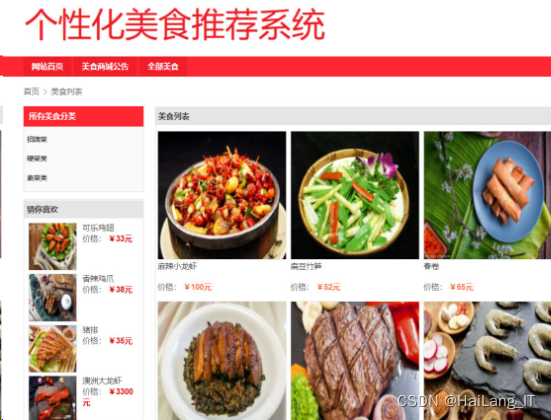
实现效果图样例
美食店铺推荐系统:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









