







 本文介绍了基于深度学习的奥特曼识别项目,包括神经网络特别是卷积神经网络和FPN特征金字塔网络的理论基础,数据集的创建与扩充,以及实验环境的搭建和模型训练过程,展示了如何通过这些技术推动动漫产业的发展。
本文介绍了基于深度学习的奥特曼识别项目,包括神经网络特别是卷积神经网络和FPN特征金字塔网络的理论基础,数据集的创建与扩充,以及实验环境的搭建和模型训练过程,展示了如何通过这些技术推动动漫产业的发展。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的奥特曼识别
课题背景和意义
结合当前我国动漫产业与人工智能领域的发展现状,如何运用人工智能推动我国动漫产业的发展是一个值得探究的方向。机器视觉作为人工智能快速发展的一个分支,在各个研究方向都有良好的发展与应用。中国是机器视觉发展最活跃的地区之一,机器视觉的应用范围涵盖了医疗、工业、航天、军事、民用、科研等国民经济的各个行业。
将机器视觉应用于动画图像分析,对动漫作品中的人物进行图像识别。通过对图像中人物的智能识别,可以帮助用户在平常生活中对所见的短视频或图片中的动漫人物进行识别,帮助用户获取动漫人物信息,也可以为用户查找动漫提供便利,培养用户对动漫的兴趣,从而增加动漫产业的用户量,增加动漫产业的活力,促进动漫产业的发展。
实现技术思路
一、 算法理论基础
1.1 神经网络
深度神经网络(DNN)是计算机人工智能的一次技术飞跃。目前,深度神经网络在机器视觉、机器人学习和语音识别等众多人工智能中被大量应用。深度神经网络DNN虽然有计算难度高的问题,但是在众多人工智能任务中都表现出色。因此,如何能够提升深度神经网络的处理效率,并提高数据吞吐量,同时又能保证准确度,成为了现代人工智能技术的重点研究对象。从定义上来说,任何具有两个或者两个以上隐藏层的神经网络都是深层神经网络,而近些年中,深度神经网络是指具有更多层次的网络。
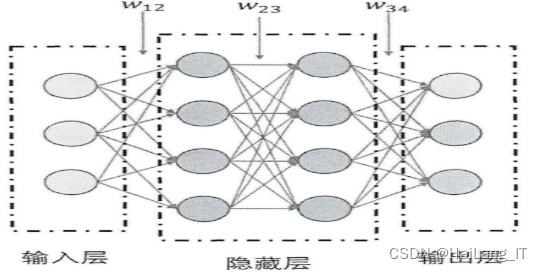
卷积神经网络(CNN)是最著名的深度学习方法之一,其中多层以稳健的方式进行训练。卷积神经网络非常有效,也是各种计算机视觉应用中最常用的方法。
对于图像处理,如果使用全连接神经网络会有以下缺点:
- (1)全连接神经网络需要将图像展开,导致图像失去了空间信息;
- (2)使用大量的参数,训练效率低下;
- (3)同时大量的参数也很快会导致网络过拟合。卷积神经网络(CNN)则能够克服以上问题与缺点。
卷积神经网络有着与全连接神经网络完全不同的结构,卷积神经网络通过各层的卷积核生成下一层的“图像”信息,每一层的输入和输出皆为3维排列的,包含宽度、高度和深度。高度和宽度都有直观的理解,就如同图片的高和宽,卷积核本身也是一个二维的矩阵,其中卷积神经网络中的深度指的是指传入数据的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数。举个简单的例子来说明什么是宽度、高度和深度,我们常见的RGB图片,RGB代表红、绿、蓝三种颜色,也是一个图片的三个通道,通过对红(red)、绿(green)、蓝(blue)三个颜色通道的变化以及它们相互之间的组合来得到不同的颜色的,每种颜色的深度,用0到255的值表示,一张RGB图片我们就可以把它看成一个MN3的彩色像素数组,其中每一个像素点是深度为3的数组。
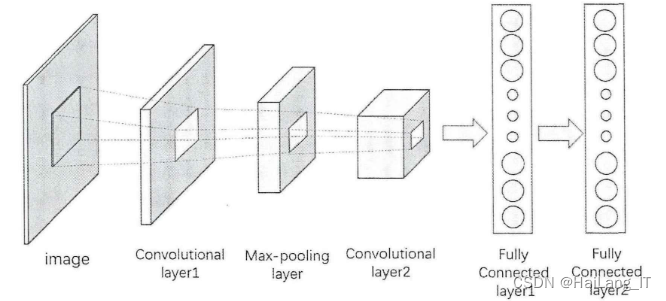
卷积神经网络(CNN)的每一层由多个卷积单元组成。在CNN中,层与层之间通过卷积核将三维的输入数据变化为卷积核三维的激活数据并输出。第一层输入层为输入图像,宽度和高度即为图像的宽度和高度,深度表示三种颜色通道。中间部分包括卷积层、激活函数以及池化层,卷积层与其他各层之间通过卷积运算、激活函数和池化层将上一层信息传递到下一层。最后将三维图像数据展平输入到全连接层中进行运算。卷积层是构建卷积神经网络的核心部分,网络中的主要计算量都集中在卷积层。
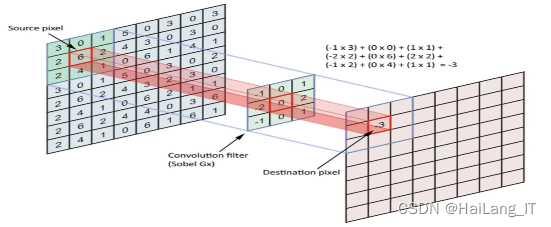
卷积层由一组滤波器组成,也称为卷积核。卷积核实际上是一个二维矩阵,在卷积神经网络中,卷积是一种线性操作,涉及一组权重与输入相乘,与传统神经网络非常相似。由于该技术是为二维输入而设计的,因此在输入数据数组和二维权重数组(称为过滤器或卷积核)之间执行乘法,从数学角度来说,卷积层的运算就是矩阵的卷积运算。卷积层可以降低参数的数量,这是因为卷积具有“权值共享”的特性,可以降低参数数量,达到降低计算开销,防止由于参数过多而造成过拟合。
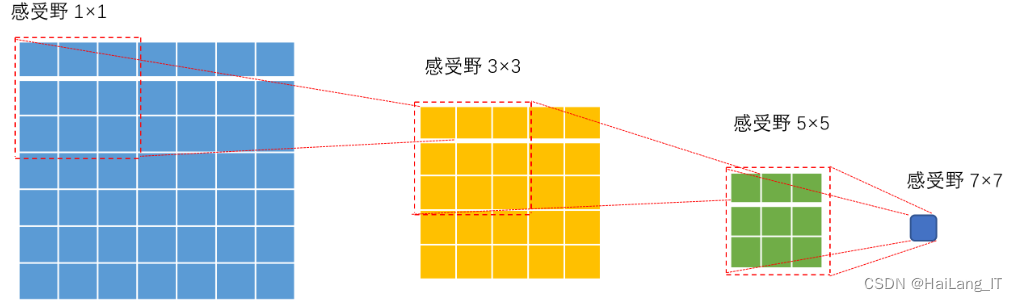
感受野的定义是指网络每一层输出的特征图上的像素点在输入图片上映射的区域大小,也可以理解为卷积神经网络特征所能看到输入图片的区域范围大小。感受野的大小决定了网络对输入图像不同位置的信息获取能力,较小的感受野通常用于捕捉细节信息,而较大的感受野则用于捕捉全局上下文信息。通过不同层的卷积和池化操作,感受野会逐渐扩大,从而能够对输入图像的不同尺度和层次的特征进行提取和理解。感受野的大小是设计卷积神经网络结构时需要考虑的重要因素,合理选择感受野大小可以提高网络的性能和泛化能力。
1.2 FPN特征金字塔网络
FPN特征金字塔网络是一种用于目标检测和语义分割任务的网络结构。它的设计目标是在不同尺度上提取和利用图像中的语义信息。FPN网络的核心思想是通过自顶向下和自底向上的路径来构建特征金字塔。自顶向下路径通过上采样操作将较粗糙的低分辨率特征图转换为高分辨率特征图,这样可以保留更多的细节信息。自底向上路径则通过跨层连接的方式将不同层级的特征图进行融合,以获取更丰富的语义信息。
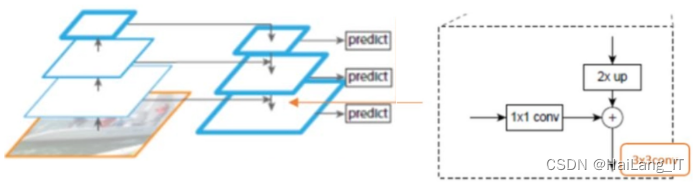
在FPN中,特征金字塔的顶层特征图包含了全局语义信息,逐层向下的特征图则包含了更加局部和详细的信息。这样的设计使得FPN网络能够在不同尺度上进行目标检测和语义分割,并且能够处理不同大小和尺度的目标。FPN网络已经在许多视觉任务中取得了很好的效果,特别是在处理多尺度目标的情况下表现出色。它已经成为许多先进目标检测和语义分割算法的重要组成部分。
二、 数据集
2.1 数据集
由于网络上没有现有的合适的数据集,我决定自己进行奥特曼识别的数据收集。我使用网络爬虫技术从各种来源收集了大量奥特曼相关的图片,并制作了一个全新的数据集。这个数据集包含了不同奥特曼系列的战斗场景、奥特曼角色的形象以及其他相关元素。通过网络爬取,我能够获取真实的、多样化的奥特曼图片,这将为我的奥特曼识别研究提供更准确、可靠的数据。我相信这个自制的数据集将为奥特曼识别技术的发展提供有力的支持,并为该领域的研究做出积极的贡献。

2.2 数据扩充
数据扩充是一种常用的数据增强技术,旨在通过对原始数据进行变换和调整来扩充数据集的规模和多样性。数据扩充可以帮助提高模型的鲁棒性和泛化能力,减轻过拟合问题,并且可以缓解数据不平衡的情况。通过数据扩充,可以应用各种变换操作来生成新的训练样本。例如,可以进行随机旋转、平移、缩放、镜像翻转等几何变换,以增加数据的空间多样性。此外,还可以应用亮度调整、对比度增强、颜色变化等像素级别的操作,以增加数据的视觉多样性。通过数据扩充,可以有效增加数据集的大小,从而提高模型的泛化能力。此外,数据扩充还可以模拟真实世界中的各种变化和噪声,使模型更好地适应实际应用场景。
三、实验及结果分析
3.1 实验环境搭建
实验所使用的服务器操作系统环境为Windows系统。该服务器配置了英伟达GeForce GTX 2080 Ti显卡和16GB的显存,以及Intel Xeon Gold 6230 CPU @ 2.10 GHz。模型使用PyTorch框架实现,CUDA版本为11.6,使用的PyTorch版本是1.10.2。PyTorch既可以看作加入了GPU支持的NumPy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。除了Facebook外,它已经被Twitter、CMU和Salesforce等机构采用。
3.2 模型训练
在实验过程中,需要设置以下超参数:Batch Size(批大小)、Activation Function(激活函数)、Epoch(训练轮次)、Learning Rate(学习率)等。Batch Size定义了一次训练所选取的样本数量,它影响模型的优化程度和速度,并直接影响GPU内存的使用情况。适当的Batch Size可以提高内存利用率和训练速度。激活函数的作用是改变之前数据的线性关系,使得神经网络可以学习非线性的复杂函数映射。
import torch
import torch.nn as nn
import torch.optim as optim
# 设置超参数
batch_size = 32
activation = nn.ReLU()
num_epochs = 10
learning_rate = 0.001
# 定义模型
model = YourModelClass()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 加载数据和数据迭代器
train_dataset = YourDataset(...)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 训练模型
for epoch in range(num_epochs):
for inputs, labels in train_loader:
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每个epoch结束后的操作
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}")
# 在训练完成后,可以使用模型进行预测等操作本实验使用的激活函数是ReLU函数,它具有解决梯度消失问题、计算速度快和收敛速度快的优点。实验分为两个阶段进行训练,首先冻结前置特征提取网络的权重,训练RPN和最终预测网络部分,然后微调后面两部分的权重。学习率采用动态设置,每5个epoch学习率乘以0.33,并在第10个epoch后开始保存权重。其他参数设置包括载入图片的线程数、分类类别数、数据载入函数的自定义参数等。
optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=learning_rate)
for epoch in range(num_epochs):
for inputs, labels in train_loader:
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 动态调整学习率
if (epoch + 1) % 5 == 0:
learning_rate *= 0.33
for param_group in optimizer.param_groups:
param_group['lr'] = learning_rate
# 在第10个epoch后开始保存权重
if epoch >= 9:
torch.save(model.state_dict(), f'weights_epoch_{epoch+1}.pth')
# 每个epoch结束后的操作
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}")
最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









