







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长大数据毕设专题,本次分享的课题是
🎯基于大数据的热映电影数据可视化系统
项目背景
随着电影产业的蓬勃发展,热映电影数据成为了分析市场趋势、观众喜好和投资方向的重要依据。然而,这些数据往往庞大且复杂,难以直观地呈现其内在规律和联系。因此,基于大数据的热映电影数据可视化系统应运而生。该系统通过深度挖掘和可视化展示热映电影数据,为电影制作方、发行商、影院和观众提供了全面、直观的数据支持。这不仅有助于提升电影产业的决策效率和市场竞争力,还能为电影研究、文化传播和艺术教育等领域提供有力的数据支撑和新的研究视角。
设计思路
通过Python网络爬虫技术,我们收集了多个网站的热映电影影评、票房数据及用户信息。经过全面的文本分析和聚类处理,我们提取了评论主题,并通过数据可视化手段,结合地址、时间等特异性信息,深入剖析了观影人群的用户画像、观影体验和增长趋势,为综合评价电影影响力提供了有力依据。
TF-IDF称为“词频-逆文档频率”。它是一种用于信息检索和文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
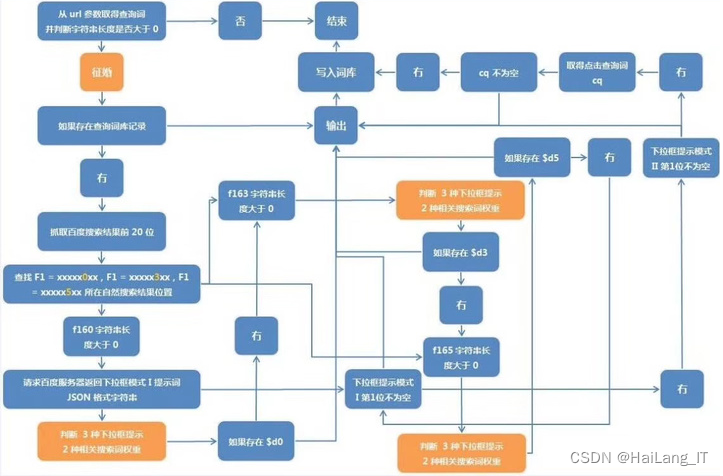
- TF(词频):表示词条(关键字)在文本中出现的频率。这个数字通常会被归一化(一般是词频除以文章总词数),以防止它偏向长的文件(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)。
- IDF(逆文档频率):主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。IDF是一个词语普遍重要性的度量,某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
将TF和IDF相乘,就得到了一个词的TF-IDF值。某个词在文章中的TF-IDF值越大,那么这个词对这篇文章的代表性就越强,也就是越能区分出这篇文章与其他文章的不同之处。所以,TF-IDF常被用于提取文章的关键词,或者用于文本相似度的计算等。
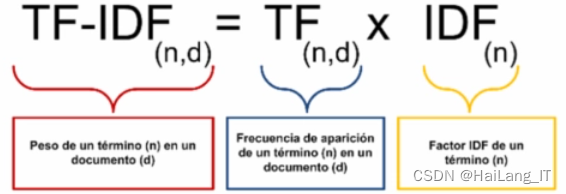
TF-IDF的优点在于简单快速,结果比较符合实际情况。但缺点在于单纯以“词频”衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不合理的。另外,TF-IDF也没有考虑到上下文的信息,比如一个词在不同的上下文中,重要性可能是不同的。
K-means聚类算法,也称为k均值聚类算法,是一种基于划分的无监督聚类算法,广泛应用于数据挖掘领域。该算法以k为参数,将n个数据对象划分为k个簇,使得同一簇内的数据对象具有较高的相似度,而不同簇间的数据对象相似度较低。K-means算法的基本思想是通过迭代寻找k个簇的一种划分,使得聚类结果对应的代价函数(如所有样本点到其所属簇中心距离的平方和)最小。这个过程通常是通过不断调整每个簇的中心点来实现的,直到满足某个终止条件(如簇中心不再发生明显变化,或达到预设的最大迭代次数等)。
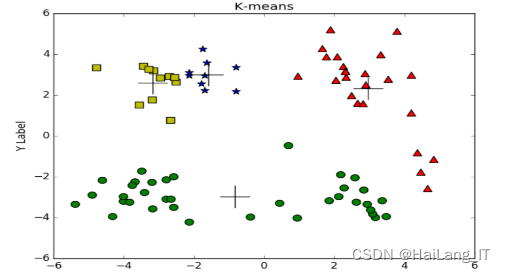
K-means算法的处理流程如下:
- 随机选取k个对象作为初始的聚类中心(也称为质心)。
- 计算每个数据对象到各个聚类中心的距离,并将其分配给距离最近的聚类中心,形成k个簇。
- 重新计算每个簇的质心,质心是该簇中所有数据对象的均值。
- 重复步骤2和3,直到满足终止条件。
数据集
现有的公开数据集难以满足课题的需求,因此自行收集并制作一个全新的数据集。我通过爬虫技术从各大电影票务平台、社交媒体和专业影评网站爬取了热映电影的相关数据,包括电影名称、上映时间、票房、评分、观众评论等信息。随后,我对这些数据进行了清洗和预处理,去除了重复、无效和异常的数据,确保了数据的质量和准确性。为了丰富数据集的维度和深度,我还对部分数据进行了手动标注和分类。最终,我得到了一个包含多维度、高质量热映电影信息的自制数据集。
url = "https://example.com"
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
data = []
titles = soup.select(".title")
links = soup.select(".link")
for title, link in zip(titles, links):
title_text = title.get_text()
link_href = link["href"]
data.append({"标题": title_text, "链接": link_href})
df = pd.DataFrame(data)
print(df)系统实验
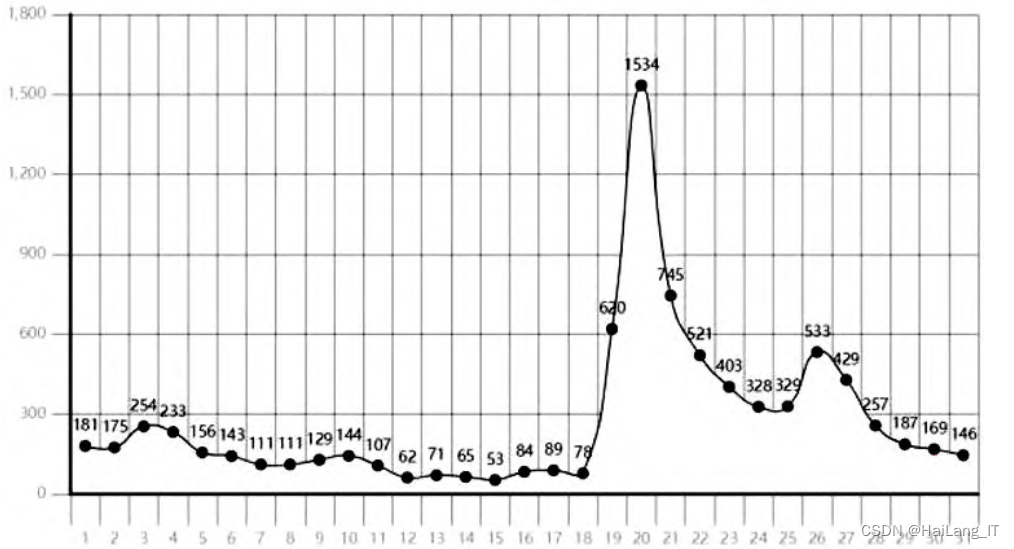
通过对电影上映后的评论量和票房变化进行分析,可以发现评论量与票房的起伏主要集中在电影上映的第一个月。评论量的变化可以反映人们对电影的关注度,而票房的变化则反映观众对电影的喜好和观影热度。通过对国内外上映首月的评论量和票房进行简单比较,可以进一步了解评论量和票房之间的联系。使用Python中的pandas库和pyecharts库可以方便地导入数据并绘制图表,以便更直观地展示评论量和票房的变化趋势。
热力图是一种可视化工具,用于展示数据在不同维度上的密度和分布情况,以色彩的深浅来表示数值的大小。热力图的主要意义在于帮助观察者从大量数据中快速发现模式、趋势和异常值,并从中提取有用的信息。生成热力图的方式通常涉及以下步骤:首先,将数据转换为二维矩阵形式,其中行和列表示不同的维度;然后,根据数据的数值大小,为每个数据点分配相应的颜色深浅;最后,使用可视化工具将矩阵渲染为色彩丰富的热力图。通过这种方式,热力图能够直观地展示数据的分布情况,帮助观察者更好地理解和分析数据。
词云图是一种以视觉化形式展示文本数据的工具,通过词语的频率或重要性来确定词语在图中的大小,并使用不同的颜色和字体样式进行表现。词云图的主要意义在于帮助观察者快速了解文本数据中的关键词和主题,并从中提取有用的信息。生成词云图的方式通常包括以下步骤:首先,收集文本数据,可以是文章、评论、社交媒体数据等;然后,对文本进行预处理,如分词、去除停用词和标点符号等;接下来,计算词语的频率或权重,常用的方法有词频统计、TF-IDF等;最后,使用可视化工具将词语按照频率或权重进行排列,并根据词语的重要性确定其在图中的大小和样式。通过这种方式,词云图能够直观地展示文本数据中的关键词和主题,帮助观察者更好地理解和分析文本内容。

相关代码示例:
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 读取文本数据
text_data = pd.read_csv("text_data.csv") # 替换为实际的文本数据文件路径
# 对文本进行预处理,如分词、去除停用词和标点符号等
# 计算词语的频率或权重
word_frequencies = {} # 词语频率字典,用于记录每个词语的出现次数
# 遍历文本数据,统计词语频率
for text in text_data:
# 预处理文本,如分词、去除停用词和标点符号等
# 统计词语频率
for word in text.split():
if word in word_frequencies:
word_frequencies[word] += 1
else:
word_frequencies[word] = 1
# 创建词云对象
wordcloud = WordCloud()
# 生成词云图
wordcloud.generate_from_frequencies(word_frequencies)
# 设置词云图的参数
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
# 显示词云图
plt.show()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









