







 本文介绍了如何利用深度学习技术,特别是卷积神经网络、LSTM和Dropout算法,设计一个聊天机器人。详细探讨了数据集的构建与扩充,包括自定义数据集和数据扩充技术。文章还展示了实验环境的搭建和模型训练的过程,旨在提高聊天机器人的自然语言理解和生成能力。
本文介绍了如何利用深度学习技术,特别是卷积神经网络、LSTM和Dropout算法,设计一个聊天机器人。详细探讨了数据集的构建与扩充,包括自定义数据集和数据扩充技术。文章还展示了实验环境的搭建和模型训练的过程,旨在提高聊天机器人的自然语言理解和生成能力。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的聊天机器人设计
课题背景和意义
随着人工智能技术的快速发展,聊天机器人成为了人机交互的重要组成部分。传统的聊天机器人往往受限于规则和模板,无法进行灵活的对话和语义理解。基于深度学习的聊天机器人设计成为了一个具有挑战性和创新性的研究课题。该系统可以利用深度学习算法来模拟人类对话过程,实现自然语言理解和生成,提供更智能、更自然的对话体验。通过研究和设计基于深度学习的聊天机器人,可以推动人工智能技术在对话领域的应用,提升人机交互的效果和体验,为用户提供更加智能化的服务。
实现技术思路
一、 算法理论技术
1.1 卷积神经网络
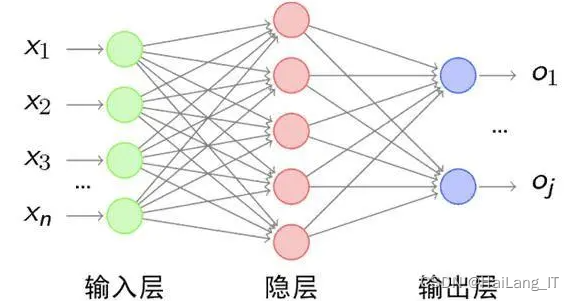
卷积神经网络(CNN)是一种深度学习的神经网络模型,其网络结构是深层神经网络,并且训练数据多为大规模有标签的数据集。在图像识别方面,CNN取得了显著的进展。它最早由Hubel和Wiesel提出,经过五十年的发展,已经可以利用GPU做更高效的训练,预测的精准度也得到大幅提升。CNN通常由输入层、卷积层、池化层、激励层、全连接层和输出层组成,可以从足够多的训练数据中学习出以二维向量为输入的、具有抽象特征的图像特征。卷积层是卷积神经网络的关键,通过权重共享的方法将每一层做输入与权重的卷积计算。与传统神经网络相比,这样的结构不仅减少了传统全连接所需的巨大参数数量,降低了计算量,同时也实现了局部感知。
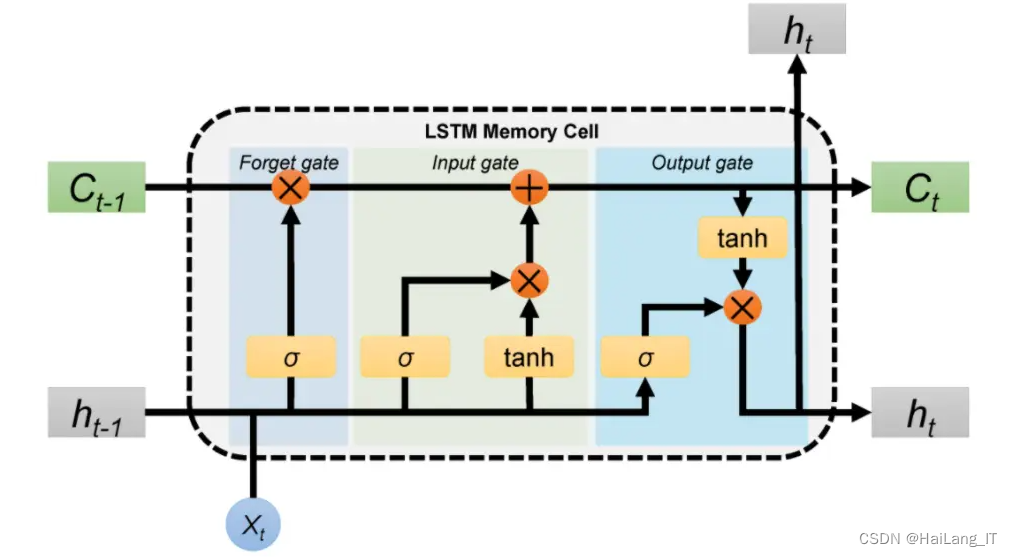
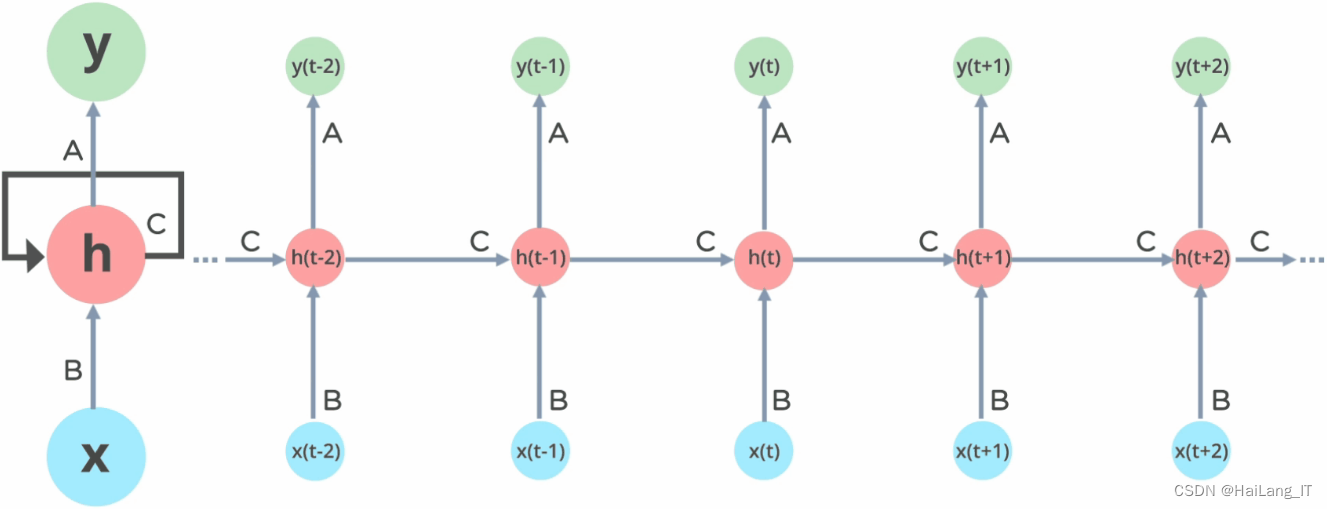
长短期记忆神经网络(LSTM)是一种特殊的循环神经网络(RNN),用于处理序列数据并解决传统RNN中的长期依赖问题。LSTM通过引入称为"记忆单元"的结构来实现这一目标。每个记忆单元具有三个关键组件:输入门、遗忘门和输出门。输入门负责决定是否将新的输入信息存储到记忆单元中。遗忘门决定是否从记忆单元中删除先前的信息。输出门则控制着从记忆单元中提取的信息。这些门结构通过学习得到的权重来决定信息的流动。相比于传统的RNN,LSTM能够更好地捕捉和保留长期依赖的信息,因此在处理需要记忆和理解上下文关系的任务上表现更好。它在自然语言处理、语音识别、机器翻译等领域取得了显著的成果。
1.2 自然语言处理
自然语言处理(NLP)是人工智能领域的重要分支,涉及处理和理解人类语言的计算机技术。关键技术包括词法分析、句法分析、语义分析、机器翻译、信息检索、文本分类和情感分析、问答系统以及文本生成。这些技术在各个领域得到广泛应用,如智能助理、机器翻译、情感分析、智能搜索和智能客服等。通过NLP,计算机可以处理和理解人类语言,使其能够更好地与人类进行交互、理解和生成自然语言文本,为人们提供更智能、便捷和个性化的服务和体验。

自然语言处理技术中的语言模型用于计算一个序列的联合概率,以判断其是否符合人类的自然语言表达。语言模型是自然语言处理、语义识别、断句、语义分析和语义理解等任务的基础。它分为一元模型和N元模型。这些模型用于预测给定一个序列,判断其是否是完整且正确的字符串的概率。语言模型可以用于自动纠错、文本生成、机器翻译、语音识别和对话系统等任务。通过学习大量文本数据,语言模型能够捕捉到词汇之间的概率关系和上下文信息,从而能够生成具有语法正确性和语义连贯性的文本。它为计算机理解和生成自然语言提供了重要的基础和工具。
1.3 Dropout算法
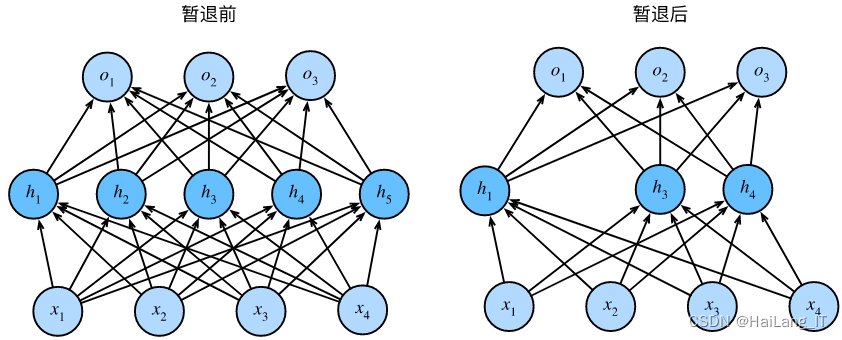
Dropout是一种用于深度学习模型中的正则化技术。它在训练过程中随机地将一部分神经元的输出设置为零(丢弃),以减少过拟合的风险。在神经网络中,每个神经元都会以一定的概率被“丢弃”。这意味着在每个训练样本的前向传播过程中,被丢弃的神经元不会对输出产生任何贡献。这种随机性迫使网络中的其他神经元更好地合作和学习,减少了神经元之间过度依赖的情况。
由于RNN具有时间序列的特性,直接在RNN层后面添加Dropout层可能会破坏时间信息的流动。因此,在RNN中,通常在每个时间步(时间序列的每个单元)应用Dropout。这意味着在每个时间步中,RNN的输入和输出都会被随机地丢弃一部分。这有助于减少RNN中的过拟合问题。
二、 数据集
2.1 数据集
由于网络上没有现有的合适的数据集,我决定自己去收集数据并制作一个全新的数据集。我使用了多种渠道和方式,包括网络爬取、用户调查和实地采集,收集了大量的对话数据。这些对话数据涵盖了不同领域、不同主题和不同语境下的对话,以及用户的真实语言表达。通过收集真实对话数据,我能够构建一个更贴近实际场景的数据集,为聊天机器人的训练和评估提供更准确、可靠的数据。我相信这个自制的数据集将为基于深度学习的聊天机器人设计和研究提供有力的支持,并为该领域的发展做出积极贡献。
2.2 数据扩充
为了增加数据集的丰富性和多样性,我采用了数据扩充技术。通过应用自然语言处理和文本生成算法,我对原始对话数据进行了扩充。这包括对对话进行语义变换、语法转换和情感生成等处理,生成了更多的对话样本。此外,我还使用了数据增强技术,如对话重组、对话合成和对话插入等方法,来生成更多的训练样本。通过数据扩充,能够更全面地训练和评估基于深度学习的聊天机器人设计,使其在不同对话场景和应用中表现更为鲁棒和灵活。
# 数据扩充函数:随机替换文本中的某些单词
def augment_data(text, n_replacements):
words = word_tokenize(text)
augmented_texts = []
for _ in range(n_replacements):
augmented_words = words.copy()
# 随机选择要替换的单词
word_index = random.randint(0, len(augmented_words) - 1)
# 随机生成替换的单词
augmented_words[word_index] = '替换词'
augmented_text = ' '.join(augmented_words)
augmented_texts.append(augmented_text)
return augmented_texts
# 扩充数据
augmented_texts = []
augmented_labels = []
for text, label in zip(train_texts, train_labels):
# 对每个样本进行扩充,生成3个新样本
augmented = augment_data(text, 3)
augmented_texts.extend(augmented)
augmented_labels.extend([label] * len(augmented))
三、实验及结果分析
3.1 实验环境搭建
在Windows系统下,使用Python的gensim库中的Word2Vec模型进行训练,使用收集和提取的运动类领域的中文语料库。Word2Vec模型的参数设置如下:词向量维度为100,训练窗口大小为8,最小词频为5,负采样设为10,负样本数为20。通过这些设置,可以训练一个具有丰富语义表示的运动领域中文词向量模型。
3.2 模型训练及结果分析
传统方法中,仅使用相邻两行文本作为问答对进行训练,导致语料的丰富性和关联性不足。通过这个改进后的算法生成的新语料库,可以更好地学习更长的句子,并增强同一个话题中前后对话内容的关联性。改进后的算法通过多行文本的组合,增加了问答对的数量和多样性,提高了聊天模型的性能。改进后的算法。算法的具体步骤如下:
- 从原始语料文件开始读取每一行,如果该行内容为"L",则将列表"group"添加到列表"group_s"中,并跳转到步骤4。
- 对行内容进行正则化匹配,包括符号的统一、特殊符号的删除以及小行长度阈值内内容的过滤。
- 将正则化后的行以句号分割,并将短句添加到"group"列表中。
- 读取下一行,如果下一行不为空,则跳转到步骤1。
- 遍历"group_s"列表,取出"group"列表,并遍历结束后跳转到步骤10。
- 遍历"group"列表,按索引i读取,分别取出索引i、i+1、i+2的内容存入e、next_line、next_next_line,遍历结束后跳转到步骤5。
- 将line存入x_data列表中,将next_line存入y_data列表中。
- 将"]ine"存入x_data列表中,将next_line和next_next_line用逗号拼接后存入y_data列表中。
- 将line和next_line用逗号拼接后存入x_data列表中,将next_next_line存入y_data列表中。
- 返回x_data、y_data。
- 结束。
相关代码示例:
import re
def improve_dialogue_corpus(input_file):
group_s = []
group = []
x_data = []
y_data = []
with open(input_file, 'r') as f:
for line in f:
if line.strip() == 'L':
group_s.append(group)
group = []
continue
line = re.sub('[^a-zA-Z0-9\s\.\,\;\:\!\?]+', '', line)
line = re.sub('\s+', ' ', line)
if len(line) < 5:
continue
sentences = line.split('.')
group.extend(sentences)
group_s.append(group)
for group in group_s:
for i in range(len(group) - 2):
line = group[i]
next_line = group[i + 1]
next_next_line = group[i + 2]
x_data.append(line)
y_data.append(next_line)
x_data.append(']ine')
y_data.append(next_line + ',' + next_next_line)
x_data.append(line + ',' + next_line)
y_data.append(next_next_line)
return x_data, y_data
# Example usage
input_file = 'dialogue_corpus.txt'
x_data, y_data = improve_dialogue_corpus(input_file)Word2Vec模型在实际语料库训练后的效果分析。Word2Vec模型的分析可以通过两种方式进行:一种是将其作为模型的输入来完成自然语言处理任务,另一种是考察训练后词向量的语言学特性,如词义相似度等。 从这两个方面对改进模型进行了分析,将模型应用于文本分类系统,并通过分类结果的指标评估训练词向量的质量,同时查询词语的一系列相关词,通过词义相关性的指标评估模型的效果。经过Word2Vec的多种模型训练得到的词向量作为BP神经网络的输入进行文本分类训练,并通过预测分类结果评估模型的训练效果。
对每个文本进行分词处理,并去除停用词,经过Word2Vec训练后得到的词向量(100维)相加并进行平均处理,得到该文本的语义向量表示,这些向量既包含了该文本的语义信息,同时也可以作为分类模型的输入。其次,将文本的表示向量作为BP神经网络的输入,经过隐藏层的计算后传递给输出层,并连接一个Softmax全连接层,输出最后的分类结果。其中,隐藏层节点个数为50个,输出层节点个数为2,输出结果为标签0,标签1,采用梯度下降算法更新网络的权值和阈值,使用交叉验证的方式进行训练。对最终输出的结果进行准确率、召回率和F1值的计算。
相关代码示例:
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 读取语料库并进行分词处理
sentences = LineSentence('corpus.txt')
tokenized_sentences = [sentence.split() for sentence in sentences]
# 训练Word2Vec模型
model = Word2Vec(tokenized_sentences, size=100, window=8, min_count=5, negative=10, sg=1)
# 保存模型
model.save('word2vec_model.bin')
# 加载模型
model = Word2Vec.load('word2vec_model.bin')
# 获取训练得到的词向量
word_vectors = model.wv
# 构建文本的语义向量表示
def text_to_vector(text):
words = text.split()
vector = sum([word_vectors[word] for word in words if word in word_vectors])
return vector / len(words)
最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









