







 本文介绍了基于深度学习的推土机识别系统的开发,重点讲解了YOLOv5目标检测算法和LRCN视频分类技术的应用,包括数据集的构建、数据扩充策略以及实验环境和模型训练的详细步骤。
本文介绍了基于深度学习的推土机识别系统的开发,重点讲解了YOLOv5目标检测算法和LRCN视频分类技术的应用,包括数据集的构建、数据扩充策略以及实验环境和模型训练的详细步骤。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的推土机识别系统
课题背景和意义
在建筑工程和土方工程中,推土机是一种重要的土方施工机械。为了实现对推土机的高效、准确识别,提高施工现场的安全性和效率,基于深度学习的推土机识别系统应运而生。该系统利用深度学习算法,通过对图像和视频的处理,实现对推土机的自动检测和识别。这不仅有助于实时监控施工现场的推土机作业情况,还可以为土方工程的自动化管理提供有力支持。
实现技术思路
一、算法理论基础
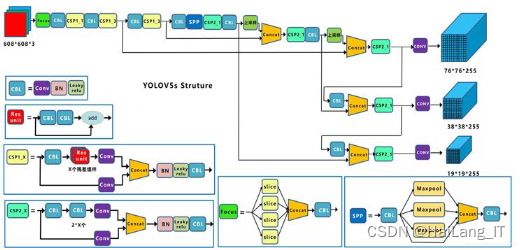
1.1 YOLOv5
YOLOv5是一种用于图像识别的目标检测算法,它在官方代码中提供了四个版本:s、m、l、x。这些版本的网络深度和特征图宽度不同,其中YOLOv5s是深度和特征图宽度最小的版本。其他版本在YOLOv5s的基础上进行了进一步的优化,以提高性能和准确度。
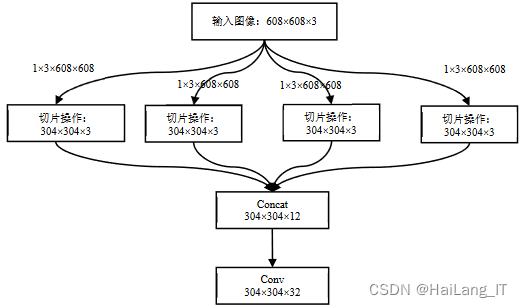
YOLOv5引入了独创的网络结构,即Focus模块。该模块在网络框架中的计算流程如下:假设输入图像大小为608×608×3,通过切片操作,将输入图像按每隔一个像素取一个值的方式,得到四组尺寸为304×304×3的特征图。然后,将这四组特征图通过concat连接起来,使得特征图的维度变为304×304×12。最后,经过卷积操作输出最终的特征图,大小为304×304×32。
整个操作流程类似于下采样,尽管Focus模块的切片操作会稍微增加计算量,但它可以提取更深层的特征,更充分地利用图像信息。这样的设计使得YOLOv5能够更好地捕捉图像中的细节和上下文信息,从而提高目标检测的准确性和性能。
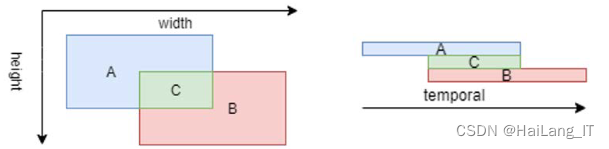
1.2 交并比
在图像识别中,IoU是评估模型识别性能的重要指标。它是一个二维的度量,用于衡量预测框与真实框之间的重叠程度。IoU的计算公式为两者交集的面积除以并集的面积,其中A表示真实框,B表示预测框,C表示它们的重叠区域。通过计算IoU,我们可以评估预测框与真实框之间的匹配程度,从而衡量模型的准确性和召回率。在视频分类中,IoU同样是评估模型性能的指标,但它是一维的。在视频分类中,IoU用于衡量预测动作标签与真实动作标签之间的重叠程度。图中的示意图展示了IoU的计算方式,其中A表示真实动作标签,B表示预测动作标签,C表示它们在时间上的重叠。

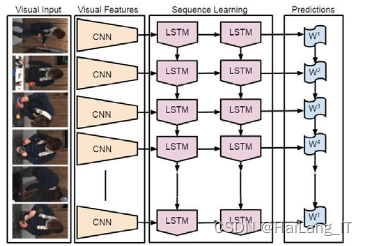
1.3目标检测算法
LRCN是一种网络模型,用于视频分类任务。首先输入连续的多帧图片,并利用AlexNet网络提取这些图片的空间特征信息。然后,通过LSTM神经网络对这些空间特征信息进行时间维度的关联,以捕捉视频中的时序信息和长期依赖关系。最后,使用softmax函数对每个LSTM单元的输出结果进行归一化处理,并求取均值,从而实现对视频中单个动作或动作组合的预测。
LRCN模型的核心思想是将卷积神经网络(CNN)和循环神经网络(RNN)相结合,以同时利用空间特征和时序信息来进行视频分类。通过使用CNN提取空间特征和LSTM建立时间关联,LRCN能够对视频中的动作进行准确预测。最后,通过对LSTM输出结果的归一化和求均值,可以得到对视频中动作的整体预测结果。
LSTM单元在LRCN模型中的添加为提取时序特征信息提供了优势。与传统的BP算法和CNN相比,它们只能考虑前一个输入的影响,对于相同状态目标的识别效果较好。然而,在涉及时间序列信息的处理中,缺乏"记忆"功能的网络结构只能逐个处理单个输入向量。这对于包含有具体含义的时序信息的处理来说是不够的,因为多种可能的组合可能会干扰视频的分类结果,从而影响识别的准确率。
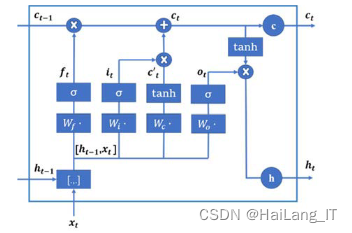
RNN模型通过添加隐藏状态来记忆前述信息,并将其应用于当前特征信息的计算处理中,可以处理一定范围内的时间序列信息,并取得良好的识别效果。然而,对于长周期时序信息的处理,训练过程可能会出现梯度爆炸或消失的问题。为了解决这个问题,研究者引入了存储器单元,设计了基于LSTM单元的网络结构。
LSTM单元的添加在LRCN模型中提取时序特征信息方面具有优势。通过引入存储器单元,LSTM能够记忆和利用历史信息,并有效处理长周期时序信息,提高了模型在视频分类任务中的准确率和性能。
二、 数据集
2.1 数据集
为了实现基于深度学习的推土机识别系统,我们首先需要构建一个高质量的推土机数据集。由于推土机在施工现场的作业环境复杂,且不同型号的推土机外观差异较大,数据收集存在一定的难度。为了解决这个问题,我们采用了多种途径收集数据,包括从施工现场实地拍摄、网络搜索和公开数据集等。在数据收集过程中,我们注重数据的多样性和标注准确性,尽量涵盖不同型号、不同作业场景和不同光照条件下的推土机图像。为了提高模型的泛化能力,我们还采用了数据扩充技术,如旋转、缩放、平移、亮度调整等,对原始图像进行变换,生成更多的推土机图像。

2.2 数据扩充
在推土机识别系统中,数据扩充同样扮演着关键角色。通过对原始推土机图像进行旋转、缩放、平移等操作,我们可以模拟不同角度、距离和光照条件下的推土机外观变化,从而增加数据集的多样性和规模。此外,我们还可以采用数据增强技术,如添加噪声、模糊处理等,来进一步提高模型的鲁棒性。这些扩充和增强操作有助于模型更好地泛化到实际施工现场中,实现对推土机的准确识别和实时检测。同时,为了支持结果的可视化和导出,我们还可以将检测结果以图片或视频的形式展示出来,方便用户进行进一步的分析和处理。

相关代码示例:
def add_noise(image, noise_level):
# 生成均值为0、标准差为noise_level的高斯噪声
noise = np.random.normal(0, noise_level, image.shape)
noisy_image = image + noise
# 将像素值限制在0到255之间
noisy_image = np.clip(noisy_image, 0, 255).astype(np.uint8)
return noisy_image
def apply_blur(image, kernel_size):
# 使用高斯模糊进行图像模糊处理
blurred_image = cv2.GaussianBlur(image, (kernel_size, kernel_size), 0)
return blurred_image
# 读取原始图像
image = cv2.imread('image.jpg')
# 添加噪声
noisy_image = add_noise(image, noise_level=30)
# 进行模糊处理
blurred_image = apply_blur(image, kernel_size=5)
三、实验及结果分析
3.1 实验环境搭建
改进后的LRCN算法使用ResNet-34网络模型提取视频样本的空间特征,并使用GRU网络对这些特征进行时序关系的建模。算法首先将视频样本转化为帧率为25帧/秒的视频帧序列,然后将帧尺寸归一化为256×256像素大小。接着,将连续的每20帧作为训练输入,对视频进行分段处理。模型使用标签平滑交叉熵损失函数进行训练,优化器采用Adam,初始学习率设置为0.001,Dropout率为0.5,batch-size为16,epoch为100。
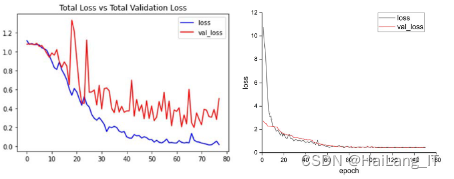
3.2 模型训练
改进后的YOLOv5算法在数据集上进行预训练,并使用Focal loss作为损失函数。预训练完成后,进行迁移学习。总共设置150个epoch进行训练,其中前50个epoch冻结模型的主干,并使用批量大小为32,后100个epoch解冻模型主干,并使用批量大小为16,以防止模型过拟合,确保模型训练充分。
相关代码示例:
# 构建YOLOv5模型
model = YOLOv5()
# 预训练
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
scheduler = CosineAnnealingLR(optimizer, T_max=pretrain_epochs)
criterion = FocalLoss()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.train()
for epoch in range(pretrain_epochs):
total_loss = 0.0
for images, targets in train_loader:
images = images.to(device)
targets = targets.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
total_loss += loss.item()
scheduler.step()
print(f"Epoch {epoch+1}/{pretrain_epochs}, Loss: {total_loss/len(train_loader)}")
# 保存预训练权重
torch.save(model.state_dict(), pretrain_checkpoint)
# 迁移学习
fine_tune_dataset = CocoDetection(root='coco/train2017', annFile='coco/annotations/instances_train2017.json', transform=transform)
fine_tune_loader = DataLoader(fine_tune_dataset, batch_size=fine_tune_batch_size, shuffle=True, num_workers=4)海浪学长项目示例:





最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









