







文章目录
Kafka的应用场景
- 异步处理
- 系统解耦
- 流量削峰
- 日志处理
消息队列的两种模型
- 消息队列的模式
-
点对点:一个消费者消费一个消息
- 消息发送者生产消息发送到消息队列中,然后消息接收者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中)
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
-
发布订阅:多个消费者可以消费一个消息
- 每个消息可以有多个订阅者;
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
-
Kafka中的重要概念
- broker
- Kafka服务器进程,生产者、消费者都要连接broker
- 一个集群由多个broker组成,功能实现Kafka集群的负载均衡、容错
- producer:生产者
- consumer:消费者
- topic:主题,一个Kafka集群中,可以包含多个topic。一个topic可以包含多个分区
- 是一个逻辑结构,生产、消费消息都需要指定topic
- Kafka中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制
- 一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
- partition:Kafka集群的分布式就是由分区来实现的。一个topic中的消息可以分布在topic中的不同partition中
- replica:副本,实现Kafkaf集群的容错,实现partition的容错。一个topic至少应该包含大于1个的副本
- consumer group:消费者组,一个消费者组中的消费者可以共同消费topic中的分区数据。每一个消费者组都一个唯一的名字。配置group.id一样的消费者是属于同一个组中
- offset:偏移量。相对消费者、partition来说,可以通过offset来拉取数据
- offset记录着下一条将要发送给Consumer的消息的序号
- 默认Kafka将offset存储在ZooKeeper中
- 在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset
- 偏移量在分区中才是有意义的。在分区之间,offset是没有任何意义的
消费者组
- 一个消费者组中可以包含多个消费者,共同来消费topic中的数据
- 一个topic中如果只有一个分区,那么这个分区只能被某个组中的一个消费者消费
- 有多少个分区,那么就可以被同一个组内的多少个消费者消费
幂等性
-
生产者消息重复问题
- Kafka生产者生产消息到partition,如果直接发送消息,kafka会将消息保存到分区中,但Kafka会返回一个ack给生产者,表示当前操作是否成功,是否已经保存了这条消息。如果ack响应的过程失败了,此时生产者会重试,继续发送没有发送成功的消息,Kafka又会保存一条一模一样的消息
-
在Kafka中可以开启幂等性
- 当Kafka的生产者生产消息时,会增加一个
pid(生产者的唯一编号)和sequence number(针对消息的一个递增序列) - 发送消息,会连着
pid和sequence number一块发送 - kafka接收到消息,会将消息和
pid、sequence number一并保存下来 - 如果ack响应失败,生产者重试,再次发送消息时,Kafka会根据pid、
sequence number是否需要再保存一条消息 - 判断条件:生产者发送过来的
sequence number是否小于等于partition中消息对应的sequence,小于等于则不接受 - 配置幂等:
props.put("enable.idempotence",true);
- 当Kafka的生产者生产消息时,会增加一个
zookeeper
- ZK用来管理和协调broker,并且存储了Kafka的元数据(例如:有多少topic、partition、consumer)
- ZK服务主要用于通知生产者和消费者Kafka集群中有新的broker加入、或者Kafka集群中出现故障的broker。
事务消息
Kafka事务指的是生产者生产消息以及消费者提交offset的操作可以在一个原子操作中,要么都成功,要么都失败。尤其是在生产者、消费者并存时,事务的保障尤其重要(consumer-transform-producer模式)。
事务操作API
Producer接口中定义了以下5个事务相关方法:
- initTransactions(初始化事务):要使用Kafka事务,必须先进行初始化操作
- beginTransaction(开始事务):启动一个Kafka事务
- sendOffsetsToTransaction(提交偏移量):批量地将分区对应的offset发送到事务中,方便后续一块提交
- commitTransaction(提交事务):提交事务
- abortTransaction(放弃事务):取消事务
生产者分区写入策略
生产者写入消息到topic,Kafka将依据不同的策略将数据分配到不同的分区中
- 轮询分区策略
- 随机分区策略
- 按key分区分配策略
- 自定义分区策略
轮询策略
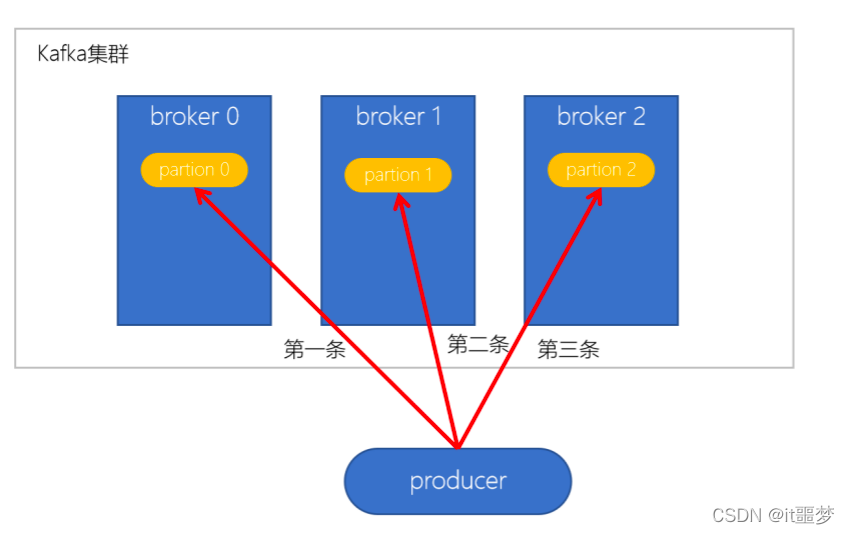
- 默认的策略,也是使用最多的策略,可以最大限度保证所有消息平均分配到一个分区
- 如果在生产消息时,key为null,则使用轮询算法均衡地分配分区
随机策略(不用)
随机策略,每次都随机地将消息分配到每个分区。在较早的版本,默认的分区策略就是随机策略,也是为了将消息均衡地写入到每个分区。
按key分配策略
按key写入策略,key.hash() % 分区的数量
自定义分区策略
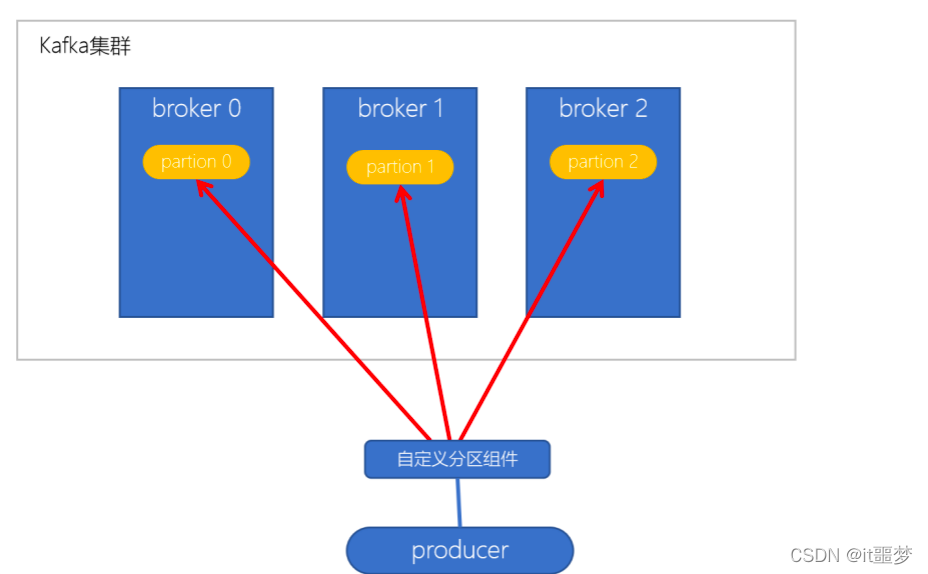
public class KeyWithRandomPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// cluster.partitionCountForTopic 表示获取指定topic的分区数量
return r.nextInt(1000) % cluster.partitionCountForTopic(topic);
}
}
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, KeyWithRandomPartitioner.class.getName());
消费组Consumer Group Rebalance机制
- 再均衡:在某些情况下,消费者组中的消费者消费的分区会产生变化,会导致消费者分配不均匀(例如:有两个消费者消费3个,因为某个partition崩溃了,还有一个消费者当前没有分区要削峰),Kafka Consumer Group就会启用rebalance机制,重新平衡这个Consumer Group内的消费者消费的分区分配。
- 触发时机
- 消费者数量发生变化
- 某个消费者crash
- 新增消费者
- topic的数量发生变化
- 某个topic被删除
- partition的数量发生变化
- 删除partition
- 新增partition
- 消费者数量发生变化
- 不良影响
- 发生rebalance,所有的consumer将不再工作,共同来参与再均衡,直到每个消费者都已经被成功分配所需要消费的分区为止(rebalance结束)
消费者的分区分配策略
分区分配策略:保障每个消费者尽量能够均衡地消费分区的数据,不能出现某个消费者消费分区的数量特别多,某个消费者消费的分区特别少
-
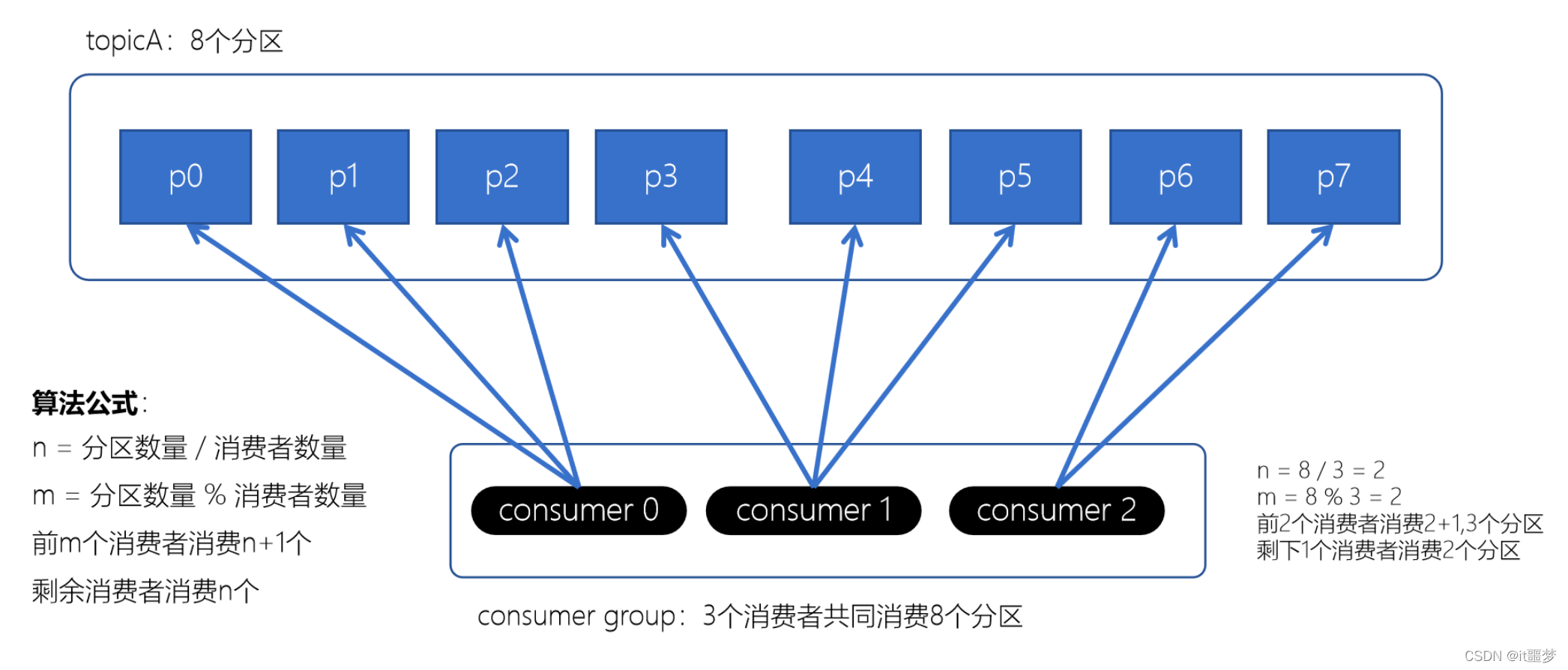
Range分配策略(范围分配策略):
Kafka默认的分配策略- n:分区的数量 / 消费者数量
- m:分区的数量 % 消费者数量
- 前m个消费者消费n+1个分区
- 剩余的消费者消费n个分区
-
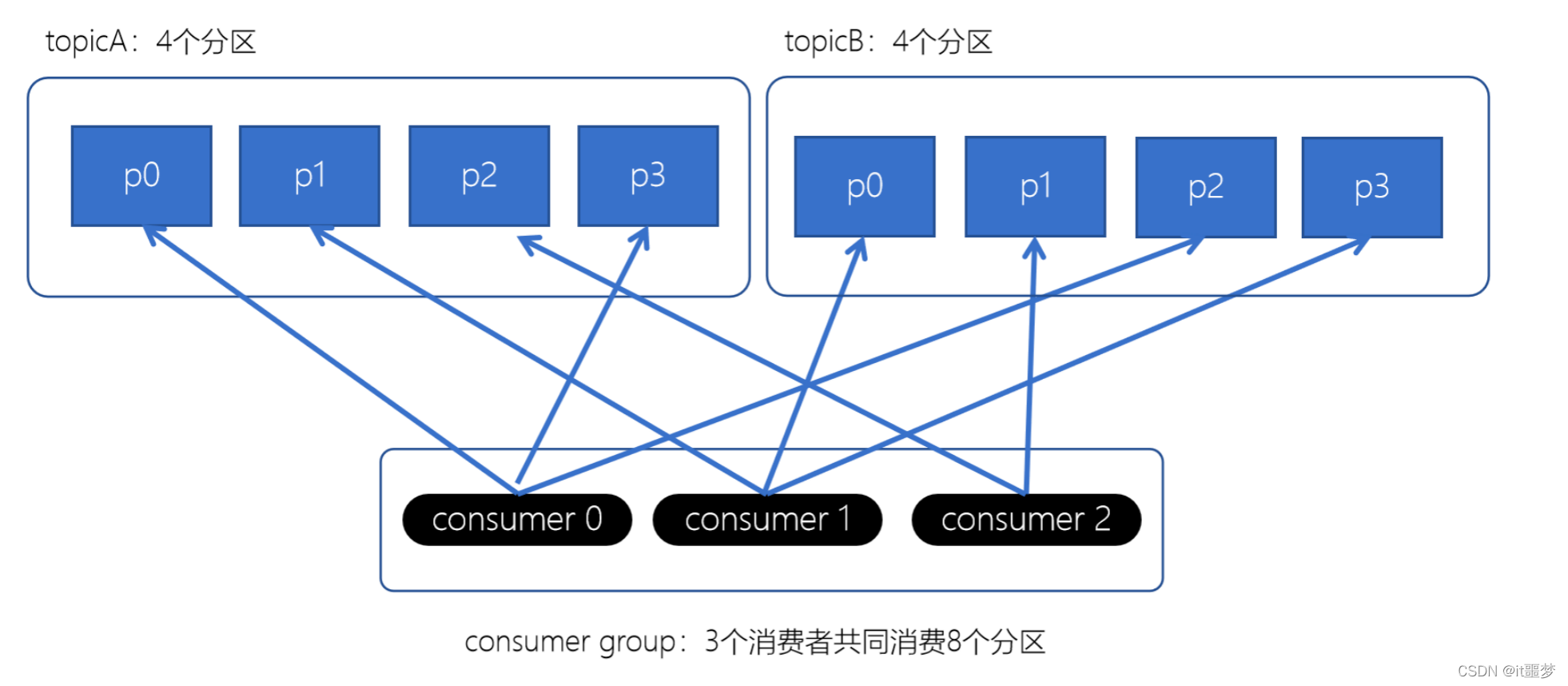
RoundRobin分配策略(轮询分配策略)
- 消费者挨个分配消费的分区
- Striky粘性分配策略
- 在没有发生rebalance跟轮询分配策略是一致的
- 发生了rebalance,轮询分配策略,重新走一遍轮询分配的过程。而粘性会保证跟上一次的尽量一致,只是将新的需要分配的分区,均匀的分配到现有可用的消费者中即可
- 减少上下文的切换
没有发生rebalance时,Striky粘性分配策略和RoundRobin分配策略类似。
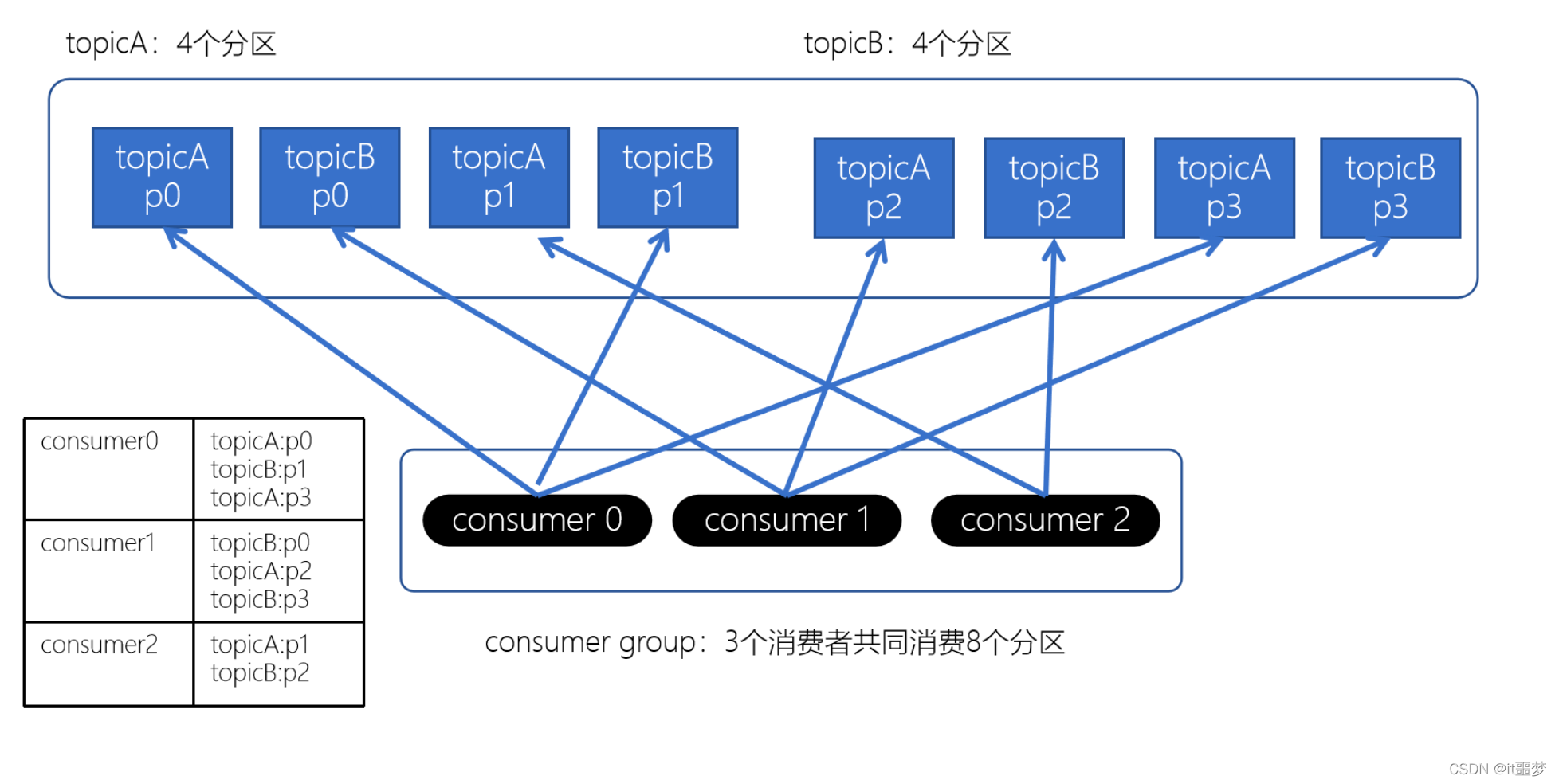
上面如果consumer2崩溃了,此时需要进行rebalance。如果是Range分配和轮询分配都会重新进行分配,例如
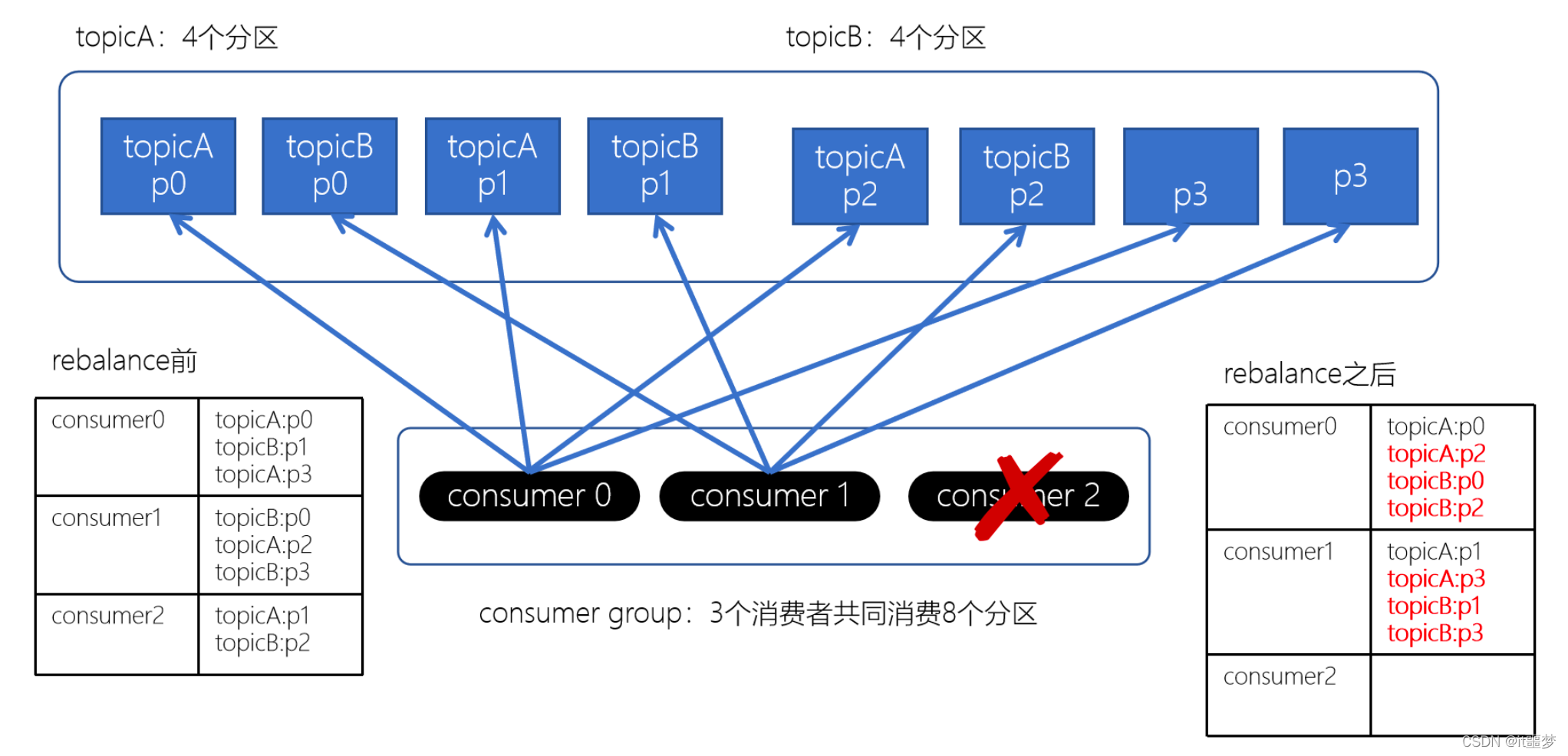
通过上图,我们发现,consumer0和consumer1原来消费的分区大多发生了改变。接下来我们再来看下粘性分配策略。
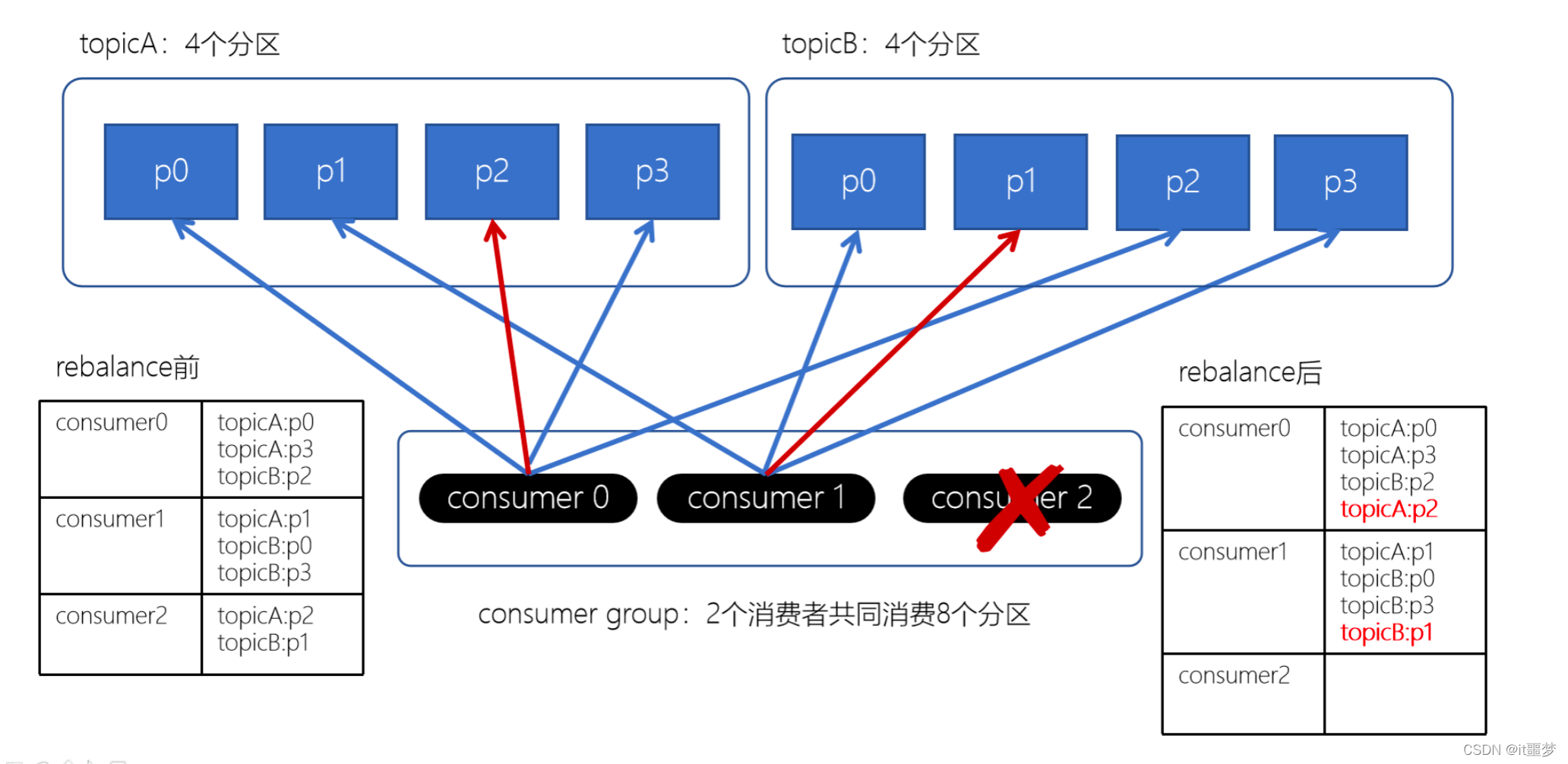
我们发现,Striky粘性分配策略,保留rebalance之前的分配结果。这样,只是将原先consumer2负责的两个分区再均匀分配给consumer0、consumer1。这样可以明显减少系统资源的浪费,例如:之前consumer0、consumer1之前正在消费某几个分区,但由于rebalance发生,导致consumer0、consumer1需要重新消费之前正在处理的分区,导致不必要的系统开销。(例如:某个事务正在进行就必须要取消了)
副本的ACK机制
producer是不断地往Kafka中写入数据,写入数据会有一个返回结果,表示是否写入成功。这里对应有一个ACKs的配置。
- acks = 0:生产者只管写入,不管是否写入成功,可能会数据丢失。性能是最好的
- acks = 1:生产者会等到leader分区写入成功后,返回成功,接着发送下一条
- acks = -1/all:确保消息写入到leader分区、还确保消息写入到对应副本都成功后,接着发送下一条,性能是最差的
根据业务情况来选择ack机制,是要求性能最高,一部分数据丢失影响不大,可以选择0/1。如果要求数据一定不能丢失,就得配置为-1/all。
分区中是有leader和follower的概念,为了确保消费者消费的数据是一致的,只能从分区leader去读写消息,follower做的事情就是同步数据,Backup。
高级API(High-Level API)、低级API(Low-Level API)
- 高级API就是直接让Kafka帮助管理、处理分配、数据
- offset存储在ZK中
- 由kafka的rebalance来控制消费者分配的分区
- 开发起来比较简单,无需开发者关注底层细节
- 无法做到细粒度的控制
- 低级API:由编写的程序自己控制逻辑
- 自己来管理Offset,可以将offset存储在ZK、MySQL、Redis、HBase、Flink的状态存储
- 指定消费者拉取某个分区的数据
- 可以做到细粒度的控制
- 原有的Kafka的策略会失效,需要我们自己来实现消费机制
leader和follower
- Kafka中的leader和follower是相对分区有意义,不是相对broker
- Kafka在创建topic的时候,会尽量分配分区的leader在不同的broker中,其实就是负载均衡
- leader职责:读写数据
- follower职责:同步数据、参与选举(leader crash之后,会选举一个follower重新成为分区的leader
- 注意和ZooKeeper区分
- ZK的leader负责读、写,follower可以读取
- Kafka的leader负责读写、follower不能读写数据(确保每个消费者消费的数据是一致的),Kafka一个topic有多个分区leader,一样可以实现数据操作的负载均衡
AR\ISR\OSR
- AR表示一个topic下的所有副本
- ISR:In Sync Replicas,正在同步的副本(可以理解为当前有几个follower是存活的)
- OSR:Out of Sync Replicas,不再同步的副本
- AR = ISR + OSR
leader选举
-
Controller:controller是kafka集群的老大,是针对Broker的一个角色
- Controller是高可用的,是用过ZK来进行选举
-
Leader:是针对partition的一个角色
- Leader是通过ISR来进行快速选举
-
如果Kafka是基于ZK来进行选举,ZK的压力可能会比较大。例如:某个节点崩溃,这个节点上不仅仅只有一个leader,是有不少的leader需要选举。通过ISR快速进行选举。
-
leader的负载均衡
- 如果某个broker crash之后,就可能会导致partition的leader分布不均匀,就是一个broker上存在一个topic下不同partition的leader
- 通过以下指令,可以将leader分配到优先的leader对应的broker,确保leader是均匀分配的
bin/kafka-leader-election.sh --bootstrap-server node1.itcast.cn:9092 --topic test --partition=2 --election-type preferred
Kafka读写流程
- 写流程
- 通过ZooKeeper找partition对应的leader,leader是负责写的
- producer开始写入数据
- ISR里面的follower开始同步数据,并返回给leader ACK
- 返回给producer ACK
- 读流程
- 通过ZooKeeper找partition对应的leader,leader是负责读的
- 通过ZooKeeper找到消费者对应的offset
- 然后开始从offset往后顺序拉取数据
- 提交offset(自动提交——每隔多少秒提交一次offset、手动提交——放入到事务中提交)
Kafka的物理存储
- Kafka的数据组织结构
- topic
- partition
- segment
- .log数据文件
- .index(稀疏索引)
- .timeindex(根据时间做的索引)
- 深入了解读数据的流程
- 消费者的offset是一个针对partition全局offset
- 可以根据这个offset找到segment段
- 接着需要将全局的offset转换成segment的局部offset
- 根据局部的offset,就可以从(.index稀疏索引)找到对应的数据位置
- 开始顺序读取
消息传递的语义性
Flink里面有对应的每种不同机制的保证,提供Exactly-Once保障(二阶段事务提交方式)
- At-most once:最多一次(只管把数据消费到,不管有没有成功,可能会有数据丢失)
- At-least once:最少一次(有可能会出现重复消费)
- Exactly-Once:仅有一次(事务性性的保障,保证消息有且仅被处理一次)
Kafka的消息不丢失
- broker消息不丢失:因为有副本relicas的存在,会不断地从leader中同步副本,所以,一个broker crash,不会导致数据丢失,除非是只有一个副本。
- 生产者消息不丢失:ACK机制(配置成ALL/-1)、配置0或者1有可能会存在丢失
- 消费者消费不丢失:重点控制offset
- At-least once:一种数据可能会重复消费
- Exactly-Once:仅被一次消费
数据积压
- 数据积压指的是消费者因为有一些外部的IO、一些比较耗时的操作(Full GC——Stop the world),就会造成消息在partition中一直存在得不到消费,就会产生数据积压
- 在企业中,我们要有监控系统,如果出现这种情况,需要尽快处理。虽然后续的Spark Streaming/Flink可以实现背压机制,但是数据累积太多一定对实时系统它的实时性是有说影响的
数据清理&配额限速
- 数据清理
- Log Deletion(日志删除):如果消息达到一定的条件(时间、日志大小、offset大小),Kafka就会自动将日志设置为待删除(segment端的后缀名会以 .delete结尾),日志管理程序会定期清理这些日志
- 默认是7天过期
- Log Compaction(日志合并)
- 如果在一些key-value数据中,一个key可以对应多个不同版本的value
- 经过日志合并,就会只保留最新的一个版本
- Log Deletion(日志删除):如果消息达到一定的条件(时间、日志大小、offset大小),Kafka就会自动将日志设置为待删除(segment端的后缀名会以 .delete结尾),日志管理程序会定期清理这些日志
- 配额限速
- 可以限制Producer、Consumer的速率
- 防止Kafka的速度过快,占用整个服务器(broker)的所有IO资源














 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









