







文章目录
1.1初始认识ByteBuf
ByteBuf主要负责把数据从底层I/O读到ByteBuf,然后传递给应用程序,应用程序处理完成之后再把数据封装成ByteBuf写回I/O。
1.1.1 ByteBuf的基础结构
我们来看netty
* +-------------------+------------------+------------------+
* | discardable bytes | readable bytes | writable bytes |
* | | (CONTENT) | |
* +-------------------+------------------+------------------+
* | | | |
* 0 <= readerIndex <= writerIndex <= capacity
从上面ByteBuf的结构来看,我们发现ByteBuf有三个非常重要的指针,分别是readerIndex(记录读指针开始的位置)、writeIndex(记录写指针的开始位置)、和capacity(缓冲区的总长度)三者的关系是readerIndex <= writerIndex <= capacity。discardable bytes表示是无效的,readable bytes表示可读数据区,writable bytes表示这段数据空闲,可以往里面写数据。
1.1.2 ByteBuf的基本分类
AbstractByteBuf有众多子类,大致可以分为三个维度进行分类,分别如下:
- Pooled:池化内存,就是从预先分配好的内存空间中提取一段连续内存封装成一个ByteBuf,分配给应用程序使用。
- Unsafe:是JDK底层的一个负责I/O操作对象,可以直接获得对象的内存地址,基于内存地址进行读写操作。
- Direct:堆外内存,直接调用JDK底层的API进行物理内存分配,不再JVM的堆内存中,需要手动释放。

1.2 ByteBufAllocator内存管理器
Netty中内存分配有一个顶层的抽象就是ByteBufAllocator,负责分配所有ByteBuf类型的内存。
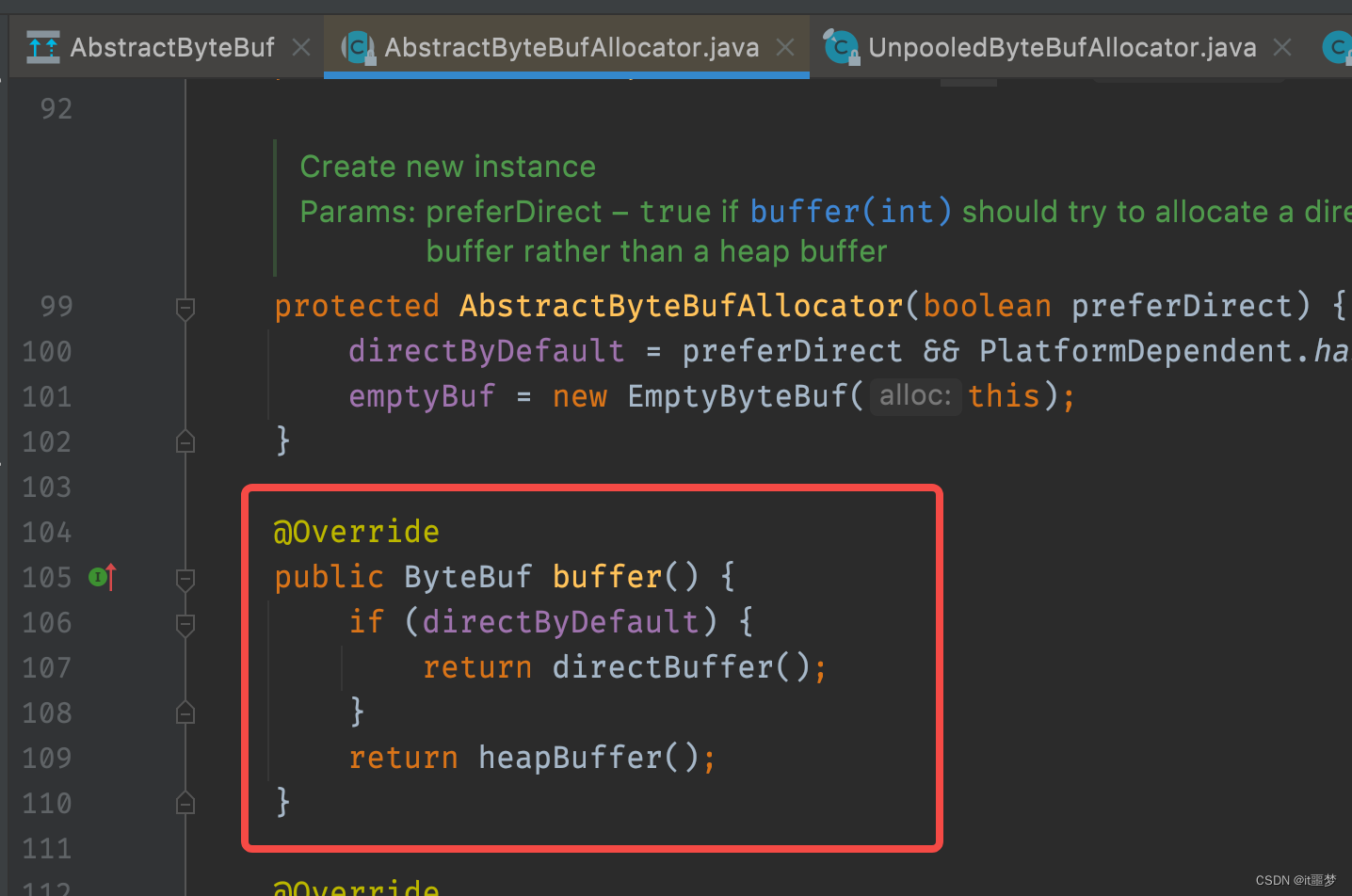
buffer()方法中对是否默认支持directBuffer判断,如果支持则分配directBuffer,否则分配heapBuffer。
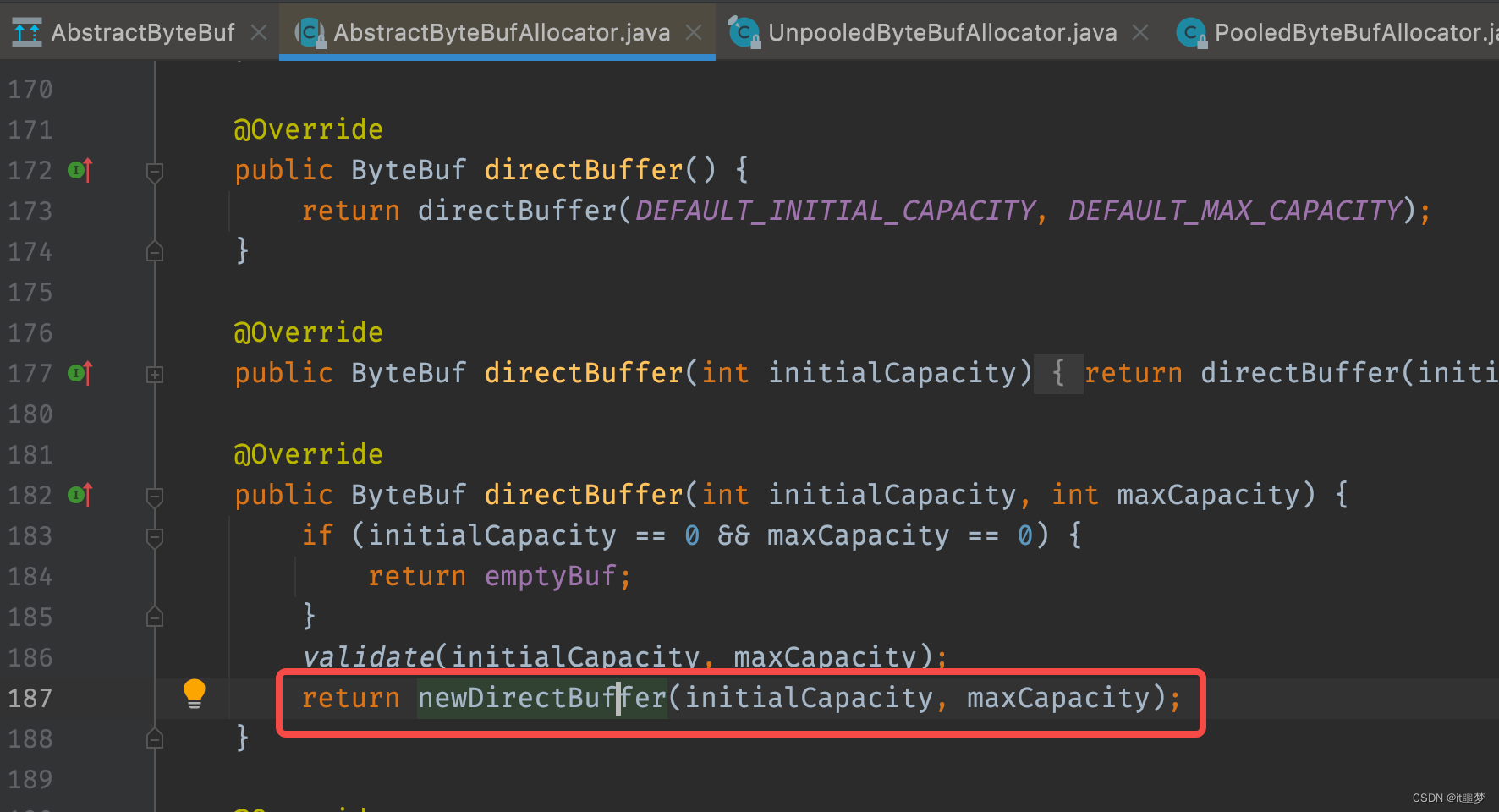
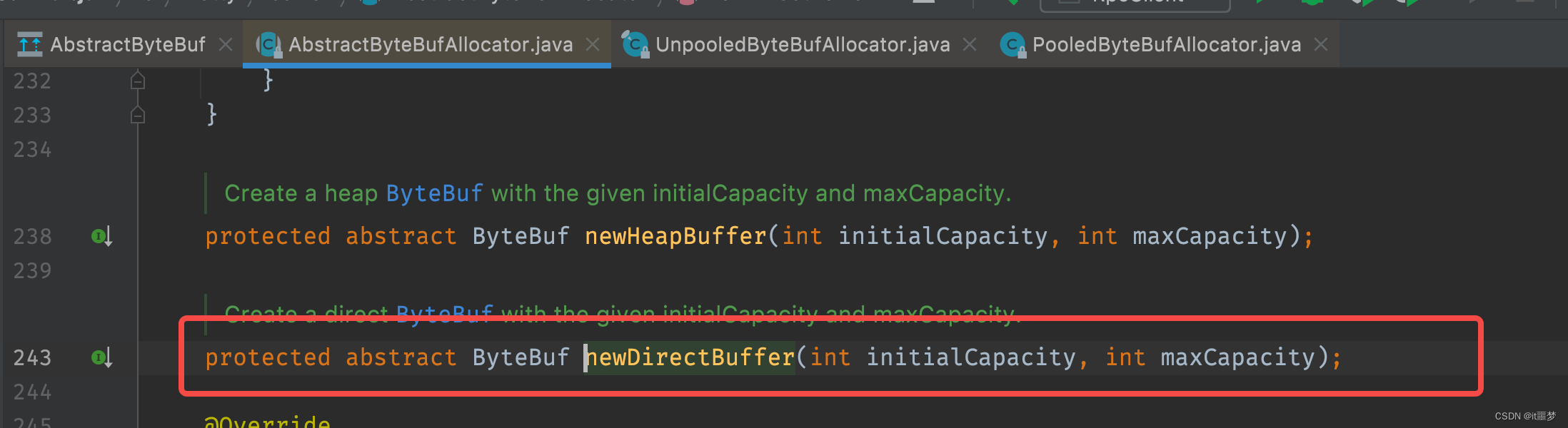
我们发现newDirectBuffer()方法其实是一个抽象方法,最终,交给AbstractByteBufAllocator的子类实现。


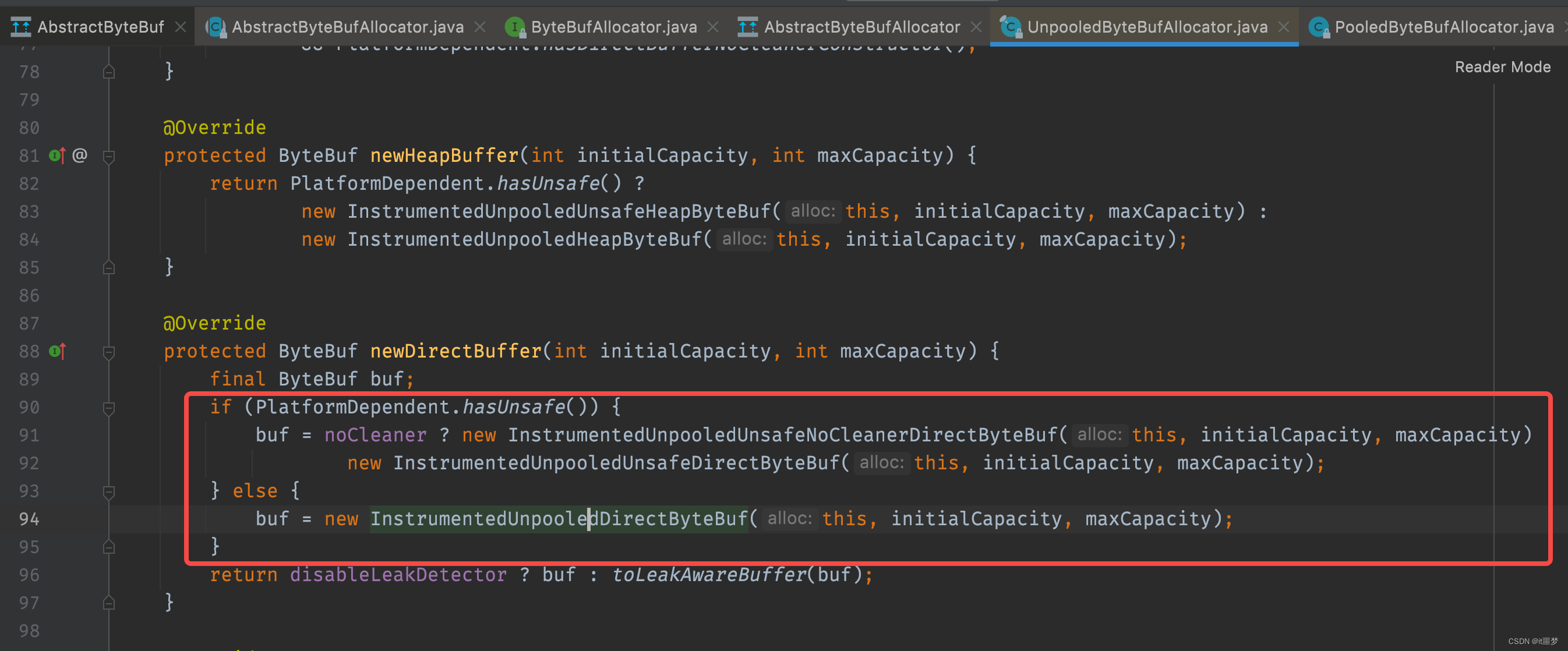
分析到这里,已经知道directBuffer、heapBuffer、和Pooled、Unpooled的分配规则,那么Unsafe和非Unsafe是如何判别的呢?其实是Netty自动判别的,如果操作系统支持Unsafe那就使用Unsafe读写。
1.3 非池化内存分配
1.3.1 堆内内存的分配
现在来看UnpooledByteBufAllocator的分配原理,首先是heapBuffer的分配逻辑,newHeapBuffer()方法代码如下:
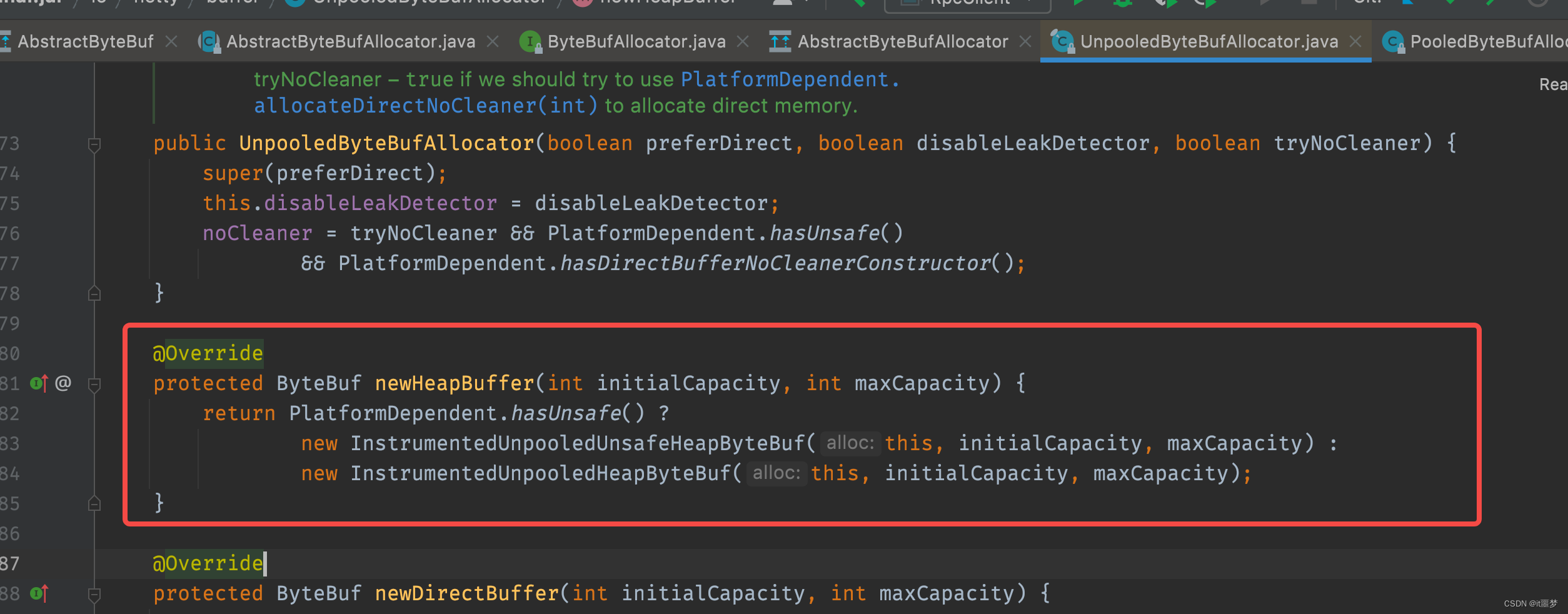
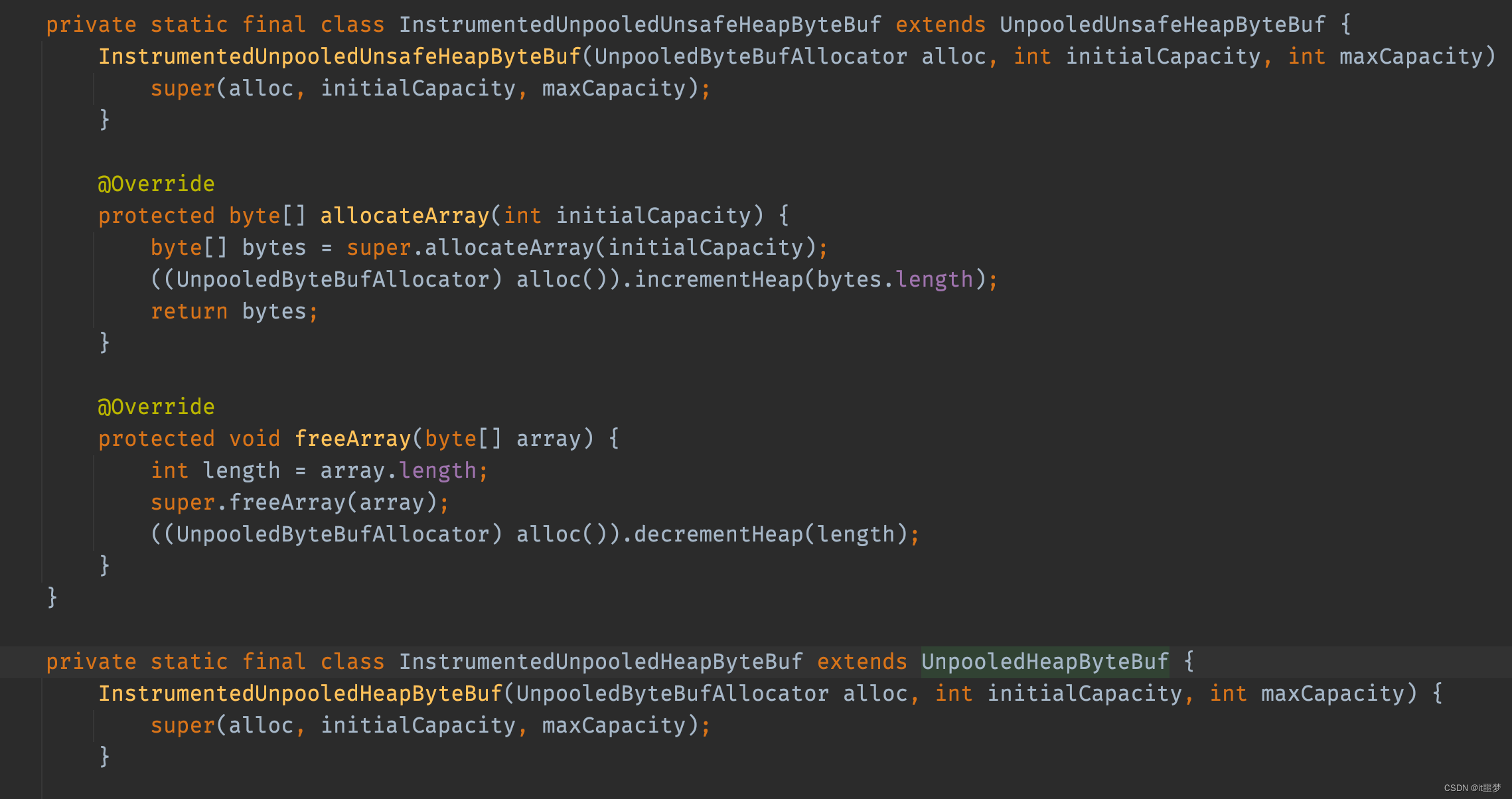
UnpooledUnsafeHeapByteBuf和UnpooledHeapByteBuf都是调用的UnpooledHeapByteBuf的构造方法,那么它们之间到底有什么区别呢?其实根本区别在于I/O的读写,我们分别来看它们的getByte()方法,了解二者的区别。先看UnpooledHeapByteBuf的getByte()方法的实现代码。
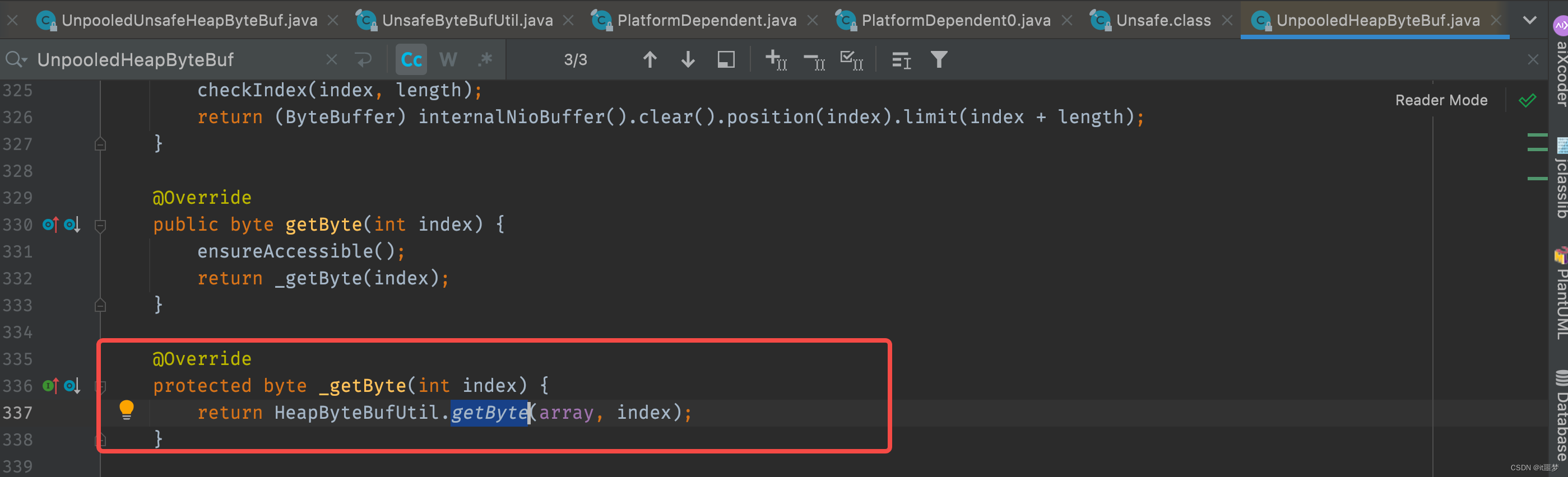
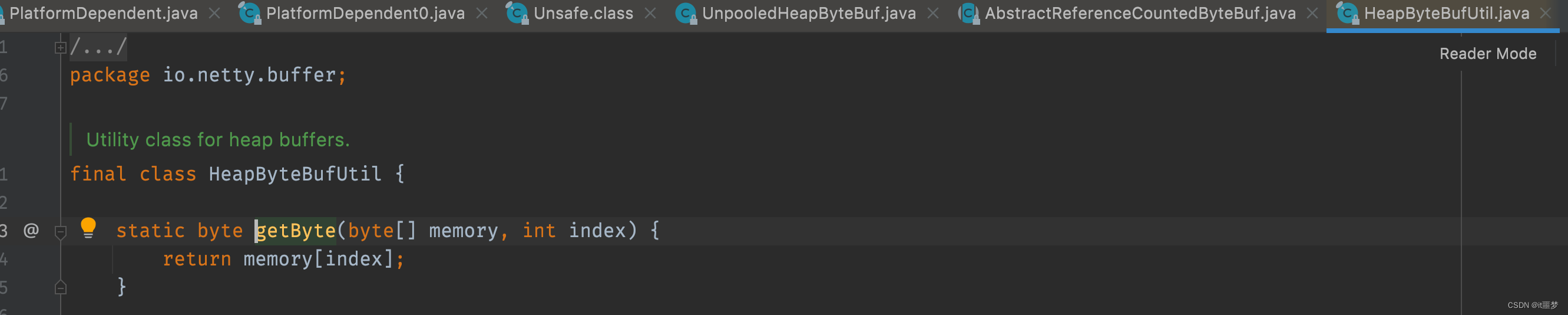
就是根据index索引直接从数组中取值,接下来看UnpooledUnsafeHeapByteBuf的getByte()方法实现。
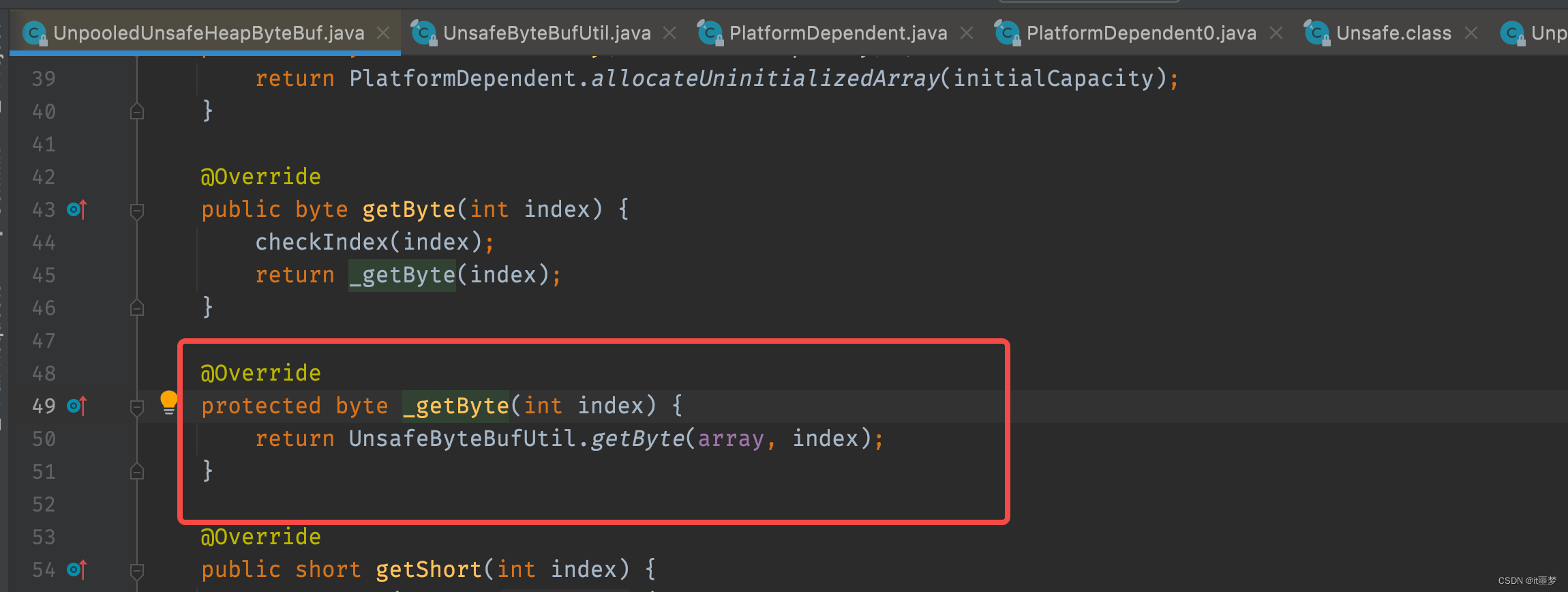

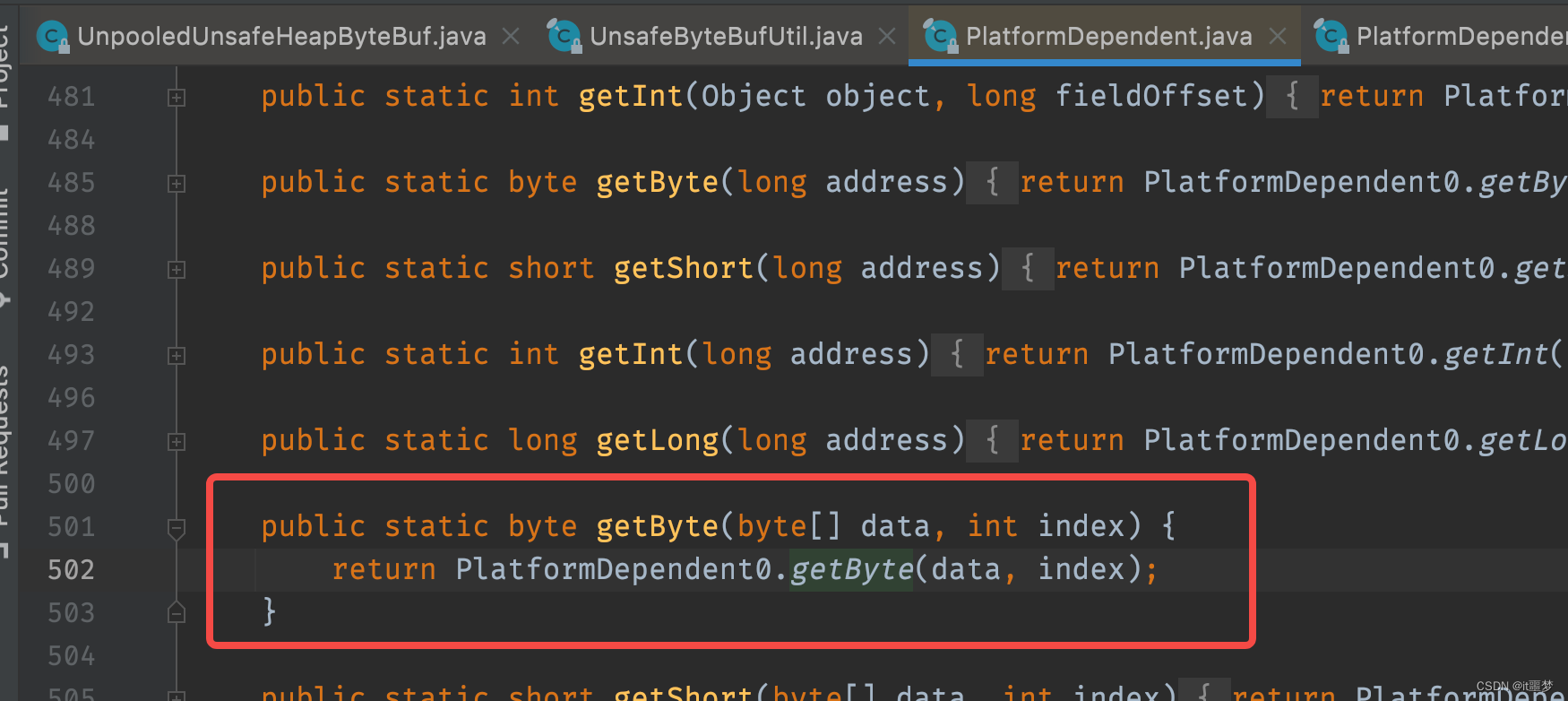
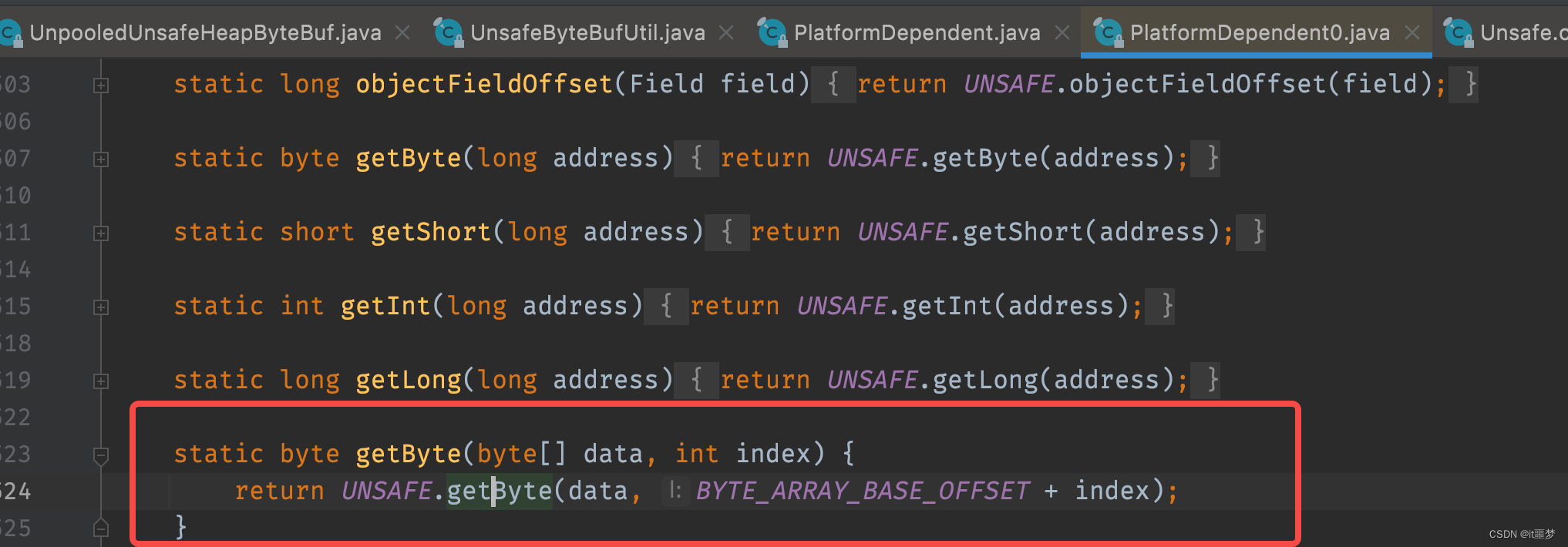
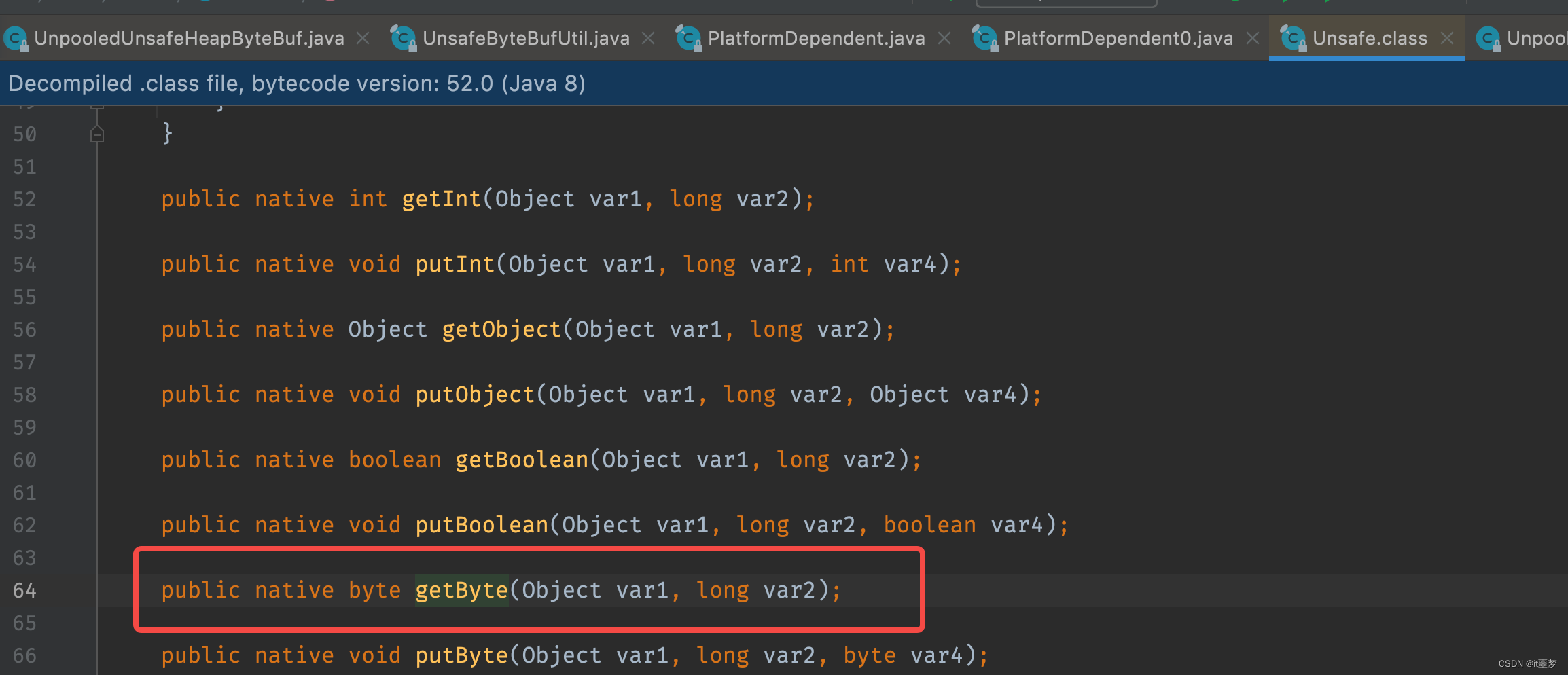
可以看到调用了Unsafe的getByte()方法,这是一个native()方法。它直接通过Buffer的内存地址加上一个偏移量去取数据。非Unsafe通过数组的下标取数据,Unsafe直接操作内存地址,相对于非Unsafe来说效率当然更高。
1.4 池化内存分配
1.4.1 PooledByteBufAllocator简述
首先找到AbstractByteBufAllocator的子类PooledByteBufAllocator实现分配内存两个方法newHeapBuffer()和newDirectBuffer()
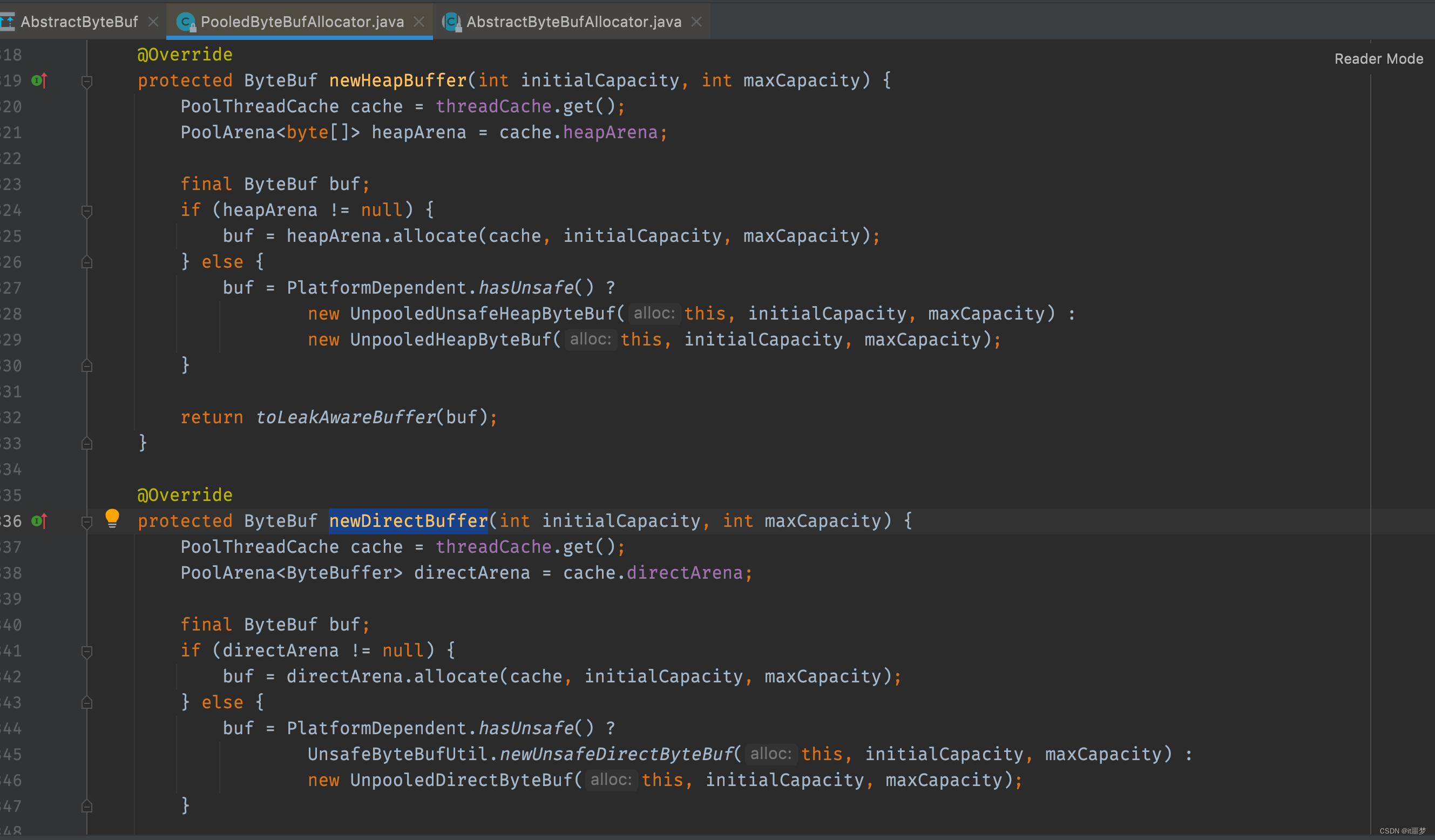
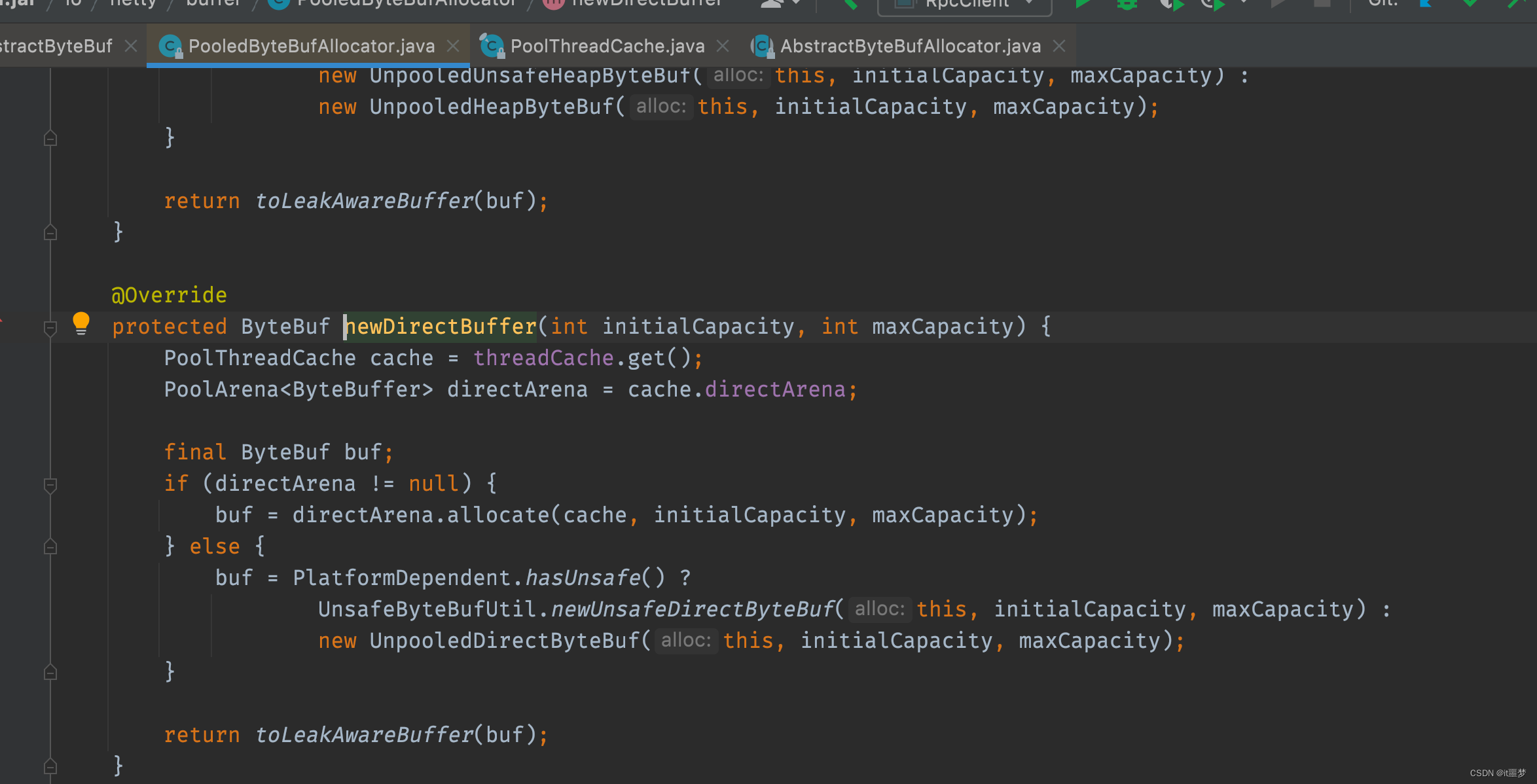
我们发现这两个方法大体机构都是一样的,以newDirectBuffer()方法为例,简单分析一下。
首先,通过threadCache.get()方法获得一个类型为PoolThreadCache的cache的对象;然后,通过cache获得directArena对象,最后,调用directArena.allocate方法分配ByteBuf。这里读者可能会有点看不懂,我们接下来详细分析一下,threadCache对象其实是PoolThreadLocalCache类型的变量,PoolThreadLocalCache相关代码如下。
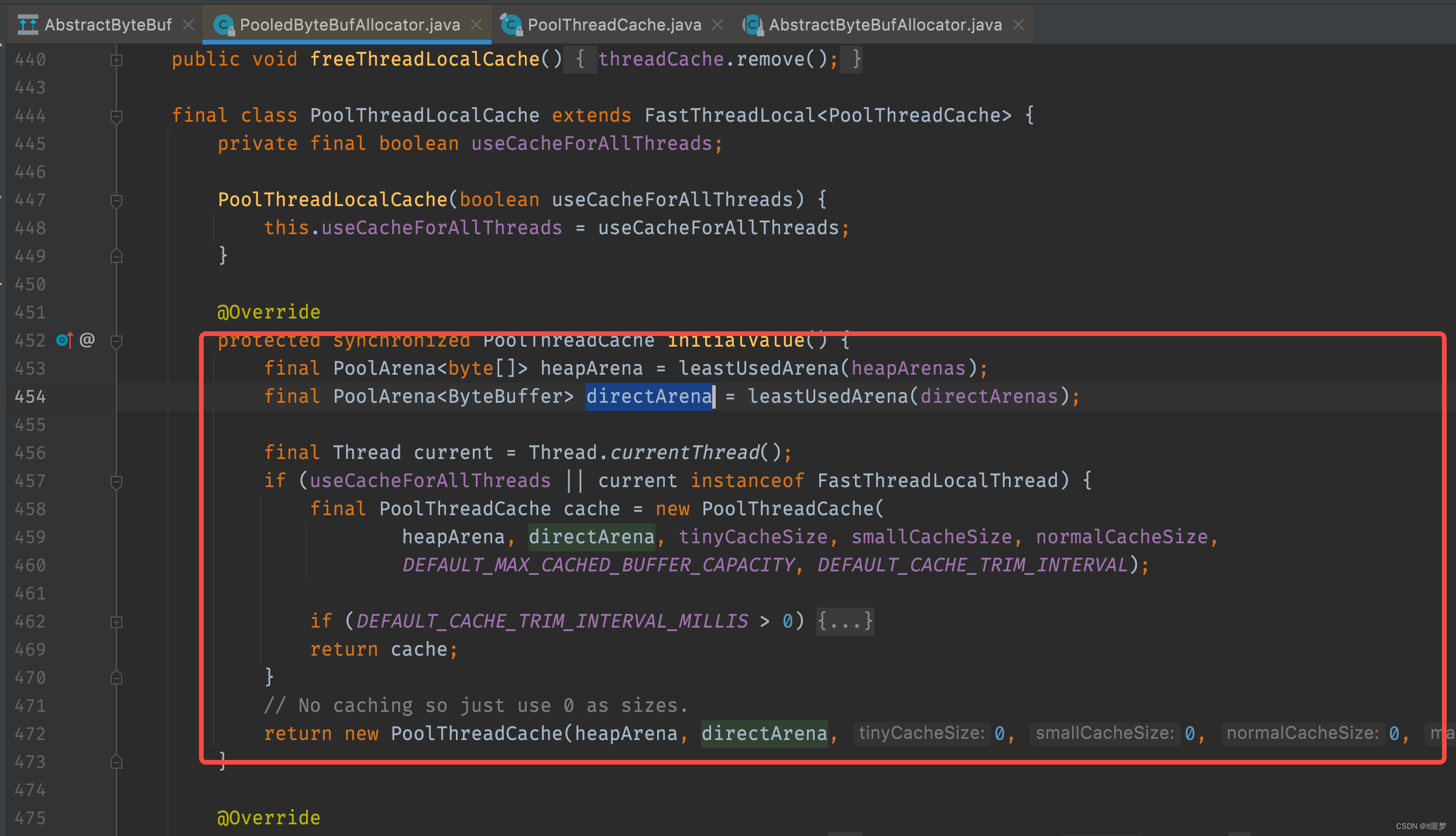
首先调用leastUsedArena()方法分别获得类型为PoolArena的heapArena和direcArena对象,然后把heapArena和directArena对象作为参数传递到PoolThreadCache的构造器中,那么heapArena和directArena对象是哪里初始化的呢?经过查找,发现在PooledByteBufAlloctor的构造方法中调用newArenaArray()方法给heapArenas和directArenas进行了赋值。
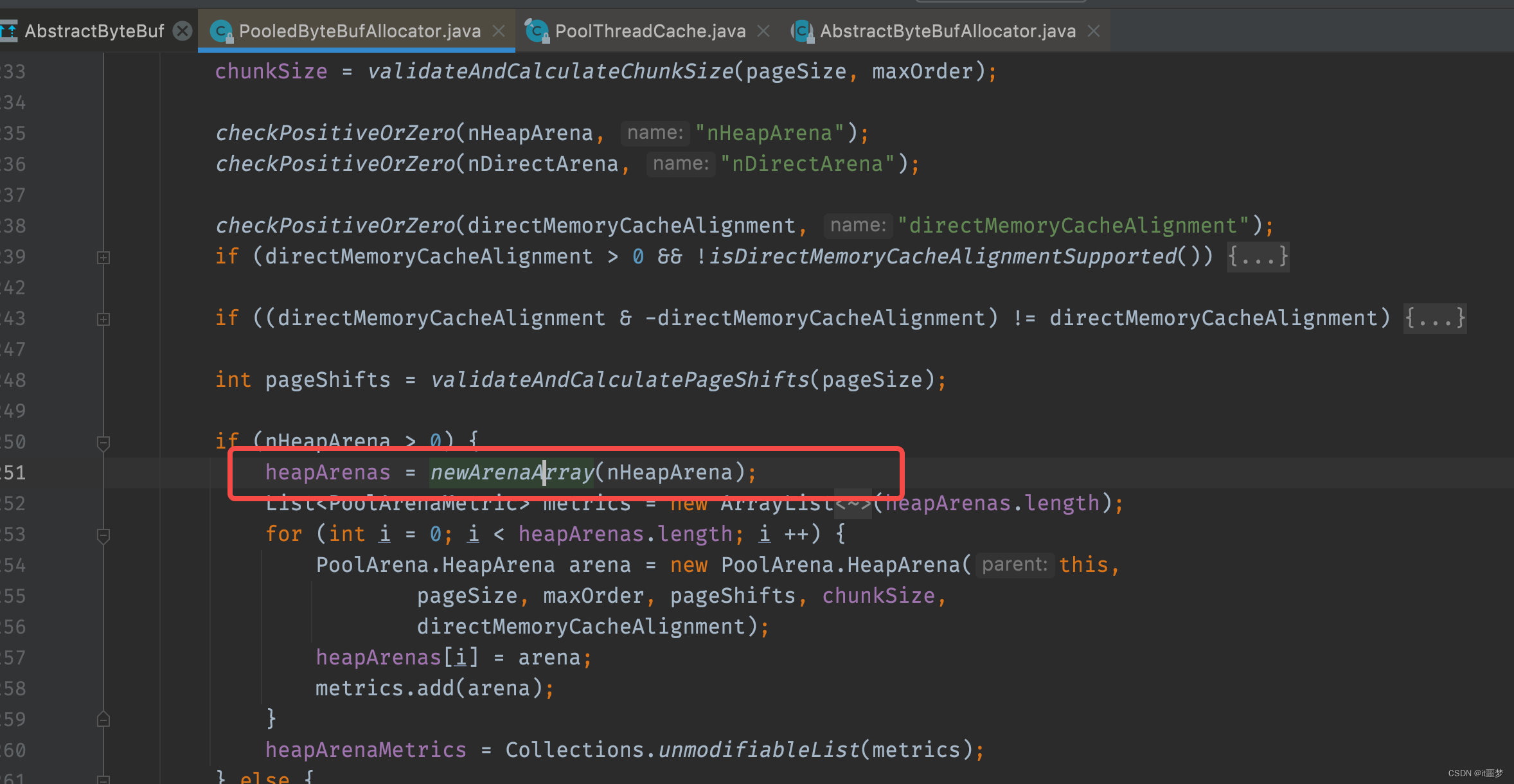
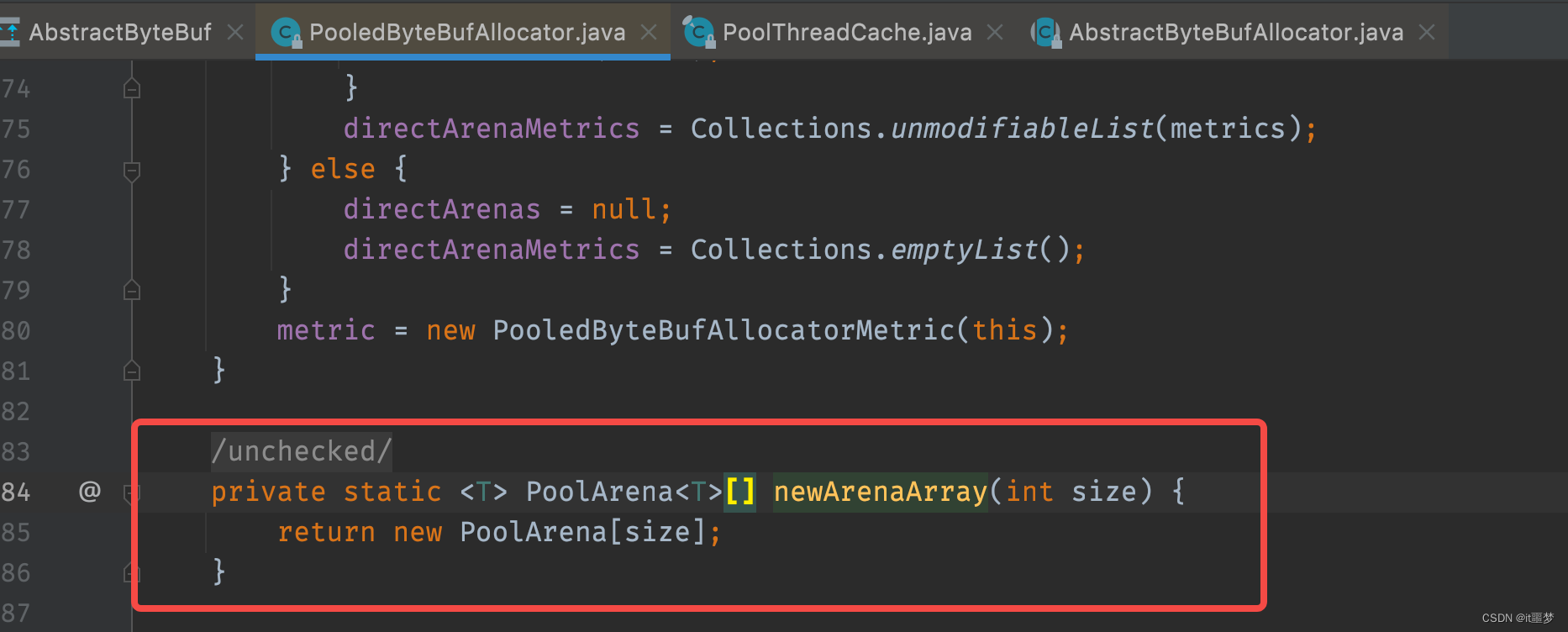
其实就是创建了一个固定大小的PoolArena数组,数组大小由传入的参数nHeapArena和nHeapArena决定,通过构造方法向上找,可以找到两个这两个常量值。
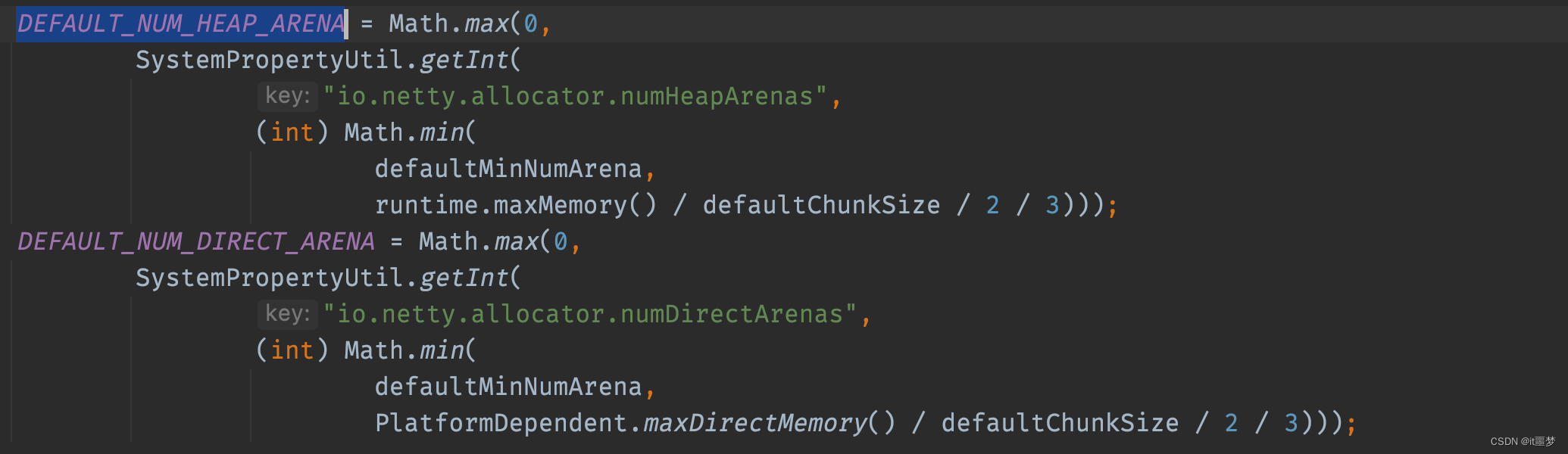
它们的默认值都是CPU核数 * 2,EventLoopGroup分配线程时,默认线程数也是CPU核数*2,主要目的是就是保证Netty中的每一个任务线程都可以有一个独享的Arena,保证在每个线程分配内存的时候不用加锁。
基于上面分析,我们知道heapArena和directArena,这里统称为Arena。假设有四个线程,那么对应分配四个Arena。在创建ByteBuf的时候,首相通过PoolThreadCache获取Arena对象并且赋值给其成员变量,然后每个线程通过PoolThreadCache调用get()方法的时候会获得它底层Arena,也就是说EventLoop1获得Arena1,依次类推。
PoolThreadCache除了可以在Arena上进行内存分配,还可以在它底层维护的ByteBuf缓存列表进行分配。
1.4.2 DirectArena内存分配流程
Arena分配内存的基本流程有三个步骤。
- 优先从对象池里获得PooledByteBuf进行复用
- 然后在缓存中进行内存分配
- 最后考虑从内存堆中进行内存分配
以directBuffer为例,首先来看从对象池中获得PooledByteBuf进行复用的情况,我们依旧跟进到PooledByteBufAllocator的newDirectBuffer()方法
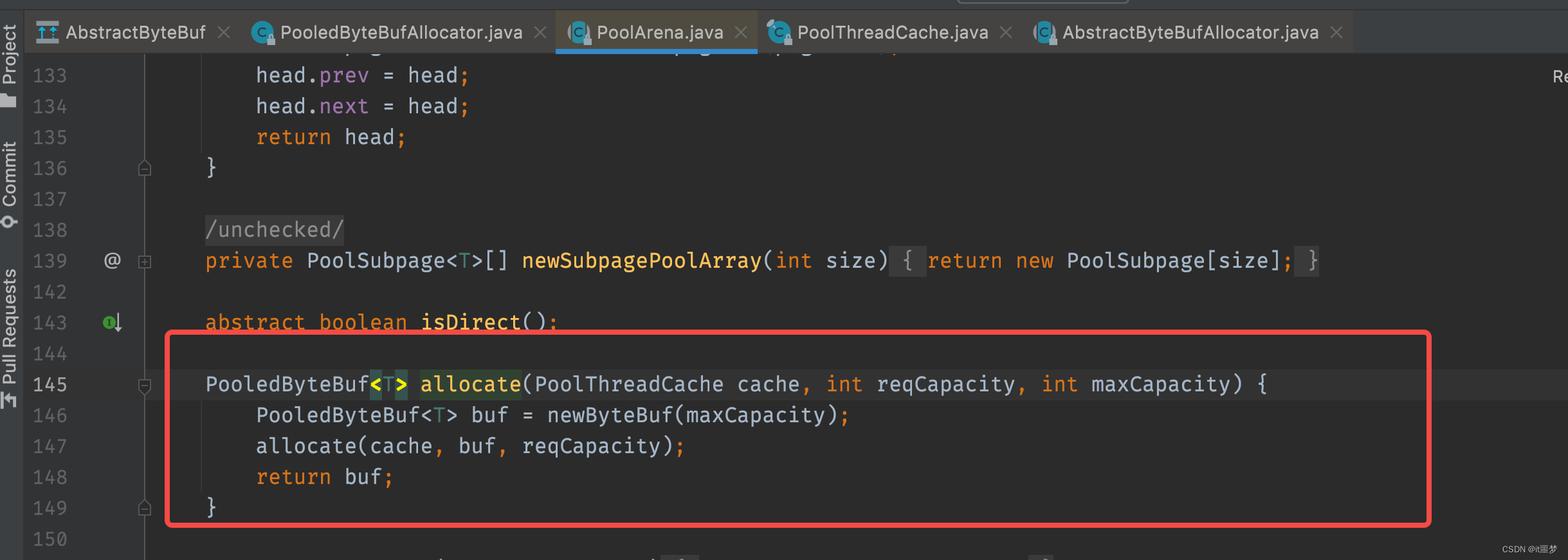
首先调用newByteBuf()方法获得一个PooledByteBuf对象,然后通过allocate()方法在线程私有的PoolThreadCache中分配一块内存,再对buf里面的内存地址之类的进行初始化,跟进newByteBuf()方法,选择DirectArena对象。
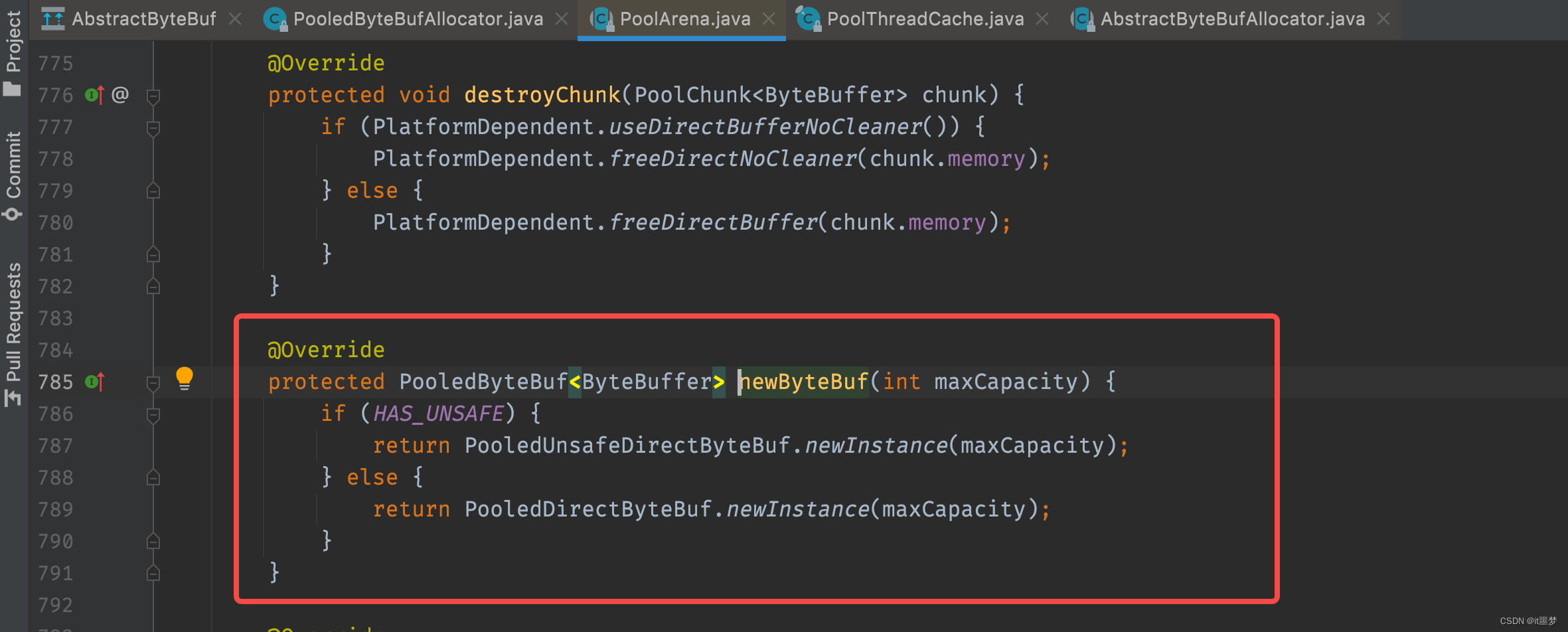
首先判断是否支持Unsafe,默认情况下一般是支持Unsafe的,继续看PooledUnsafeDirectByteBuf的newInstance()方法,代码如下:
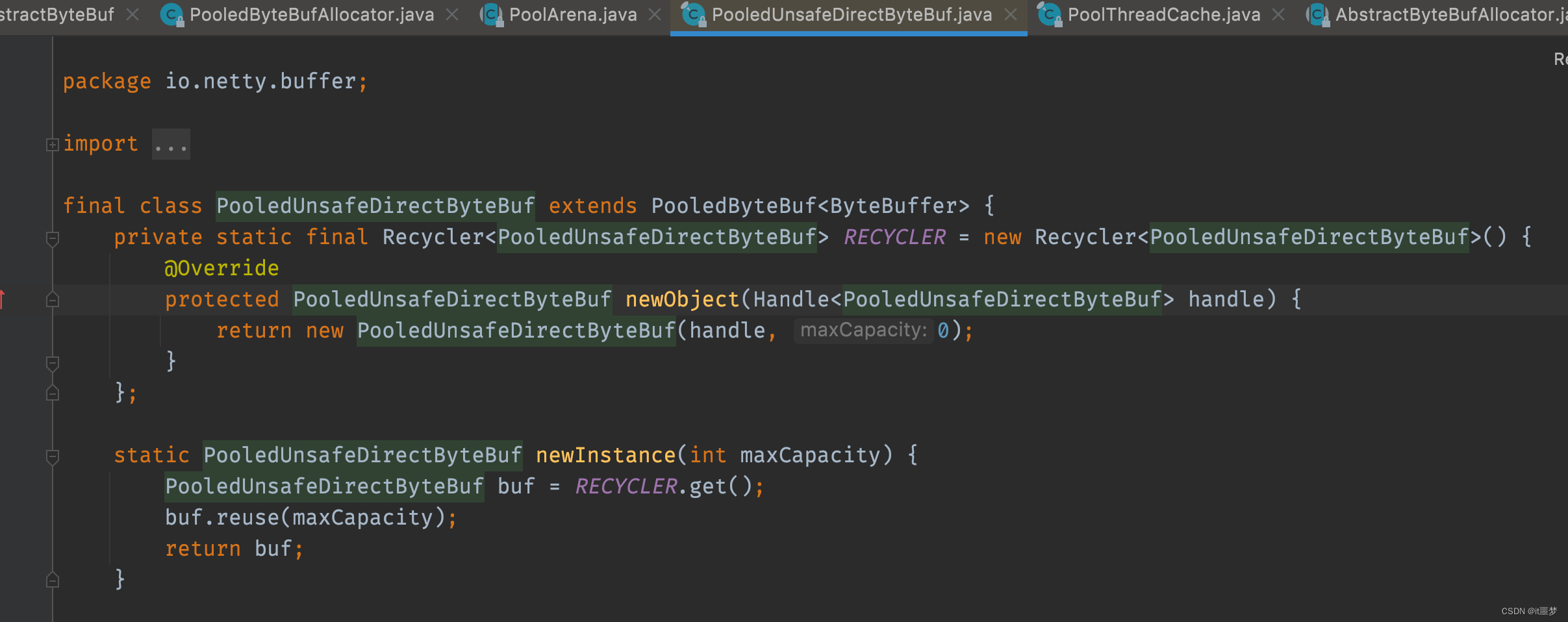
通过RECYCLER(内存回收站)对象的get()方法获得一个buf。从上面的代码片段看,RECYCLER对象实现了一个newObject方法,当回收站里面没有可用的buf时就会创建一个新的buf。因为获得buf可能是回收站取出来的,所以服用前需要重置。继续往下看就会调用buf的reuse()方法,代码如下。
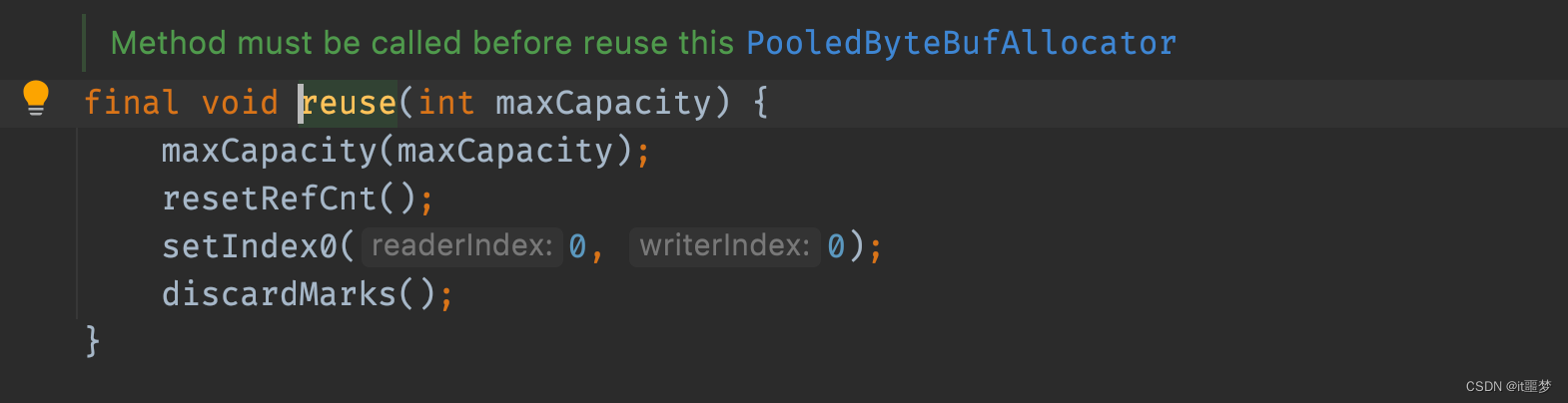
reuse()方法就是让所有的参数重新归为初始状态。到这里我们应该已经清楚从内存池获取buf对象的全过程。接下来,再回到PoolArena的allocate方法,看看真实的内存是如何分配出来的?buf内存分配主要有两种情况,分别是从缓冲中进行内存分配和从内存堆里进行内存分配。
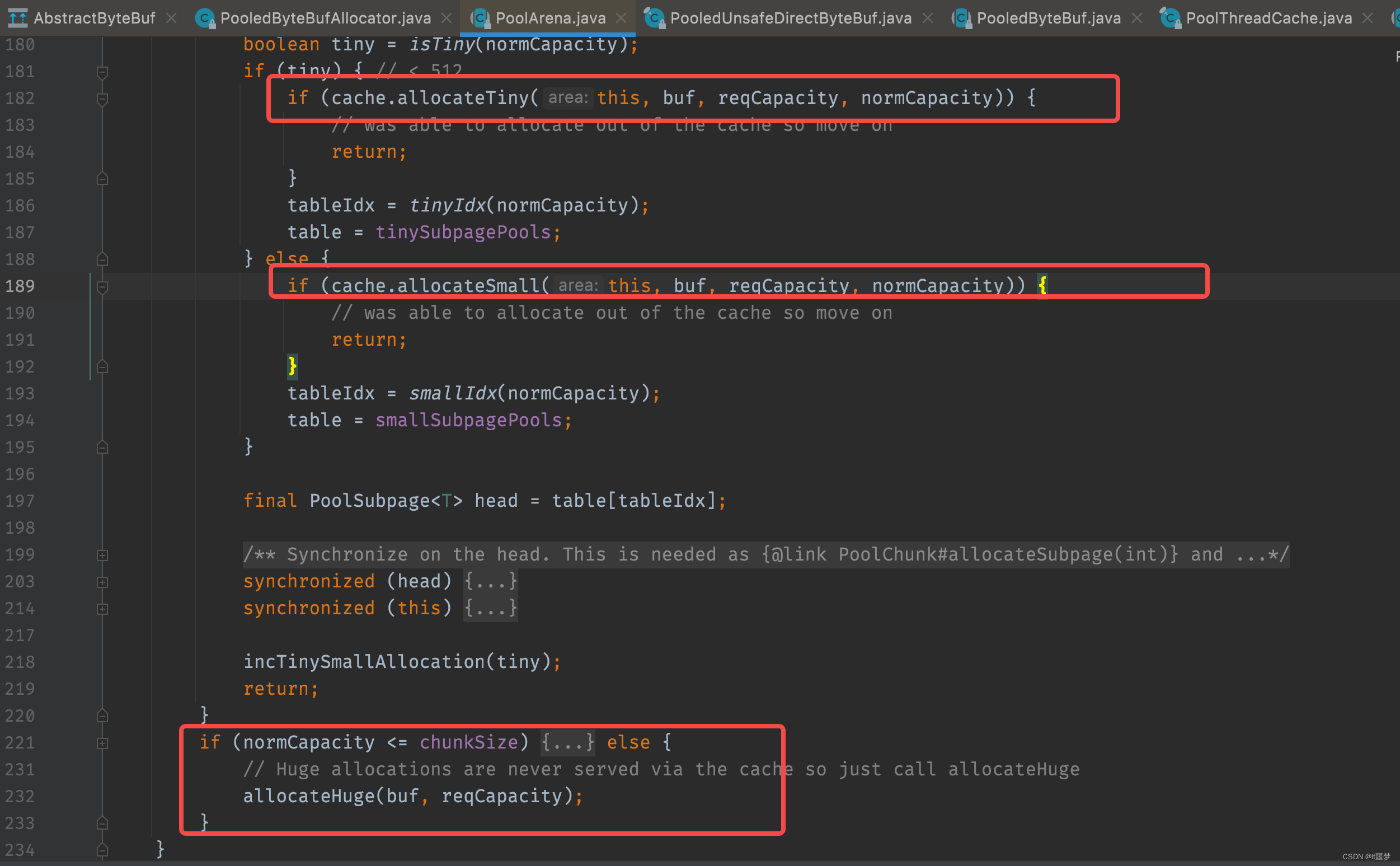
从对应的缓存中获取内存,如果所有规格都不满足,那就直接调用allocateHuge()方法进行真是的内存分配。
1.4.3 内存池的内存规格
Netty内存池中主要设置了四种规格大小的内存:tiny指0-512Byte的规格大小,small值512Byte-8KB的规则大小,normal指8KB-16MB的规格大小,huge指16MB以上的规格大小。
Netty中所有内存的内存规格是以Chunk为单位向系统申请的,每个Chunk大小为16MB,后续的所有内存分配都是在这个Chunk里面的操作。一个Chunk会以Page为单位进行切分,8KB对应一个Page,而一个Chunk被划分为2048个Page。小于8KB的是SubPage。继续把Page进行划分,以节省空间。
1.4.4 命中缓存的分配
知道其先命中缓存,如果命中不到,则去分配一段连续的内存,现在剖析命中缓存的相关逻辑,前面讲到PoolThreadCache中维护了三个缓存数组(实际上是六个,这里仅以Direct为例)
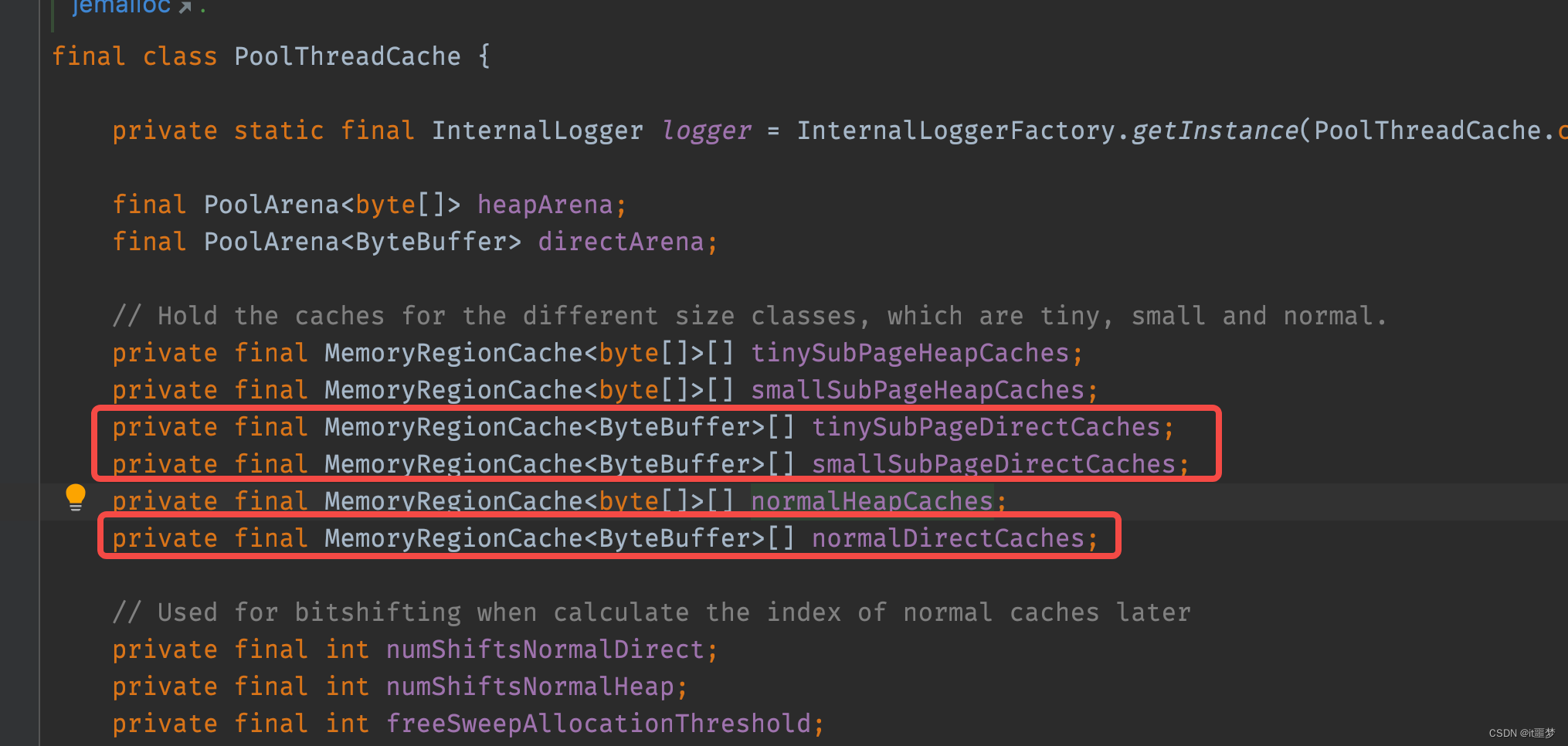
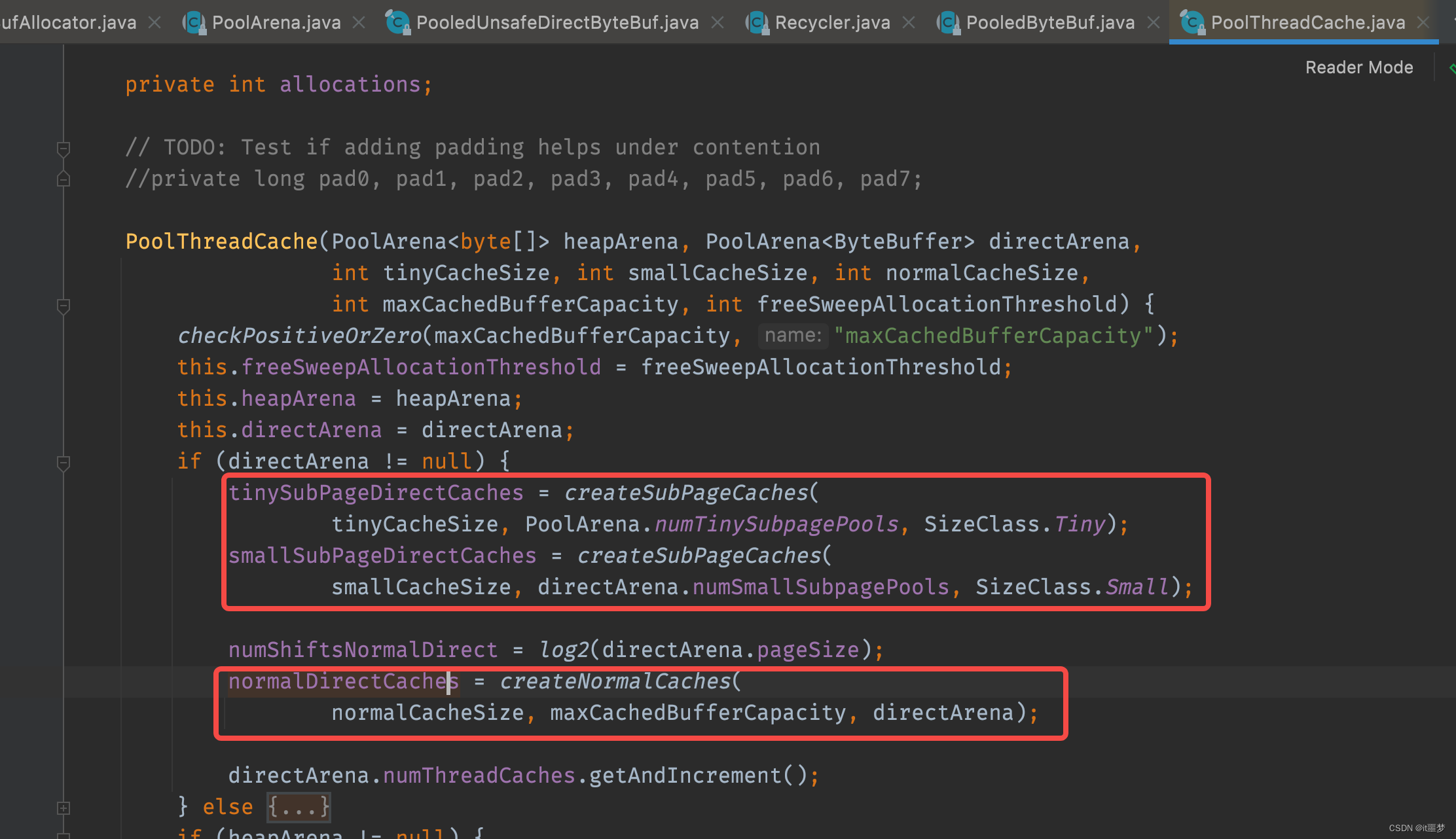
三个数组是在构造方法中进行了初始化,代码如下:
以tiny类型为例,具体分析一下SubPage缓存结构,实现代码如下:
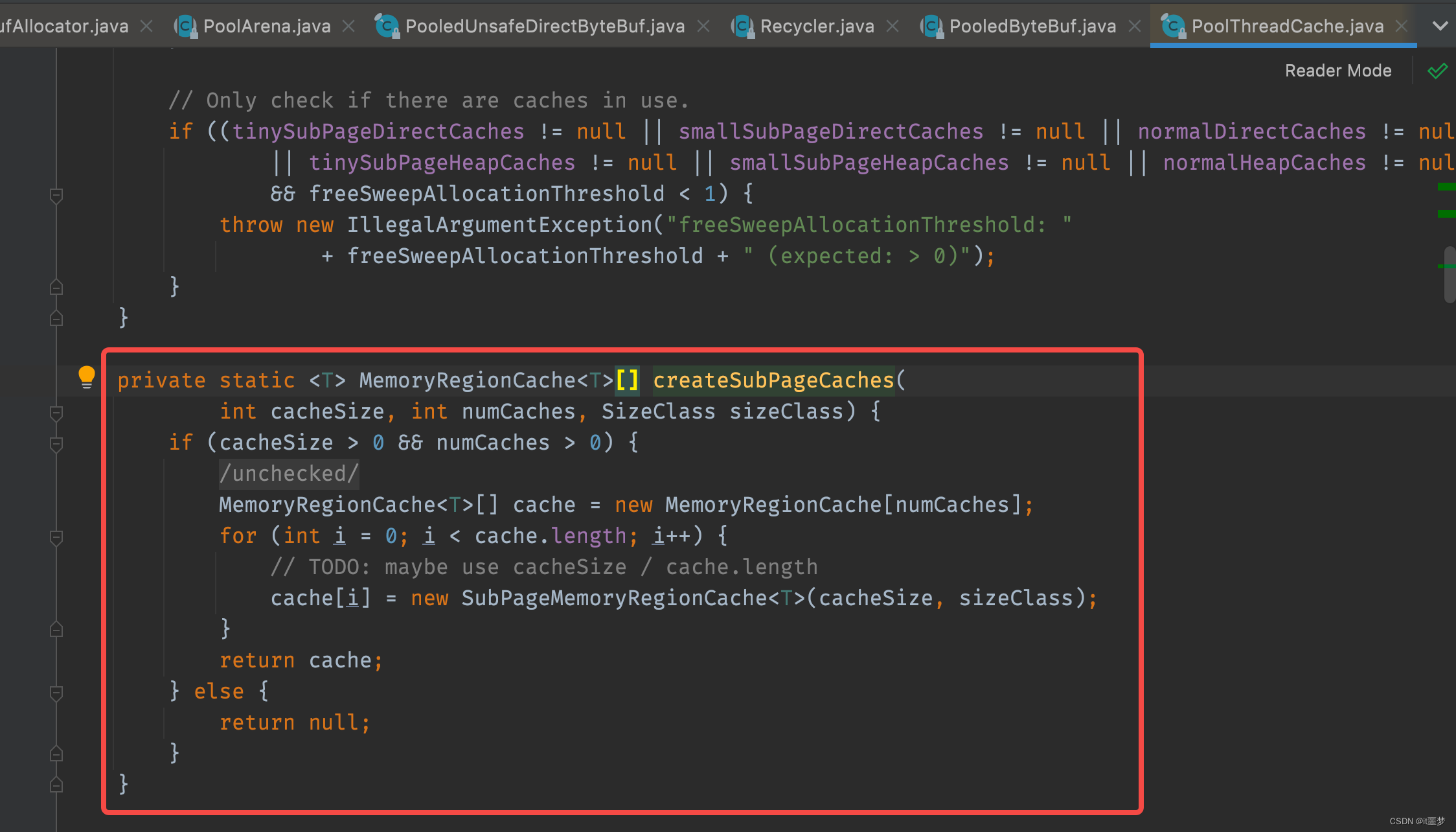
其实就是创建了一个缓存数组,这个缓存数组的长度是numCaches。
在PoolThreadCache给数组tinySubPageDirectCaches赋值前,需要设定的数组长度就是对应每一种规格的固定值。以tinySubPageDirectCahces[1]为例对应的对象中ByteBuf的缓冲区大小为16Byte,在tinySubPageDirectCache[2]中缓冲的ByteBuf大小为32Byte,以此类推,tinySubPageDirectCache[31]中缓存的Bytebuf大小为496Byte。
不同类型的缓存数组规格不一样,tiny长度为32 ,small长度为4,normal类型长度为3。缓存数组中的每一个元素都是MemoryRegionCache类型,代表一个缓存对象。每个MemoryRegionCache对象中维护了一个队列,队列的容量大小由PooledByteBufAllocator类中定义的tinyCacheSize、smallCacheSize、normalCacheSize的值来决定。
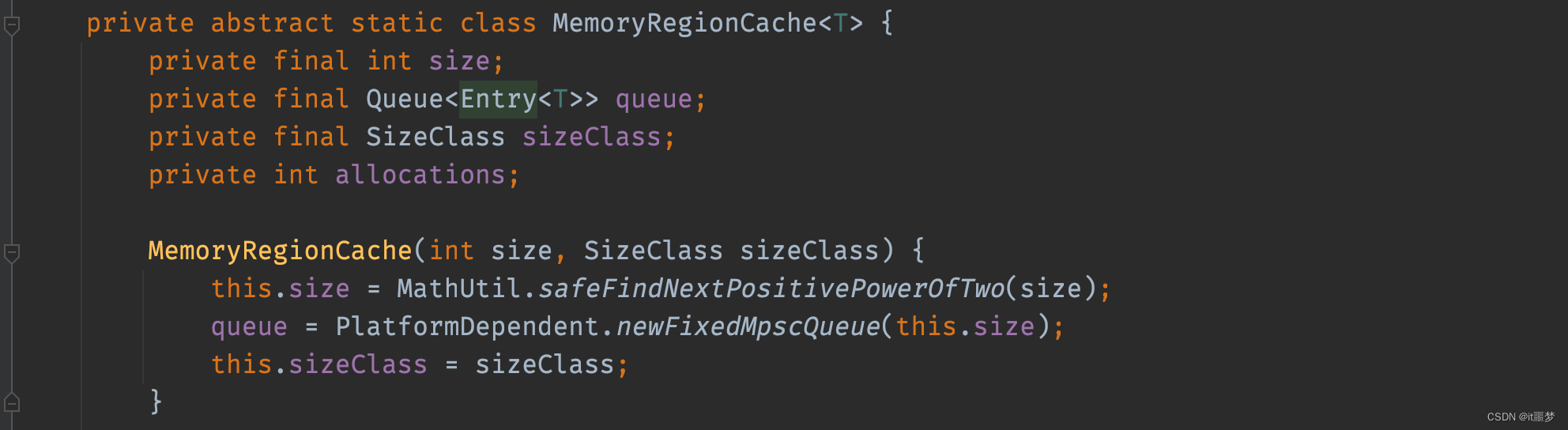
Netty为了将对象循环利用,将其放在对象回收站进行回收,chunk=null和handle=-1表示当前Entry不指向任何一块内存。recyclerHandler.recycle(this)将当前Entry回收。
1.4.5 Page级别的内存分配
Netty内存分配单位是Chunk,一个Chunk大小事16MB














 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









