







基本概念
MessageQueue: 消息存储的队列
topic:由一个或多个队列组成,逻辑概念
tag:msg标签
目录
broker:具体的机器
架构

RocketMQ主要将zookeeper换成了NameServer
分布式事务
2pc协议
最大努力同质性
TCC补偿
RocketMQ事务
基于可靠性分布式队列的消息队列的最终一致性
RocketMQ由四部分组成
- NameServer可集群部署,节点之间无任何信息同步。提供轻量级的服务发现和路由。
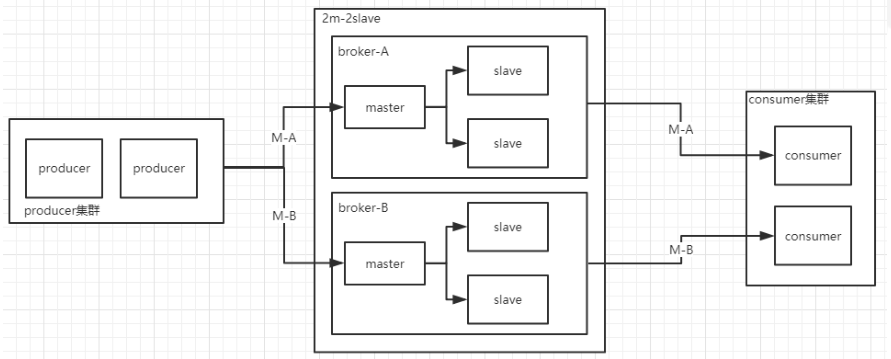
- Broker分为master和slave,一个master可以对应多个slave,但一个slave只能对应一个master,master和slave对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId=0表示master否则是slave。
- Producer,生产者相同的Group组成一个集群,与NameServer集群中的一个节点建立长连接,定期从NameServer获取topic路由信息,并向提供Topic的master建立长连接,且定时发送心跳包。
- Consumer,拥有相同Group组成一个集群,与NameServer集群中的一个节点建立长连接,定期从NameServer获取topic路由信息,并向提供Topic的master,slave建立长连接,且定时向master、slave发送心跳包。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,具体由Broker配置决定。
RocketMQ安装
下载
- 下载rocketmq的安装文件: RocketMQ · 官方网站 | RocketMQ
- 【unzip rocketmq-all-4.5.0-bin-release.zip】 解压压缩包
开启NameServer
- 【nohup sh mqnamesrv &】进入到bin目录下,运行namesrv,启动NameServer ->ps: nohup command & 表示在后台运行
- 默认情况下,nameserver监听的是9876端口。
- 【tail -f ~/logs/rocketmqlogs/namesrv.log】 查看启动日志
启动Broker
nohup sh bin/mqbroker -n ${namesrvIp}:9876 -c /conf/broker.conf & ->[-c可以指定broker.conf配置文件]。默认情况下会加载conf/broker.conf
- 【nohup sh mqbroker -n localhost:9876 &】 启动broker,其中-n表示指定当前broker对应的命名服务地址: 默认情况下,broker监听的是10911端口 。
- 输入 tail -f ~/logs/rocketmqlogs/broker.log 查看日志
- 如果 tail -f ~/logs/rocketmqlogs/broker.log 提示找不到文件,则打开当前目录下的 nohup.out日志文件查看,出现如下日志表示启动失败,提示内存无法分配
内存不足问题,rocketmq比较耗内存,所以默认分配的内存比较大,修改runbroker.sh和runbroker.sh
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g -Xmn512g"
Xms 是指设定程序启动时占用内存大小。一般来讲,大点,程序会启动的快一点,但是也可能会导致机器暂时
间变慢。
Xmx 是指设定程序运行期间最大可占用的内存大小。如果程序运行需要占用更多的内存,超出了这个设置值,
就会抛出OutOfMemory异常。
xmn 年轻代的heap大小,一般设置为Xmx的3、4分之一
停止服务
【sh bin/mqshutdown broker】 //停止 brokersh
【bin/mqshutdown namesrv】 //停止 nameserver
停止服务的时候需要注意,要先停止broker,其次停止nameserver。
broker.conf文件
默认情况下,启动broker会加载conf/broker.conf文件,namesrvAddr:nameserver地址,brokerClusterName:Cluster名称,brokerName:broker名称,如果配置主从模式,master和slave需要配置相同的名称来表名关系。
brokerRole=SYNC_MASTER/ASYNC_MASTER/SLAVE; 同步表示slave和master消息同步完成后再返回信息给客户端
docker-compose
version: '3.5'
services:
rmqnamesrv:
image: foxiswho/rocketmq:4.8.0
container_name: rmqnamesrv
ports:
- 9876:9876
volumes:
- ./data/namesrv/logs:/home/rocketmq/logs
- ./data/namesrv/store:/home/rocketmq/store
command: sh mqnamesrv
networks:
rmq:
aliases:
- rmqnamesrv
rmqbroker:
image: foxiswho/rocketmq:4.8.0
container_name: rmqbroker
ports:
- 10909:10909
- 10911:10911
- 10912:10912
volumes:
- ./data/broker/logs:/home/rocketmq/logs
- ./data/broker/store:/home/rocketmq/store
- ./data/broker/conf/broker.conf:/etc/rocketmq/broker.conf
environment:
NAMESRV_ADDR: "rmqnamesrv:9876"
JAVA_OPT_EXT: "-server -Xms128m -Xmx128m -Xmn128m"
command: sh mqbroker -c /etc/rocketmq/broker.conf
depends_on:
- rmqnamesrv
networks:
rmq:
aliases:
- rmqbroker
rmqconsole:
image: styletang/rocketmq-console-ng
container_name: rmqconsole
ports:
- 8078:8080
environment:
JAVA_OPTS: "-Drocketmq.namesrv.addr=rmqnamesrv:9876 -Dcom.rocketmq.sendMessageWithVIPChannel=false"
depends_on:
- rmqnamesrv
networks:
rmq:
aliases:
- rmqconsole
networks:
rmq:
name: rmq
driver: bridge
基本应用
依赖包
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.5.2</version>
</dependency>
生产者
public class Producer {
public static void main(String[] args) throws MQClientException,InterruptedException {
/*
*生产者组,简单来说就是多个发送同一类消息的生产者称之为一个生产者组
*rocketmq支持事务消息,在发送事务消息时,如果事务消息异常(producer挂了),broker端会来回查事务的状态,这个时候会根据group名称来查找对应的producer来执行相应的回查逻辑。相当于实现了producer的高可用
*/
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
//指定namesrv服务地址,获取broker相关信息
producer.setNamesrvAddr("192.168.11.162:9876");
producer.start();
for (int i = 0; i < 10; i++) {
try {
/*
* 创建一个消息实例,指定指定topic、tag、消息内容
*/
Message msg = new Message("TopicTest","TagA",("Hello RocketMQ " +i).getBytes(RemotingHelper.DEFAULT_CHARSET) /* Message body */);
//发送消息并且获取发送结果
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
} catch (Exception e) {
e.printStackTrace();
Thread.sleep(1000);
}
}
producer.shutdown();
}
}SendResult中,有一个sendStatus状态,表示消息的发送状态。一共有四种状态
- FLUSH_DISK_TIMEOUT : 表示没有在规定时间内完成刷盘(需要Broker的刷盘策略创立设置成SYNC_FLUSH才会报这个错误)。
- FLUSH_SLAVE_TIMEOUT :表示在主备方式下,并且Broker被设置成SYNC_MASTER方式,没有在设定时间内完成主从同步。
- SLAVE_NOT_AVAILABLE : 这个状态产生的场景和FLUSH_SLAVE_TIMEOUT 类似,表示在主备方式下,并且Broker被设置成SYNC_MASTER ,但是没有找到被配置成Slave的Broker 。
- SEND OK :表示发送成功,发送成功的具体含义,比如消息是否已经被存储到磁盘?消息是否被同步到了Slave上?消息在Slave 上是否被写入磁盘?需要结合所配置的刷盘策略、主从策略来定。这个状态还可以简单理解为,没有发生上面列出的三个问题状态就是SEND OK
消费者
RocketMQ提供了两种消息消费模型,一种是pull主动拉去,另一种是push,被动接收。但实际上RocketMQ都是pull模式,只是push在pull模式上做了一层封装,也就是pull到消息以后触发业务消费者注册到这里的callback. RocketMQ是基于长轮训来实现消息的pull。
public static void main(String[] args) throws MQClientException {
DefaultMQPushConsumer consumer=new DefaultMQPushConsumer("gp_consumer_group");
consumer.setNamesrvAddr("192.168.13.102:9876");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
consumer.subscribe("test_topic","*");
/*consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list,
ConsumeConcurrentlyContext consumeConcurrentlyContext) {
System.out.println("Receive Message: "+list);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //签收
}
});*/
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> list, ConsumeOrderlyContext consumeOrderlyContext) {
MessageExt messageExt=list.get(0);
// 重新发送该消息
if(messageExt.getReconsumeTimes()==3){ //消息重发了三次
//持久化 消息记录表
return ConsumeOrderlyStatus.SUCCESS; //签收
}
return ConsumeOrderlyStatus.SUCCESS; //签收
}
});
consumer.start();
}rocketmq控制台安装
rocket官方提供了一个可视化控制台https://github.com/apache/rocketmq-externals,这个是rocketmq的扩展,里面不仅包含控制台的扩展,也包含对大数据flume、hbase等组件的对接和扩展。
配置
- 下载https://github.com/apache/rocketmq-externals/archive/master.zip
- cd /${rocketmq-externals-home}/rocket-console/
- 修改application.properties文件
- 配置namesrvAddr地址,指向目标服务的ip和端口:rocketmq.config.namesrvAddr=192.168.13.162:9876
- cd /${rocketmq-externals-home}/rocket-console/
- mvn spring-boot:run
创建消息
创建Topic

readQueueNums和writeQueueNums分别表示读队列数和写队列数
writeQueueNums表示producer发送到的MessageQueue的队列个数
readQueueNumbs表示Consumer读取消息的MessageQueue队列个数,其实类似于kafka的分区的概念这两个值需要相等,在集群模式下如果不相等,假如说writeQueueNums=6,readQueueNums=3, 那么每个broker上会有3个queue的消息是无法消费的。
消息模式
NormalProducer
消息同步发送
同步消息发送模式,即producer会等到broker回应后才能继续发送下一个消息

消息异步发送
异步发送是指发送方发出数据后,不等接收方发回响应,接着发送下个数据包的通讯方式。 MQ的异步发送,需要用户实现异步发送回调接口(SendCallback)。消息发送方在发送了一条消息后,不需要等待服务器响应即可返回,进行第二条消息发送。发送方通过回调接口接收服务器响应,并对响应结果进行处理

producer.send(msg, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
System.out.printf("%s%n",sendResult);
}
@Override
public void onException(Throwable throwable) {
throwable.printStackTrace();
}
});OneWay
单向(Oneway)发送特点为发送方只负责发送消息,不等待服务器回应且没有回调函数触发,即只发送请求不等待应答.效率最高
producer.sendOneway(msg);OrderProducer(顺序)
在RocketMQ中,是基于多个Message Queue来实现类似于kafka的分区效果。如果一个Topic 要发送和接收的数据量非常大, 需要能支持增加并行处理的机器来提高处理速度,这时候一个Topic 可以根据需求设置一个或多个Message Queue。Topic 有了多个Message Queue 后,消息可以并行地向各个Message Queue 发送,消费者也可以并行地从多个Message Queue 读取消息并消费。
消息发送及消费原理
rocketmq天然支持高可用,它可以支持多主多从的部署架构,这也是和kafka最大的区别之一。RocketMQ中并没有master选举功能,所以通过配置多个master节点来保证rocketMQ的高可用。和所有的集群角色定位一样,master节点负责接受事务请求、slave节点只负责接收读请求,并且接收master同步过来的数据和slave保持一致。当master挂了以后,如果当前rocketmq是一主多从,就意味着无法接受发送端的消息,但是消费者仍然能够继续消费。
当存在多个主节点时,一条消息只会发送到其中一个主节点,rocketmq对于多个master节点的消息发送,会做负载均衡,使得消息可以平衡的发送到多个master节点上。
由于每个master可以配置多个slave,所以如果其中一个master挂了,消息仍然可以被消费者从slave节点消费到。可以完美的实现rocketmq消息的高可用。
接下来,站在topic的角度来看看消息是如何分发和处理的,假设有两个master节点的集群,创建了一个TestTopic,并且对这个topic创建了两个队列,也就是分区。
消费者定义了两个分组,分组的概念也是和kafka一样,通过分组可以实现消息的广播。

集群总结
RocketMQ天生对集群的支持非常友好
- 单Master
优点:除了配置简单没什么优点
缺点:不可靠,该机器重启或宕机,将导致整个服务不可用
- 多Master
优点:配置简单,性能最高
缺点:可能会有少量消息丢失(配置相关),单台机器重启或宕机期间,该机器下未被消费的消息在机器恢复前不可订阅,影响消息实时性
- 多Master多Slave,每个Master配一个Slave,有多对Master-Slave,集群采用异步复制方式,主备有短暂消息延迟,毫秒级
优点:性能同多Master几乎一样,实时性高,主备间切换对应用透明,不需人工干预
缺点:Master宕机或磁盘损坏时会有少量消息丢失
- 多Master多Slave,每个Master配一个Slave,有多对Master-Slave,集群采用同步双写方式,主备都写成功,向应用返回成功
优点:服务可用性与数据可用性非常高
缺点:性能比异步集群略低,当前版本主宕备不能自动切换为主
消息的顺序消费
首先,需要保证顺序的消息要发送到同一个messagequeue中;其次,一个messagequeue只能被一个 消费者消费,这点是由消息队列的分配机制来保证的;最后,一个消费者内部对一个mq的消费要保证 是有序的。
我们要做到生产者 - messagequeue - 消费者之间是一对一对一的关系。
自定义发送规则
因为一个Topic 会有多个Message Queue ,如果使用Producer 的默认配置,这个Producer 会轮流向各个Message Queue 发送消息。Consumer 在消费消息的时候,会根据负载均衡策略,消费被分配到的Message Queue。
因此如果不经过特定的设置,某条消息被发往哪个Message Queue,被哪个Consumer消费是未知的,rockerMQ提供了消息路由功能,我们可以自定义消息分发策略,可以实现MessageQueueSelector,来实现自己的消息分发策略。
//消息路由策略
producer.send(message, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> list, Message message, Object o) {
int key = o.hashCode();
int size = list.size();
int index = key%size;
return list.get(index);
}
},"key-"+num);消费端的负载均衡
消费端会通过RebalanceService线程,10秒钟做一次基于topic下的所有队列负载
- 消费端遍历自己的所有topic,依次调rebalanceByTopic
- 根据topic获取此topic下的所有queue
- 选择一台broker获取基于group的所有消费端(有心跳向所有broker注册客户端信息)
- 选择队列分配策略实例AllocateMessageQueueStrategy执行分配算法
触发条件
- 消费者启动之后
- 消费者数量发生变更
- 每10秒会触发检查一次rebalance
分配算法
- (AllocateMessageQueueAveragely)平均分配算法(默认)
- (AllocateMessageQueueAveragelyByCircle)环状分配消息队列
- (AllocateMessageQueueByConfig)按照配置来分配队列: 根据用户指定的配置来进行负载
- (AllocateMessageQueueByMachineRoom)按照指定机房来配置队列
- (AllocateMachineRoomNearby)按照就近机房来配置队列:
- (AllocateMessageQueueConsistentHash)一致性hash,根据消费者的cid进行
消息可靠性原则
消息消费端的确认机制
RocketMQ提供了ack机制,以保证消息能够被正常消费。发送者为了保证消息肯定消费成功,只有使用方明确表示消费成功,RocketMQ才会认为消息消费成功。中途断电,抛出异常等都不会认为成功
consumer.registerMessageListener((MessageListenerConcurrently) (list, consumeOrderlyContext) -> {
list.stream().forEach(messageExt -> System.out.println(new String(messageExt.getBody())));
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});所有消费者在设置监听的时候会提供一个回调,业务实现消费回调的时候,当回调方法中返回ConsumeConcurrentlyStatus.CONSUME_SUCCESS,RocketMQ才会认为这批消息(默认是1条)是消费完成的。如果这时候消息消费失败,例如数据库异常,余额不足扣款失败等一切业务认为消息需要重试的场景,只要返回ConsumeConcurrentlyStatus.RECONSUME_LATER,RocketMQ就会认为这批消息消费失败了
衰减重试
为了保证消息肯定至少被消费一次,RocketMQ会把这批消息重新发回到broker,在延迟的某个时间点(默认是10秒,业务可设置)后,再次投递到这个ConsumerGroup。而如果一直这样重复消费都持续失败到一定次数(默认16次),就会投递到DLQ死信队列。应用可以监控死信队列来做人工干预
可以修改broker-a.conf文件
messageDelayLevel = 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h分布式事务
经典的X/OpenDTP事务模型
X/Open DTP(X/Open Distributed Transaction Processing Reference Model) 是X/Open这个组织定义的一套分布式事务的标准,也就是定义了规范和API接口,由各个厂商进行具体的实现。
这个标准提出了使用二阶段提交(2PC –Two-Phase-Commit)来保证分布式事务的完整性。后来J2EE也遵循了X/OpenDTP规范,设计并实现了java里的分布式事务编程接口规范-JTA
X/OpenDTP角色
AP:application, 应用程序,也就是业务层。哪些操作属于一个事务,就是AP定义的
RM: Resource Manager,资源管理器。一般是数据库,也可以是其他资源管理器,比如消息队列,文件系统
TM: Transaction Manager,事务管理器、事务协调者,负责接收来自用户程序(AP)发起的XA事务指令,并调度和协调参与事务的所有RM(数据库),确保事务正确完成

2PC
第一阶段

RM在第一阶段会做两件事:
- 记录事务日志:reduo,undo
- 返回给TM信息,ok、error
存在问题: 如果第一阶段完成后TM宕机或网络出现故障了,此时RM会一直阻塞,发生了死锁,因为没有timeout机制,3pc就针对此问题进行了改造,加入了timeout机制
第二阶段

分布式事务常用解决方案
最大努力通知方案

TCC两阶段补偿
TCC是Try-Confirm-Cancel,比如在支付场景中,先冻结一笔资金,再去发起支付。如果支付成功,则将冻结资金进行实际扣除;如果支付失败,则取消资金冻结

Try阶段
完成所有业务检查(一致性),预留业务资源(准隔离性)
Confirm阶段
确认执行业务操作,不做任何业务检查,只使用Try阶段预留的业务资源。
Cancel阶段
取消Try阶段预留的业务资源。Try阶段出现异常时,取消所有业务资源预留请求
开源解决方案
GTS Seata TX-LCN
RocketMQ事务消息
RocketMQ和其他消息中间件最大的一个区别是支持了事务消息,这也是分布式事务里面的基于消息的最终一致性方案
RocketMQ消息的事务架构设计
- 生产者执行本地事务,修改状态,并且提交事务
- 生产者发送事务消息到broker上,消息发送到broker上在没有确认之前,消息对于consumer是不可见状态
- 生产者确认事务消息,使得发送到broker上的事务消息对于消费者可见
- 消费者获取到消息进行消费,消费完之后执行ack进行确认
- 这里可能会存在一个问题,生产者本地事务成功后,发送事务确认消息到broker上失败了怎么
办?这个时候意味着消费者无法正常消费到这个消息。所以RocketMQ提供了消息回查机制,如果
事务消息一直处于中间状态,broker会发起重试去查询broker上这个事务的处理状态。一旦发现
事务处理成功,则把当前这条消息设置为可见

实践
通过一个下单以后扣减库存的数据一致性场景来演示RocketMQ的分布式事务特性
生产者
public static void main(String[] args) throws MQClientException, UnsupportedEncodingException, InterruptedException {
TransactionMQProducer transactionMQProducer=new TransactionMQProducer("tx_producer");
transactionMQProducer.setNamesrvAddr("localhost:9876");
ExecutorService executorService= Executors.newFixedThreadPool(10);
transactionMQProducer.setExecutorService(executorService);
transactionMQProducer.setTransactionListener(new TransactionListenerLocal()); //本地事务的监听
transactionMQProducer.start();
for(int i=0;i<20;i++){
String orderId= UUID.randomUUID().toString();
String body="{'operation':'doOrder','orderId':'"+orderId+"'}";
Message message=new Message("order_tx_topic", "TagA",orderId,body.getBytes(RemotingHelper.DEFAULT_CHARSET));
transactionMQProducer.sendMessageInTransaction(message,orderId+"&"+i);
Thread.sleep(1000);
}
}TransactionListenerLocal
public class TransactionListenerLocal implements TransactionListener {
private Map<String,Boolean> results=new ConcurrentHashMap<>();
//执行本地事务
@Override
public LocalTransactionState executeLocalTransaction(Message message, Object o) {
System.out.println("开始执行本地事务:"+o.toString()); //o
String orderId=o.toString();
//模拟数据库保存(成功/失败)
boolean result=Math.abs(Objects.hash(orderId))%2==0;
results.put(orderId,result); //
return result?LocalTransactionState.COMMIT_MESSAGE:LocalTransactionState.UNKNOW;
}
//提供给事务执行状态检查的回调方法,给broker用的(异步回调)
//如果回查失败,消息就丢弃
@Override
public LocalTransactionState checkLocalTransaction(MessageExt messageExt) {
String orderId=messageExt.getKeys();
System.out.println("执行事务回调检查: orderId:"+orderId);
boolean rs=results.get(orderId);
System.out.println("数据的处理结果:"+rs); //只有成功/失败
return rs?LocalTransactionState.COMMIT_MESSAGE:LocalTransactionState.ROLLBACK_MESSAGE;
}
}TransactionConsumer
public class TransactionConsumer {
//RocketMQ可以支持广播消息,就意味着,同一个group的每个消费者都可以消费同一个消息
public static void main(String[] args) throws MQClientException {
DefaultMQPushConsumer defaultMQPushConsumer= new DefaultMQPushConsumer("tx_consumer");
defaultMQPushConsumer.setNamesrvAddr("192.168.13.102:9876");
defaultMQPushConsumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
//subExpression 可以支持sql的表达式. or and a=? ,,,
defaultMQPushConsumer.subscribe("order_tx_topic","*");
defaultMQPushConsumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
list.stream().forEach(message->{
//扣减库存
System.out.println("开始业务处理逻辑:消息体:"+new String(message.getBody())+"->key:"+message.getKeys());
});
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; //签收
}
});
defaultMQPushConsumer.start();
}
}事务消息三种状态
- ROLLBACK_MESSAGE:回滚事务
- COMMIT_MESSAGE: 提交事务
- UNKNOW: broker会定时的回查Producer消息状态,直到彻底成功或失败。
当executeLocalTransaction方法返回ROLLBACK_MESSAGE时,表示直接回滚事务,当返回COMMIT_MESSAGE提交事务
当返回UNKNOW时,Broker会在一段时间之后回查checkLocalTransaction,根据checkLocalTransaction返回状态执行事务的操作(回滚或提交),
如示例中,当返回ROLLBACK_MESSAGE时消费者不会收到消息,且不会调用回查函数,当返回COMMIT_MESSAGE时事务提交,消费者收到消息,当返回UNKNOW时,在一段时间之后调用回查函数,并根据status判断返回提交或回滚状态,返回提交状态的消息将会被消费者消费,所以此时消费者可以消费部分消息
消息的存储和转发
消息的生成过程
- Producer发送消息之前,先向NameServer发出获取消息Topic的路由信息的请求
- NameServer返回该Topic的路由表及Broker列表
- Producer根据代码中指定的Queue选择策略,从Queue列表中选出一个队列,用于后续存储消息
- Producer对消息做了特殊处理,如超过4M,则会对其进行压缩
- Producer向选择的Queue所在的Broker发出请求,将消息发送到Queue。
路由表即Map对象,key为Topic名称,value为QueueData实例列表。QueueData由Broker中该Topic所有Queue对应的QueueData。
Broker列表也是Map对象,key为brokerName,value为BrokerData
Queue选择算法
- 轮询算法-默认算法
- 最小投递延迟
MQ消息存储选择
RocketMQ就是采用文件系统的方式来存储消息,消息的存储是由ConsumeQueue和CommitLog配合完成的。CommitLog是消息真正的物理存储文件。ConsumeQueue是消息的逻辑队列,有点类似于数据库的索引文件,里面存储的是指向CommitLog文件中消息存储的地址。
每个Topic下的每个Message Queue都会对应一个ConsumeQueue文件,文件的地址是:{topicNmae}/{filename}, 默认路径: /root/store
在rocketMQ的文件存储目录下,可以看到这样一个结构的的而文件。
重点需要关心Commitlog、Consumequeue、Index
Commitlog
CommitLog是用来存放消息的物理文件,每个broker上的commitLog本当前机器上的所有consumerQueue共享,不做任何的区分。
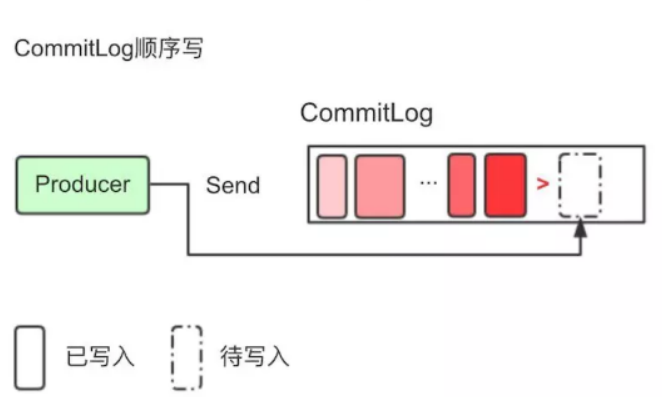
CommitLog中的文件默认大小为1G,可以动态配置; 当一个文件写满以后,会生成一个新的commitlog文件。所有的Topic数据是顺序写入在CommitLog文件中的。
文件名的长度为20位,左边补0,剩余未起始偏移量,比如00000000000000000000表示第一个文件, 文件大小为102410241024,当第一个文件写满之后,生成第二个文件,000000000001073741824 表示第二个文件,起始偏移量为1073741824
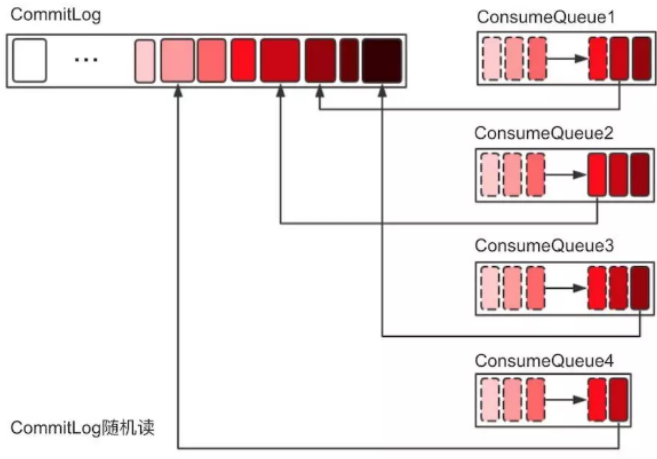
ConsumeQueue
consumeQueue表示消息消费的逻辑队列,这里面包含MessageQueue在commitlog中的其实物理位置偏移量offset,消息实体内容的大小和Message Tag的hash值。对于实际物理存储来说,consumeQueue对应每个topic和queueid下的文件,每个consumeQueue类型的文件也是有大小,每个文件默认大小约为600W个字节,如果文件满了后会也会生成一个新的文件
IndexFile
索引文件,如果一个消息包含Key值的话,会使用IndexFile存储消息索引。Index索引文件提供了对CommitLog进行数据检索,提供了一种通过key或者时间区间来查找CommitLog中的消息的方法。在物理存储中,文件名是以创建的时间戳明明,固定的单个IndexFile大小大概为400M,一个IndexFile可以保存2000W个索引
abort
broker在启动的时候会创建一个空的名为abort的文件,并在shutdown时将其删除,用于标识进程是否正常退出,如果不正常退出,会在启动时做故障恢复
消息存储的整体结构

RocketMQ的消息存储采用的是混合型的存储结构,也就是Broker单个实例下的所有队列公用一个日志数据文件CommitLog。这个是和Kafka又一个不同之处。
优点在于:由于消息主题都是通过CommitLog来进行读写,ConsumerQueue中只存储很少的数据,
所以队列更加轻量化。对于磁盘的访问是串行化从而避免了磁盘的竞争
缺点在于:消息写入磁盘虽然是基于顺序写,但是读的过程确是随机的。读取一条消息会先读取
ConsumeQueue,再读CommitLog,会降低消息读的效率。
消息发送到消息接收的整体流程
- Producer将消息发送到Broker后,Broker会采用同步或者异步的方式把消息写入到CommitLog。RocketMQ所有的消息都会存放在CommitLog中,为了保证消息存储不发生混乱,对CommitLog写之前会加锁,同时也可以使得消息能够被顺序写入到CommitLog,只要消息被持久化到磁盘文件CommitLog,那么就可以保证Producer发送的消息不会丢失。
- commitLog持久化后,会把里面的消息Dispatch到对应的Consume Queue上,Consume Queue相当于kafka中的partition,是一个逻辑队列,存储了这个Queue在CommiLog中的起始offset,log大小和MessageTag的hashCode。

- 当消费者进行消息消费时,会先读取consumerQueue , 逻辑消费队列ConsumeQueue保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量Offset,消息大小、和消息Tag的HashCode值

- 直接从consumequeue中读取消息是没有数据的,真正的消息主体在commitlog中,所以还需要从commitlog中读取消息
什么时候清理物理消息文件?
消息存储在CommitLog之后,的确是会被清理的,但是这个清理只会在以下任一条件成立才会批量删除消息文件(CommitLog):
- 消息文件过期(默认72小时),且到达清理时点(默认是凌晨4点),删除过期文件。
- 消息文件过期(默认72小时),且磁盘空间达到了水位线(默认75%),删除过期文件。
- 磁盘已经达到必须释放的上限(85%水位线)的时候,则开始批量清理文件(无论是否过期),直到空间充足。
若磁盘空间达到危险水位线(默认90%),出于保护自身的目的,broker会拒绝写入服务。
















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











