







Kafka应用场景
Kafka具有很好的吞吐量、内置分区、冗余及容错性的优点(每秒可以处理几十万消息),让Kafka成为一个很好的大规模消息处理应用解决方案。适用于行为跟踪、日志收集等方面
Kafka架构
kafka包括Topic,Partition,Producer(应用节点生产消息,也可以通过Flume收集日志),Broker(kafka包含的服务器,直接使用磁盘进行存储,线性读写,速度快),Consumer Group,以及一个zookeeper集群。kafka通过zookeeper管理集群配置以及协同服务。Producer将消息push到Broker,Consumer订阅并消费消息。与其他mq不同的是,Producer将消息push到Broker,Consumer再从Broker pull消息,而不是Broker主动发送给Consumer。

Topic
topic是一个存储消息的逻辑概念,可以认为是一个消息集合。不同的topic的消息分开存储。

Partition
每个topic可以划分多个分区(且至少一个分区),同一个topic下不同分区包含的消息是不同的。每个消息在被添加到分区时,会分配一个offset,它是在此分区的唯一编号,kafka通过offset保证消息在分区内的顺序,offset不能跨域。

如图对于名字为test的topic,分为三个区,P0、P1、P2。每一条消息发送到broker,会根据partition的规则选择存储到哪一个partition。类似于数据库的分库分表,将数据做了分片处理。
Topic和Partition的存储
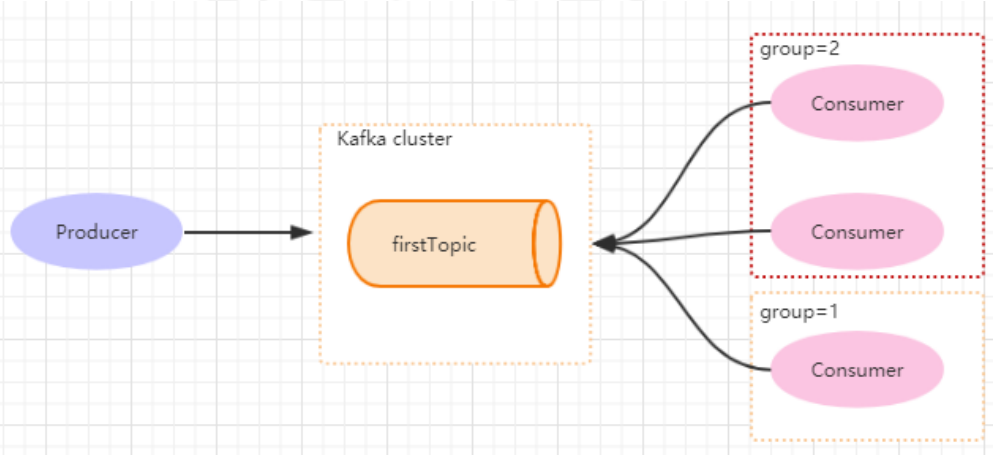
Partition以文件的形式存储在文件系统中,比如一个名为firstTopic的topic,其中有3个partition,那么在kafka的数据目录(/tmp/kafka-log)中就有三个,firstTopic-0~2,<topic_name>-
Kafka安装
- 安装zookeeper
- 配置kafka
修改server.properties,增加zookeeper配置
zookeeper.connect=localhost:2181
启动
sh kafka-server-start.sh -daemon ../config/server.properties
停止
sh kafka-server-stop.sh -daemon ../config/server.properties
- 集群配置
修改server.properties
broker.id=0<!--第一台机器-->
broker.id=1<!--第二台机器-->
broker.id=1<!--第三台机器-->
zookeeper.connect=192.168.2.125:2181
listeners=PLAINTEXT://192.168.2.12:9092分别启动三台机器
sh kafka-server-start.sh -damoen ../config/server.properties
配置参数
异步发送消息
kafka对于消息的发送支持同步和异步,本质上说kafka都是通过异步将消息首先发送到一个队列,然后通过后台线程不断从队列中取出消息进行发送,发送成功出发callback。kafka客户端会积累一定量的消息统一组装成一个批量消息发送出去,触发条件就是batch.size和linger.ms。而同步的方法,是通过future.get()来等待消息的发送返回结果。
batch.size
批量提交消息到broker上同一个分区的字节数大小,默认是16384byte,即16kb。
producer-生产者
每次发送到broker的请求增加的delay,用来聚合更多的message。
batch.size和linger.ms是kafka性能优化的关键参数,两者满足一个就会发送消息。
gruop.id
组id是提供的可扩展且具有容错性的消费者机制。同一个组内会存在多个消费者或消费者实例,共享一个ID,即group.id。组内所有消费者协调订阅主题的所有分区。
enable.auto.commit
消费者消费消息后是否自动提交,只有消息提交后才不会被再次接收到,可以配合auto.commit.interval.ms控制自动提交的频率。也可以通过consumer.commitSync()实现手动提交。
auto.offset.reset
针对新groupid中的消费者
- auto.offset.reset=latest 新的消费者将从其他消费者最后消费的offset处开始消费
- auto.offset.reset=earliest 最早的地方开始消费
- auto.offset.reset=none 之前不存在offset,则会抛出异常
max.poll.records
限制每次poll返回的消息数,可以用来预测每次poll间隔要处理的最大值。
消息消费
在实际生成中,每个topic会有多个partitions,多个partitions的好处是一方面可以利用分片有效减少消息的容量从而提升性能,另一方面为了提高消费的能力,会有多个consumer去消费同一个topic,即消费的负载均衡机制。
consumer和partition
- kafka的设计在partition上不允许并发,即consumer数量不能大于partition数量
- consumer比partition少,则容易出现partition里面的数据被取的不均匀,最好是partition是consumer的整数倍
- consumer从多个partition消费数据,不保证数据的顺序
分区动态配置Rebalance
策略
假定:分区数量10,消费者数量3
p0,p1,p2,p3,p4,p5,p6,p7,p8,p9
c1,c2,c3
- Ranage
n=分区数量/消费者数量=3
m=分区数量%消费者数量=1
则有:c1=n+1=p0,p1,p2,p3;c2=p4,p5,p6;c3=p7,p8,p9
- RoundRobin
c1 p0 p3 p6 p9
c2 p1 p4 p7
c3 p2 p5 p8
- Stricky 粘滞
保持上次的不变,尽可能均匀(优先级高)
Coordinator
coordinator用来对consumer group的管理,消费者向kafka集群中任意broker发送GroupCoorDinatorRequest请求,服务端会返回一个负载最小的broker节点的id,并将该broker设置为coordinator。
在reblance之前,coordinator已经确定了,同时整个reblance分为Join和Sync两个部分。
- Join
在这个过程中每个成员都会向coordinator发送joinGroup的请求。coordinator会选择一个consumer担任leader角色,并把组成元信息和订阅信息发送给消费者。
同时每个消费者将自己的分区分配策略上报,并选举一个都赞同的策略来实现整体的分区分配。
- Sync
完成分配后,进入Synchronizing Group State阶段,向GroupCoordinator发送Sync请求,并处理Sync响应。将partition分配方案同步给consumer group中所有consumer
















 1858
1858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











