







 本文分享了作者在招商银行FinTrch精英训练营数据赛道的参赛经历,重点讲述如何通过对抗检验、数据预处理、特征筛选、对抗验证和模型选择(如使用LGB等简单模型)应对比赛。强调了数据质量、特征理解和模型策略在比赛中的关键作用,以及B榜策略的详细解析。
本文分享了作者在招商银行FinTrch精英训练营数据赛道的参赛经历,重点讲述如何通过对抗检验、数据预处理、特征筛选、对抗验证和模型选择(如使用LGB等简单模型)应对比赛。强调了数据质量、特征理解和模型策略在比赛中的关键作用,以及B榜策略的详细解析。
招商2022FinTrch精英训练营数据赛道方案Rank1
背景
我个人是十分懒的,一直觉得写这些太麻烦了,而且名次也不高,不过既然进面了,咱就好好准备一下。
客户流失预测,经典的二分类问题,评价指标为AUC,数据脱敏,字段只能靠猜
数据只给了train单表,类别特征基本没啥用,零零总总50列。
一天提交三次,不能组队,参赛队伍大概700多?
听说以前是前200进面,今年实际情况是前50,有兴趣的朋友注意一下。不过没进面也没关系,招行奖金给的还是挺香的。
后续更新:
去了线下训练营,二期数据组rank1。 题目还是这个题目,所以基本直接复用了初赛的策略,不得不说这个比赛挑战性略差,而且数据存在leak,难怪线上赛最后一天能从第8掉到30多。。。
由于签了文件,不能直接放代码,就提几个点,供感兴趣的朋友参考。
1、做好对抗检验,数据很脏,需要进行筛选再使用
2、树模型足够了,不需要技术深度,也不需要工程化经验,单纯树+原始给的特征就可以做的很高
3、数据存在leak,不知道后续会不会改进
4、线下赛基本不看数据团队的排名,最后排名还是看产品,所以运气很重要。
总体而言线下训练营还是蛮令人失望的,加上今年改革,好好的管培生offer也没了,后来者来摸个奖就好了,性价比真的不高。
后续更新2:
很多人问代码我就重新开了一下,代码可在我的github中找到
后面就都是初赛的策略了,简单粗暴。做的精细点就好。
正题
这比赛本质还是考察选手对数据的敏感度和对特征的筛选和分析能力。至于模型策略啥的,并不是很侧重,一手lgb足以应付。
比赛分AB榜,最令人吐槽的是AB榜数据分布差异太大,A榜随随便便95+,B榜开局68。。。
所以,A榜没啥好聊的,咱来看看B榜
一、数据
官方给了50维度左右的数据,但是没给字段意思,做特征只能靠猜,不过这之前咱们需要看一下train和test的数据分布情况
首先是label分布情况
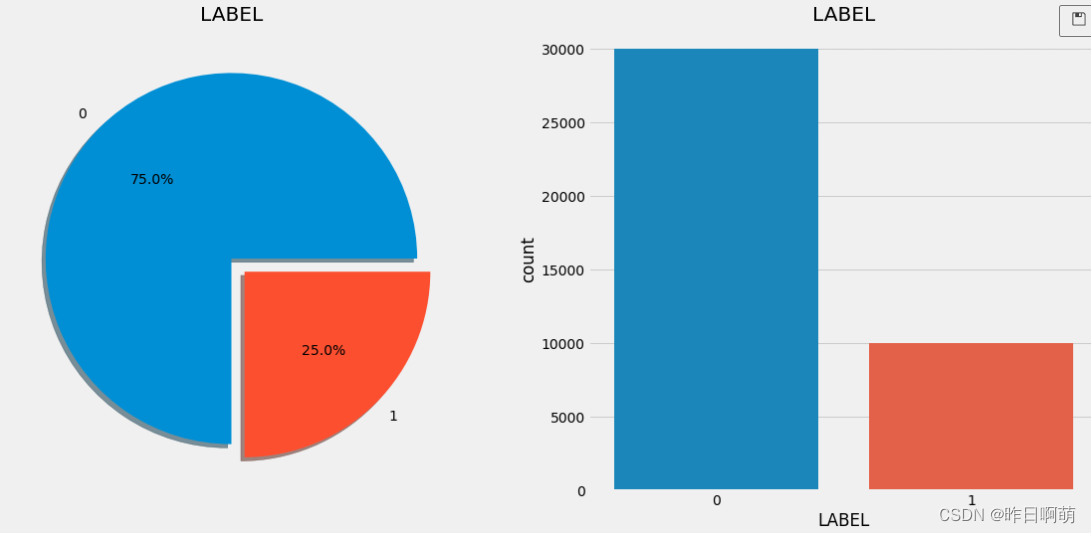
标准的三一比,应该是人工采样过的
数据EDA
主要有三大类:
注: 由于数据均为长尾分布,且数值普遍偏大,为了可视化效果,对这些特征做了log变换
一、数据偏移
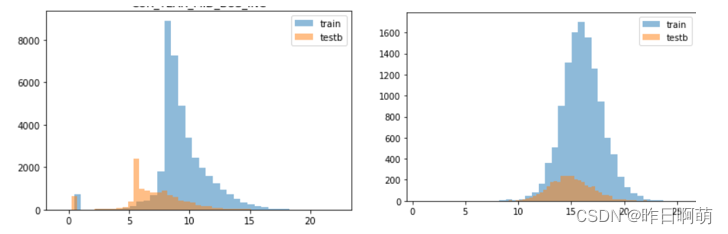
即训练集和测试集的数据分布差异大,对于这种数据的处理方法常用的主要有两种:
1、直接删除。
2、调整分布均值偏移,使其分布一致。
不仅仅是这几列,还有大量的时间类特征也发生了较大偏移
所以推测testb的数据和train的数据并不是同一批。
二、数据脱敏后的异常值
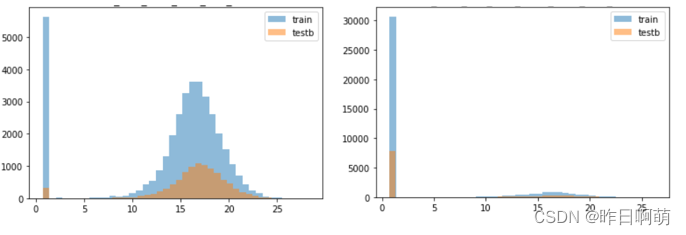
在实际的数据中,会出现大量2的情况,其原因主要可能有三种情况:
1、脱敏将大量为0的值替换为2.
2、脱敏将大量为nan的值替换为2.
3、脱敏后数据溢出
但是有意思的是,上图;两种情况的异常值均为2, 也就是说,我们不能简单的将所有2直接替换为nan或者0,对于不同的特征仍需进一步的精细化处理
三、数据分布不完整
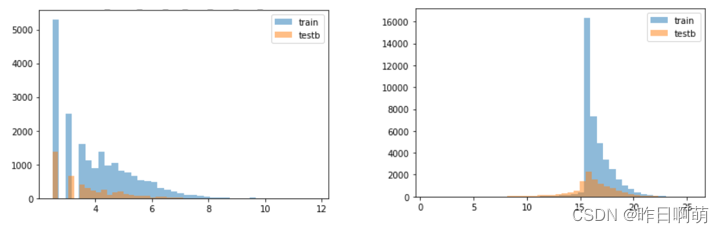
对于这一类的数据说实话没啥比较好的处理方法,在后续的操作中也删了不少
四、特征之间的相似度关系
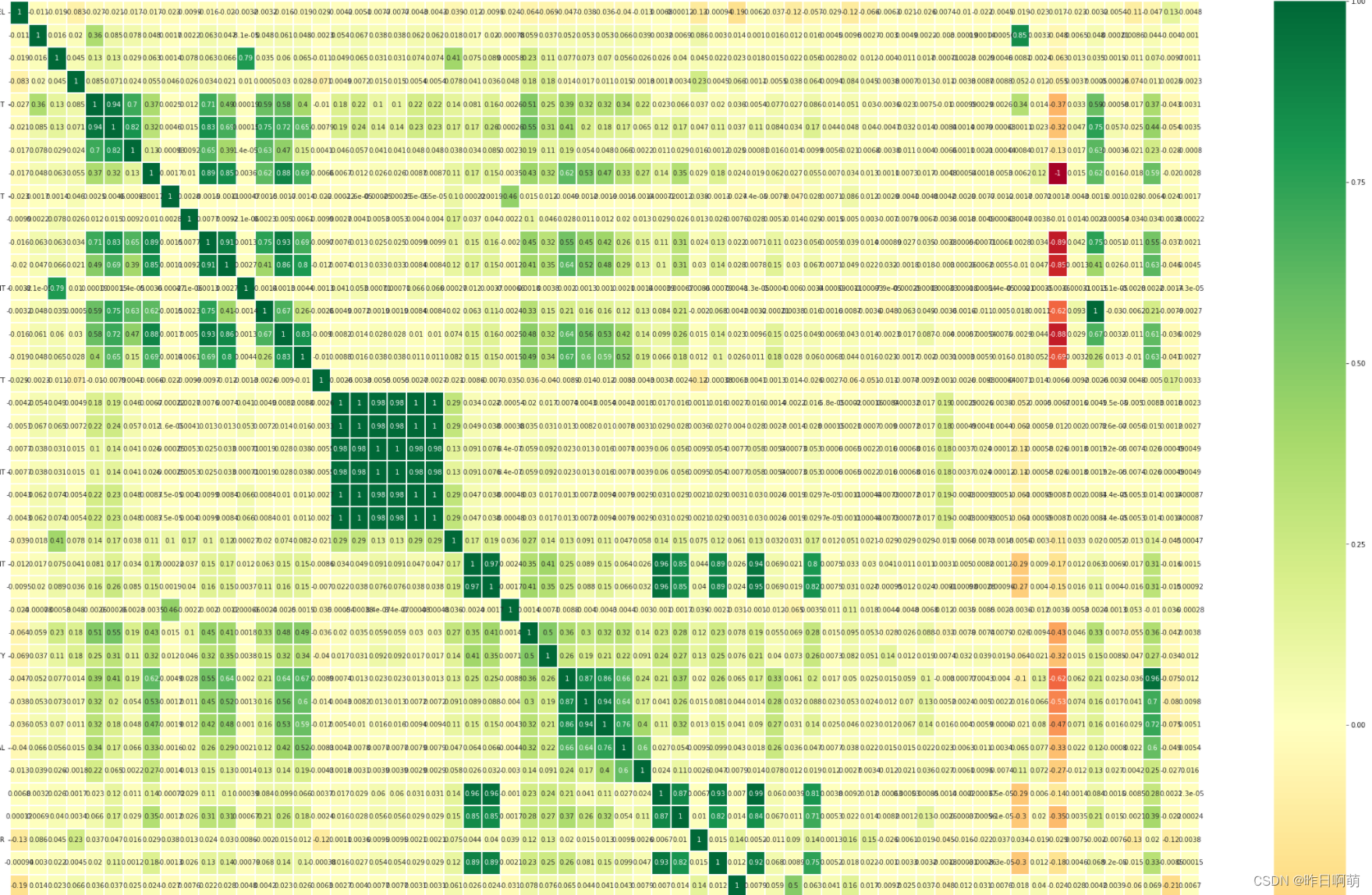
不得不说还是很有意思的,出现了非常多列相似度极高的情况,仔细看一眼数据发现有几列数据基本一致。主办方这是人为下毒嘛?(狗头)
二、特征
由于a榜并没有数据偏移的现象,所以a榜提分主要靠卷特征,b榜之后对之前做的特征进行了进一步的筛选和取舍。
由于数据只给了单表,类别特征又非常的糟糕,所以没啥聚合策略可以做的,那么能做的,也就加减乘除mask的暴力了
不过直接暴力特征维度太高了,而且会生成相当量级的冗余特征,我们使用相似度简单过滤一下
original_fea = list(train.columns)[2:]
corr_fea = test[list(test.columns)].corr()
from tqdm import tqdm
history_data = []
very_low_corr_fea = []
print(len(list(corr_fea.columns)[2:]))
for col1 in tqdm(list(train.columns)[2:]):
if col1 in cat_cols: continue
for col2 in list(corr_fea[col1][abs(corr_fea[col1] )> 0.3].index):
if col1 == col2 or sorted([col1,col2]) in history_data: continue
history_data.append(sorted([col1,col2]))
train[f'corr_{col1}_{col2}_diff'] = train[col1] - train[col2]
train[f'corr_{col1}_{col2}_rate'] = train[col1]/train[col2]
test[f'corr_{col1}_{col2}_diff'] = test[col1] - test[col2]
test[f'corr_{col1}_{col2}_rate'] = test[col1]/test[col2]
print(len(history_data))
当然我们也可以对多列特征之间做交叉
def get_row_fea(df,features):
for fea in features:
df[f'{fea[0]}_{fea[1]}_std'] = df[fea].std(1)
df[f'{fea[0]}_{fea[1]}_max'] = df[fea].max(1)
df[f'{fea[0]}_{fea[1]}_min'] = df[fea].min(1)
df[f'{fea[0]}_{fea[1]}_sub'] = df[fea[0]] - df[fea[1]]
df.loc[df[fea[0]] <= df[fea[1]], f'{fea[0]}_{fea[1]}_mark'] = 0
df.loc[df[fea[0]] > df[fea[1]], f'{fea[0]}_{fea[1]}_mark'] = 1
return df
根据对字段含义的猜测,我又手搓了几个比较有实际意义的特征,但这里注意,可能会和之前暴力生成的特征出现重复,怎们办的,算算相似度删除掉相似度过高的特征吧
corr_fea = train[list(train.columns)].corr()
drop_data = ['CUR_YEAR_MON_AGV_']
very_low_corr_fea = []
print(len(list(corr_fea.columns)[2:]))
#print(corr_fea)
for col1 in tqdm(list(train.columns)[2:]):
if col1 in cat_cols: continue
for col2 in list(corr_fea[col1][corr_fea[col1] == 1].index):
if col1 == col2 or sorted([col1,col2]) in drop_data: continue
drop_data.append(sorted([col1,col2]))
for col in drop_data:
if (col[0] in list(train.columns)) and (col[1] in list(train.columns)):
train = train.drop([col[0]], axis=1)
test = test.drop([col[0]], axis=1)
然后,,,,然后就没了,这个比赛的类别特征基本无用,也没有多表聚合,感觉可操作的空间不是很大。
三、对抗验证筛选特征
这个主要是针对b榜,数据分布差异较大所采用的。这里简单说下思路,代码之后我会上传到我的github中
两中变体策略:
1、concat训练测试集,建立新的label列,train为0,test1.我们使用一个二分类模型来判断当前数据是否为测试数据。打印二分类模型的特征重要性。特征越重要说明该特征在train和test上的分布差异越大。
2、与上一种方法类似,但是我们每次只使用一个特征,计算以该特征训练的ROC-AUC,最后得到的AUC分数越高,说明该特征越能区分train和test,也就是越需要被删除。
四、null importance 特征筛选
方案出自kaggle,具体链接忘记了,直接搜应该就有
当我们删除掉了一些分布差异较大的特征之后,剩余的特征可能仍然存在相当量级的无用特征,如何将这些无用特征剔除提升我们的模型性能呢?
1、首先我们使用真实标签进行训练,得到特征的重要性分数保存。
2、随机打乱标签,对打乱后的标签进行训练,打印特征重要性分数。这里可能需要根据实际情况多做几次,取重要性的均值或众数。
3、对于前两步骤的重要性分布情况,如果1中的重要性远高于2中的重要性,说明该特征是有效特征,反之说明该特征为无效特征。
对比一下下面两个图就能明白了
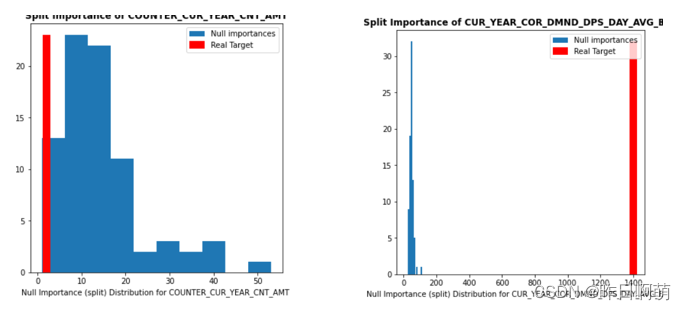
右图则是我们期望的特征重要性分布情况
五、模型
这里我就不多说了,lgb,xgb,catboost轮流上,最后融就行了
当然,融也看你怎么融,直接取平均加权重还是stacking。
stacking我的策略是第一层lgb,xgb,cat。 第二层是lr。 当然也试过lgb,不过效果一般
这里做stacking注意,训练lr的数据应当是第一层valid的预测值,不然会导致过拟合。面试可能会问。
可惜最后没融上去,羡慕他们融一下上个2-30来名的,下次多留点机会梭哈。


















 6467
6467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









