







概念抛出:
操作关系型数据库的数据:RDBMS ==> Sqoop ==> Hadoop
操作非关系型数据库的数据(比如说分散在各个服务器的日志)?==>Hadoop
引出Flume概念:
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
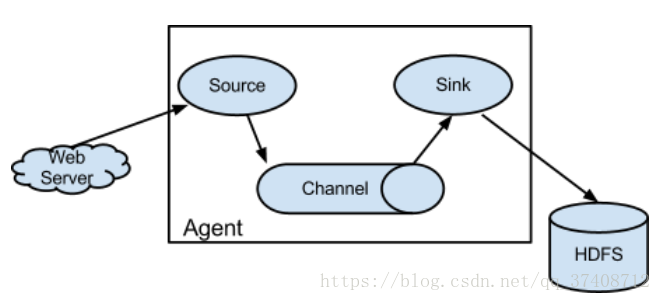
collecting 采集 source
aggregating 聚合 channel (找个地方把采集过来的数据暂存处理)
moving 移动 sink
Flume要点:编写配置文件,组合source、channel、sink三者之间的关系
Agent:就是由source、channel、sink组成
编写flume的配置文件其实就是配置agent的构成
总结:Flume就是一个框架:针对日志数据进行采集汇总的一个工具,把日志从A地方搬运到B地方去
Flume部署:
1) 下载(在后方链接找相应版本):http://archive.cloudera.com/cdh5/cdh/5/
2) 解压到~/app
3) 添加到系统环境变量 ~/.bash_profile
export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
4) $FLUME_HOME/conf/flume-env.sh
JAVA_HOME
FLUME的简单配置模型:
从指定的网络端口上采集日志到控制台输出
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动FLUME:
./flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file /home/hadoop/script/flume/simple-flume.conf \
-Dflume.root.logger=INFO,console \
-Dflume.monitoring.type=http \
-Dflume.monitoring.port=34343
telnet localhost 44444 客户端连接到FLUME
随便输入一条数据,FLUME端打印:
Event: 一条数据
Event: { headers:{} body: 4C 79 6E 6E 0D Lynn. }
Event:headers + body(字节数组)
Flume支持的source、channel、sink简介:
source
avro
exec : tail -F xx.log
Spooling Directory:
Taildir
netcat
sink
HDFS
logger
avro : 配合avro source使用
kafka
channel
memory
file
Agent:组合各种source、channel、sink之间的关系
用法举例:
需求:采集指定文件的内容到HDFS
技术选型:exec - memory - hdfs
./flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file /home/hadoop/script/flume/exec-memory-hdfs.conf \
-Dflume.root.logger=INFO,console \
-Dflume.monitoring.type=http \
-Dflume.monitoring.port=34343
需求:采集指定文件夹的内容到控制台
选型:spooling - memory - logger
./flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file /home/hadoop/script/flume/spooling-memory-logger.conf \
-Dflume.root.logger=INFO,console \
-Dflume.monitoring.type=http \
-Dflume.monitoring.port=34343
taildir
./flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file /home/hadoop/script/flume/taildir-memory-logger.conf \
-Dflume.root.logger=INFO,console \
-Dflume.monitoring.type=http \
-Dflume.monitoring.port=34343














 5586
5586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









