






前言
深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,可以直接根据输入的图像进行控制,是一种更接近人类思维方式的人工智能方法。 DQN简单来说就是Q-Learning和深度神经网络的结合。一、Q-Learning算法
强化学习并不是某一种特定的算法,而是一类算法的统称,与有监督学习、无监督学习共称为机器学习的三大分支。
对于监督学习我们都不陌生,这种方法是在有标注数据的前提下可以高效的学习各类别对应的数据特征。而强化学习一开始并没有标注数据,它需要在对应环境中不断尝试进而获取相关数据和标签信息,然后根据学到的数据信息掌握可以带来高分的行为选择。
尤其是近年来深度学习技术的迅速发展,强化学习在学术界和工业界有了进一步地运用,比如让计算机学着玩游戏;再比如在对话系统中可以借助强化学习快速的针对对话状态做出行为反馈,无需人工维护。
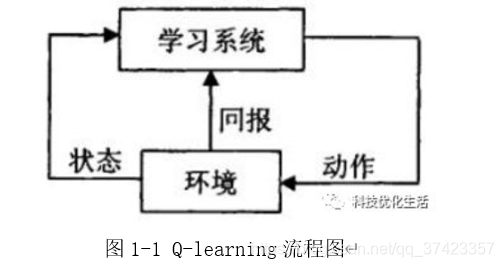
Q-Learning是强化学习算法中值迭代的算法,Q即为Q(s,a)就是在某一时刻的 s 状态下(s∈S),采取 a (a∈A)动作能够获得收益的期望,环境会根据agent的动作反馈相应的回报reward r,所以算法的主要思想就是将State与Action构建成一张Q-table来存储Q值,然后根据Q值来选取动作获得较大的收益。
Q-Learning始终是选择最优价值的行动,在实际项目中,Q- Learning充满了冒险性,倾向于大胆尝试。流程图如图1-1所示。
二、DQN算法
Off-policy是Q-Learning的特点,DQN中也延用了这一特点。而不同的是,Q-Learning中用来计算target和预测值的Q是同一个Q,也就是说使用了相同的神经网络。这样带来的一个问题就是,每次更新神经网络的时候,target也都会更新,这样会容易导致参数不收敛。回忆在有监督学习中,标签label都是固定的,不会随着参数的更新而改变。
DQN使用神经网络来近似值函数,即神经网络的输入是state。
我们使用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值。
但当问题更加复杂的时候,如果我们还用表格来存储的话,那么就算计算机内存再大也不够使用。DQN就说使用神经网络来分析得到Q值,而没有必要把Q值记录在表格中,而是直接使用神经网络生成的Q值。DQN的算法流程图如图2-1所示:
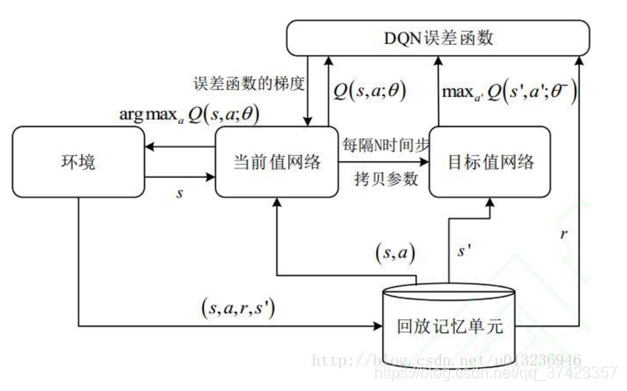
图2-1 DQN算法流程图
1.经验回放
DQN的输入是我们的状态s对应的状态向量ϕ(s), 输出是所有动作在该状态下的动作价值函数Q,主要使用的技巧是经验回放(experience replay),即将每次和环境交互得到的奖励与状态更新情况都保存起来,用于后面目标Q值的更新。为什么需要经验回放呢?我们回忆一下Q-Learning,它是有一张Q表来保存所有的Q值的当前结果的,但是DQN是没有的,那么在做动作价值函数更新的时候,就需要其他的方法,这个方法就是经验回放。
其实就是反复试验,然后存储数据。接下来数据存到一定程度,就每次随机采用数据,进行梯度下降。他根据每次更新所参与样本量的不同把更新方法分为增量法(Incremental Methods)和批处理法(Batch Methods)。前者是来一个数据就更新一次,后者是先攒一堆样本,再从中采样一部分拿来更新Q网络,称之为“经验回放”。
2.灾难性遗忘
灾难性遗忘即学习了新的知识之后,几乎彻底遗忘掉之前习得的内容。
深度学习的结构一旦确定,在训练过程中很难调整。神经网络的结构直接决定学习模型的容量。固定结构的神经网络意味着模型的容量也是有限的,在容量有限的情况下,神经网络为了学习一个新的任务,就必须擦除旧有的知识。
深度学习的隐含层的神经元是全局的,单个神经元的细小变化能够同时影响整个网络的输出结果。另外,所有前馈网络的参数与输入的每个维度都相连,新数据很大可能改变网络中所有的参数。我们知道,对于本身结构就已经固定的神经网络,参数是关于知识的唯一变化量。如果变化的参数中包含与历史知识相关性很大的参数,那么最终的效果就是,新知识覆盖了旧的知识。
3.贪心选择策略
greedygreedy策略,顾名思义,是一种贪婪策略,它每次都选择使得值函数最大的action,即at=maxaQ(St,a;ω)at=maxaQ(St,a;ω)。但是这种方式有问题,就是对于采样中没有出现过的(state, action) 对,由于没有评估,没有Q值,之后也不会再被采到。
其实这里涉及到了强化学习中一个非常重要的概念,叫Exploration & Exploitation,探索与利用。前者强调发掘环境中的更多信息,并不局限在已知的信息中;后者强调从已知的信息中最大化奖励。而greedygreedy策略只注重了后者,没有涉及前者。所以它并不是一个好的策略。
而ϵ−greedyϵ−greedy策略兼具了探索与利用,它以ϵϵ的概率从所有的action中随机抽取一个,以1−ϵ1−ϵ的概率抽取at=maxaQ(St,a;ω)at=maxaQ(St,a;ω)。
强化学习正是因为有了探索Exploration,才会常常有一些出人意表的现象,才会更加与其他机器学习不同。例如智能体在围棋游戏中走出一些人类经验之外的好棋局。
使用神经网络Q Network作为Q表的函数逼近器,输入时状态(State),输出是Q-value,动作选择策略使用的是e-greedy法则。
三、实验结果
实验参数如下:
无人机运动学模型:最高速度[pixel/s],最高旋转速度[rad/s],加速度[pixel/ss],旋转加速度[rad/ss],速度分辨率[pixel/s],转速分辨率[rad/s]]。
1)Kinematic=[100,1.2,80,0.6,3,0.08];
2)训练轮数E=10; 每轮迭代点数M=1。
3)机器人的初期状态[x(m),y(m),yaw(Rad),v(m/s),w(rad/s)],goal为目标点。
x=[46 79 0 0 0]; goal=[440 420];
4). 贪婪系数Const.eps=0.5;
退火系数Const.anneal=0.95;
缓存区大小Const.BufferSize=50;
batch大小Const.BatchSize=10。
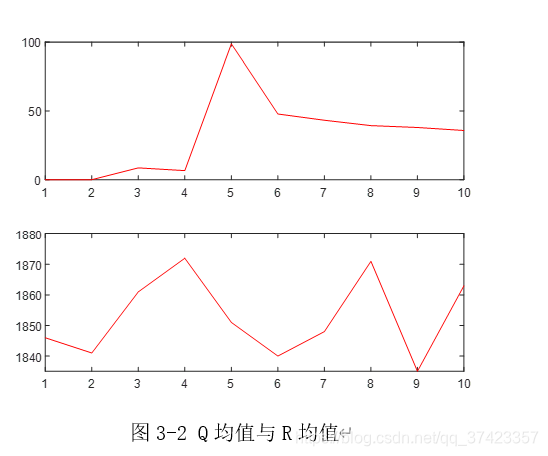
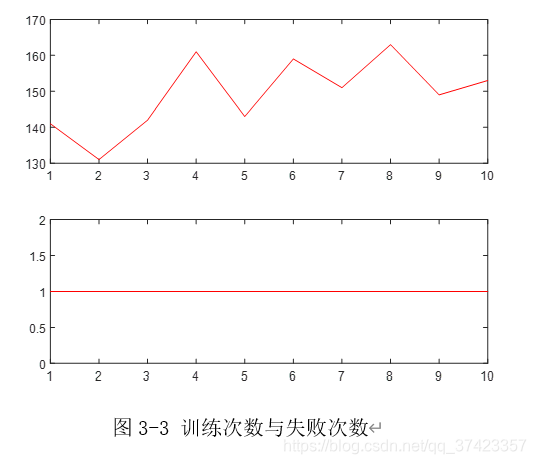
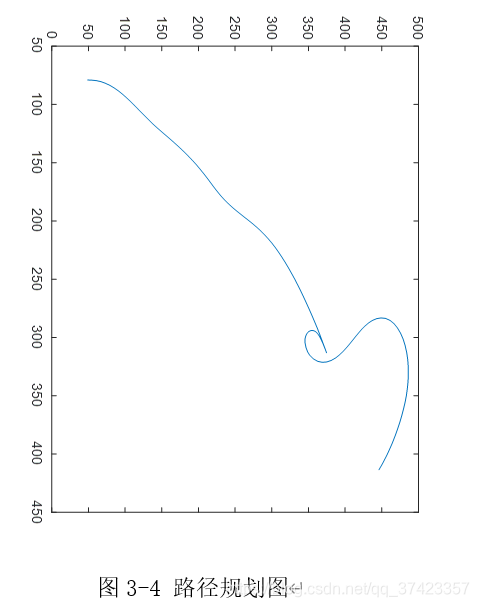
四、总结
通过本次实验,明确了DQN算法的大致流程,接下来要进一步了解代码中的子函数。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









