







三种排序算法的介绍
插入排序:插入排序分为2种,直接插入排序和折半插入排序。插入排序的算法很简单,即从第二个元素开始,标记当前元素,从前扫描数组,每扫描一个数组中的数就将其往后移动一位,直到遇到一个小于(或大于,与排序顺序有关)标记元素的数,至于为什么遇到一个就可以停止当前循环,是因为遇到的这个小于标记元素的数前面的所有数据都已经被排好次序了。折半插入排序则是利用了这一点,使得扫描的次数更快一点,折半插入排序和直接插入排序不同的一点是,直接插入排序是边扫描边往后移动数据,而折半插入排序是先用二分法找到插入位置,再移动数组,而且折半插入排序的数组需要从1开始而不是0。两种插入排序的方法本质没有区别,最差情况时间复杂度为O(n^2)。
冒泡排序:冒泡排序是我学的最早的排序方法,实质是非常低效的排序方法(数据量比较小的时候与其他的方法没有区别),其算法是从第一个数据开始,将第一个数据与其后的数据比较,只要不符合排序顺序就交换这两个数据的值,这样经过有限次循环总会将数组按顺序排好。有一种优化方法是设置一个flag值,每次循环开始使就将flag值置0,只有出现数据交换就将flag置1,这样只要有一次内部循环没有发生数据交换(说明数据已按顺序排好),就退出循环,避免了重复的运算。实际上优化与不优化没有多大区别,本来效率就那么低了(笑)。最差情况空间复杂度为O(n^2),虽然和插入排序相同,在数据量较大时实际效率差了很多。
快速排序:快速排序是一种比较快的算法,主要是因为用了分治的思想,也就是递归。主要算法就是先选定一个key值,将数组分为两半,左半部分是比key值小的数,右半部分是比key值大的数,然后对2半部分再次调用该方法,直到无法再分,这样就可以用较短的时间对数组排序,平均时间复杂度为O(nlogn),至于如何计算我会在以后单独写篇文章。
时间测试
#include
#include
#include
#include
#include
#define MAX 10000 using namespace std; void insertDirectedSort(int a[],int lenth){//直接插入排序 int i=0,j=0; int temp=0; for(i=0;i
=0&&a[j]>temp){//循环条件:j没到最前端并且序号j的值比当前值大 a[j+1] = a[j]; --j; } a[j+1] = temp; } } void insertHalfSort(int a[],int lenth){//折半插入排序 for(int i=2;i<=lenth;++i){ a[0] = a[i]; int low = 1; int high = i-1; while(low<=high){//直到找到插入位置,即low>high int m = (low+high)/2; if(a[0]
high;--j)//找到插入位置后把数组后移 a[j+1] = a[j]; a[high+1] = a[0]; } } void bubbleSort(int a[],int lenth){ int flag=1; for(int i=0;i
a[j+1]){ int t=0; t = a[j]; a[j] = a[j+1]; a[j+1] = t; flag = 1; } } } } void quickSort(int a[],int low,int high){ if(low >= high) return; //当low与high相等时就结束当前函数,说明已经排好 int i=low; int j=high; int key=a[low];//令key为数组第一个数 while(i
=a[i]){//与上一循环相反 ++i; } a[j] = a[i]; } a[i] = key;//中间数回归 //分治 //a[i]不用参与递归 quickSort(a,low,i-1); quickSort(a,i+1,high); } int main(){ int a[MAX],a2[MAX],a3[MAX],a4[MAX]; clock_t s1,e1,e2,e3,e4; int num=0; /*给数组赋随机值*/ srand(time(NULL)); for(int i=0;i
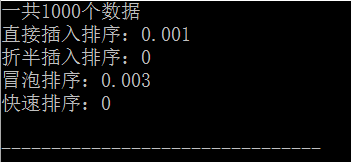
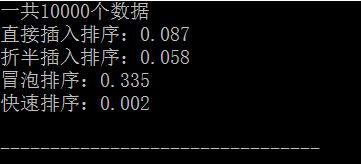
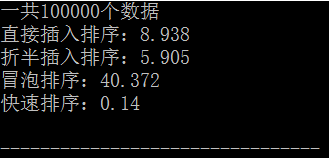
可见冒泡排序的时间比其他排序用时要多的多,而快速排序即使在数据量很大的时候也能花费较少的时间进行排序,是一种oj中常用的排序方法。















 1996
1996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









