







小表驱动大表
为什么小表驱动大表可以看这篇文章
sql优化之查询优化器
in 和 exsits
原则还是小表驱动大表
广为流传的说话: in和exists的连接方式驱动表不同
假设 A 表是左表,B 表是子查询的表。当 A 表是大表, B 表是小表时,使用 in。
select * from A where id in (select id from B)
当 A 表是小表, B 表是大表时,使用 exsits。(exists 后的子查询是被驱动的)
– exists(subquery)只返回 true 或 false,官方也有说过实际执行时会忽略查询列。因此,select * 和 select 1 没区别。
– exists子查询实际执行过程是被优化了的,不是我们之前理解的逐条匹配。
select * from A where exists (select 1 from B where B.id = A.id)
not in 和not exists:如果查询语句使用了not in,那么内外表都进行全表扫描,没有用到索引;而not extsts的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
那么事实是否如此呢
例如我们有两张表erp_travel和erp_travel_cost
explain select * from erp_travel where EXISTS (select travel_no from erp_travel_cost where bearer = erp_travel.user_no and
erp_travel_cost.travel_no = erp_travel.travel_no)
and erp_travel.user_no = '00010413';

在外查询上加了条件erp_travel.user_no = ‘00010413’;,那么相对来说 子查询就是大表,外查询是小表
那么改写成 in查询
explain select * from erp_travel where travel_no in (select travel_no from erp_travel_cost where erp_travel_cost.bearer = erp_travel.user_no)
and erp_travel.user_no = '00010413';
按照上面的说法,直接改成成in,in后的子查询是一个大表,应该很慢。但是实际执行起来发现速度依然很快。
查看explain 结果

可以看出来 ,in查询被sql优化成为了内连接查询,并且自动转化为小表驱动大表连接,所以这个效率还是十分高的,得益于join的优化,甚至比exists效率还要高。
再看一种情况
explain select * from erp_travel where erp_travel.project_no_form in (select max(erp_travel_cost.project_no) from erp_travel_cost where erp_travel_cost.travel_no = erp_travel.travel_no
GROUP BY erp_travel_cost.bearer,erp_travel_cost.project_no
) and erp_travel.user_no = '00010413';
show WARNINGS;

看起来是in后为大表,但是效率也不低,于是打印出sql优化器优化之后的sql
/* select#1 */ select * from `test_bai`.`erp_travel` where <in_optimizer>(`test_bai`.`erp_travel`.`project_no_form`,<exists>(/* select#2 */ select 1 from `test_bai`.`erp_travel_cost` where ((`test_bai`.`erp_travel_cost`.`travel_no` = `test_bai`.`erp_travel`.`travel_no`) and (`test_bai`.`erp_travel_cost`.`creater` <> '00010413')) group by `test_bai`.`erp_travel_cost`.`bearer`,`test_bai`.`erp_travel_cost`.`project_no` having (<cache>(`test_bai`.`erp_travel`.`project_no_form`) = <ref_null_helper>(max(`test_bai`.`erp_travel_cost`.`project_no`)))))
发现in被优化成了exists,
经过本人测试在mysql5.7下。mysql对in的优化已经十分好了,在合适的情况分别转换为exists和内连接提示效率
因此,in 小表, exists 大表也是一个不准确的说法,最终还是要通过执行计划进行分析,但作为一规范还是没问题的。
也就是说,即使使用后了not in 子查询,如果被sql优化之后,还是会使用索引的,但是这种情况,not in 之后不是索引 是不使用缩影的
explain select * from erp_travel where user_no not in( '00022139','0010413');

count查询优化
网上挺多资料说,要count(id)或者count(1),不要count(*),到底是不是这样呢?我们今天就来实践一下。
explain select count(id) from erp_travel; -- 通过索引
explain select count(*) from erp_travel; -- 通过索引
explain select count(1) from erp_travel; -- 通过索引
explain select count(uuid) from erp_travel; -- 全表
可以看出来除了 count 指定非索引字段,效果都是相同的
order by 和 group by 优化
排序和分组的优化其实是十分像的,本质是先排序后分组,遵循索引创建顺序的最左匹配原则。因此,这里以排序为例。
全字段排序(排序字段未使用索引)
- 什么时候使用全字段排序?
- 字段较少,数据量较小,排序可在内存中完成,Mysql 的大部分不走索引的排序都是使用 全字段排序完成的。
- 全字段索引排序流程 - 初始化 sort_buffer,确定放入 name、city、age 这三个字段。
- 从索引 city 找到第一个满足 city='杭州’条件的主键 id。
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到 city 的值不满足查询条件为止。
- 对 sort_buffer 中的数据按照字段 name 做快速排序;
- 按照排序结果取前 1000 行返回给客户端。
- 流程细节
- 整个的排序动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。
- sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。
- 如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。
- 但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。外部排序一般使用归并排序算法。
rowid 排序(排序字段未使用索引)
- 什么时候使用 rowid 排序? - 在 全字段排序 中,只对原表的数据读了一遍,剩下的操作都是在 sort_buffer 和临时文件中执行的。
- 但是存在一个问题,如果查询要返回的字段很多,sort_buffer 放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
- Mysql 认为 全字段排序代价太大,于是使用 rowid 算法排序。
- rowid 排序流程
- 初始化 sort_buffer,确定放入两个字段,即 name 和 id。
- 从索引 city 找到第一个满足 city='杭州’条件的主键 id。
- 到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中。
- 从索引 city 取下一个记录的主键 id。
- 重复步骤 3、4 直到不满足 city='杭州’条件为止。
- 对 sort_buffer 中的数据按照字段 name 进行排序。
- 遍历排序结果,取前 1000 行,并按照** id 的值回到原表中取出 **city、name 和 age 三个字段返回给客户端。
- 流程细节
- 对比 全字段排序流程你会发现,rowid 排序多访问了一次表 的主键索引。
全字段排序 对比 rowid 排序? - 如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。
- 对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择。
排序字段加索引的优点 - 在排序字段有索引的情况下,查询过程不需要临时表,也不需要排序。
- 同时,也不会扫描全部符合条件的行数,而是找到适合条件既会返回数据。
其他在排序中中需要注意的。
- 无条件查询如果只有order by create_time,即便create_time上有索引,也不会使用到。 - 因为优化器认为走二级索引再去回表成本比全表扫描排序更高。所以选择走全表扫描,然后根据老师讲的两种方式选择一种来排序
- 无条件查询但是是order by create_time limit m.如果m值较小,是可以走索引的.
- 因为优化器认为根据索引有序性去回表查数据,然后得到m条数据,就可以终止循环,那么成本比全表扫描小,则选择走二级索引。
- 即便没有二级索引,mysql针对order by limit也做了优化,采用堆排序。
索引覆盖
explain select travel_no from erp_travel where travel_no not like '%sai%';
explain select user_no,user_name,creater from erp_travel where user_name not like '%sai%';
索引覆盖查询结果,那么看起来是是索引失效的情况,实际上也会使用索引
为什么建议主键自增

如果此时再插入一条主键值为 9 的记录,那它插入的位置就如下图:
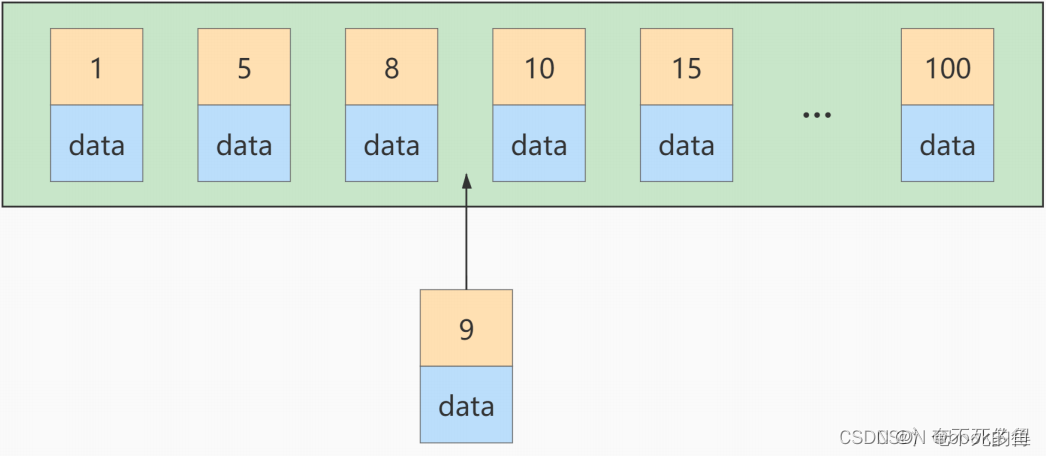
可这个数据页已经满了,再插进来咋办呢?我们需要把当前 页面分裂 成两个页面,把本页中的一些记录移动到新创建的这个页中。页面分裂和记录移位意味着什么?意味着: 性能损耗 !所以如果我们想尽量 避免这样无谓的性能损耗,最好让插入的记录的 主键值依次递增 ,这样就不会发生这样的性能损耗了。
所以我们建议:让主键具有 AUTO_INCREMENT ,让存储引擎自己为表生成主键,
在插入记录时存储引擎会自动为我们填入自增的主键值。这样的主键占用空间小,顺序写入,减少页分裂。
写到这里,其实笔者从始至终都没有直接提及推荐MySQL使用自增主键的原因。但已经对B+树、页分裂等概念做了基本了解的你,相信已经拥有了能够独立推断其中缘由的能力。
MySQL默认的InnoDB存储引擎,为了提高数据的查询效率选用叶子节点为双向链表连接的B+树作为数据存储结构,使得每一条数据都按照关键字有序排列好,在进行查找操作时,只需通过关键字即可快速定位数据位置。
与此同时,InnoDB引擎以页作为磁盘和内存交互的基本单位,为了保证每一条数据都能够有序的存储,每一次进行插入操作时,都有可能触发“页分裂”操作,因而拉低插入操作的效率。就如同我们为了提高某个字段的查询效率而为其增加辅助索引一般,虽然提高了查询效率,但伴随而来的“副作用”则是数据插入效率的降低。
“在程序猿的世界里,鱼和熊掌很难做到兼得,为了某一目的,你总得牺牲些什么。”
使用自增主键能够最大程度的避免“页分裂”的发生,从而减少这种“牺牲”的出现,同时也是解决该问题最便捷、有效的方法之一。
当然,还是那句话,我们很难做到两全其美的事情,使用自增主键是最便捷的,但绝对不是最优的解决方案,其也会为我们带来一定的“副作用”。
失效
索引失效
- like 以%开头,索引无效;当like前缀没有%,后缀有%时,索引有效。
原因也很简单 索引的B+树按照索引的值排序,而字符串 又是根据前缀权重大排序的 例如 字符串 “12” 小于 字符串 “2”也因此 如果模糊查询,%不在前面还是可以使用到索引的。
explain select * from erp_travel where travel_reason like '测试%商%'

- or语句前后没有同时使用索引。
explain select * from erp_travel where travel_reason like '测试%商%' or user_no= '00022139'

如果or两边都有索引,那么会分别走对应索引,然后合并在一起,type为index_merge
如果有一个不是索引,直接全表,就没必要再单走一个索引了
explain select * from erp_travel where travel_reason like '测试%商%' or creater= '00022139'

- 组合索引,不是使用第一列索引,索引失效。
联合索引user_no, user_name, creater
explain select * from erp_travel where creater = '00022139' and user_no= '00022139'
explain select * from erp_travel where creater = ‘00022139’ and user_no= ‘00022139’
可见,对于联合索引 并不要求写的顺序符合最左前缀匹配,但是使用索引的只决定了使用联合索引的长度
- 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
explain select * from erp_travel where user_no= 00022139

- 在索引列上使用 IS NULL 或 IS NOT NULL操作(未必失效)
索引是不索引空值的,所以这样的操作不能使用索引,可以用其他的办法处理,例如:数字类型,判断大于0,字符串类型设置一个默认值,判断是否等于默认值即可。(此处是错误的说法!)
试验
explain select * from erp_travel where user_no is null -- 走索引
由此可发现有使用到索引
总结:在索引列上使用 IS NULL 或 IS NOT NULL操作,索引不一定失效!!!
- 在索引字段上使用not,<>,!=。
不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描。 优化方法: key<>0 改为 key>0 or key<0(很愚蠢的办法,还不如全表扫描)。
explain select * from erp_travel where user_no > '00022139' -- 走索引
explain select * from erp_travel where user_no > '00022139' or user_no < '00022139' -- 不走索引
explain select * from erp_travel where user_no != '00022139' -- 不走索引
- 对索引字段进行计算操作、字段上使用函数。(索引为 emp(ename,empno,sal))
explain select max(create_time) from erp_travel where user_no like CONCAT('000122','%') --函数不在索引上还能走索引
explain select max(create_time) from erp_travel where left(user_no ,2) ='00'--不走索引
- 当全表扫描速度比索引速度快时,mysql会使用全表扫描,此时索引失效。
如果mysql估计使用全表扫描要比使用索引快,则不使用索引
- 分页不走索引
分页查询,系统十分常见的查询,建议大家学习完后,赶紧看下自己负责的分页功能是否走索引了,或者是否走了索引但是还能优化。以下,看例子来说一些优化手段。
select * from employees limit 10000, 10;
直接查询,不走索引
explain select * from erp_travel order by travel_no limit 10000, 10; --二级索引不走索引
explain select * from erp_travel order by id limit 10000, 10; -- 主键 走索引。。
explain select * from erp_travel order by travel_no limit 10; --走索引
sql优化器认为 二级索引回表的速度不如直接全表io效率高,实际上,索引占用内存小,在limit数据量大的情况下,不仅减少io次数,还能节省内存,可见,sql优化器并不一定是对的
来看网上的分页优化办法
explain select e.* from erp_travel e inner join (select id from erp_travel order by `travel_no` desc limit 10000, 10) t on t.id = e.id;
这个思路非常有意思,利用索引本身存储 id,一页可以存储很多数据,减少了io次数,limit获取的而数据也节省了很多内存,这样limit就节省了很多内存,提升limit的效率,然后,取出主键,再用主键连接erp_travel,这样查聚簇索引的叶子节点,只查了10条。大大减少了io次数,在数据量大时效果十分明显
前面说了,**sql优化器并不一定是对的,**强制指定索引可以提升查询效率
select * from app_user_copy1 force index(`key`) order by app_user_copy1.key desc limit 100000, 10;
如何建索引
老生常谈的东西了,面试也经常问,这里就做个总结。
对于如何建索引这个问题,我个人觉得应该从以下几个角度思考:
什么场景要建索引
应该挑选哪些字段建索引,字段的大小,字段的类型
索引的数量
什么场景要建索引
高频查询,且数据较多,能够通过索引筛选较多数据
表关联
统计,排序,分组聚合
应该挑选哪些字段建索引,字段的大小,字段的类型
高频查询,更新低频,并且可以过滤较多数据的字段
用于表关联的关联字段
用于排序,分组,统计等等的字段
作为建索引的字段尽量小,可以降低树的高度,具体规则看下面的阿里规范
索引的数量
索引的数量要尽量的少。
因为索引是会占空间的;
记录更新数据库记录时,是有维护索引的成本的,数量越多,维护成本越高;
一张表索引过多,当一个条件发现多个索引都生效时,优化器一般会挑选性能最好的那个索引来用,数量多,优化器的挑选的成本也会上升。
尽量不要在过滤数据不多的字段建立索引,如:性别。
where 与 order by 冲突时,优先处理 where。















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









