










目录
前言:
由于最近在学习知识图谱的实体命名问题,在实验中,我们对于词语的处理使用word2vec进行降为因此对于这个工具,基本的情况需要进行了解.
10.1 词嵌入(word2vec)
10.1.1 为何不采用one-hot向量
one-hot向量表示词(字符为词), 假设一个词的索引为iii,为了得到该词的one-hot向量表示,我们创建一个全0的长为NNN的向量,并将其第iii位设成1.one-hot词向量无法准确表达不同词之间的相似度,如我们常常使用的余弦相似度
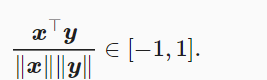
由于任何两个不同词的one-hot向量的余弦相似度都为0
它将每个词表示成一个定长的向量,并使得这些向量能较好地表达不同词之间的相似和类比关系。word2vec工具包含了两个模型,即跳字模型(skip-gram)[2] 和连续词袋模型(continuous bag of words,CBOW)
10.1.2 跳字模型
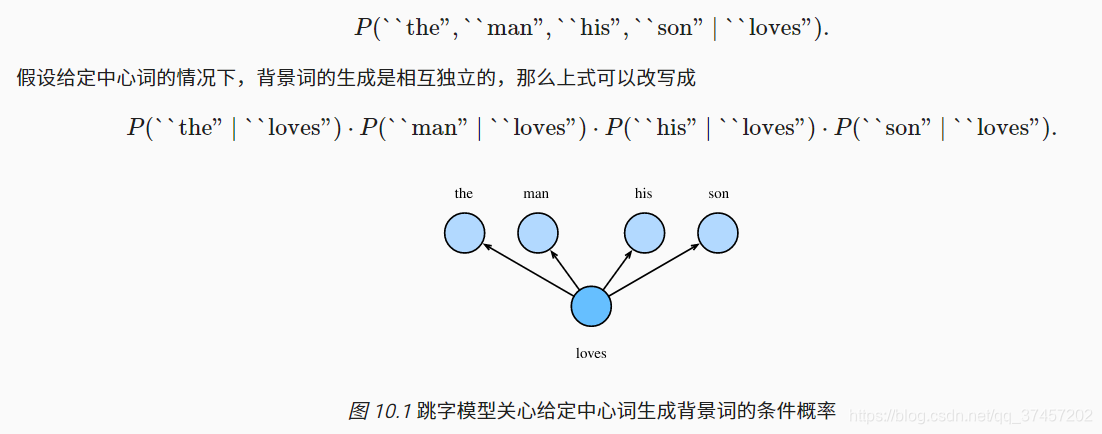
假设文本序列是“the”“man”“loves”“his”“son”。以“loves”作为中心词,设背景窗口大小为2。
关于SoftMax:https://blog.csdn.net/lz_peter/article/details/84574716
扩展到更为一般:
假设给定中心词的情况下背景词的生成相互独立,当背景窗口大小为mm时,跳字模型的似然函数即给定任一中心词生成所有背景词的概率
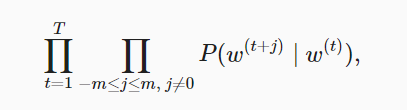
10.1.2.1. 训练跳字模型¶

10.1.3. 连续词袋模型¶
连续词袋模型假设基于某中心词在文本序列前后的背景词来生成该中心词
这部分有许多公式的推导
10.2 近似训练
跳字和连续磁词袋这部分是类似的,所以以一个进行讲解。负采样(negative sampling)或层序softmax(hierarchical softmax)
10.2.1 负采样
由于正类样本导致当所有词向量相等且值为⽆穷⼤时,以上的联 合概率才被最⼤化为1。很明显,这样的词向量毫⽆意义。
负采样通过采样并添加负类样本使⽬标函数 更有意义
设背景词Wo出现在中心词Wc的一个背景窗口为事件P,我们根据分布P(w )采样K个未出现
在该背景窗口中的词,即噪声词。设噪声词Wk (k= 1,..., K)不出现在中心词wc的该背景窗口为事
件Nr。假设同时含有正类样本和负类样本的事件P, N1,..., Nr相互独立,负采样将以上需要最大化
的仅考虑正类样本的联合概率改写为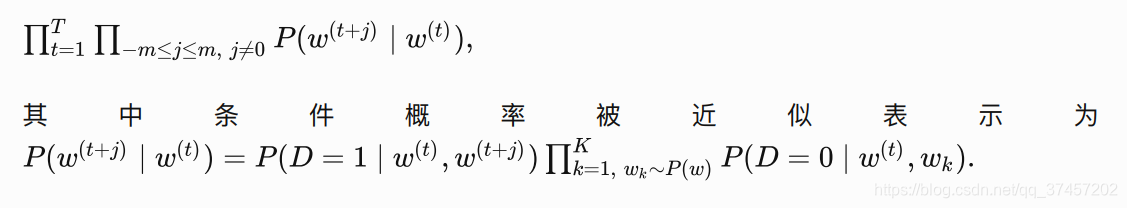
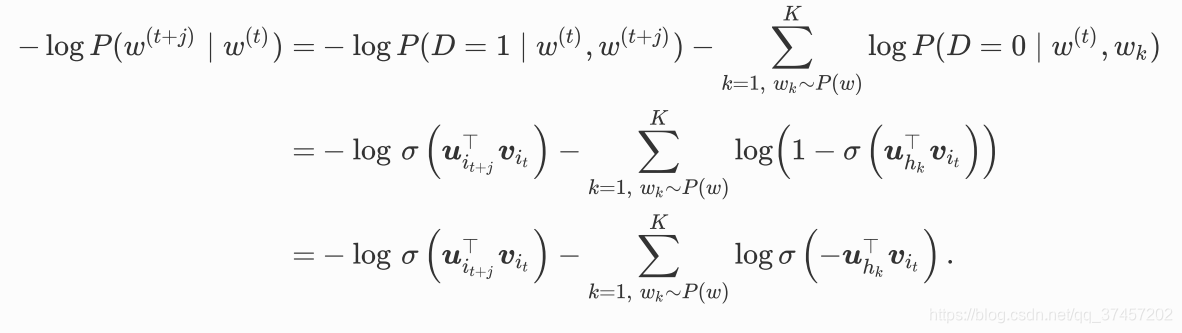
训练中每⼀步的梯度计算开销不再与词典⼤⼩相关,⽽与 K线性相关。当看k(噪声词---未出现的词) 取较⼩的常数时,负 采样在每⼀步的梯度计算开销较⼩。
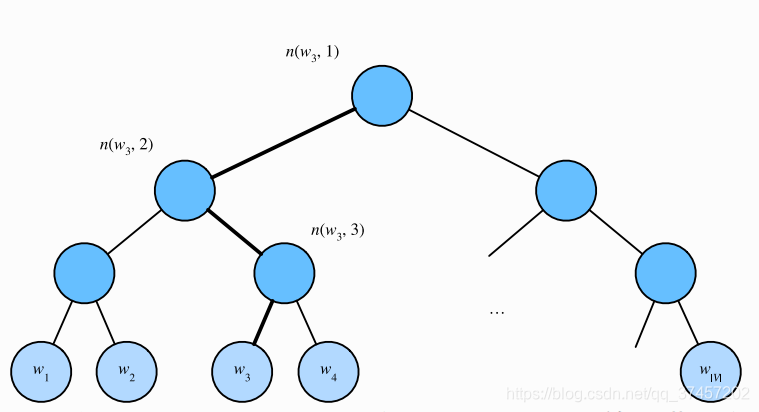
10.2.2 层序SOFTMAX
它使⽤了⼆叉树这⼀数据结构,树的每个叶结点代表词典 中的每V 个词
小结:
- 负采样通过考虑同时含有正类样本和负类样本的相互独立事件来构造损失函数。其训练中每-一步的梯度计算开销与采样的噪声词的个数线性相关。
- 层序softmax使用了二叉树,并根据根结点到叶结点的路径来构造损失函数。其训练中每一步的梯度计算开销与词典大小的对数相关。
10.3 WORD2VEC的实现
具体的代码放到了github上也添加了一些自己学习的一些笔记
需要注意的
在应用部分:需要注意的是:

当我们得到词向量后,我们可以根据词向量的余弦公式进行计算
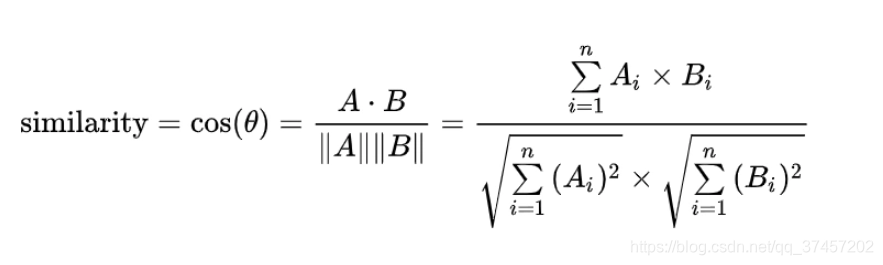
越趋近于1时两个向量的夹角越小,也代表两个文本越相似
运行结果 词性与chip接近

10.4 使⽤预训练模型GloVe的词向量
我们使用的预训练模型是 GloVe

返回的实例主要由以下几个属性
- stoi : 词到索引的字典:
- itos : ⼀个列表,索引到词的映射;
- vectors : 词向量。
10.4.1 近义词
与我们使用word2vec一样,我们也需要计算词向量之间的相似度
思想类似于KNN(k近邻)因此我们设置成如下

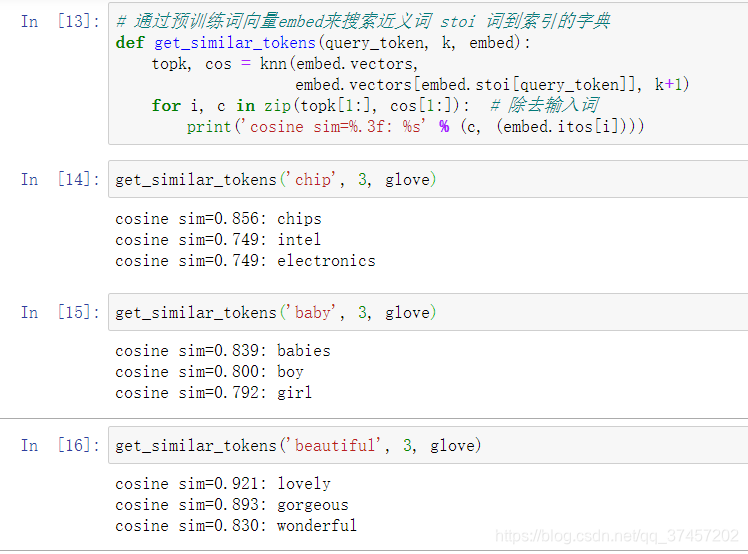
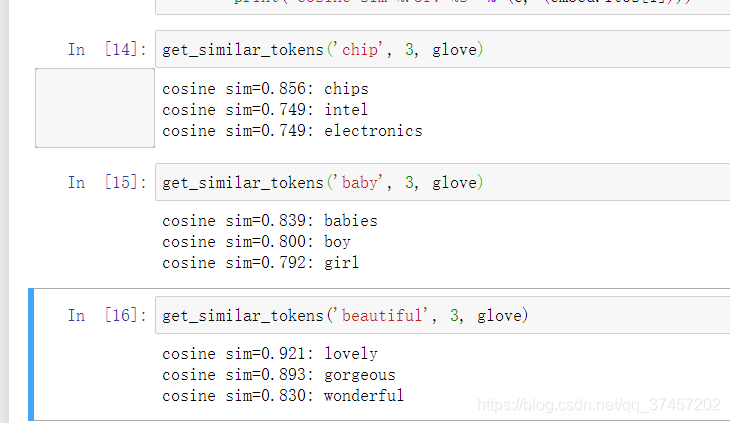
使用该模型我们可以得到的效果更为的良好
10.4.2 求类比词
求类⽐词问题可以定义为:对于类⽐关系中的4个词 a:b ::c:d ,给定前3个词 a、b 和 ,c求d 。设词w的词向量为vec(w)
求类⽐词的思路是,搜索与![]() 的结果向量最相似的词向量。
的结果向量最相似的词向量。
实现代码:


参考文献:
原文链接:https://zh.d2l.ai/chapter_natural-language-processing/word2vec.html
极大似然估计:http://fangs.in/post/thinkstats/likelihood/
softmax函数:https://blog.csdn.net/lz_peter/article/details/84574716
词向量余弦算法计算文本相似度:https://blog.csdn.net/qq_28851503/article/details/97616249
条件随机场 ConditionalRandom Field,CRF


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









