









文章目录
介绍
表引擎是ClickHouse一大特色,决定了表数据的存储方式,包括:
- 数据的存储方式和位置;
- 支持的查询方式,以及如何支持;
- 并发数据访问;
- 索引的使用;
- 多线程请求;
- 数据复制参数。
表引擎使用时必须显式在创建表时定义该表使用的引擎,以及引擎参数,注意引擎名大小写敏感。
支持的表引擎
TinyLog
以列文件的形式将数据保存在硬盘上,不支持索引,没有并发控制,可用作保存少量数据。
scentos :) create table t_tinylog ( id String, name String) engine=TinyLog;
CREATE TABLE t_tinylog
(
`id` String,
`name` String
)
ENGINE = TinyLog
Query id: 1875eb5a-209d-47ad-9d5d-a4a551f80926
Ok.
0 rows in set. Elapsed: 0.002 sec.
Memory
内存引擎,将数据以未压缩的原始形式直接保存到内存中,服务器重启数据丢失,读写不会相互阻塞,不支持索引,再简单查询下有着很高的性能。内存引擎一般用来测试,即性能需求高,且数据量不太大(不超过一亿行)的场景。
MergeTree
ClickHouse中最强大的表引擎就是合并树MergeTree,该引擎支持索引和分区,也派生出很多子类引擎。
为了举例,我们先建一张表:
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
再插入数据:
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
order by
必选选项,设定了分区内数据按照哪些字段排序,在不设置主键的情况下,进行去重、汇总等操作时会会依照order by字段进行处理。
主键必须以order by字段为前缀,比如order by字段为(a, b),那么主键只能是a或者(a, b)
partition by分区
分区的目的是为了降低扫描范围,优化查询速度。如果不填,默认为一个分区。
MergeTree是以列文件+索引文件+表定义文件组成的,如果设定了分区,那么这些文件会保存到不同的分区目录中,且ClickHouse会以分区为单位并行处理跨分区的查询统计。
任何批次的数据写入都会产生一个临时分区,该临时分区不会纳入任何一个已有分区,写入后一段时间,ClickHouse会自行将临时分区合并到已有分区中,我们也可以通过optimize命令手动执行合并:
optimize table table_name final;
上例中,我们的表数据按年月日格式的create_time列分区,我们可以查看一下数据:
scentos :) select * from t_order_mt;
SELECT *
FROM t_order_mt
Query id: a98c9b62-3053-43e3-8675-66613cd5fed6
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
6 rows in set. Elapsed: 0.003 sec.
再执行一次写入,并立刻查询:
scentos :) insert into t_order_mt values
:-] (101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
:-] (102,'sku_002',2000.00,'2020-06-01 11:00:00'),
:-] (102,'sku_004',2500.00,'2020-06-01 12:00:00'),
:-] (102,'sku_002',2000.00,'2020-06-01 13:00:00'),
:-] (102,'sku_002',12000.00,'2020-06-01 13:00:00'),
:-] (102,'sku_002',600.00,'2020-06-02 12:00:00');
INSERT INTO t_order_mt FORMAT Values
Query id: 6c133036-8444-45c4-a1a8-e05e3b1c3492
Ok.
6 rows in set. Elapsed: 0.003 sec.
scentos :) select * from t_order_mt;
SELECT *
FROM t_order_mt
Query id: 01abdb15-1f4a-48a0-abf2-d36463e7a43f
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
12 rows in set. Elapsed: 0.003 sec.
optimize后,再次查询:
scentos :) optimize table t_order_mt final;
OPTIMIZE TABLE t_order_mt FINAL
Query id: 00061d16-5830-4762-a2ed-c43def2b8fca
Ok.
0 rows in set. Elapsed: 0.003 sec.
scentos :) select * from t_order_mt;
SELECT *
FROM t_order_mt
Query id: 598a25c3-4c98-459d-94ec-c270de6a25f2
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_002 │ 2000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_002 │ 12000 │ 2020-06-01 13:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
12 rows in set. Elapsed: 0.003 sec.
primary key主键
ClickHouse中的主键只提供了数据的一级索引,而非一级约束,因此可以存在主键相同的数据。
主键的设定依据主要是查询语句的where条件,通过查询条件,合并树引擎对主键进行二分查找,定位到对应的索引粒度(index granularity)。避免了全表扫描。
索引粒度指的是稀疏索引中两个相邻索引的的数据间隔,合并树中默认值为8192,如果某列存在大量重复值,导致一个分区几万行才有一个不同的数据时,我们可以将这个值调大,但官方不建议修改。
稀疏索引示例图如下所示:
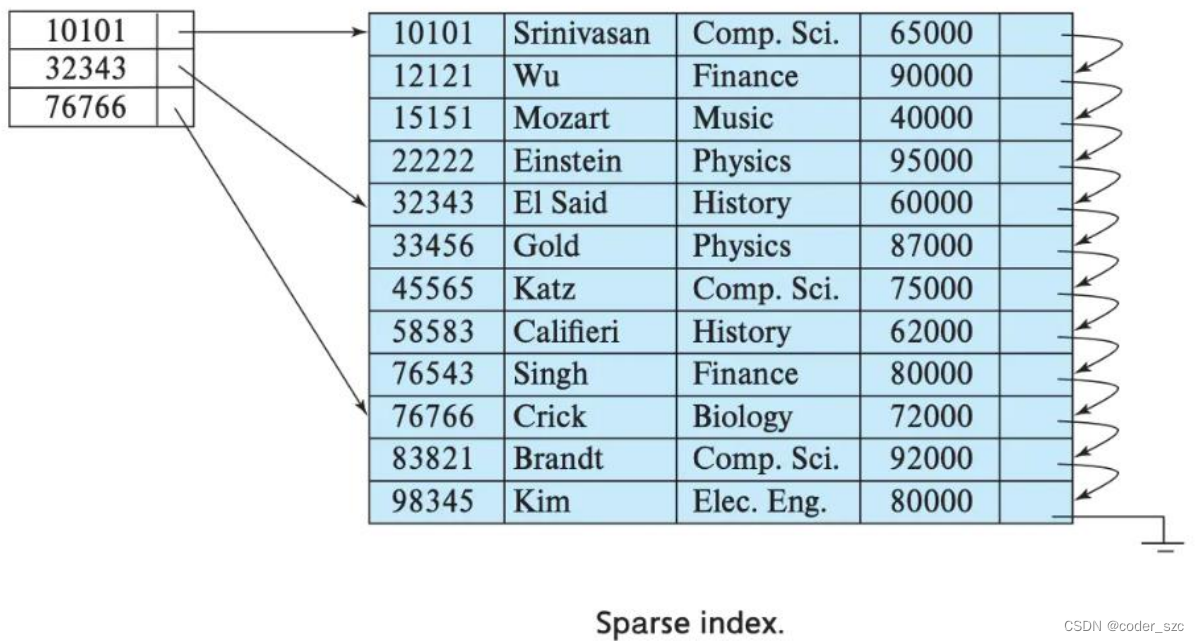
可以看到,稀疏索引的好处是通过很少的索引定位更多的数据,但每次定位只能定位到索引粒度的第一行,然后再进行进一步地扫描。
二级索引
二级索引再ClickHouse 20.1.2.4之前是实验性的,需要手动开启,在这个版本之后,默认开启,开启方式为:
set allow_experimental_data_skipping_indices=1;
20.1.2.4之后的版本中,allow_experimental_data_skipping_indices参数已经被删除
我们首先创建测试表:
create table t_order_mt2(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime,
INDEX a total_amount TYPE minmax GRANULARITY 5
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
其中INDEX a total_amount TYPE minmax GRANULARITY 5表示为列total_amount建立二级索引(一级索引为主键),类型为minmax(存储该列的最值),该索引对于对应的一级索引粒度为5。然后插入一些测试数据:
insert into t_order_mt2 values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
此时一级索引有两个:101,102;101只有一个二级索引1000,102中有600和12000两个二级索引,在CenOS7中进行测试:查询>900的数据:
[szc@scentos ~]$ clickhouse-client --send_logs_level=trace <<< 'select
> * from t_order_mt2 where total_amount > toDecimal32(900., 2)';
[scentos] 2021.12.10 19:10:59.278281 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Debug> executeQuery: (from [::1]:42466) select * from t_order_mt2 where total_amount > toDecimal32(900., 2)
[scentos] 2021.12.10 19:10:59.279046 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "total_amount > toDecimal32(900., 2)" moved to PREWHERE
[scentos] 2021.12.10 19:10:59.279487 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Trace> ContextAccess (default): Access granted: SELECT(id, sku_id, total_amount, create_time) ON default.t_order_mt2
[scentos] 2021.12.10 19:10:59.279665 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Trace> InterpreterSelectQuery: FetchColumns -> Complete
[scentos] 2021.12.10 19:10:59.280011 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Debug> default.t_order_mt2 (f8300897-4912-4035-b830-08974912f035) (SelectExecutor): Key condition: unknown
[scentos] 2021.12.10 19:10:59.280247 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Debug> default.t_order_mt2 (f8300897-4912-4035-b830-08974912f035) (SelectExecutor): MinMax index condition: unknown
[scentos] 2021.12.10 19:10:59.281230 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Debug> default.t_order_mt2 (f8300897-4912-4035-b830-08974912f035) (SelectExecutor): Index `a` has dropped 1/2 granules.
[scentos] 2021.12.10 19:10:59.281341 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Debug> default.t_order_mt2 (f8300897-4912-4035-b830-08974912f035) (SelectExecutor): Selected 2/2 parts by partition key, 1 parts by primary key, 2/2 marks by primary key, 1 marks to read from 1 ranges
[scentos] 2021.12.10 19:10:59.281658 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Debug> MergeTreeInOrderSelectProcessor: Reading 1 ranges in order from part 20200601_1_1_0, approx. 5 rows starting from 0
[scentos] 2021.12.10 19:10:59.283240 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Information> executeQuery: Read 5 rows, 160.00 B in 0.004803457 sec., 1040 rows/sec., 32.53 KiB/sec.
[scentos] 2021.12.10 19:10:59.283297 [ 55472 ] {ebdb07d8-b6cf-4bf1-8568-a5b80cbeaac2} <Debug> MemoryTracker: Peak memory usage (for query): 0.00 B.
101 sku_001 1000 2020-06-01 12:00:00
102 sku_002 2000 2020-06-01 11:00:00
102 sku_002 2000 2020-06-01 13:00:00
102 sku_002 12000 2020-06-01 13:00:00
102 sku_004 2500 2020-06-01 12:00:00
因为101只有一个二级索引,所以可以通过这一个二级索引决定读取还是排除101一级索引的数据,因此二级索引a会跳过101该一级索引;对于102,因为900在其二级索引[600, 12000]中,从而不能跳过102一级索引,得逐条读取比较,故此,二级索引a跳过了一个“索引粒度”:
Index `a` has dropped 1/2 granules.
查询<200的数据:
[szc@scentos ~]$ clickhouse-client --send_logs_level=trace <<< 'select
* from t_order_mt2 where total_amount < toDecimal32(200., 2)';
[scentos] 2021.12.10 19:22:19.517281 [ 55472 ] {e9ede560-a577-49ba-875d-596e9799ecbe} <Debug> executeQuery: (from [::1]:42610) select * from t_order_mt2 where total_amount < toDecimal32(200., 2)
[scentos] 2021.12.10 19:22:19.517679 [ 55472 ] {e9ede560-a577-49ba-875d-596e9799ecbe} <Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "total_amount < toDecimal32(200., 2)" moved to PREWHERE
[scentos] 2021.12.10 19:22:19.517893 [ 55472 ] {e9ede560-a577-49ba-875d-596e9799ecbe} <Trace> ContextAccess (default): Access granted: SELECT(id, sku_id, total_amount, create_time) ON default.t_order_mt2
[scentos] 2021.12.10 19:22:19.518014 [ 55472 ] {e9ede560-a577-49ba-875d-596e9799ecbe} <Trace> InterpreterSelectQuery: FetchColumns -> Complete
[scentos] 2021.12.10 19:22:19.518156 [ 55472 ] {e9ede560-a577-49ba-875d-596e9799ecbe} <Debug> default.t_order_mt2 (f8300897-4912-4035-b830-08974912f035) (SelectExecutor): Key condition: unknown
[scentos] 2021.12.10 19:22:19.518262 [ 55472 ] {e9ede560-a577-49ba-875d-596e9799ecbe} <Debug> default.t_order_mt2 (f8300897-4912-4035-b830-08974912f035) (SelectExecutor): MinMax index condition: unknown
[scentos] 2021.12.10 19:22:19.518588 [ 55472 ] {e9ede560-a577-49ba-875d-596e9799ecbe} <Debug> default.t_order_mt2 (f8300897-4912-4035-b830-08974912f035) (SelectExecutor): Index `a` has dropped 2/2 granules.
[scentos] 2021.12.10 19:22:19.518614 [ 55472 ] {e9ede560-a577-49ba-875d-596e9799ecbe} <Debug> default.t_order_mt2 (f8300897-4912-4035-b830-08974912f035) (SelectExecutor): Selected 2/2 parts by partition key, 0 parts by primary key, 2/2 marks by primary key, 0 marks to read from 0 ranges
[scentos] 2021.12.10 19:22:19.519013 [ 55472 ] {e9ede560-a577-49ba-875d-596e9799ecbe} <Debug> MemoryTracker: Peak memory usage (for query): 0.00 B.
[szc@scentos ~]$
类似方才的分析,101和102都被二级索引a跳过:
Index `a` has dropped 2/2 granules.
数据存活时间TTL
列存活时间
创建测试表:
create table t_order_mt3(
id UInt32,
sku_id String,
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
其中total_amount Decimal(16,2) TTL create_time+interval 10 SECOND指定该(total_amount)列存活时间为10s,即当前时间>某一行数据的create_time列+10s时,该行该列(total_amount)字段清零。
我们先插入数据
scentos :) insert into t_order_mt3 values
(106,'sku_001',1000.00,'2021-12-10 20:14:50'),
(107,'sku_002',2000.00,'2021-12-10 22:14:20'),
(110,'sku_003',600.00,'2021-12-10 12:00:00');
INSERT INTO t_order_mt3 FORMAT Values
Query id: 95e3afc8-322c-4c51-a65b-a1713dc77a34
Ok.
3 rows in set. Elapsed: 0.003 sec.
scentos :) select * from t_order_mt3;
SELECT *
FROM t_order_mt3
Query id: ff04f192-809d-4203-9e7d-e5445e7dcdc1
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 106 │ sku_001 │ 1000 │ 2021-12-10 20:14:50 │
│ 107 │ sku_002 │ 2000 │ 2021-12-10 22:14:20 │
│ 110 │ sku_003 │ 0 │ 2021-12-10 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
3 rows in set. Elapsed: 0.002 sec.
如果没有即时生效,需要对表进行手动合并:
scentos :) optimize table t_order_mt3 final;
OPTIMIZE TABLE t_order_mt3 FINAL
Query id: 661e3c01-0975-4f7e-9fee-c5b0be152511
Ok.
0 rows in set. Elapsed: 0.003 sec.
scentos :) select * from t_order_mt3;
SELECT *
FROM t_order_mt3
Query id: cfb71396-7731-4072-844c-38146804d853
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 106 │ sku_001 │ 0 │ 2021-12-10 20:14:50 │
│ 107 │ sku_002 │ 2000 │ 2021-12-10 22:14:20 │
│ 110 │ sku_003 │ 0 │ 2021-12-10 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
3 rows in set. Elapsed: 0.002 sec.
表级存活时间
表级存活时间是指,超过指定时间的数据行会丢失(而非清零),所涉及的字段必须是Date或Datetime类型,建议使用分区的日期字段。
比如下面是个例子:清除当前时间时间超过create_time字段10s的数据行:
scentos :) alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
ALTER TABLE t_order_mt3
MODIFY TTL create_time + toIntervalSecond(10)
Query id: bd8e52a1-070a-4b9a-819e-0755b1a2b85b
Ok.
0 rows in set. Elapsed: 0.040 sec.
scentos :) select * from t_order_mt3;
SELECT *
FROM t_order_mt3
Query id: 2fc4d900-1ef8-4360-94b4-f635d8b33563
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 107 │ sku_002 │ 2000 │ 2021-12-10 22:14:20 │
└─────┴─────────┴──────────────┴─────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
可以用的时间周期有:SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER、YEAR,顾名思义,分别表示秒、分、时、天、周、月、三个月、年。
ReplacingMergeTree
ReplacingMergeTree是带有去重功能的合并树,在合并的时候根据主键进行数据去重。如果表进行了分区,那么去重只会在分区内均行,而不能在跨分区进行。
示例如下,首先创建一张表,用去重合并树作为表引擎:
create table t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
engine =ReplacingMergeTree(create_time)中传入的参数为去重字段,只保留各分区内该字段值最大的数据,如果不填,默认保留各分区最新的数据。
然后插入数据:
insert into t_order_rmt values
(101,'sku_001',1000.00,'2021-12-10 20:37:00') ,
(102,'sku_002',2000.00,'2021-12-10 20:35:00'),
(102,'sku_004',2500.00,'2021-12-10 20:35:00'),
(102,'sku_002',2000.00,'2020-12-10 20:36:00'),
(102,'sku_002',12000.00,'2021-12-10 20:33:00'),
(102,'sku_002',600.00,'2021-12-10 20:36:00');
并进行查询:
scentos :) select * from t_order_rmt;
SELECT *
FROM t_order_rmt
Query id: 050d0f4d-2eda-4e70-82b7-87f845701095
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2021-12-10 20:37:00 │
│ 102 │ sku_002 │ 600 │ 2021-12-10 20:36:00 │
│ 102 │ sku_004 │ 2500 │ 2021-12-10 20:35:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 2000 │ 2020-12-10 20:36:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
4 rows in set. Elapsed: 0.024 sec.
再插入数据,把(102,'sku_002',600.00,'2021-12-10 20:36:00')中的600改为1600,立刻查询:
scentos :) insert into t_order_rmt values
(101,'sku_001',1000.00,'2021-12-10 20:37:00') ,
(102,'sku_002',2000.00,'2021-12-10 20:35:00'),
(102,'sku_004',2500.00,'2021-12-10 20:35:00'),
(102,'sku_002',2000.00,'2020-12-10 20:36:00'),
(102,'sku_002',12000.00,'2021-12-10 20:33:00'),
(102,'sku_002',1600.00,'2021-12-10 20:36:00');
INSERT INTO t_order_rmt FORMAT Values
Query id: b5508d64-9feb-4d01-9264-db69e0e8ceb1
Ok.
6 rows in set. Elapsed: 0.003 sec.
scentos :) select * from t_order_rmt;
SELECT *
FROM t_order_rmt
Query id: 946d4461-c00a-4aef-bddc-09e7aca31be9
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2021-12-10 20:37:00 │
│ 102 │ sku_002 │ 1600 │ 2021-12-10 20:36:00 │
│ 102 │ sku_004 │ 2500 │ 2021-12-10 20:35:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 2000 │ 2020-12-10 20:36:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2021-12-10 20:37:00 │
│ 102 │ sku_002 │ 600 │ 2021-12-10 20:36:00 │
│ 102 │ sku_004 │ 2500 │ 2021-12-10 20:35:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 2000 │ 2020-12-10 20:36:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
8 rows in set. Elapsed: 0.003 sec.
发现新数据没有被去重,我们手动合并后,再查询,可见数据回到了四行:
scentos :) optimize table t_order_rmt final;
OPTIMIZE TABLE t_order_rmt FINAL
Query id: 4ae5add5-c25a-4834-acd9-99d6ae9c64c5
Ok.
0 rows in set. Elapsed: 0.003 sec.
scentos :) select * from t_order_rmt;
SELECT *
FROM t_order_rmt
Query id: 6aeded9c-9cdb-4aea-8fbd-66e16adb79d5
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 2000 │ 2020-12-10 20:36:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2021-12-10 20:37:00 │
│ 102 │ sku_002 │ 1600 │ 2021-12-10 20:36:00 │
│ 102 │ sku_004 │ 2500 │ 2021-12-10 20:35:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
4 rows in set. Elapsed: 0.003 sec.
scentos :)
可以得到以下结论:
- 去重合并树使用的是
order by字段作为唯一主键; - 去重不能跨分区;
- 只有同一批插入数据或合并表时才会去重;
- 去重时,保留去重字段值最大的数据;如果去重字段值相同,保留最新插入的数据。
SummingMergeTree
如果只关心数据的汇总聚合,我们可以使用汇总合并树SummingMergeTree,该引擎提供了预聚合的功能,以节省存储空间和查询性能的开销。
示例如下,先创建一张表,使用汇总合并树引擎:
create table t_order_smt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =SummingMergeTree(total_amount)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id );
然后插入数据:
insert into t_order_smt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');
进行查询:
scentos :) select * from t_order_smt;
SELECT *
FROM t_order_smt
Query id: 3fbe051f-e47e-4693-b2cc-fa395547e059
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 16000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
4 rows in set. Elapsed: 0.002 sec.
scentos :)
先按时间将数据分为6月2号和6月1号两个区,然后对每个分区内order by字段相同的数据的total_amount值进行合并累加。
我们再做一次数据插入和查询,将(102,'sku_002',12000.00,'2020-06-01 13:00:00')中的13:00:00改为23:00:00:
scentos :) insert into t_order_smt values
:-] (101,'sku_001',1000.00,'2020-06-01 12:00:00'),
:-] (102,'sku_002',2000.00,'2020-06-01 11:00:00'),
:-] (102,'sku_004',2500.00,'2020-06-01 12:00:00'),
:-] (102,'sku_002',2000.00,'2020-06-01 13:00:00'),
:-] (102,'sku_002',12000.00,'2020-06-01 23:00:00'),
:-] (102,'sku_002',600.00,'2020-06-02 12:00:00');
INSERT INTO t_order_smt FORMAT Values
Query id: a6a291e0-a44f-41ba-973b-5ab470878d1a
Ok.
6 rows in set. Elapsed: 0.003 sec.
scentos :) select * from t_order_smt;
SELECT *
FROM t_order_smt
Query id: 5c1d2e64-6b51-4190-b467-130ccb441034
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 600 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 16000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 1000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 16000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_004 │ 2500 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
8 rows in set. Elapsed: 0.004 sec.
可见新插入的数据没有被聚合,且(102,'sku_002',12000.00',...)只保留了插入时间最早的一条
102 │ sku_002 │ 16000 │ 2020-06-01 11:00:00
然后我们手动合并一下:
scentos :) optimize table t_order_smt final;
OPTIMIZE TABLE t_order_smt FINAL
Query id: 1ab134b2-a680-4005-a36f-724e4be5222a
Ok.
0 rows in set. Elapsed: 0.003 sec.
scentos :) select * from t_order_smt;
SELECT *
FROM t_order_smt
Query id: 4ba33366-5d47-4e82-9b1a-299567068182
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 102 │ sku_002 │ 1200 │ 2020-06-02 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
┌──id─┬─sku_id──┬─total_amount─┬─────────create_time─┐
│ 101 │ sku_001 │ 2000 │ 2020-06-01 12:00:00 │
│ 102 │ sku_002 │ 32000 │ 2020-06-01 11:00:00 │
│ 102 │ sku_004 │ 5000 │ 2020-06-01 12:00:00 │
└─────┴─────────┴──────────────┴─────────────────────┘
4 rows in set. Elapsed: 0.020 sec.
因此,我们可以得到以下结论:
- 汇总合并树需要指定某一列为合并列,可以是多列,但必须是数字列,默认以所有的非
order by的数字列进行合并; - 非合并列按插入顺序保留最早的数据;
- 聚合不会跨分区;
- 只有同一批次插入的数据或手动合并后,才会进行聚合。
相比聚合函数sum,汇总合并树的效率更高。














 5134
5134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









