









Hadoop生态圈是大数据行业内比较常用的离线数据处理技术,而Hadoop的安装模式又分三种、分别是单机模式、伪分布式和集群模式。伪分布式主要是用于开发人员测试,集群模式才是生产环境上配置的。那么、今天就说一下Hadoop的伪分布式安装搭建。
1、环境准备:
- 虚拟机系统:Centos-7
- JDK:JDK1.8.0_171。
- 关闭防火墙、配置好机器静态IP。
2、下载:
http://hadoop.apache.org/官网进行下载安装包、自行选择版本下载。但是、大家最好还是下载跟我同一个版本的安装包,这样配置的时候才不会出很多问题。因为不同版本的安装包,Apache可能会修改了某些参数,导致就算你的配置跟我的配置一样,但是还是不能启用。话不多说,这里我选择了hadoop-2.7.1版本下载。
3、安装配置:
- 配置主机名:执行以下命令进行打开虚拟机主机名配置文件,进行相应的修改。将文件中原有的主机名删除,添加你自己的主机名。保存并退出。随后重启虚拟机。
vi /etc/hostname
-
配置hosts文件:执行以下命令进行打开hosts配置文件,进行修改。在文件最后增加机器的IP地址和刚才配好的主机名。保存并退出。
vi /etc/hosts
-
生成SSH密钥:执行以下命令,然后一直回车。来生成SSH密钥。生成的密钥文件会存放在/root/.ssh/目录下。前提是你用的root帐号登录并且生成的ssh密钥。
ssh-keygen
-
配置机器免密登录:执行以下命令、将刚才生成好的SSH密钥发送指定的机器上,来实现机器免密登录。
ssh-copy-id root@CSDN01
-
上传和解压下载好的Hadoop安装包:使用ftp工具将Hadoop安装包上传到/usr/local/目录下、然后使用以下命令解压安装包。
tar -zxvf hadoop-2.7.1_64bit.tar.gz

-
配置hadoop-env.sh文件:这个文件里写的是hadoop的环境变量,主要修改hadoop的JAVA_HOME和HADOOP_CONF_DIR 路径。使用以下命令打开文件进行修改。修改完成后保存退出。
cd hadoop-2.7.1/etc/hadoop/ vi hadoop-env.sh
-
修改core-site.xml文件:使用vi core-site.xml打开文件,增加以下配置参数。
<configuration> <!--用来指定 hdfs 的老大,namenode 的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://CSDN01:9000</value> </property> <!--用来指定 hadoop 运行时产生临时文件的存放目录,如果不配置默认使用/tmp目录存在安全隐患 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-2.7.1/tmp</value> </property> </configuration>
-
修改hdfs-site.xml:使用vi hdfs-site.xml打开文件,增加以下配置参数。
<configuration> <!--指定 hdfs 保存数据副本的数量,包括自己,默认值是 3--> <!--如果是伪分布模式,此值是 1--> <property> <name>dfs.replication</name> <value>1</value> </property> <!--设置 hdfs 的操作权限,false 表示任何用户都可以在 hdfs 上操作文件--> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
-
修改 mapred-site.xml:这个文件初始时是没有的,有的是模板文件,mapred-site.xml.template
所以需要拷贝一份,并重命名为 mapred-site.xml 。执行以下命令进行复制。cp mapred-site.xml.template mapred-site.xml 复制完成后、使用vi mapred-site.xml打开文件,增加以下配置参数。
复制完成后、使用vi mapred-site.xml打开文件,增加以下配置参数。<configuration> <property> <!--指定 mapreduce 运行在 yarn 上--> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
-
修改 yarn-site.xml:使用vi yarn-site.xml打开文件,增加以下配置参数。
<configuration> <!-- Site specific YARN configuration properties --> <property> <!--指定 yarn 的老大 resoucemanager 的地址--> <name>yarn.resourcemanager.hostname</name> <value>CSDN01</value> </property> <property> <!--NodeManager 获取数据的方式--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
-
配置 slaves 文件:使用vi slaves打开文件,增加以下配置参数。
CSDN01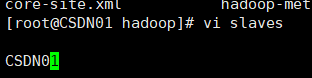
-
配置Hadoop的环境变量:使用vi /etc/profile打开文件,增加以下配置参数。保存退出后,使用source /etc/profile命令来使配置立即生效。
#配置hadoop的环境变量 export HADOOP_HOME=/usr/local/hadoop-2.7.1 export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin

-
格式化namenode:使用以下命令进行格式化hadoop的namenode。出现successfully代表成功。
hadoop namenode -format
-
启动hadoop:使用start-all.sh命令启动hadoop。启动完成后,通过jps命令查看进程节点。如果出现以下六个说明成功启动。

- 通过浏览器查看和管理hadoop: http://ip:50070来进行查看hadoop。

到此、Centos7下的Hadoop伪分布式安装搭建就成功完成了。















 3284
3284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









