







一、synchronized
相信对于 java 开发这个关键字并不陌生,它主要是用来进行线程间通信和保证共享数据的一致性,但是在刚入行的时候听老前辈说过尽量少使用 synchronized 这个关键字,多使用 juc 包下的 Lock 来替代它,因为使用 synchronized 的成本很高,可能在当时他说的是对的,但是在现在看来这句话不一定是对的,为什么这么说呢,请看下面的例子(使用 jdk 版本:1.8.0_231)
public class SyncBeforeJdk16Test {
@Test
public void syncTest(){
Object lock = new Object();
Lock jucLock = new ReentrantLock();
//---------------------- before -------------------------------
for (int i = 0; i < 2; i++) {
new Thread(()->{
synchronized (lock){
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
//---------------------- end -------------------------------
long start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
synchronized (lock){
i ++;
}
}
System.out.println("sync time used " + (System.currentTimeMillis() - start));
long jucStart = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
jucLock.lock();
i ++;
jucLock.unlock();
}
System.out.println("juc time used " + (System.currentTimeMillis() - jucStart));
}
}代码应该不难看懂,就是执行了 1E 次的 i++ 操作,只不过中间一个通过 synchronized 加锁执行一个通过 Lock 加锁执行,start 到 end 间的代码好像跟下面代码的执行半毛钱关系没有,至于为什么要这么写我待会跟你解释
执行结果如下:
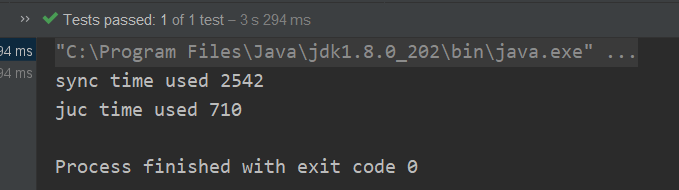
这么看来老前辈好像没有骗我,使用 juc 下的 Lock 确实比 synchronized 关键字快得多,那么为什么说现在看来不一定是对的呢,现在把 start 跟 before 中间的代码注掉看一下执行效果

你会发现使用 synchronized 关键字执行时间少了一半多
那么在执行的 vm 参数中加上这个 -XX:BiasedLockingStartupDelay=0 再试下呢(参数前面有横杠不要省略)

令人吃惊的事情出现了,synchronized 执行时间比 juc 快了 7 倍!这为什么跟老前辈说的不一样了呢?还有 start 跟 before 中间的代码作用是什么?vm 参数的作用又是什么?下面就开始介绍 jdk 1.6 之后对 synchronized 关键字究竟做了哪些优化
二、jdk 1.6 对 synchronized 的优化
1、对象头
说到 jdk1.6 对 synchronized 关键字的优化,就不得不提一下对象头是什么,下面来看一下 jdk 官方对于对象头的解释https://wiki.openjdk.java.net/display/HotSpot/Synchronization#Synchronization-Agesen99
In the Java HotSpot™ VM, every object is preceded by a class pointer and a header word.
The header word, which stores the identity hash code as well as age and marking bits for generational garbage collection, is also used to implement a thin lock scheme
Synchronization affects multiple parts of the JVM: The structure of the object header is defined in the classes oopDesc and markOopDesc大概意思是说对象头包含了一个 class 的指针 (klass) 和 header word (oop),header word (oop) 就是一种用来保存 hash code,分代年龄,gc标记,也会被用来实现轻量锁(这里提到的轻量锁并不代表下文中提到的轻量级锁,在此的意思是与调用操作系统函数消耗资源相对较多的锁的一种对照)对象头的数据结构被定义在 oopDesc markOppDesc 中
openjdk 中关于对象头的定义在代码注释中如下:http://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/6f33e450999c/src/share/vm/oops/markOop.hpp
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)其实大概可以看出普通对象的对象头包含什么信息,共分为两部分,32位跟64位的,下面拿64位举例(之后下文中提到的对象头默认都为64位)
64位的操作系统:25 bit 未使用,31 bit 存储 hash code,4 bit 存储分代年龄信息,1 bit biased lock 存储是否为偏向锁的标志位,2 bit 锁的标志/gc标记位
以上信息可以在代码注释中找到,这里就不粘了
下面来打印一下对象头中的信息来实际感受一下,首先要引入一个 jol 包,这个包是 openjdk 提供的,可以获取对象头信息
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>public class ObjectHeader {
@Test
public void test(){
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());
}
}上面代码执行结果如下

从上面可以了解到对象头中的信息 0-12 byte 表示对象头信息,另外 4 byte 代表对齐填充,因为 hotspot 规定对象大小必须为 8 byte 的倍数,所以需要最后 4byte 进行补齐
从上面理论知识中你了解到 oop 大小为 8byte,但是你可能听到 kclass 大小也为 8byte,但是实验中显示只有 4byte,这是因为默认开启了指针压缩(Compressed oops https://wiki.openjdk.java.net/display/HotSpot/CompressedOops),如果在 vm 参数中加上 -XX:-UseCompressedOops 就可以关闭指针压缩,下面看一下启用这个参数之后的效果

2、对象头中的 hash code
可能你已经发现了,上文中提到前 64 bit 中有 31 bit 表示 hash code,但是打印出来的效果不是 1 就是 0,难道 hash code 真的是这样吗,下面调用下 hashCode 方法来看一下
public class ObjectHeader {
@Test
public void test(){
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
//这个方法会从首个不为 0 的位置开始打印, 所以打印结果不是 32 bit
System.out.println(Integer.toBinaryString(o.hashCode()));
}
}执行结果如下:

你可能会有疑问,这明显不是理论知识中提到的 hash code。我猜想你产生疑惑的原因是 hash code 是对象创建出来就产生的,并不是调用 hashCode 方法后才生成的,然而现实却是 hashCode 确实是调用 hashCode 方法之后才生成的,之后来验证下结果,其实就是在调用 hashCode 方法之后再打印下对象头信息,结果如下

其实已经可以看出来跟之前不一样了,但是如果仔细对照上面理论知识中提到的对象布局信息的话发现是对不上的,为了方便阅读,我把上面理论知识提到的结构信息粘过来
64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)调用完 hashCode 方法后字节码变动的是 2 byte - 5byte,但是结构信息提到 hashCode 是 4 byte - 8byte 间,而却如果仔细对的话发现他们并不是一致的,这就涉及到操作系统的大小端(Big-endian/Little-endian)的概念,由于使用的是 cpu 是 x64,所以为小端结构,因此需要将打印出来的前 8byte 二进制字符序列倒过来看,为了方便观察,直接将 hash code 打印结果转换成 16 进制进行对照
101000100001100100111010010010 ===> 0x28864e92OFFSET SIZE VALUE
1 2 10010010(0x92)
2 3 01001110(0x4e)
3 4 10000110(0x86)
4 5 00101000(0x28)
hash code 0x28864e92通过对照发现与上面 hash code 一致
3、偏向锁、轻量级锁和重量级锁
其实你之前大概应该从很多地方了解到过 jdk 1.6 中对 synchronized 优化引入了偏向锁,轻量级锁,重量级锁,那么这写优化是什么,能不能感知的到呢,其实你已经看到他们的效果了,就是在文章开头我给出的三个 1E 次 i ++ 的例子,他们对应的分别是重量级锁,轻量级锁,偏向锁。如果之前提到的内容都没问题的话,相信下面应该理解起来非常轻松,当然本篇文章主要介绍的是偏向锁,但是对于其他的锁也会提及。
1、偏向锁(Biased Lock)
首先来了解下什么是偏向锁,偏向锁就是在每次进行加锁的时候保留当线程的 thread id(操作系统中的线程 id 并非 java 中的线程 id),每次获取锁的时候进行比较,如果一致则获取锁,如果不一致则走锁撤销的逻辑把当前锁更新成无锁状态,并膨胀为轻量级锁(Lightweight Lock)。其实轻量级锁最显著的特性就是不调用操作系统函数 pthread_mutex_lock
下面来看一下轻量级锁的头信息,需要在启动的时候加上这个参数 -XX:BiasedLockingStartupDelay=0 ,由于偏向锁是有延迟的,并不是说 jvm 启动成功之后创建的一定就是可偏向状态的对象,这样设计其实也有有道理,因为 jvm 启动的时候内部使用了很多的同步代码,比如说类加载器中的 loadClass 方法 java.lang.ClassLoader#loadClass(java.lang.String, boolean),如果说无延迟启动的话其实大部分情况下是有冲突的,也就是说达不到偏向锁的优化效果,反而加载过程中每一次不同线程调用或者多线程冲突的情况下都需要进行锁撤销反而增加了开销。
public class LightweightLockTest {
@Test
public void test(){
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
synchronized (o){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}

可以与上面不开启偏向锁无所状态下的对象头进行对比,着重看偏移量为 0 - 1 的 value 值。对比之后可以发现无锁状态下它们的区别只是在倒数第3个 bit 位上,结合之前的结构信息图可以发现倒数第三个 bit 位上是用来区分是否是偏向锁标志位的,1 代表可偏向状态,0 代表不可偏向状态。
再看下加锁之后,偏移量 2 - 5 的 value 发生了变化,与结构信息图中相符,结构信息图中 1 - 54 bit 是作为线程 id 存储的空间,55 - 56 的 bit 值与偏向锁的重偏向有关,之后会提到。
出了同步代码块之后通过打印头信息发现与加锁时的头信息一致。
2、偏向锁中的限制
此时我们大概了解了偏向锁的整个结构,总结一下,偏向锁默认有延迟会延后开启,01 状态代表无锁,对象头中偏移量 0 - 1 中倒数第三个 bit 位代表可偏向状态,如果曾经偏向过某个线程,那么 0 - 54 bit 则表示偏向的线程 id。可能此时你会有疑问,如果我调用了 hashCode 方法再进行加锁会怎样呢,因为存储 hashCode 与 线程 id 有冲突,对象头只能保存一个,请看以下代码
public class InflateByHashCodeTest {
@Test
public void test(){
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
o.hashCode();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
synchronized (o){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
}执行结果如下

执行 hashCode 后发现对象头中可偏向状态标志位变成了 0,也就是变成了不可偏向的无锁状态,之后头对象中保存了 hash 值,再次加锁的时候发现所标志位变成了 00(轻量级锁),也就是说可偏向状态是不可撤销的,一旦成了不可偏向就无法撤销,在此能得出结论,当可偏向对象调用 hashCode 方法的时候无法用到偏向锁。
在这里给你留一个问题,如果在加锁过程中调用 hashCode 方法 jvm 会怎么处理对象头呢?
3、偏向锁的重偏向
下面我们聊聊偏向锁的重偏向,先解释下什么叫重偏向,当两个线程交替执行的时候,获取锁时只需要将头像头中的线程 id 通过替换成当前获取锁的线程 id 而不需要进行锁的升级即可完成加锁。看完前面的例子你或许会有疑问,前面两个线程交替执行之后进行了锁的膨胀,并没有进行重偏向。这需要引出 epoch 与两个 vm 参数 -XX:BiasedLockingBulkRebiasThreshold 和 -XX:BiasedLockingBulkRevokeThreshold
epoch:是否进行重偏向的标志位
-XX:BiasedLockingBulkRebiasThreshold:重偏向的阈值默认为 20,当锁没有冲突,相同 class 不同实例膨胀个数达到当前值则试图进行重偏向
-XX:BiasedLockingBulkRevokeThreshold:重偏向撤销的阈值默认为 40,相同 class 不同实例当重偏向之后发生锁冲突实例膨胀后个数达到当前值则不再进行重偏向
但是需要注意的是这两个 vm 参数不能调小,如果调小的话不会生效
public class EpochTest {
@Test
public void test(){
ArrayList<Object> objects = Lists.newArrayList();
Thread t = new Thread(()->{
for (int i = 0; i < 61; i++) {
Object o = new Object();
objects.add(o);
synchronized (o){
if(i == 0){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
}
});
t.start();
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("------------------------------第一组对照----------------------------");
//对照
Object o = new Object();
for (int i = 0; i < 61; i++) {
if( i == 0){
synchronized (o){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
synchronized (objects.get(i)){
if(i == 60){
System.out.println(ClassLayout.parseInstance(objects.get(i)).toPrintable());
}
}
}
System.out.println("------------------------------第二组对照----------------------------");
Thread thread = new Thread(()->{
//对照
Object o2 = new Object();
for (int i = 0; i < 61; i++) {
if( i == 0){
synchronized (o2){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
synchronized (objects.get(i)){
if(i == 60){
System.out.println(ClassLayout.parseInstance(objects.get(i)).toPrintable());
}
}
}
});
thread.start();
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}这里代码有点多,我最后再来解释下,List 中放 61 个对象,开启一个线程每个对象调用一次 synchronized 同步块,之后等待执行完毕后调用主线程对每个对象再次调用 synchronized 同步块,在这里会新创建一个对象进行对照,等待主线程执行完毕后,在开启第三个线程执行如上操作,下面我们来看下执行结果

这组对照可以发现线程 id 发生了改变,但是并没有出现锁的膨胀。

这组对照可以看出锁偏向时确实 epoch 发生了改变

这组对照可以看出撤销达到阈值发生了锁的膨胀。
4、重量级锁
重量级锁其实很好体现,代码如下
public class HeavyweightLockTest {
@Test
public void test(){
Object lock = new Object();
for (int i = 0; i < 2; i++) {
new Thread(()->{
synchronized (lock){
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
System.out.println(ClassLayout.parseInstance(lock).toPrintable());
}
}执行结果如下

锁表志位 10 即为重量级锁
三、锁的膨胀过程
这里不展开讲了,附上 openjdk 官方的一张图 :https://wiki.openjdk.java.net/display/HotSpot/Synchronization















 5397
5397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









