







前引
终于终于把Lab1给过掉了 哎呀 不容易 没过掉Lab1的几天中 我试了大概如下的数据结构 vector<char> deque<char> unordered_map<int,string> unordered_set<string> + priority_queue<int> 无一不以失败告终
到最后功夫还是不负有心人 终于实现了出来
写完这个Lab的博客 我就去吃午饭^^ 内容很多 少说闲话了 那大家往下面看吧
Lab1 Stitching Substrings Into a Byte Stream
获取实验文档+调试方法介绍
老样子啊 下面为了方便大家 于是给了Lab的文档链接的
CS144实验文档获取链接
CS144 Lab Assignments
下载这个即可
以后每篇博客里面都贴一下调试方法的链接吧 哈哈 还是挺有用的
Stanford University CS144 调试方法
1、Collaboration Policy(协作原则)
下面是原文 但是就不说了 意思就是 可以freely ask questions but not to post any source code 禁止贴源码
但其实我这样写Lab 其实还是违反了规定的 但是呢 我还是希望i hope it can give u some ideas but please not to copy my code :( it was not my intention
这部分就先写到这里
2、Overview(总览)
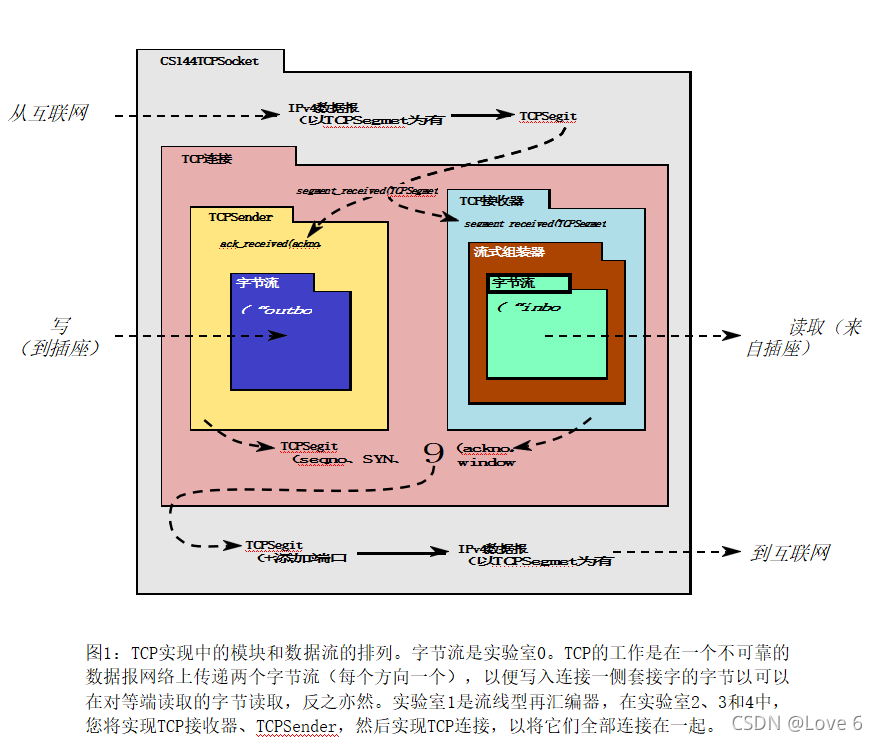
我们实验Lab0 Lab1 Lab2 Lab3 Lab4最终要达成的目的 就是手撕一个TCP 只不过是以模块化的形式一点点实现 所以更要求我们的代码需要严谨+严谨 我在之前的Lab0中 原来写错过代码 但是因为测试用例不多 还是过了 到后面因为Lab0错了 所以导致我的Lab1也通不过 - -
下面是机翻的Lab1-Lab4的实现
1.在实验1中,您将实现一个流重新汇编器——一个模块,它将字节流的小部分(称为子字符串或片段)缝合成正确序列的连续字节流。
2.在实验2中,您将实现TCP中处理流入站的部分:TCPCrmitver。这包括考虑TCP如何表示每个字节在流中的位置——称为“序列号”。TCP接收器负责告诉发送者(a)它能够成功组装多少入站字节流(这称为“确认”)和(b)现在允许发送者再发送多少个字节(“流控制”)。
3.在实验3中,您将实现处理出站字节流的TCP部分:TCPSender。当发送方怀疑它传输的片段在途中丢失并且从未到达接收方时,应该如何反应?什么时候应该再试一次并重新传输丢失的段?
4.在实验室4中,您将结合以前到实验室的工作,创建一个工作的TCP实现:一个包含TCPSender和TCPCemitever的TCP连接。您将使用它来与世界各地的真实服务器对话。
下面是我们的实现总览图
3、Getting started(开始)
下面就正式开始实验啦 开始实验之前我们需要获取Lab1所需要的代码 老样子 我们进入sponge 然后输入命令``
我们的Lab1所需材料就成功获取啦 和Lab0一样如果 编写程序编写好了 进入build目录 输入make编译
我们需要编写的程序是在sponge/libsponge 一个是stream_reassembler.cc 还有stream_reassembler.hh

4、Putting substrings in sequence(按顺序放置子字符串)
这里我就不像Lab0那样 跟保姆一样 哈哈哈 一点点的展开讲了 愿意写这个Lab的hxd 相比都是有一定的自己处理文档和信息的能力的 这里我就讲一下注意事项 和 实现思路 还有 文档的一些细节处理 讲完之后我就把代码贴出来吧 如果有hxd实在不清楚怎么实现的可以看一下我的代码
下面放一下图 和函数注释的机翻
//构造一个`流汇编器`,将存储多达`容量`字节。
简化的重新汇编器(连续的size_t容量);
//接收一个子字符串,并将任何新的相邻字节写入流中,
//,同时保持在`容量`的内存范围内。将使用的字节
//当超过容量时,它会被悄悄丢弃。
//
//`数据`:子串
//`索引`表示`data`中第一个字节的索引(按顺序放置)
//`eof`:这个子字符串的最后一个字节将是整个流中的最后一个字节
voidpush_substring(连续字符串和数据,连续uint64_t索引,连续push_substring);
//访问重新组装的字节流(来自实验室0的代码)
ByteStream&stream_out();
//已存储但尚未重新组装的子字符串中的字节数
size_tunassembled_bytes()同意;
//内部状态是否为空(输出流除外)?
bool空()const;
1、实现前的建议
可能是这段时间没有休息好 也可能是没有规划好直接开干 对于CS144 这个Lab 下面的建议是我拿了无数的挥霍小时总结出来的
1、最重要的一点 在你打算思考之前 先仔细仔细再仔细的看一下 实验文档中 函数具体要做成的目的 这个Lab实现目的是什么 有哪些地方需要注意 输出的时候规则是什么 是否选择丢弃多余的 还是保留多余的字节 什么时候输入 输入的时候是否需要丢弃多余的字节 是否保留乱序字节这些
2、开始敲代码前 当你开始写第一行代码的时候 务必务必一定一定要 思考清楚全局怎么布局 用什么的数据结构去存储 对于一些细节的地方 可以先在草稿本上画一下 因为确实很多地方处理很细节 需要斟酌范围 或者思考怎么处理
3、敲代码每一行的时候 需要仔细仔细再仔细一点 没有想清楚之前就先别打代码 可以在草稿本上面先画 很多时候因为细节而过不了phase是很正常的
4、实在没有思路 先看一下别人的实现思路 别一行行的看 看个大概后自己实现 照抄的话 提升几乎为0 建议每一行代码都是自己去实现
5、还是在最后的时候说一句 注意实现的细节 第一点真的很重要 我就是因为不了解 实验的很多细节 导致出现了偏差 从而导致整个实现都出来偏差 而到最后从头来过了很多次 一定要先明白函数需要我们干什么 对于一些地方文档中会告诉我们应该怎么处理
好了 写了那么多 就是希望大家能少绕一些弯路
先明白 明确实验目的 函数实现细节 远比直接上手 省超级超级多的时间
2、Lab中的注意事项
这里我还是得好好交代一下 因为这里就关乎代码怎么去实现了
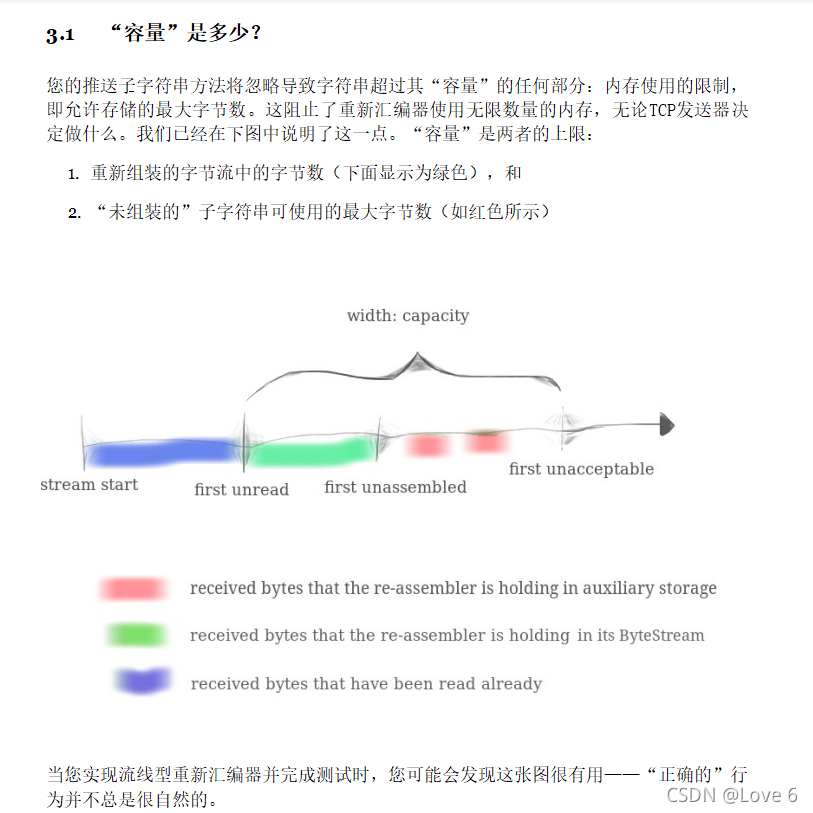
1、这里的容量和我们的第一个Lab的字节流处理的容量是单独分开的 各是各的 刚开始我看图没仔细看下面的英文 还以为capacity是一起的 - - 注意一下 这里是各管各的
2、输入的字符串 可以把其当作全是正确的子字符串 只不过可以是乱序的 我们要做的就是把乱序的字符串存储 并按照正确的顺序输出给字节流(Lab0所实现的)
3、输入进来的字符串如果不是按照顺序进来的画 是需要缓存下来的 缓存下来的字符串可能有完全一样的 有部分重叠 有完全不挨着的 我们需要自己去处理这些字符串 如果输入进来的字符串 我们在储存的时候发现多出来的字节 我们就需要丢弃
4、我们输出字符串到字节流的时机 即我们只要有按照顺序的字符串准备好了 我们就输出过去 但是如果字节流的接受空间已经满了 那我们就需要停止输入 暂时堵塞
5、我们默认开始序号为0 即如果刚开始我们向字节流输入的第一个字节 序号应该是0
3、代码实现思路
下面就要讲一下我的实现思路了 在这里必须要感谢一下下面链接的博主 我的思路启发是因为它的实现思路
真的还是很佩服他想到的这个思路 同样还是觉得需要不断地努力啊
我先说一下为什么deque vector实现并不好实现吧 首先就是我们用这个来实现的话 就跟Lab0 一样 尽管可以处理重叠 前后的字符串问题 但是我们怎么来处理size这个问题呢 根据序号来存储 我们需要记忆住每个数据包的index 对于deque vector基本上下表就是我们来记忆index的 而且对于已经输入字节流进去的部分 我们需要做删除处理 那如果刚开始输入进来的index是 1 之后是10001 那我们怎么处理呢 没法处理- -(实践出真知)
第二个是对于unordered_map实现起来有难度 首先的就是 如何排序 其实这个map确实不好实现 第一个是脑子没转过来 没有想到用map - - 其实map也是可以的 只不过map一般是用于找寻是否存储了我们的目标 对于这种需要排序的而对是否存储 快速寻找的这种需求不大 所以我们采用set
对于数据结构介绍清楚了 下面就到了处理字符串的时候了
下面就是很多地方具体实现思路了 如果想自己实现的话 就别往下看了 - - 因为这个Lab核心就是怎么处理字符串 看了思路的话 难度就小了几倍了 如果思考了很久还是觉得无从下手的话 再看看 看完下面的思路 能不能自己实现出来
处理字符串 我们对于index+data.size() < start_idx的不做处理 直接掠过
对于字符串index 小于 start_idx 前面小于start_idx部分直接丢弃 然后把index设置为start_idx data剩余部分留着
通过重载< set可以进行排序了
我们每次就看set中有没有 字符串index 大于等于的我们即将要插入的index 如果index + data.size() < find_str.startpos 则说明没有交集 我们再进入处理 要插入的字符串与 set中离我们最近 小于我们要插入的index的字符串 如果还是没有交际 直接插入即可
如果对于第一个情况 有交集的话 我们直接删除我们find出来的那个字符串 并对两个字符串进行合并 对于第二个情况也是 出现交际 我们把我们find出来的字符串删除 先进行合并 再删除那个元素
最后要插入的时候 插入长度是min(我们目前剩余的空间,字符串长度)
输出的话 如果字节流空间满了 则不输出了 break 如果要输出的字符串长度大于剩余空间 我们就把能输出的部分给输出了 不能输出的部分就留下来 改一下startpos重新放到set中
4、最终代码实现(stream_reassembler.cc stream_reassembler.hh)
代码实现(stream_reassembler.hh)
#ifndef SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH
#define SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH
#include "byte_stream.hh"
#include <cstdint>
#include <string>
#include <set>
//! \brief A class that assembles a series of excerpts from a byte stream (possibly out of order,
//! possibly overlapping) into an in-order byte stream.
class StreamReassembler {
private:
struct node
{
long startpos;
std::string str;
node(long index,std::string& s) :startpos(index),str(s) {}
bool operator<(const node& b) const {return this->startpos < b.startpos;}
};
std::set<node> bytes{};
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
size_t _unassembled_bytes = 0;
long start_idx = 0,end_idx = -1;
bool _eof = false;
public:
//! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes.
//! \note This capacity limits both the bytes that have been reassembled,
//! and those that have not yet been reassembled.
int merge_nodes(const node& a,const node& b);
StreamReassembler(const size_t capacity);
//! \brief Receive a substring and write any newly contiguous bytes into the stream.
//!
//! The StreamReassembler will stay within the memory limits of the `capacity`.
//! Bytes that would exceed the capacity are silently discarded.
//!
//! \param data the substring
//! \param index indicates the index (place in sequence) of the first byte in `data`
//! \param eof the last byte of `data` will be the last byte in the entire stream
void push_substring(const std::string &data, const uint64_t index, const bool eof);
//! \name Access the reassembled byte stream
//!@{
const ByteStream &stream_out() const { return _output; }
ByteStream &stream_out() { return _output; }
//!@}
//! The number of bytes in the substrings stored but not yet reassembled
//!
//! \note If the byte at a particular index has been pushed more than once, it
//! should only be counted once for the purpose of this function.
size_t unassembled_bytes() const;
//! \brief Is the internal state empty (other than the output stream)?
//! \returns `true` if no substrings are waiting to be assembled
bool empty() const;
};
#endif // SPONGE_LIBSPONGE_STREAM_REASSEMBLER_HH
代码实现(stream_reassembler.cc)
#include "stream_reassembler.hh"
// Dummy implementation of a stream reassembler.
// For Lab 1, please replace with a real implementation that passes the
// automated checks run by `make check_lab1`.
// You will need to add private members to the class declaration in `stream_reassembler.hh`
template <typename... Targs>
void DUMMY_CODE(Targs &&... /* unused */) {}
using namespace std;
StreamReassembler::StreamReassembler(const size_t capacity) : _output(capacity), _capacity(capacity) {}
//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
int StreamReassembler::merge_nodes(const node& lower,const node& higher)
{
long lower_endpos = lower.str.size() + lower.startpos;
long newstr_size = -1,higher_strsize = higher.str.size();
if(lower_endpos >= higher.startpos)
{
newstr_size = 0;
if(lower.startpos < higher.startpos)
newstr_size += (higher.startpos - lower.startpos);
long lower_plus = (lower_endpos - higher.startpos);
newstr_size += max(lower_plus,higher_strsize);
}
return newstr_size;
}
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof)
{
long endpos = index + data.size(),idx = index;
string sub_str = data;
if(_eof || endpos < start_idx) return;
if(eof) end_idx = index + data.size();
if(idx < start_idx)
{
sub_str = data.substr(start_idx-idx);
idx = start_idx;
}
node insert(idx,sub_str);
while(true)
{
auto iter = bytes.lower_bound(insert);
long newstr_size = 0;
if(iter != bytes.end() && (newstr_size = merge_nodes(insert,*iter)) >= 0)
{
long delpos = iter->startpos - insert.startpos;
long tmp_size = iter->str.size();
if(newstr_size == tmp_size + delpos)
insert.str = insert.str.substr(0,delpos) + iter->str;
_unassembled_bytes -= iter->str.size();
bytes.erase(iter);
}
else break;
}
do
{
auto iter = bytes.lower_bound(insert);
if(iter == bytes.begin()) break;
--iter;
long newstr_size = 0;
if((newstr_size = merge_nodes(*iter,insert)) >= 0)
{
long delpos = insert.startpos - iter->startpos;
long tmp_size = insert.str.size();
if(newstr_size == tmp_size + delpos)
insert.str = iter->str.substr(0,delpos) + insert.str;
else insert.str = iter->str;
insert.startpos = iter->startpos;
_unassembled_bytes -= iter->str.size();
bytes.erase(iter);
}
else break;
} while(true);
size_t max_insert_size = min(_capacity - _unassembled_bytes,insert.str.size());
insert.str = insert.str.substr(0,max_insert_size);
bytes.emplace(insert);
_unassembled_bytes += insert.str.size();
auto iter = bytes.begin();
while((iter = bytes.begin()) != bytes.end() && iter->startpos == start_idx && _output.remaining_capacity() > 0)
{
long send_bytes = min(iter->str.size(),_output.remaining_capacity());
string send_str = iter->str.substr(0,send_bytes);
_output.write(send_str);
_unassembled_bytes -= send_str.size();
start_idx += send_str.size();
if(send_str.size() != iter->str.size())
{
insert.startpos = iter->startpos + send_str.size();
insert.str = iter->str.substr(send_str.size());
bytes.emplace(insert);
}
bytes.erase(iter);
}
if(start_idx == end_idx)
{
_output.end_input();
_eof = true;
}
}
size_t StreamReassembler::unassembled_bytes() const
{
return _unassembled_bytes;
}
bool StreamReassembler::empty() const
{
return unassembled_bytes() == 0;
}
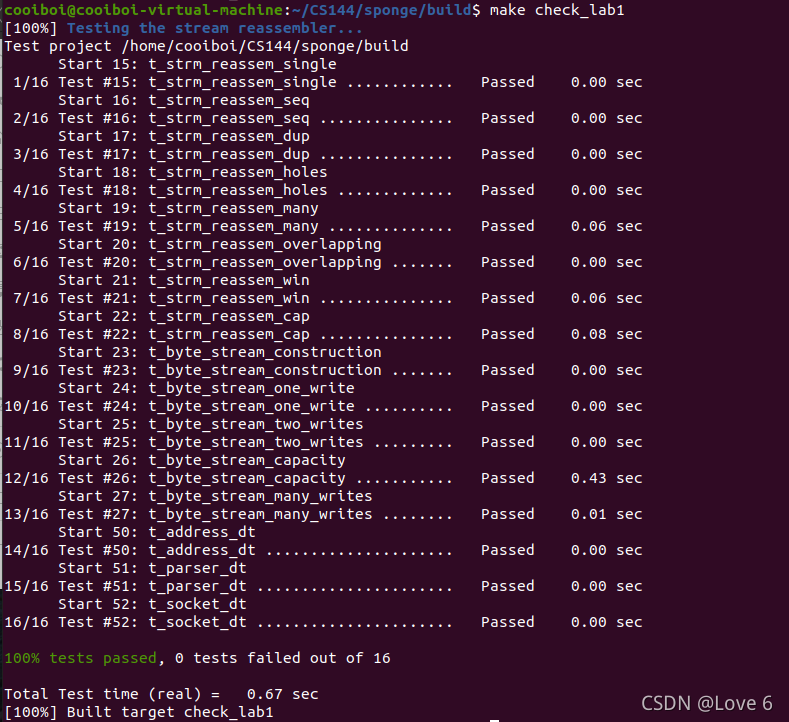
5、编译运行 测试用例检验程序 (100% tests passed)
对了 这里提一嘴 大家记得把代码一定要备份一份 如果会git的话 要记得送上去 如果不会的话 一定要在一些地方把代码拷贝下来 以后之后修改了出错了 改不回去了 - -
我们老样子 进入sponge/build make make完后 make check_lab1 如下图 终于写完了 吃饭去了 大家有缘下一个Lab见 希望这个部分不要出错 哈哈哈 各位再见















 1097
1097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











