







虚拟机安装
高级命令使用
Shell 编程
Hadoop 环境搭建
SSH免密登录(伪分布式)
- SSH 免密登录: 在虚拟机输入代码 一直回车即可生成对应的公钥私钥文件
ssh-keygen -t rsa
- 执行生成公钥私钥后在 本服务的 ~/.ssh/ 下会生成 对应的公钥文件 和私钥文件
ll ~/.ssh/

3. 需要公钥复制到免密登录的其他服务器(这里因为是伪分布式 所以直接放到本地就行,自己免密码登录自己)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
把公钥 重定向追加到 authorized_keys 文件中,authorized_keys 文件名必须正确书写 链接自己 查看免密登录效果
ssh 自己服务器IP
Hadoop 集群安装部署(伪分布式)
上传解压 安装包, 先把解压后的目录存放在 /usr/local/hadoop 下 (个人习惯)
链接:https://pan.baidu.com/s/1RmfjYg1JLsiheqBN7p4Z6A?pwd=5xz2
提取码:5xz2
tar -zxvf hadoop-3.2.0.tar.gz
后期操作 会经常用到 解压后的 bin和sbin 目录里面的命令 这里配置一下Hadoop 的环境变量
vi /etc/profile
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
source /etc/profile
修改Hadoop配置文件(/usr/local/hadoop/hadoop-3.2.0/etc/hadoop/) 主要修改下面这几个文件:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
workers
- 首先修改 hadoop-env.sh 文件,增加环境变量信息,添加到 hadoop-env.sh 文件末尾即可。
指定java的安装位置
export JAVA_HOME=/usr/local/JDK
hadoop的日志的存放目录
export HADOOP_LOG_DIR=/usr/local/hadoop/hadoop_repo/logs/hadoop
- 修改 core-site.xml 文件
注意 fs.defaultFS 属性中的主机名需要和你配置的主机名保持一致
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop_repo</value>
</property>
</configuration>
- hdfs-site.xml 把hdfs中文件副本的数量设置为1,因为现在伪分布集群只有一个节点
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- mapred-site.xml 设置mapreduce使用的资源调度框架
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml 设置yarn上支持运行的服务和环境变量白名单
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- workers 修改主机名 伪分布 从节点 就是本机:bigdata01
格式化HDFS
hdfs namenode -format
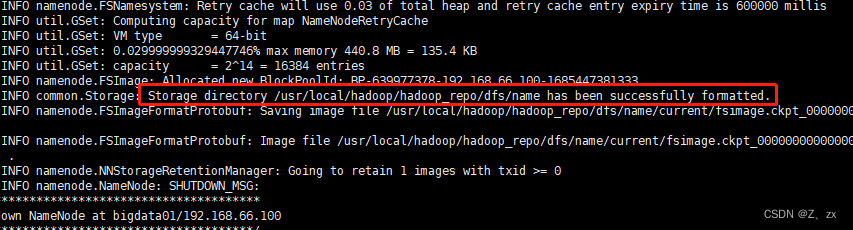
如果能看到successfully formatted这条信息就说明格式化成功了。
如果提示错误,一般都是因为配置文件的问题,当然需要根据具体的报错信息去分析问题。
注意:格式化操作只能执行一次,如果格式化的时候失败了,可以修改配置文件后再执行格式
化,如果格式化成功了就不能再重复执行了,否则集群就会出现问题。
如果确实需要重复执行,那么需要把/usr/local/hadoop/hadoop_repo目录中的内容全部删除,再执行格式化
可以这样理解,我们买一块新磁盘回来装操作系统,第一次使用之前会格式化一下,后面你会没事就去格
式化一下吗?肯定不会的,格式化之后操作系统又得重装了
启动/停止 Hadoop
使用sbin目录下的start-all.sh脚本
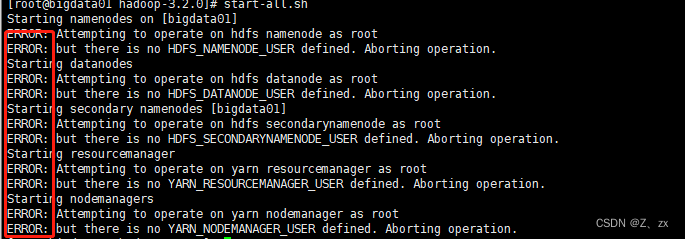
执行的时候发现有很多ERROR信息,提示缺少HDFS和YARN的一些用户信息。
解决方案如下:
修改sbin目录下的 start-dfs.sh , stop-dfs.sh 这两个脚本文件,在文件前面增加如下内容
vi start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vi stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改sbin目录下的 start-yarn.sh , stop-yarn.sh 这两个脚本文件,在文件前面增加如下内容
vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
重新启动
1.查看进程是否启动成功
jps
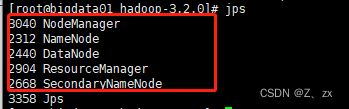
5个进程都存在说明启动成功了
- 还可以通过webui界面来验证集群服务是否正常
HDFS webui界面:http://IP:9870
YARN webui界面:http://IP:8088
使用sbin目录下的 start-all.sh 脚本停止
开启日志聚合功能
- 修改 yarn-site.xml 添加下面内容
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://IP:19888/jobhistory/logs/</value>
</property>
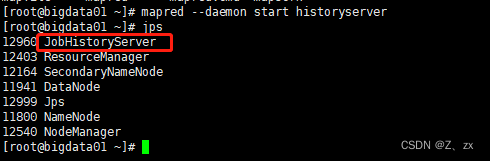
- 启动historyserver进程,需要在集群的所有节点上都启动这个进程
bin/mapred --daemon start historyserver
停止Hadoop集群中的任务
使用yarn application -kill命令,后面指定任务id即可
yarn application -kill application_15877135678















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









