






一、DataX3.0概览
DataX 是阿里云 DataWorks 数据集成 的开源版本,主要就是用于实现数据间的离线同步。 DataX 致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等 各种异构数据源(即不同的数据库) 间稳定高效的数据同步功能。

-
设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
-
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
二、DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader�为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。

核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
三、使用 DataX 实现数据同步
准备工作:
JDK(1.8 以上,推荐 1.8)
Python(2,3 版本都可以)
Apache Maven 3.x(Compile DataX)(手动打包使用,使用 tar 包方式不需要安装)
.查看是否具备jdk和python环境:
查看jdk版本,命令:java -version
查看python的版本,命令(大写V):python -V
注意:
JDK(1.6以上,1.8即可)
Python(一般2.7都可以)一定要为python2,因为后面执行datax.py的时候,里面的python的print会执行不了,导致运行不成功,会提示你print语法要加括号,python2中加不加都行 python3中必须要加,否则报语法错
如果上一步的环境不存在则参考下面的博客进行环境安装:
安装java环境,参考博客(不用按照步骤去卸载,直接看安装步骤即可):https://blog.csdn.net/love3765/article/details/88783126.
因为 CentOS 7 上自带 Python 2.7 的软件包,所以不需要进行安装,
如要安装请参照:安装python环境,参考博客(安装步骤全部执行即可):https://www.cnblogs.com/Jomini/p/10507077.html.
4.下载DataX:
https://github.com/alibaba/DataX/blob/master/userGuid.md
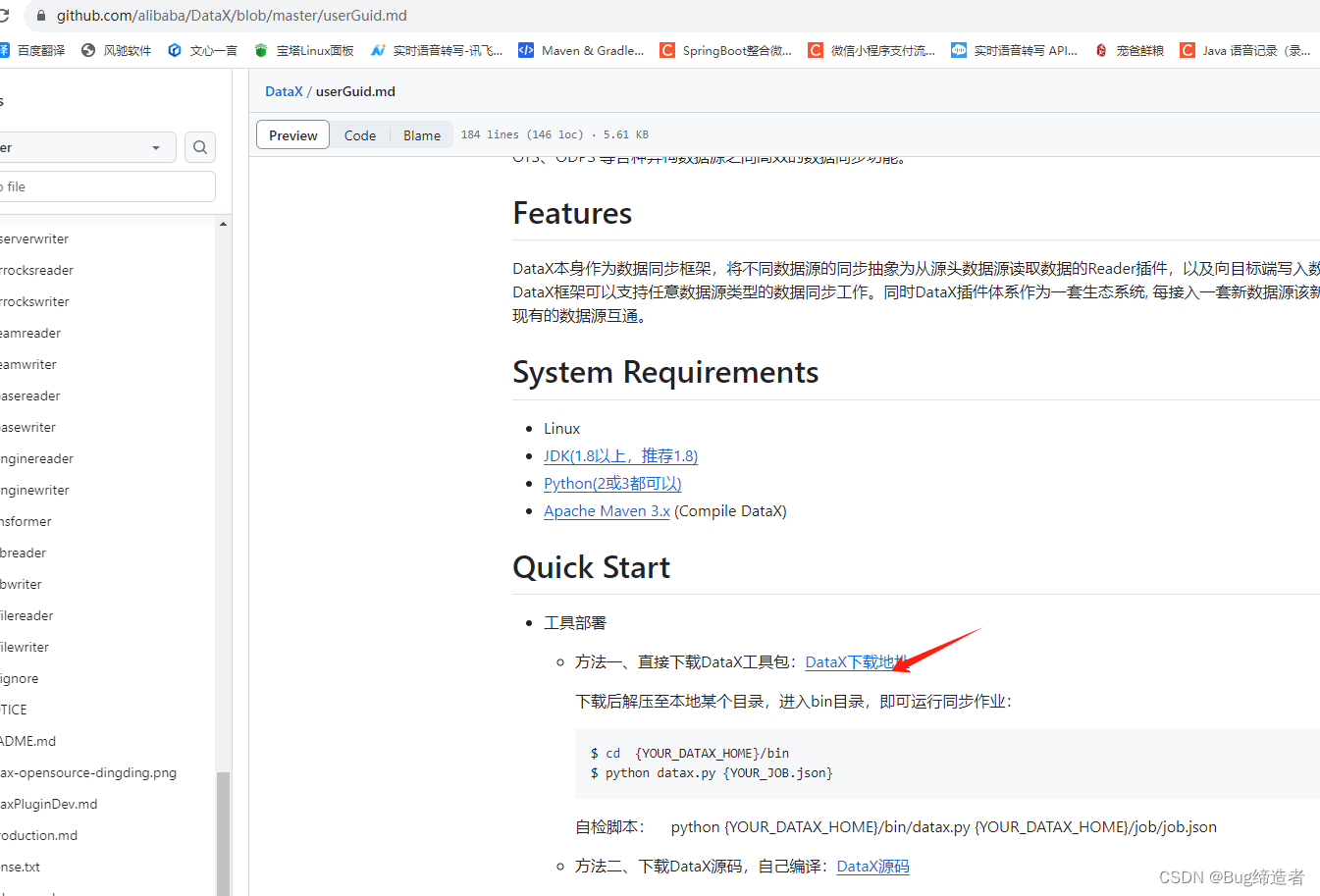

下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
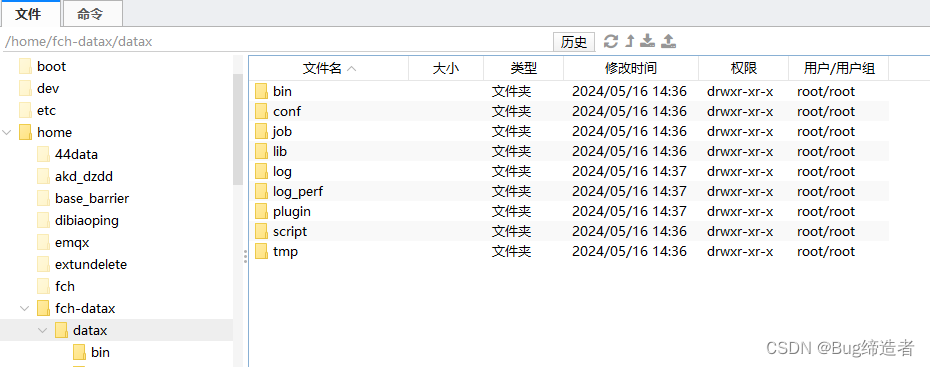
输入命令验证:
python /home/fch-datax/datax/bin/datax.py /home/fch-datax/datax/job/job.json

.通过 DataX 实现ORACLE往MySQL 数据同步
第一步、创建作业的配置文件(json格式)
可以通过命令查看配置模板: python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
示例:生成 ORACLE 到 MySQL 同步的模板:
cd /home/fch-datax/dataxpython bin/datax.py -r oraclereader -w mysqlwriter > job/oracle2mysql.json
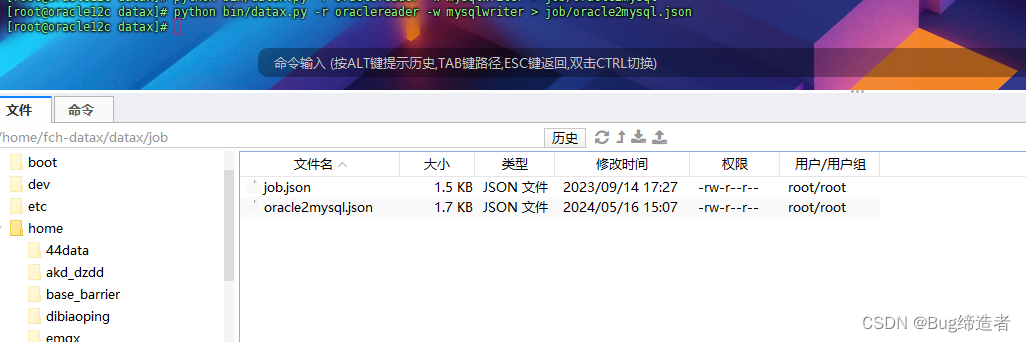
然后编辑oracle2mysql. json文件,将要移动的oracle数据源与要迁移到的mysql数据库信息进行配置。
附标准模版
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader", # 读取端
"parameter": {
"column": [], # 需要同步的列 (* 表示所有的列)
"connection": [
{
"jdbcUrl": [], # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接用户
"username": "", # 连接密码
"where": "" # 描述筛选条件
}
},
"writer": {
"name": "mysqlwriter", # 写入端
"parameter": {
"column": [], # 需要同步的列
"connection": [
{
"jdbcUrl": "", # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接密码
"preSql": [], # 同步前. 要做的事
"session": [],
"username": "", # 连接用户
"writeMode": "" # 操作类型
}
}
}
],
"setting": {
"speed": {
"channel": "" # 指定并发数
}
}
}
}

最后执行:
python bin/datax.py job/oracle2mysql.json
输出:
四、DataX-Web 安装部署
直接将安装包下载下来(下载地址:百度网盘 请输入提取码,提取码:cpsk),解压安装到指定的路径即可:![]()
部署
执行一键安装脚本,进入解压后的目录,找到 bin 目录下面的 install.sh 文件,如果选择交互式的安装,则直接执行:
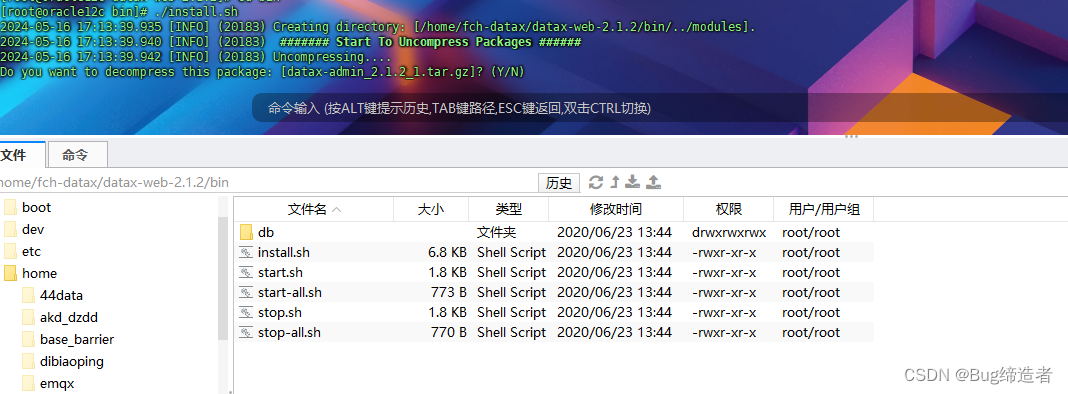
在交互模式下,对各个模块的 package 压缩包的解压以及 configure 配置脚本的调用,都会请求用户确认,可根据提示查看是否安装成功,如果没有安装成功,可以重复尝试;
输入对应的mysql连接信息
成功后初始化数据库
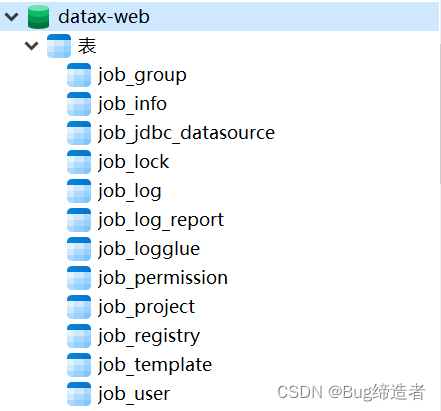
配置
安装完成之后,在项目目录下 /modules/datax-execute/bin/env.properties 指定PYTHON_PATH 的路径(即 DataX 的 python 脚本路径):


启动服务
一键启动所有服务
./start-all.sh
中途可能发生部分模块启动失败或者卡住,可以退出重复执行,如果需要改变某一模块服务端口号,则:
vi ./modules/{module_name}/bin/env.properties
找到 SERVER_PORT 配置项,改变它的值即可。 当然也可以单一地启动某一模块服务:
./start.sh -m {module_name}
一键取消所有服务
./stop-all.sh
当然也可以单一地停止某一模块服务:
./stop.sh -m {module_name}查看服务(注意!注意!)
在 Linux 环境下使用 JPS 命令,查看是否出现 DataXAdminApplication 和DataXExecutorApplication 进程,如果存在这表示项目运行成功:

访问 Web UI
部署完成后,在浏览器中输入 http://ip:port/index.html 就可以访问对应的主界面(ip 为 datax-admin 部署所在服务器 ip,port 为 datax-admin 指定的运行端口 9527),输入用户名 admin 密码 123456 就可以直接访问系统:

如果你登录不进去,显示账号密码错误,可以先去数据库看看是否有 dataxweb 数据库生成,如果没有则需要我们手动把 datax_web.sql 导入 dataxweb 数据库中,先创建 dataxweb 数据库再进入此数据库,最后导入 datax_web.sql 文件 即可
五、DataX-Web 任务部署
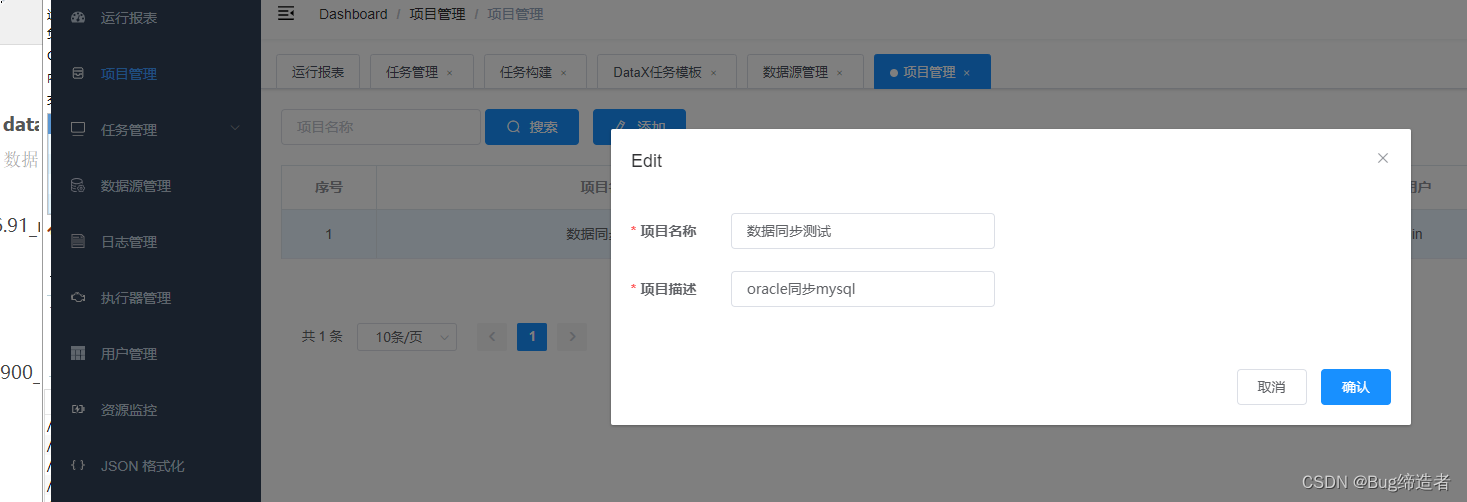
创建项目
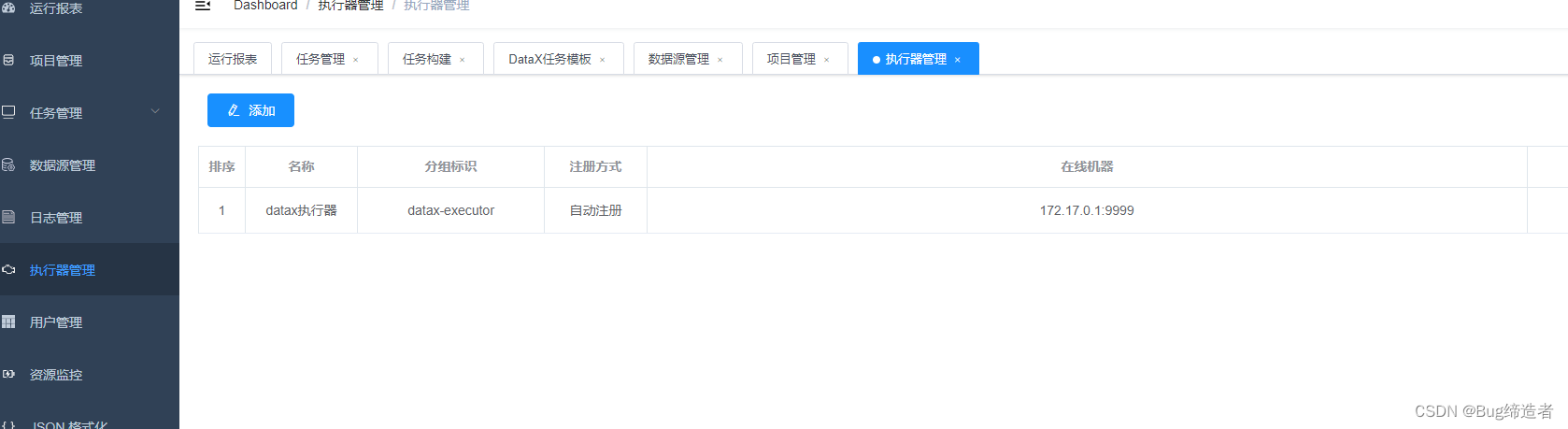
执行器管理
在这里会列举所有在线的 Executor 列表:
创建数据源
oracle源数据库

mysql 数据源
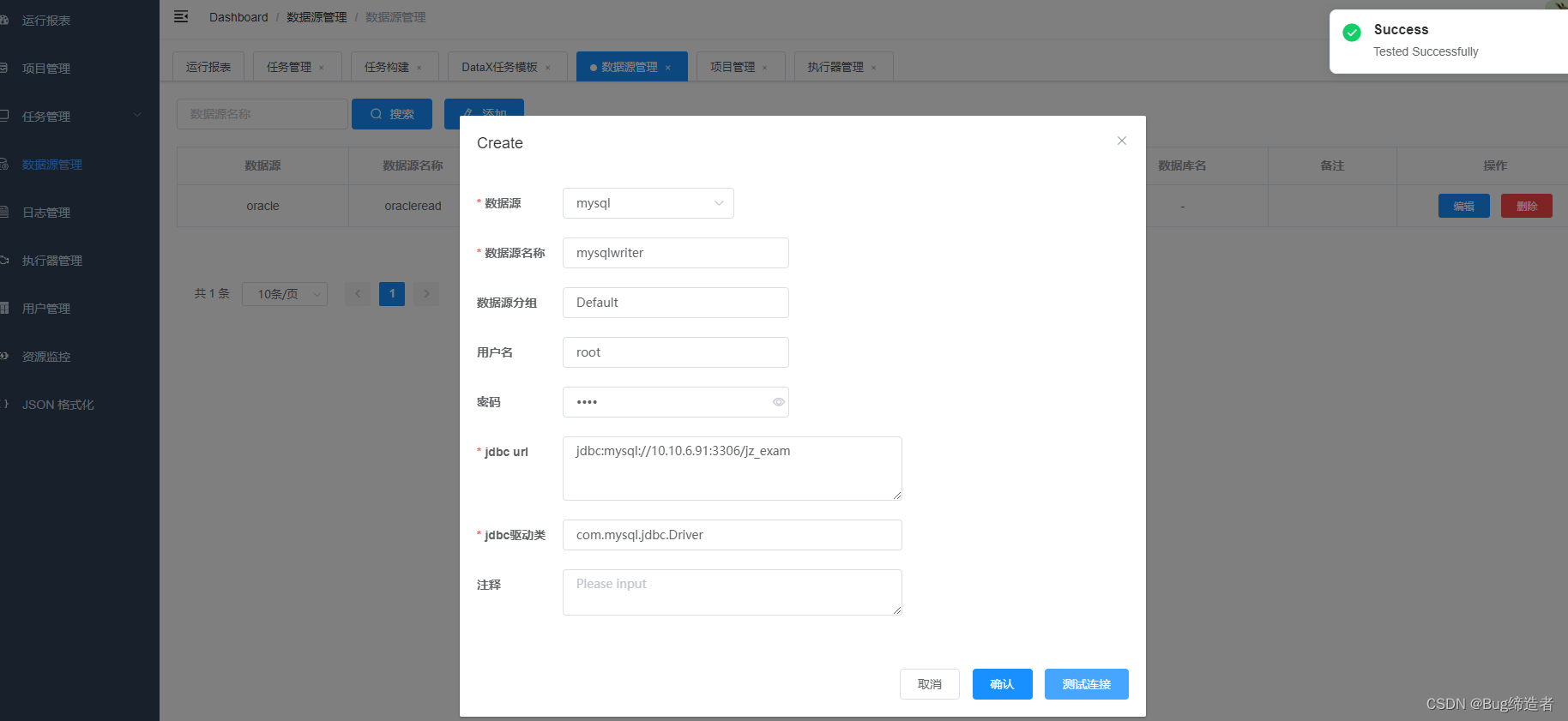
创建任务模板

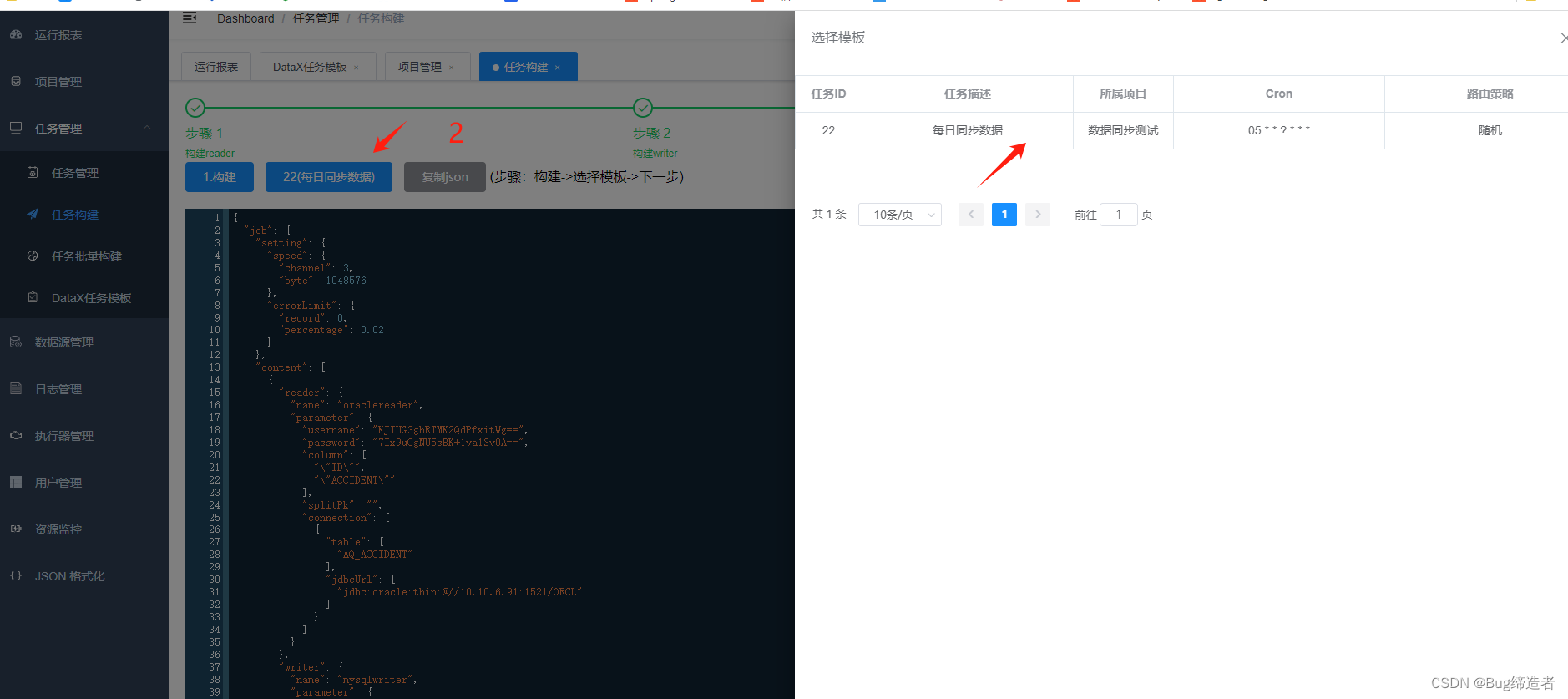
任务创建
构建 oracle的reader

构建 myql数据writer

设置字段映射
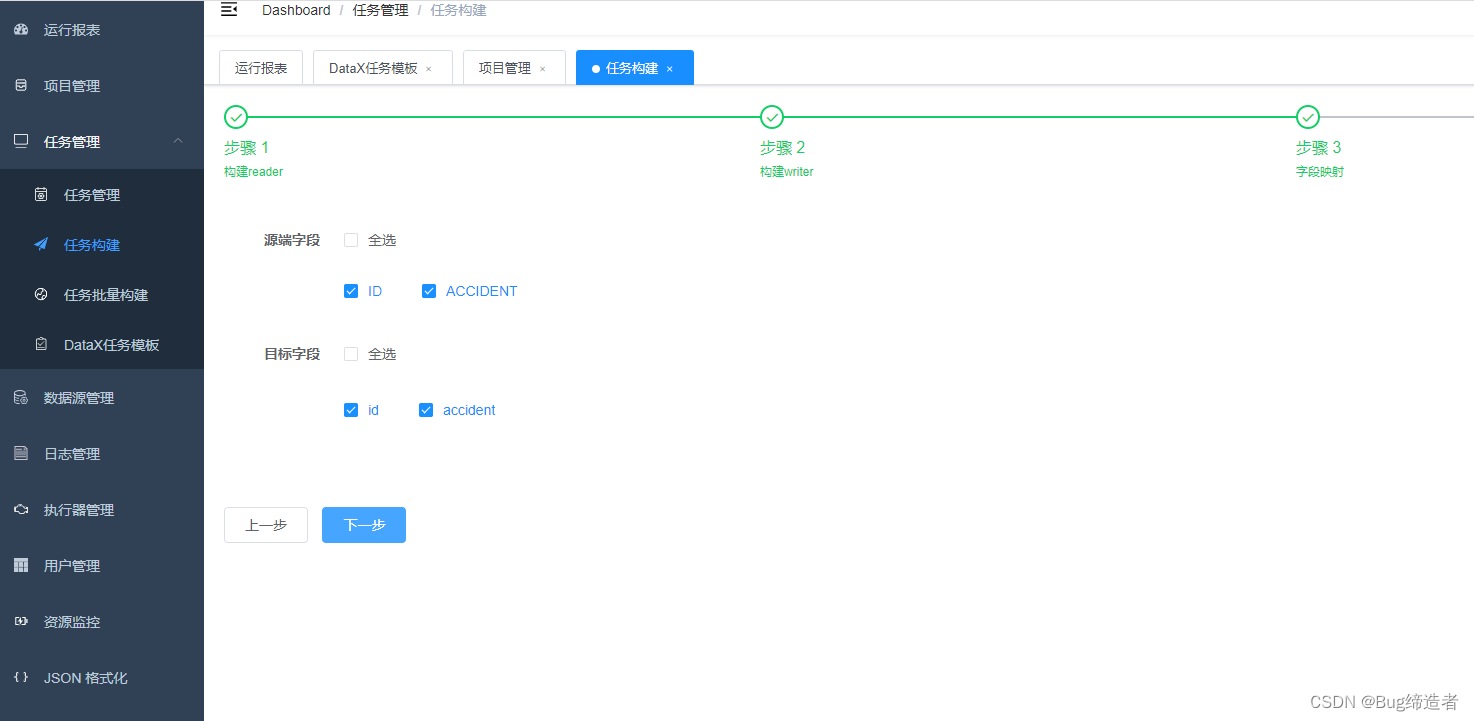
构建

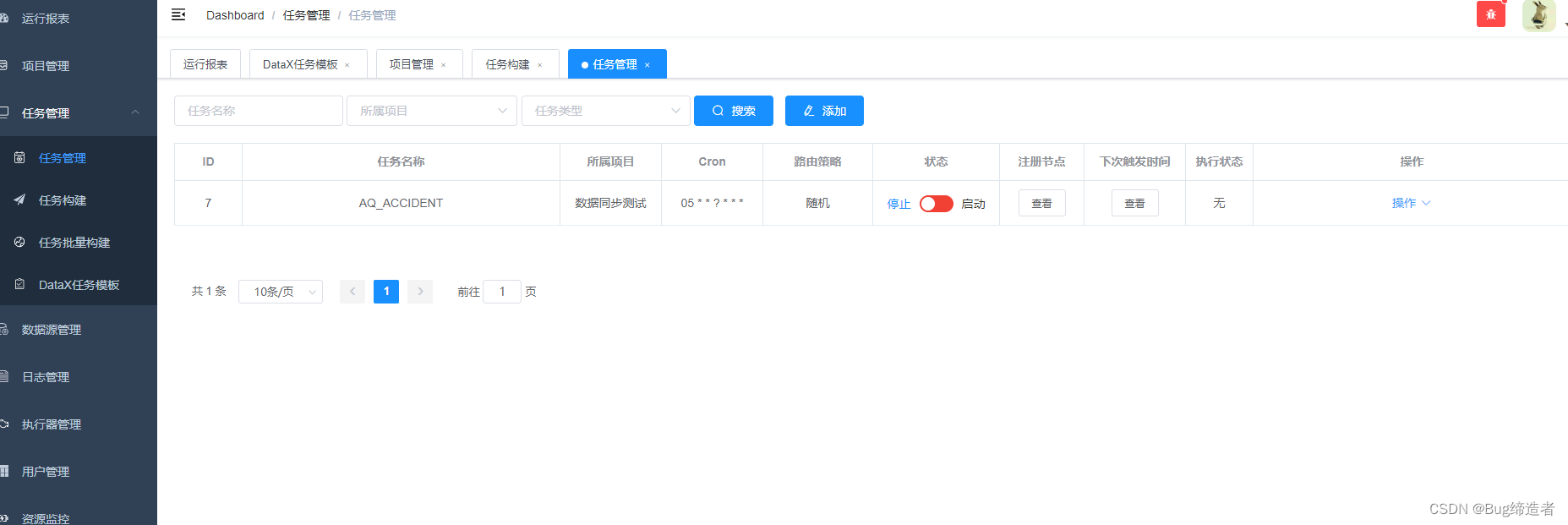
DataX-Web 任务管理
启动项目
 日志查询
日志查询
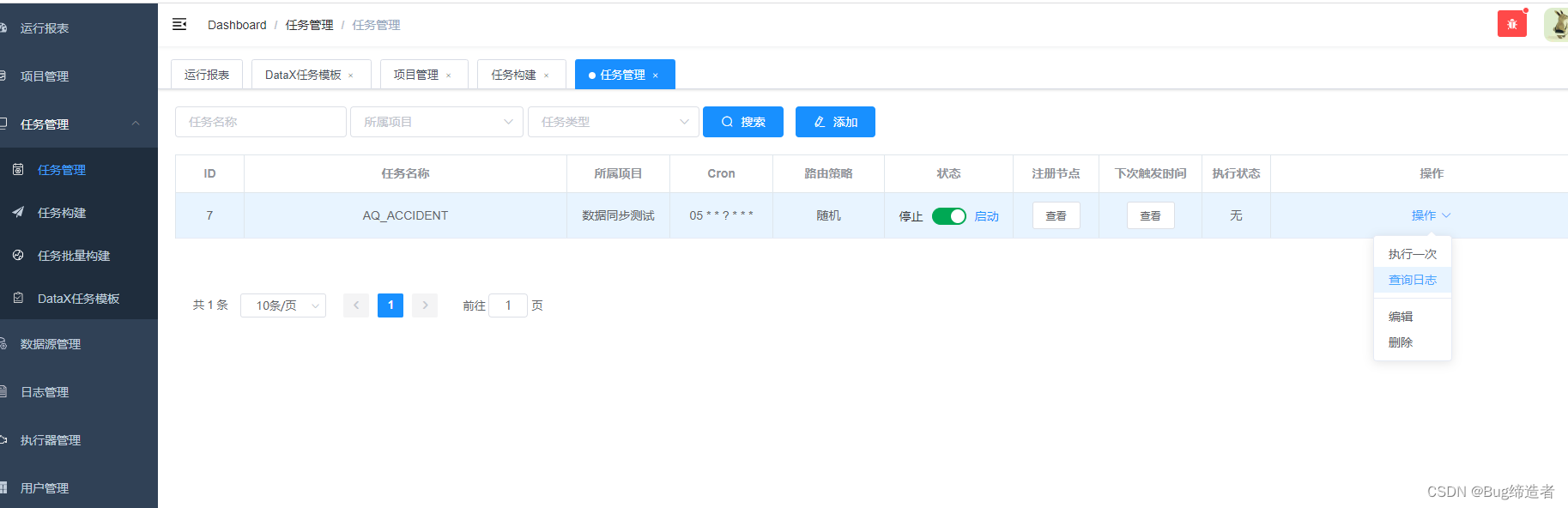
问题汇总
如果任务执行失败,且报错
“在有总bps限速条件下,单个channel的bps值不能为空,也不能为非正数”
修改文件datax/conf/core.json

core -> transport -> channel -> speed -> "byte": 2000000,将单个channel的大小改为2MB即可。















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









