







hadoop广义上讲是一个大数据生态圈,接受大量处理、处理大量数据的一个全套的框架!
hadoop3.x版本以后,主要有三大模块,HDFS、YARN、mapReduce这三大核心组成!
什么是HDFS?
分布式文件系统,hadoop集群的功能类似于三个臭皮匠抵一个诸葛亮,把很多配置低、廉价的服务器组织到一起,协调好发挥出最大的作用。
分布式文件系统就是把存储文件到可用的服务器上,你不用查看计划应该存储到哪个服务器上,HDFS管家帮你规划实现!!
什么是YARN?
简称资源调度框架,流水线的组长,活多的时候分配多一点的人,活少的时候分配少一点的人,不会浪费人力也不会让活积压干不完。 YARN就是流水线的组长,业务流程数据就是活,电脑内存就是工人!
什么是MapReduce?
计算组件,计算处理数据的封装底层的代码,你写代码的时候,调用可以省事情,但是发展很多年弊端很多,逐渐被弃用!
三个服务器的hostname分别是flinka flinkb flinkc flinka是我们集群的主机



flinka--->flinkb
flinka-->flinkc
flinka-->flinka
都做了免密登录,至于怎么实现,自行百度。很简单!!!
创建目录
在/dev/bigdata下创建三个同级别的文件夹
server 安装位置
data 存储数据位置
export 其他
一、下载hadoop、解压hadoop
1.1、配置hdfs-env.sh文件,这里是配置jdk环境变量以及指定各个进程用户名的地方
目录/dev/bigdata/server/hadoop-3.3.0/etc/hadoop
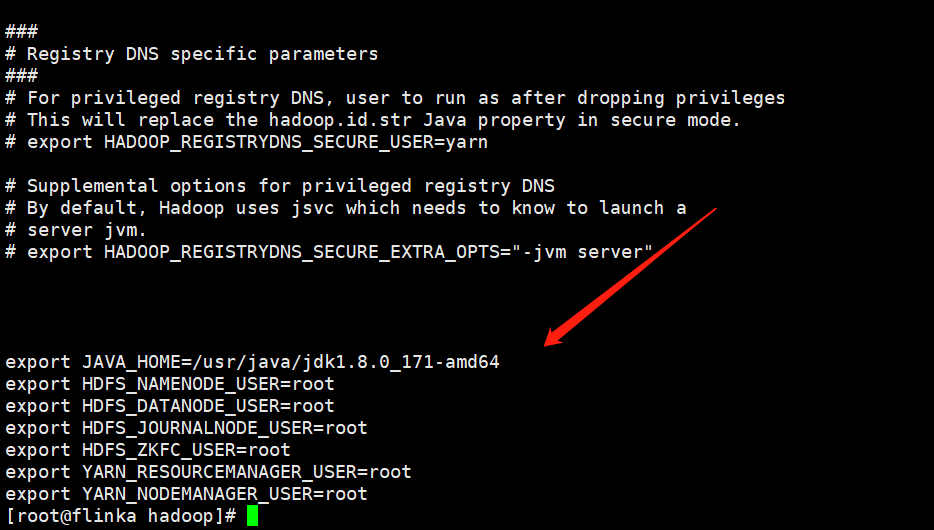
export JAVA_HOME=你服务器jdk安装的目录位置
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
输入G,然后就到了文件的末尾,复制以上的代码,然后保存退出
1.2、配置core-site.xml文件
初始是这样的
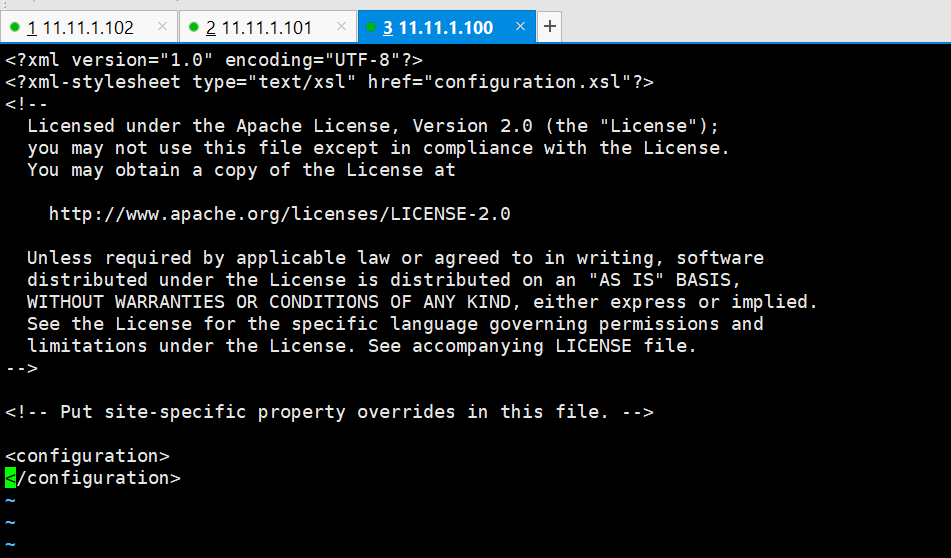
复制以下的代码
<configuration>
<!-- 配置分布式文件系统的类型 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://flinka:8020</value>
</property>
<!-- 配置hadoop本地保存数据的位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/dev/bigdata/data/hadoop</value>
</property>
<!-- 设置HDFS WEB UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 删除文件后先放到.Trash目录 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
<description>单位是分钟,1440/60 = 24 小时,保留一天时间</description>
</property>
</configuration>
1.3、配置hdfs-site.xml文件,这个是配置hdfs的备份服务器的
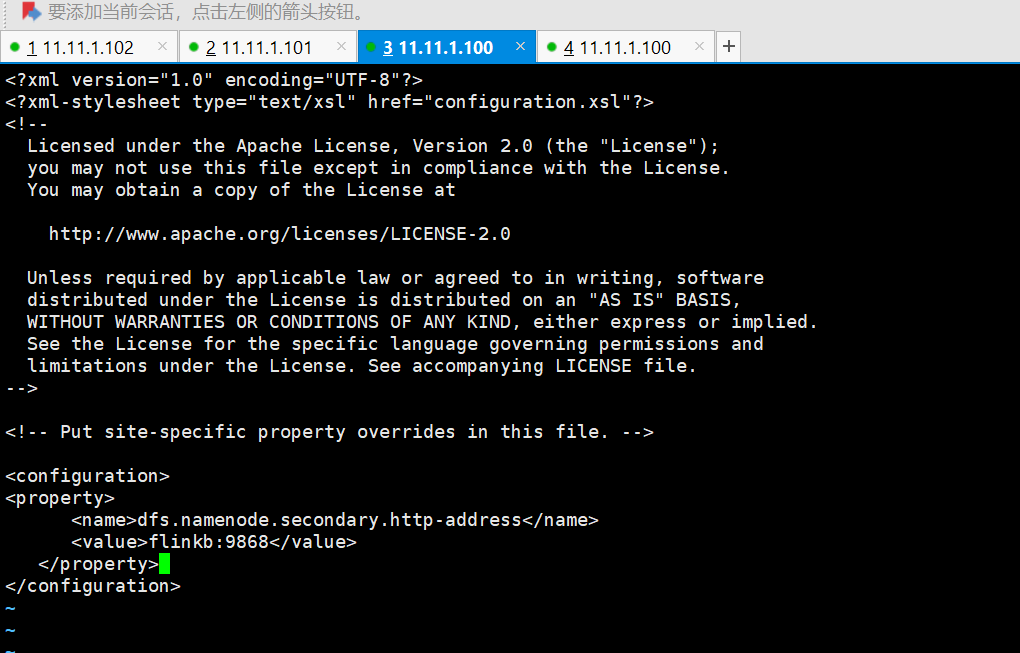
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>flinkb:9868</value>
</property>1.4、配置mapred-site.xml
配置计算程序运行的模式,是yarn还是local
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>flinka:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>flinka:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>1.5、yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>flinka</value>
</property>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://flinka:19888/jobhistory/logs</value>
</property>
<!--多长时间聚合删除一次日志 此处-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>2592000</value><!--30 day-->
</property>1.6、works
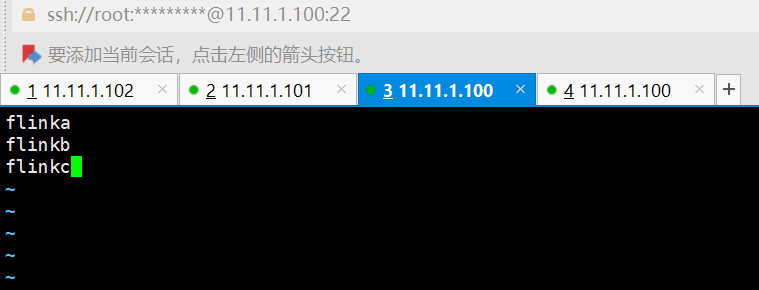
1.7、配置hadoop的环境变量
vi /etc/profile
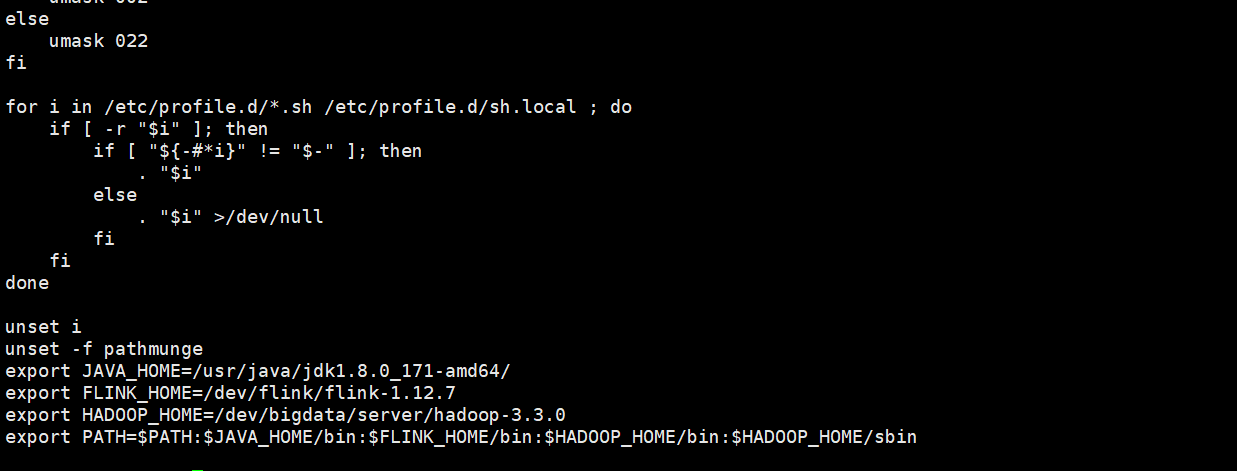
保存文件:wq
source /etc/profile
分发hadoop到其他机器上
scp -r /dev/bigdata root@flinkc:/dev/
scp -r /dev/bigdata root@flinkb:/dev/
分发环境变量给其他的机器

在其他机器上生效环境变量配置
source /etc/profile
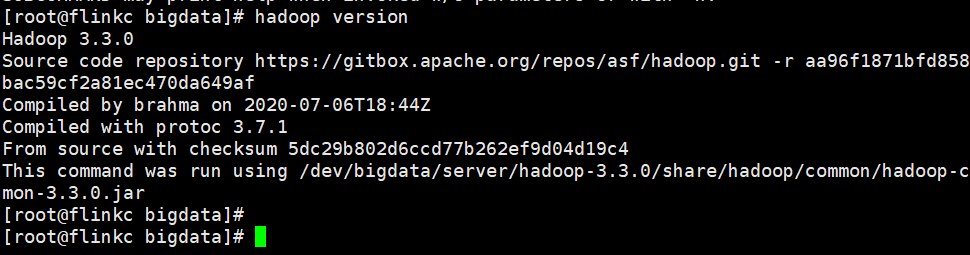
检查是否配置成功
hadoop version
启动hadoop集群
最重要的命令 初始化NameNode 这个只能在初次启动hadoop集群的时候初始化,后期如果初始化可能会出现数据清除以及集群的节点之间相互不认识,需要重新搭建集群!!
在主机上运行hdfs namenode -format
如果报错的话,说明配置的文件存在问题,根据相应的错误检查一下配置
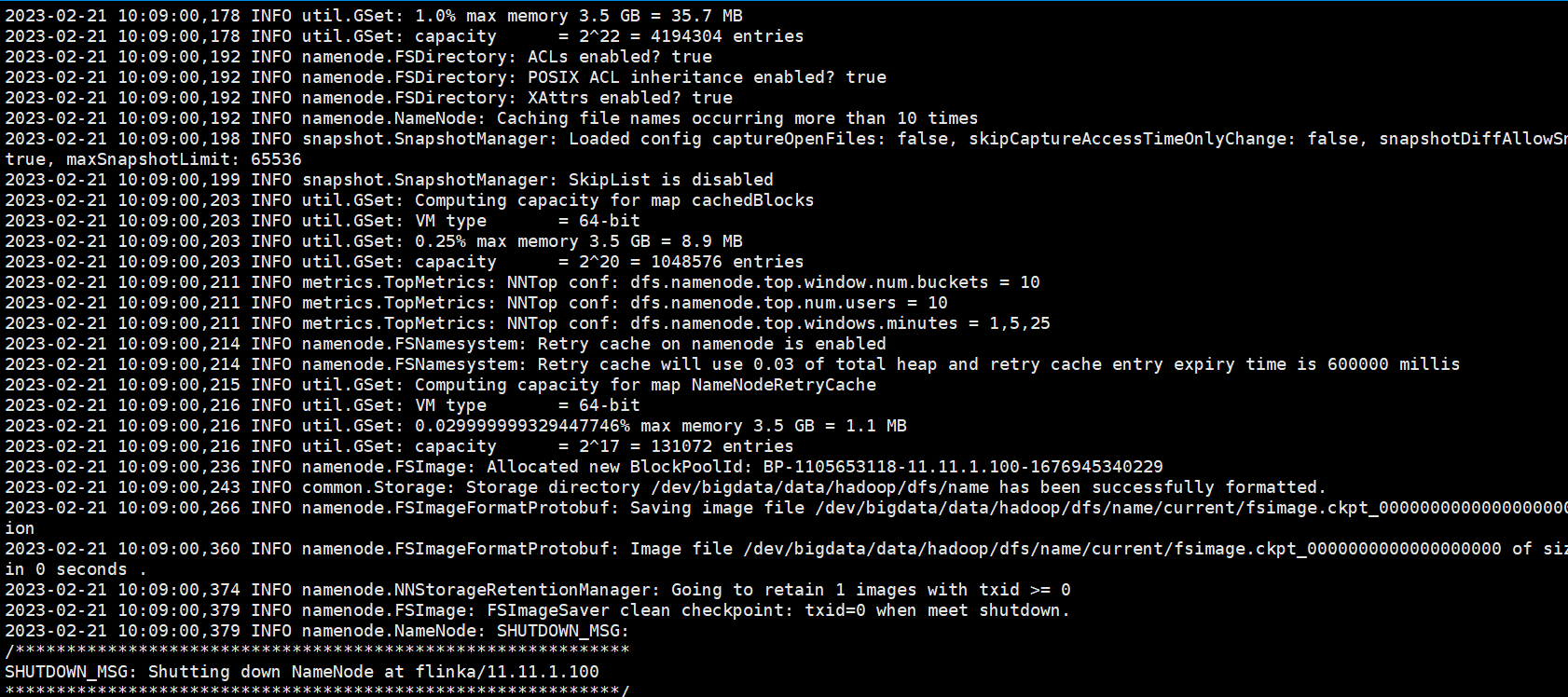
出现sucessfully formatted 说明初始化完成,只需要在一台master机器上初始化一次就够了!
启动集群 start-dfs.sh
报错
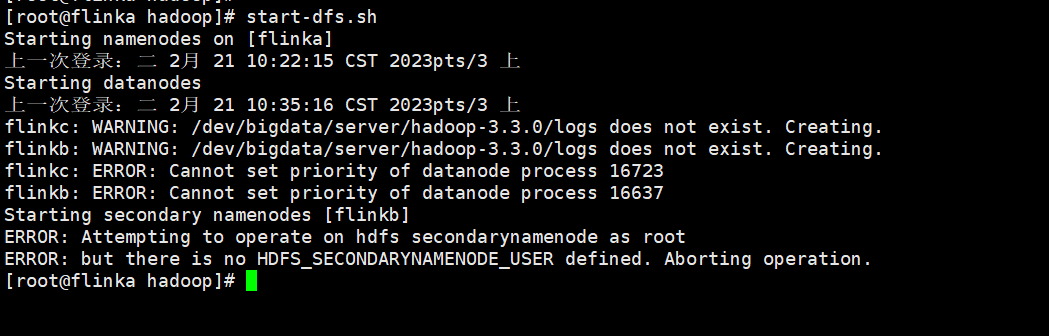
百度了很多,这个答案是对的
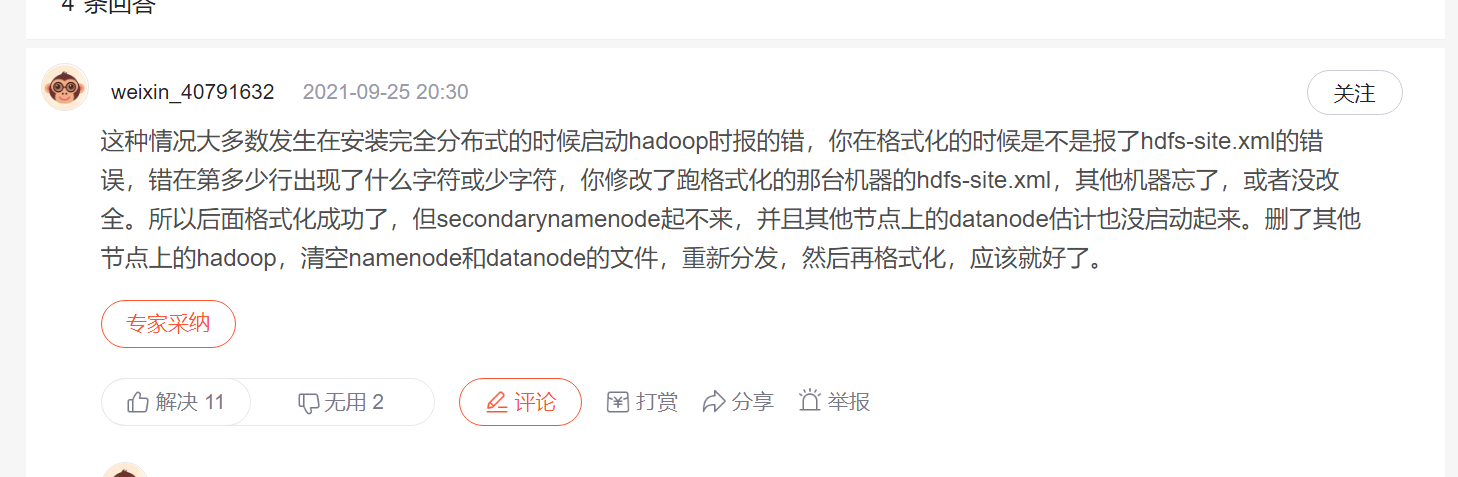
删除了/dev/bigdata/data/hadoop hadoop本地数据存储位置下的所有数据,然后把其他机器上的hadoop安装以及数据全部删除!!!
重新分发数据到其他机器上,然后在初始化数据!
再启动start-dfs.sh
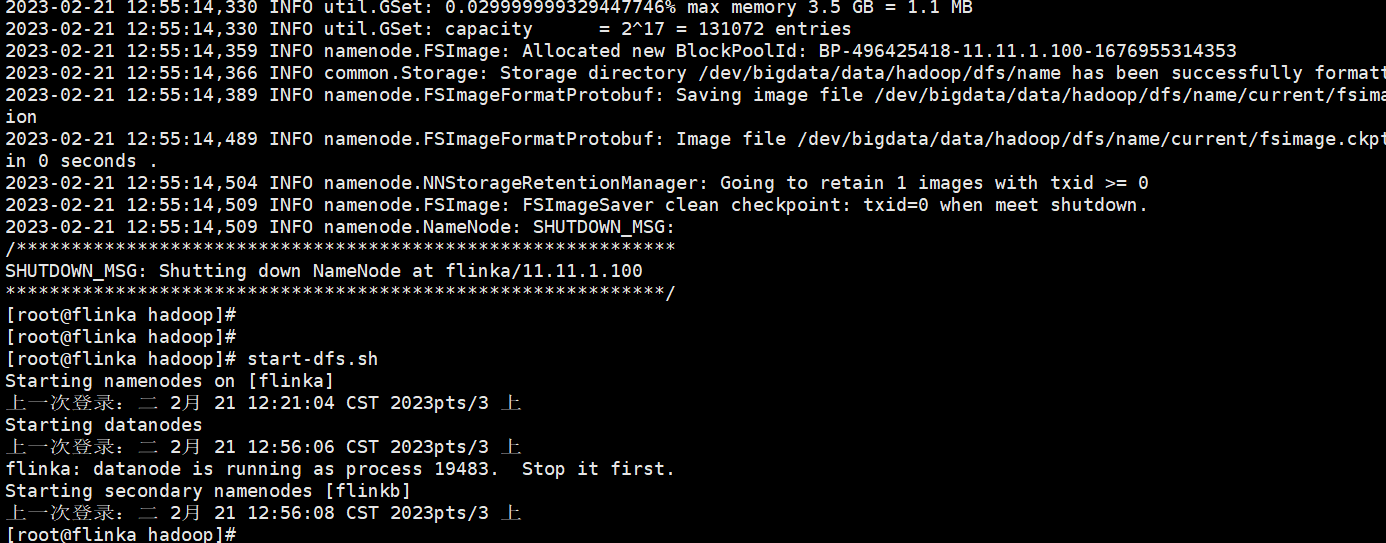
通过jps查看进程
flinka 下面有NameNode
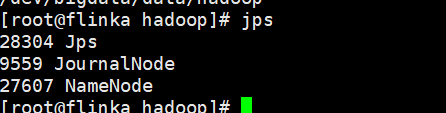
这里有一个问题,flinka是主节点,但是里面只有NameNode没有DataNode?
原因,在生成免密登录的密钥的时候,没有对自身分发
ssh-copy-id flinka
回车
flinkb 下面有
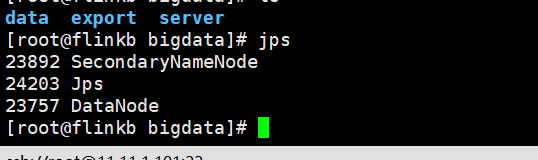
flinkc
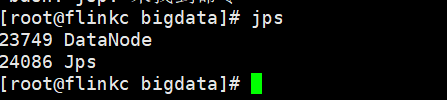
启动yarn集群
start-yarn.sh
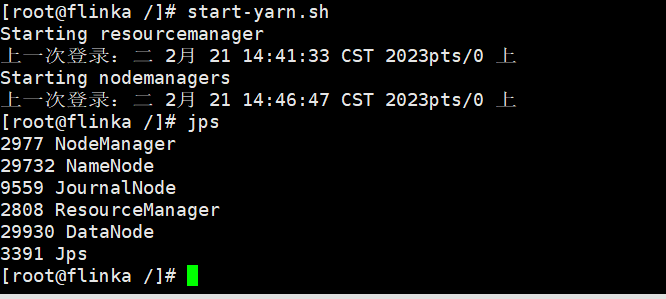
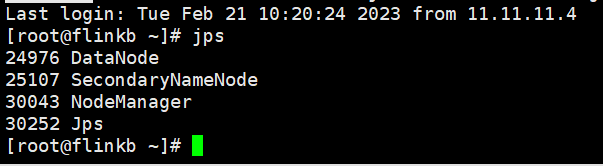
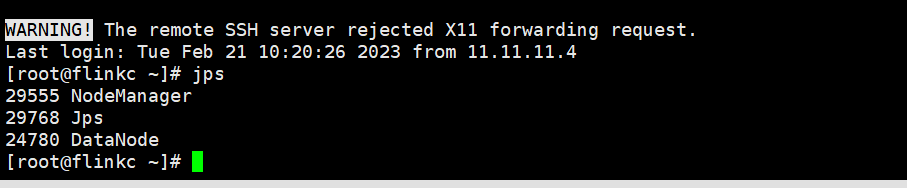
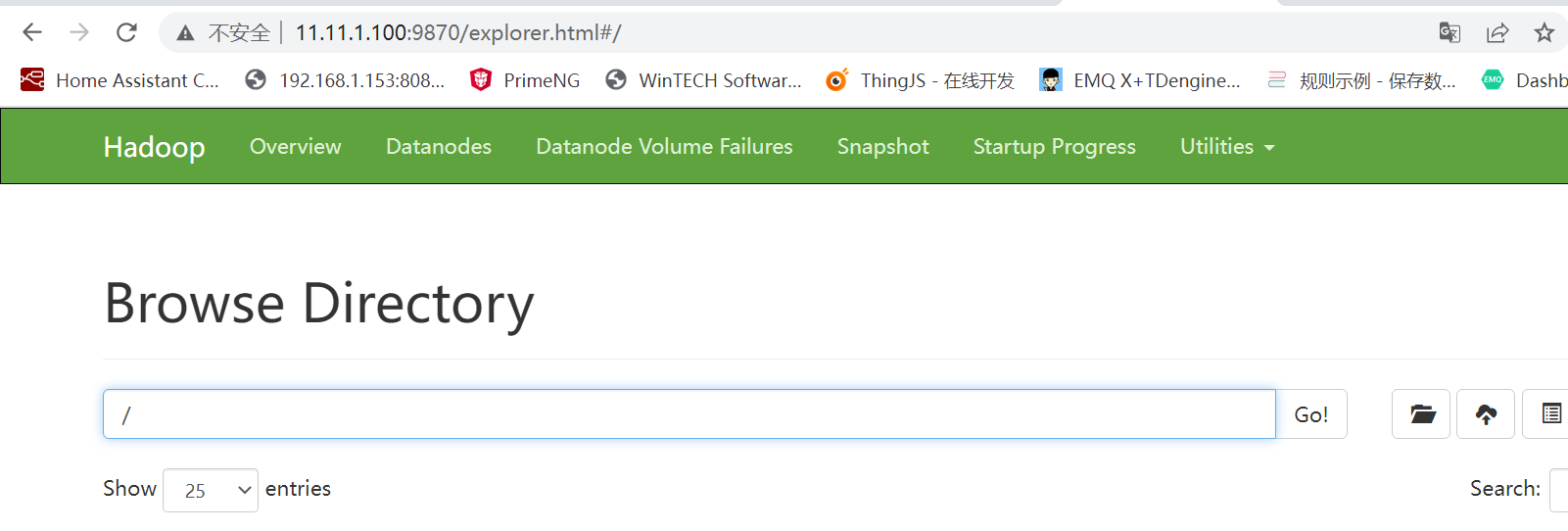
HFDS的网页是 flinka:9870
YARN的网页是flinka:8088
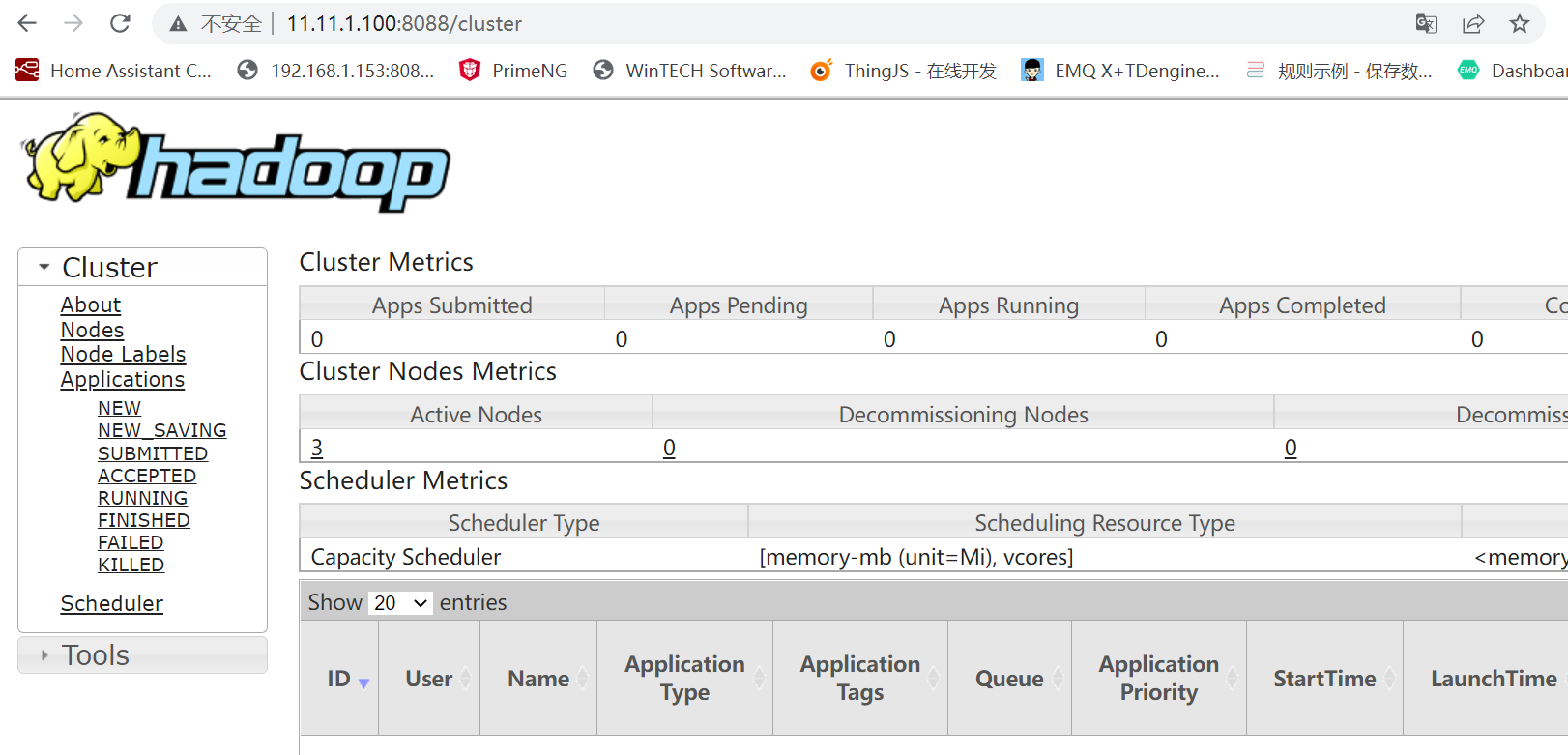
到这里hadoop集群的搭建就结束了!!!!
让我们开始体验大数据的快乐把!
















 650
650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











