






在SCI论文中,常常会见到model1,model2,model3.....这样的表述,每个model调整的混杂自变量会有所不同,具体研究者是如何筛选的呢?有什么需要注意的地方的吗?
这里通过几份示例简单和大家介绍一下多模型策略分析中,混杂自变量的选取方式:
示例1:
-
只有2个模型,Unadjusted模型就是焦点暴露与结局的单因素回归
-
Adjusted模型是调整其他全部混杂自变量的多因素回归。
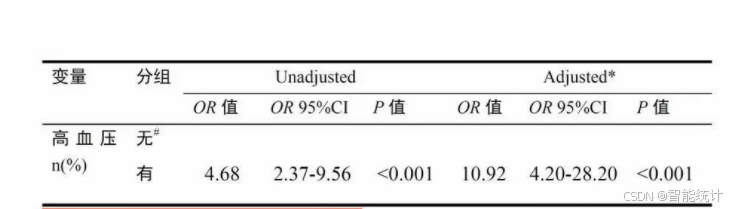
示例2:
-
有3个模型,Crude model是焦点暴露与结局的单因素回归
-
Model1校正了性别与年龄
-
Model3除年龄性别外还校正了种族,教育,吸烟,饮酒等其他混杂自变量。
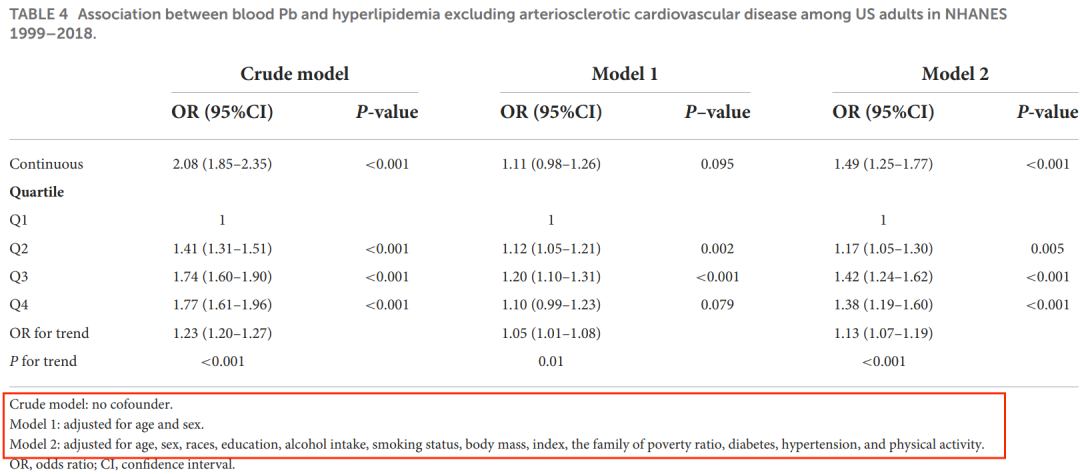
示例3:
-
有4个模型,Model1是焦点暴露与结局的单因素回归,
-
Model2校正了性别、年龄、种族、婚姻状况、教育、收入
-
Model3在Model2基础上额外校正了吸烟、饮酒、BMI、糖尿病、高血压
-
Model4在Model3基础上额外校正了尿肌酐、总胆固醇、血清可替宁。
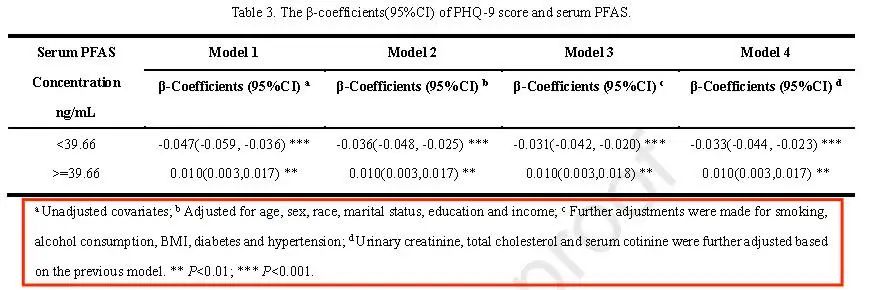
看完上面3个典型示例,不知道大家有没有发现一些规律:
-
第一个Model都是焦点暴露和结局的单因素回归结果(它可以叫Unadjusted、Crude model、Model1......);
-
每个Model都是在前一个模型基础上额外校正混杂变量,是包含关系;
-
最后一个Model需要校正全部的混杂变量;
-
中间Model混杂变量的选择不那么严格,一般来说第二个Model会校正人口学变量,或者根据混杂变量的不同类型,分开校正。像示例3,协变量较多的情况就分开校正了人口学变量、不良习惯与慢病、化验指标几类。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









