







源码地址:https://github.com/zhdh/Baidu_Poems
使用技术:Java、WebMagic
使用工具:脑子、眼睛、手、笔记本、鼠标、IDEA、Chrome
一:准备
本项目环境需要用到 Java 和 Maven以及IDE工具。
二:基础工程搭建
使用 IDEA/Eclipse 创建普通Mavent工程,引入WebMagic 提供的jar包
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>三:爬虫配置
新建一个类,实现 WebMagic 包中的 PageProcessor 接口,并对爬虫进行简单配置。
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* 百度诗词-唐诗数据抓取
* @author https://github.com/zhdh/Baidu_Poems
*/
public class BaiDuPoemPageProcessor implements PageProcessor {
private Site site = Site.me().setTimeOut(20000).setRetryTimes(3).setSleepTime(3000).setRetrySleepTime(3000);
@Override
public void process(Page page) {}
@Override
public Site getSite() { return site; }
}下一步,找到需要抓取数据的“百度汉语”唐诗类页面。

在页面中按F12 打开 开发者工具,切换到“Network”一栏,找到传输数据的接口

这里可以看到在选中接口的 Response 一栏中显示了网页中我们需要抓取的数据,但是URL 中并不包含页码参数,也就是说,这个接口所提供的数据只是首页的数据。
下面尝试切换到下一页,再观察是否有新的URL
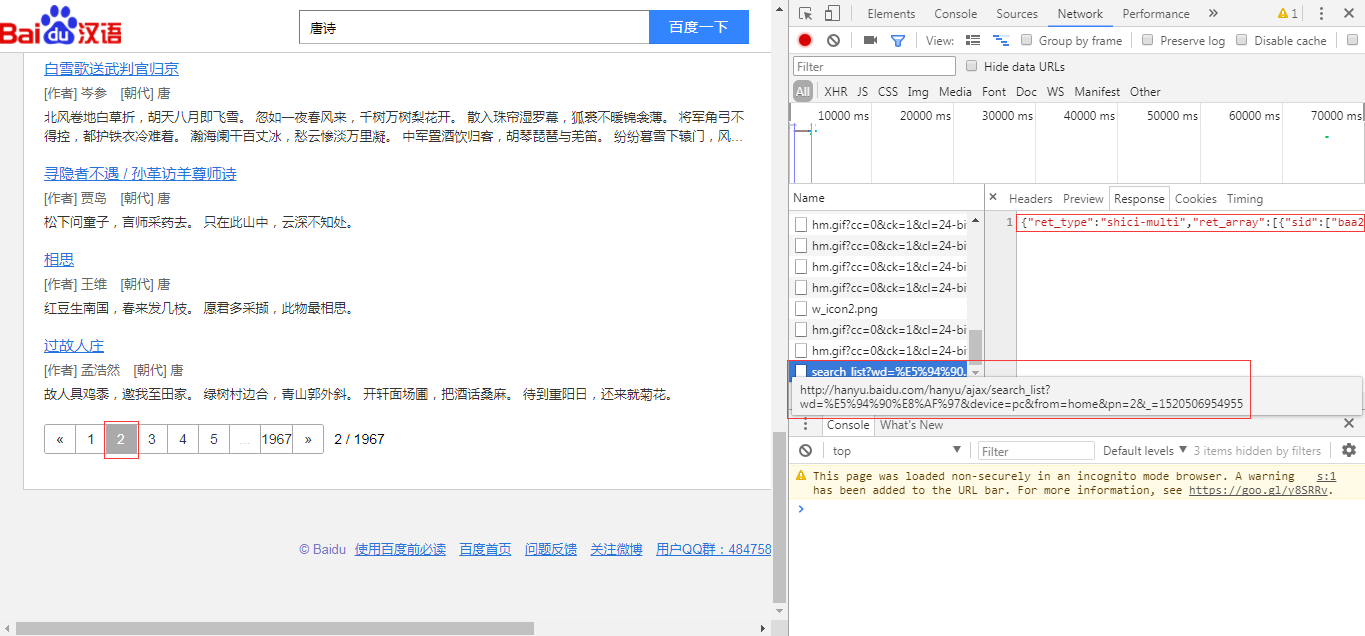
可以看到页面并未刷新,通过Ajax 加载了新的数据,请求的URL也发生了改变
http://hanyu.baidu.com/hanyu/ajax/search_list?wd=%E5%94%90%E8%AF%97&device=pc&from=home&pn=2&_=1520506954955对比两个URL不难发现,下面这个多了“pn”,“_”两个参数。pn(page number)后面带的是页码,“_”后面带的是时间戳。
将这个链接拷贝下来,配置在爬虫中:
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* 百度诗词-唐诗抓取
* @author https://github.com/zhdh
*/
public class BaiDuPoemPageProcessor implements PageProcessor {
private Site site = Site.me().setTimeOut(20000).setRetryTimes(3).setSleepTime(3000).setRetrySleepTime(3000);
@Override
public void process(Page page) {
System.out.println(page.getUrl());
System.out.println(page.getHtml());
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) throws Exception{
String url = "http://hanyu.baidu.com/hanyu/ajax/search_list?wd=%E5%94%90%E8%AF%97&device=pc&from=home&pn=2&_=1520506954955";
Spider.create(new BaiDuPoemPageProcessor()).addUrl(url).thread(1).run();
}
}启动程序验证是否能得到正确数据:

从控制台的输出看到,需要的数据并未成功获取到。
下面尝试将之前拷贝的链接放到浏览器中查看是否可以加载:

浏览器加载的信息并不是控制台输出的内容,说明百度对请求加了验证操作,下面分析为什么浏览器能访问,代码不能访问?不如将这个问题转化一下,浏览器访问和代码请求有什么异同?不难得出,浏览器请求中是有Headers和Cookies的。
Headers:

Cookies:
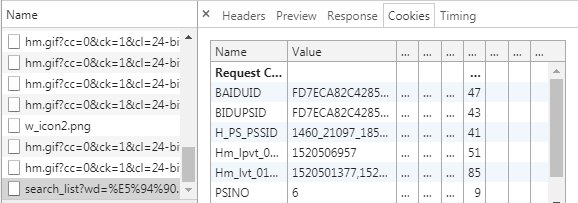
下面将Cookies和 Headers 的参数和值配置在爬虫中(不建议直接拷贝):
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* 百度诗词-唐诗抓取
* @author https://github.com/zhdh
*/
public class BaiDuPoemPageProcessor implements PageProcessor {
private Site site = Site.me().setTimeOut(20000).setRetryTimes(3).setSleepTime(3000).setRetrySleepTime(3000)
.addCookie("BAIDUID","FD7ECA82C4285D7D0770BE809D997647")
.addCookie("BIDUPSID","FD7ECA82C4285D7D0770BE809D997647")
.addCookie("H_PS_PSSID","1460_21097_18560_17001_22074")
.addCookie("Hm_lpvt_010e9ef9290225e88b64ebf20166c8c4","1520506957")
.addCookie("Hm_lvt_010e9ef9290225e88b64ebf20166c8c4","1520501377,1520501381,1520501555,1520501560")
.addCookie("PSINO","6").addCookie("PSTM","1520501166")
.addHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
.addHeader("Accept","application/json, text/javascript, */*; q=0.01")
.addHeader("Accept-Encoding","gzip, deflate")
.addHeader("Accept-Language","zh-CN,zh;q=0.9").addHeader("Connection","keep-alive").addHeader("Referer","http://hanyu.baidu.com");
@Override
public void process(Page page) {
System.out.println(page.getUrl());
System.out.println(page.getHtml());
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) throws Exception{
String url = "http://hanyu.baidu.com/hanyu/ajax/search_list?wd=%E5%94%90%E8%AF%97&device=pc&from=home&pn=2&_=1520506954955";
Spider.create(new BaiDuPoemPageProcessor()).addUrl(url).thread(1).run();
}
}再次尝试启动爬虫查看是否可能正确获取数据:
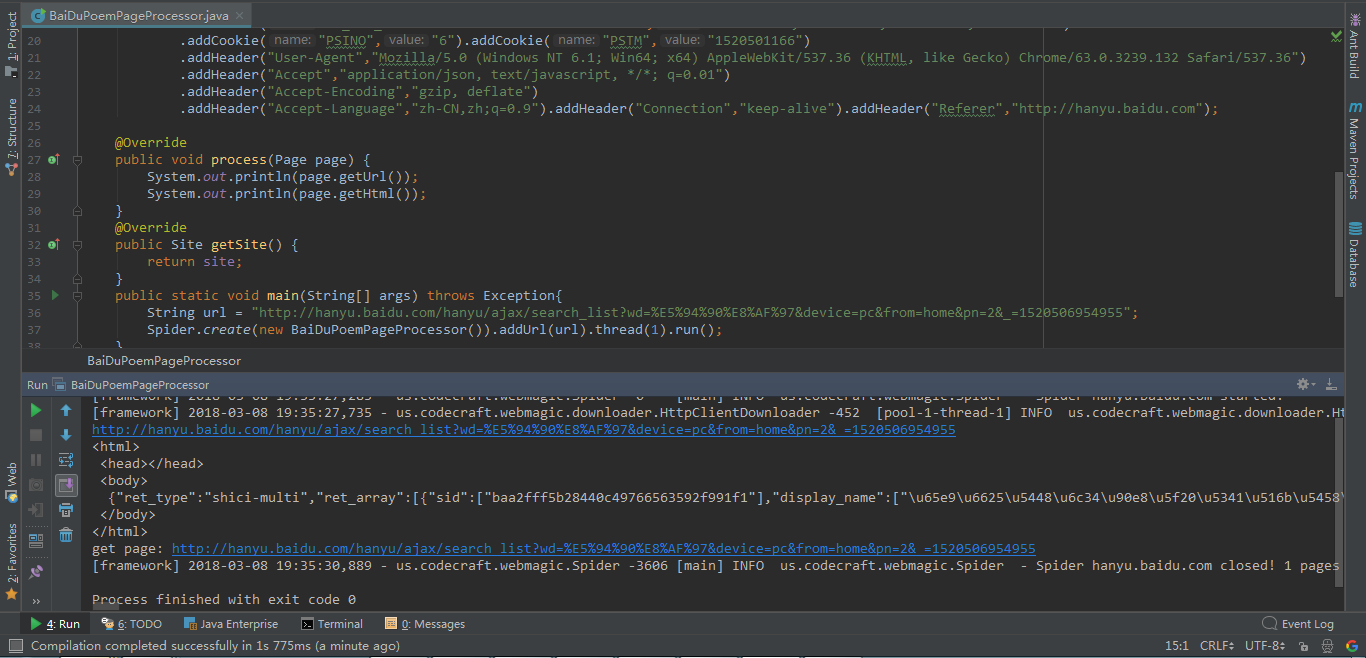
从控制台的输出可以看到,已经成功获取到数据。下一步将关键数据提取出来。
考虑到部分同学对正则表达式不太熟悉,这里使用XPath语法匹配元素。
从输出的数据可以看到我们需要的数据是在<html>标签中的<body>里面,Xpath表达式可以这样写:
//html/body/text()运行结果:

从输出的信息可以看到,数据是JSON格式的。所以需要用到JSON的包,接着我们从Maven导入FastJSON的Jar包
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.30</version>
</dependency>然后将数据格式化一下再输出
String body = page.getHtml().xpath("//html/body/text()").toString();
JSONObject jsonObject = JSON.parseObject(body);
String content = jsonObject.get("ret_array").toString();
System.out.println(content);
下面将JSON串的字段抽取为对象
package com.data.entity;
/**
* 诗词结构
*
* @author https://github.com/zhdh/Baidu_Poems
*/
public class Poem {
/**
* 朝代
*/
private String dynasty;
/**
* 作者
*/
private String literatureAuthor;
/**
* 名称
*/
private String displayName;
/**
* 内容
*/
private String body;
public String getDynasty() {
return dynasty;
}
public void setDynasty(String dynasty) {
this.dynasty = dynasty;
}
public String getLiteratureAuthor() {
return literatureAuthor;
}
public void setLiteratureAuthor(String literatureAuthor) {
this.literatureAuthor = literatureAuthor;
}
public String getDisplayName() {
return displayName;
}
public void setDisplayName(String displayName) {
this.displayName = displayName;
}
public String getBody() {
return body;
}
public void setBody(String body) {
this.body = body;
}
@Override
public String toString() {
return "Poem{" +
"dynasty='" + dynasty + '\'' +
", literatureAuthor='" + literatureAuthor + '\'' +
", displayName='" + displayName + '\'' +
", body='" + body + '\'' +
'}';
}
}然后将Json 串转换为对象集合,并输出查看结果
@Override
public void process(Page page) {
System.out.println(page.getUrl());
String body = page.getHtml().xpath("//html/body/text()").toString();
JSONObject jsonObject = JSON.parseObject(body);
String content = jsonObject.get("ret_array").toString();
List<Poem> poemList = JSON.parseArray(content,Poem.class);
for (Poem p : poemList) {
System.out.println(p);
}
}
可以看到,已经实现了单页面的信息采集,下一步需要实现多个页面的数据采集。

从页面信息里可以看到总共有 1967 页,那么可以将页面作为变量,递增爬取每个页面的数据
对代码改进之后:
mport com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.data.entity.Poem;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.List;
/**
* 百度诗词-唐诗类信息爬取
* @author https://github.com/zhdh/Baidu_Poems
*/
public class BaiDuPoemPageProcessor implements PageProcessor {
/** 初始增量 */
private static int i = 1;
/** 最大页码 */
private static final int MAX_PN = 1967;
private Site site = Site.me().setTimeOut(20000).setRetryTimes(3).setSleepTime(3000).setRetrySleepTime(3000)
.addCookie("BAIDUID", "FD7ECA82C4285D7D0770BE809D997647")
.addCookie("BIDUPSID", "FD7ECA82C4285D7D0770BE809D997647")
.addCookie("H_PS_PSSID", "1460_21097_18560_17001_22074")
.addCookie("Hm_lpvt_010e9ef9290225e88b64ebf20166c8c4", "1520506957")
.addCookie("Hm_lvt_010e9ef9290225e88b64ebf20166c8c4", "1520501377,1520501381,1520501555,1520501560")
.addCookie("PSINO", "6").addCookie("PSTM", "1520501166")
.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
.addHeader("Accept", "application/json, text/javascript, */*; q=0.01")
.addHeader("Accept-Encoding", "gzip, deflate")
.addHeader("Accept-Language", "zh-CN,zh;q=0.9").addHeader("Connection", "keep-alive").addHeader("Referer", "http://hanyu.baidu.com");
@Override
public void process(Page page) {
String body = page.getHtml().xpath("//html/body/text()").toString();
JSONObject jsonObject = JSON.parseObject(body);
String content = jsonObject.get("ret_array").toString();
List<Poem> poemList = JSON.parseArray(content, Poem.class);
for (Poem p : poemList) {
System.out.println(p);
}
if (i < MAX_PN) {
i++;
String url = "http://hanyu.baidu.com/hanyu/ajax/search_list?wd=%E5%94%90%E8%AF%97&device=pc&from=home&pn=" + i + "&_=" + System.currentTimeMillis();
// 将URL添加到请求列表
page.addTargetRequest(url);
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) throws Exception {
String url = "http://hanyu.baidu.com/hanyu/ajax/search_list?wd=%E5%94%90%E8%AF%97&device=pc&from=home&pn=1&_=1520506954955";
Spider.create(new BaiDuPoemPageProcessor()).addUrl(url).thread(1).run();
}
}效果:
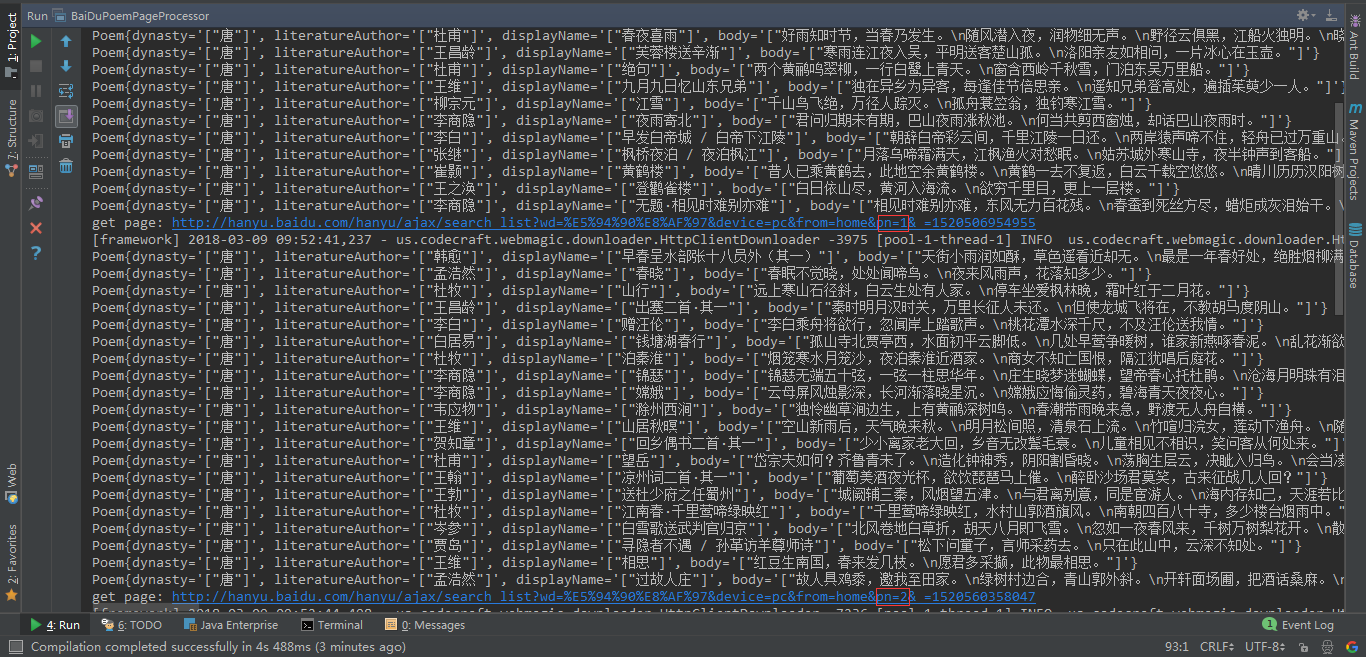
从控制台输出的信息可以看到,已经实现了多页面信息抓取了。接着要做的就是将数据保存到数据库中。
导入Mysql、Mybatis的Jar包
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.18</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.1.1</version>
</dependency>创建相应数据库 :
CREATE DATABASE `baiduhanyu`;
USE `baiduhanyu`;
CREATE TABLE `t_poem`(
`id` INT AUTO_INCREMENT PRIMARY KEY,
`type` VARCHAR(10) COMMENT '类型',
`dynasty` VARCHAR(10) COMMENT '朝代',
`literatureAuthor` VARCHAR(20) COMMENT '作者',
`displayName` VARCHAR(40) COMMENT '名称',
`body` TEXT COMMENT '内容',
`time` TIMESTAMP DEFAULT NOW() COMMENT '更新时间'
)编写数据操作接口:
import com.data.entity.Poem;
/**
* 诗词数据操作接口
* @author https://github.com/zhdh
*/
public interface PoemDao {
/**
* 插入诗词数据
* @param poem 诗词对象
* @return 受影响行数
*/
Integer insertPoem(Poem poem);
}编写数据操作接口对应Mapper
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.data.dao.PoemDao">
<select id="insertPoem" parameterType="com.data.entity.Poem">
INSERT INTO t_poem (`type`, `dynasty`, `literatureAuthor`, `displayName`, `body`, `time`)
VALUES (#{type}, #{dynasty}, #{literatureAuthor}, #{displayName}, #{body}, DEFAULT);
</select>
</mapper>配置Mybatis :
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/baiduhanyu/?characterEncoding=utf-8"/>
<property name="username" value="root"/>
<property name="password" value=""/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/data/mapper/PoemMapper.xml"/>
</mappers>
</configuration>为方便Mybatis的调用,先编写一个Mybatis工具类
package com.data.utils;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.Reader;
/**
* MybatisUtil
*
* @author https://github.com/zhdh
*/
public class MybatisUtil {
private static ThreadLocal<SqlSession> threadLocal = new ThreadLocal<SqlSession>();
private static SqlSessionFactory sqlSessionFactory;
/**
* 加载mybatis.xml配置文件
*/
static {
try {
Reader reader = Resources.getResourceAsReader("mybatis-config.xml");
sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
private MybatisUtil() {
}
/**
* 获取SqlSession
*/
public static SqlSession getSqlSession() {
SqlSession sqlSession = threadLocal.get();
if (sqlSession == null) {
sqlSession = sqlSessionFactory.openSession();
threadLocal.set(sqlSession);
}
return sqlSession;
}
/**
* 关闭SqlSession
*/
public static void closeSqlSession() {
SqlSession sqlSession = threadLocal.get();
if (sqlSession != null) {
sqlSession.close();
threadLocal.remove();
}
}
}改造爬虫,使其能将数据更新到数据库
package com.data.collection;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.data.dao.PoemDao;
import com.data.entity.Poem;
import com.data.utils.MybatisUtil;
import org.apache.ibatis.session.SqlSession;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.lang.reflect.Field;
import java.util.List;
import java.util.Random;
/**
* 百度诗词-唐诗类信息爬取
*
* @author https://github.com/zhdh/Baidu_Poems
*/
public class BaiDuPoemPageProcessor implements PageProcessor {
/**
* 初始增量
*/
private volatile static int i = 1;
/**
* 最大页码
*/
private static final int MAX_PN = 1967;
private SqlSession sqlSession = MybatisUtil.getSqlSession();
private PoemDao poemDao = sqlSession.getMapper(PoemDao.class);
private Random random = new Random();
private Site site = Site.me().setTimeOut(20000).setRetryTimes(3).setSleepTime(3000).setRetrySleepTime(3000)
.addCookie("BAIDUID", "FD7ECA82C4285D7D0770BE809D997647")
.addCookie("BIDUPSID", "FD7ECA82C4285D7D0770BE809D997647")
.addCookie("H_PS_PSSID", "1460_21097_18560_17001_22074")
.addCookie("Hm_lpvt_010e9ef9290225e88b64ebf20166c8c4", "1520506957")
.addCookie("Hm_lvt_010e9ef9290225e88b64ebf20166c8c4", "1520501377,1520501381,1520501555,1520501560")
.addCookie("PSINO", "6").addCookie("PSTM", "1520501166")
.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
.addHeader("Accept", "application/json, text/javascript, */*; q=0.01")
.addHeader("Accept-Encoding", "gzip, deflate")
.addHeader("Accept-Language", "zh-CN,zh;q=0.9").addHeader("Connection", "keep-alive").addHeader("Referer", "http://hanyu.baidu.com");
@Override
public void process(Page page) {
String body = page.getHtml().xpath("//html/body/text()").toString();
JSONObject jsonObject = JSON.parseObject(body);
String content = jsonObject.get("ret_array").toString();
List<Poem> poemList = JSON.parseArray(content, Poem.class);
for (Poem p : poemList) {
Poem formatPoem = null;
try {
formatPoem = (Poem) format(p);
} catch (ClassNotFoundException | IllegalAccessException | InstantiationException | NoSuchFieldException e) {
e.printStackTrace();
}
assert formatPoem != null;
System.out.print(formatPoem.getLiteratureAuthor() + " - " + formatPoem.getDisplayName());
poemDao.insertPoem(formatPoem);
try {
sqlSession.commit();
System.out.println(" : 插入成功");
} catch (Exception e) {
sqlSession.rollback();
System.out.println(" : 插入失败");
}
}
if (i < MAX_PN) {
i++;
String url = "http://hanyu.baidu.com/hanyu/ajax/search_list?wd=%E5%94%90%E8%AF%97&device=pc&from=home&pn=" + i + "&_=" + System.currentTimeMillis();
// 将URL添加到请求列表
page.addTargetRequest(url);
// 间隔时间
int setSleepTime = random.nextInt(10000) % (10000 - 500 + 1) + 500;
try {
Thread.sleep(setSleepTime);
System.out.println(setSleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@Override
public Site getSite() {
return site;
}
/**
* 过滤对象字段中的 <tt>["</tt> 和 <tt>"]</tt> 字符
*
* @param object object
* @return newObj
*/
private static Object format(Object object) throws ClassNotFoundException, IllegalAccessException, InstantiationException, NoSuchFieldException {
Field[] f = object.getClass().getDeclaredFields();
Class clazz = Class.forName(object.getClass().getName());
Object newObj = clazz.newInstance();
for (Field ft : f) {
ft.setAccessible(true);
Field field = clazz.getDeclaredField(ft.getName());
field.setAccessible(true);
field.set(newObj, ft.get(object).toString().substring(2, ft.get(object).toString().length() - 2));
}
return newObj;
}
public static void main(String[] args) throws Exception {
String url = "http://hanyu.baidu.com/hanyu/ajax/search_list?wd=%E5%94%90%E8%AF%97&device=pc&from=home&pn=1&_=1520506954955";
Spider.create(new BaiDuPoemPageProcessor()).addUrl(url).thread(1).run();
}
}
至此整个爬虫就完成了。
源码地址:https://github.com/zhdh/Baidu_Poems














 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









