







视觉SLAM理论到实践系列文章
下面是《视觉SLAM十四讲》学习笔记的系列记录的总链接,本人发表这个系列的文章链接均收录于此
视觉SLAM理论到实践系列文章链接
下面是专栏地址:
视觉SLAM理论到实践专栏
文章目录
前言
高翔博士的《视觉SLAM14讲》学习笔记的系列记录
视觉SLAM理论到实践系列(六)——特征点法视觉里程计(6)
SLAM中的测量方式
参考:
补充:SVD求解 A x = 0 Ax=0 Ax=0
将 A x = 0 Ax=0 Ax=0 中的 A A A 矩阵奇异值分解后,得到 U D V T x = 0 UDV^Tx=0 UDVTx=0 ,求解这个方程,也就是求解 ∥ U D V T x ∥ \|UDV^Tx\| ∥UDVTx∥ 的最小值,因为让其完全等于0是很难的
由于 ∥ R x ∥ = ∥ x ∥ \|Rx\|=\|x\| ∥Rx∥=∥x∥ ,所以即求解 ∥ D V T x ∥ \|DV^Tx\| ∥DVTx∥ 的最小值。令 V T x = y V^Tx=y VTx=y,则 ∥ D y ∥ min \|Dy\|_{\min} ∥Dy∥min 为 D D D 最小的那个奇异值,因为 ∥ D y ∥ = ∑ i = 0 3 σ i y i \|Dy\|=\sum_{i=0}^{3}\sigma_iy_i ∥Dy∥=∑i=03σiyi ,最小值即为 σ 3 \sigma_3 σ3,则 V T x = y = ( 0 0 0 1 ) V^Tx=y=\left(\begin{matrix}0\\0\\0\\1\end{matrix}\right) VTx=y= 0001
由于 V 4 × 4 T = [ a 0 , a 1 , a 2 , a 3 ] T V^T_{4\times4}=[a_0,a_1,a_2,a_3]^T V4×4T=[a0,a1,a2,a3]T,则显然 x = a 3 x=a_3 x=a3 时,有 V T x = ( 0 0 0 1 ) V^Tx=\left(\begin{matrix}0\\0\\0\\1\end{matrix}\right) VTx= 0001
即将 A A A 进行SVD分解后,得到的 V V V 矩阵的最后一列 a 3 a_3 a3 作为方程组的解,这样的方法在后面也用到了
VINS中此处的代码如下所示,在vins_estimator/src/initial/initial_ex_rotation.cpp的函数 CalibrationExRotation() 中
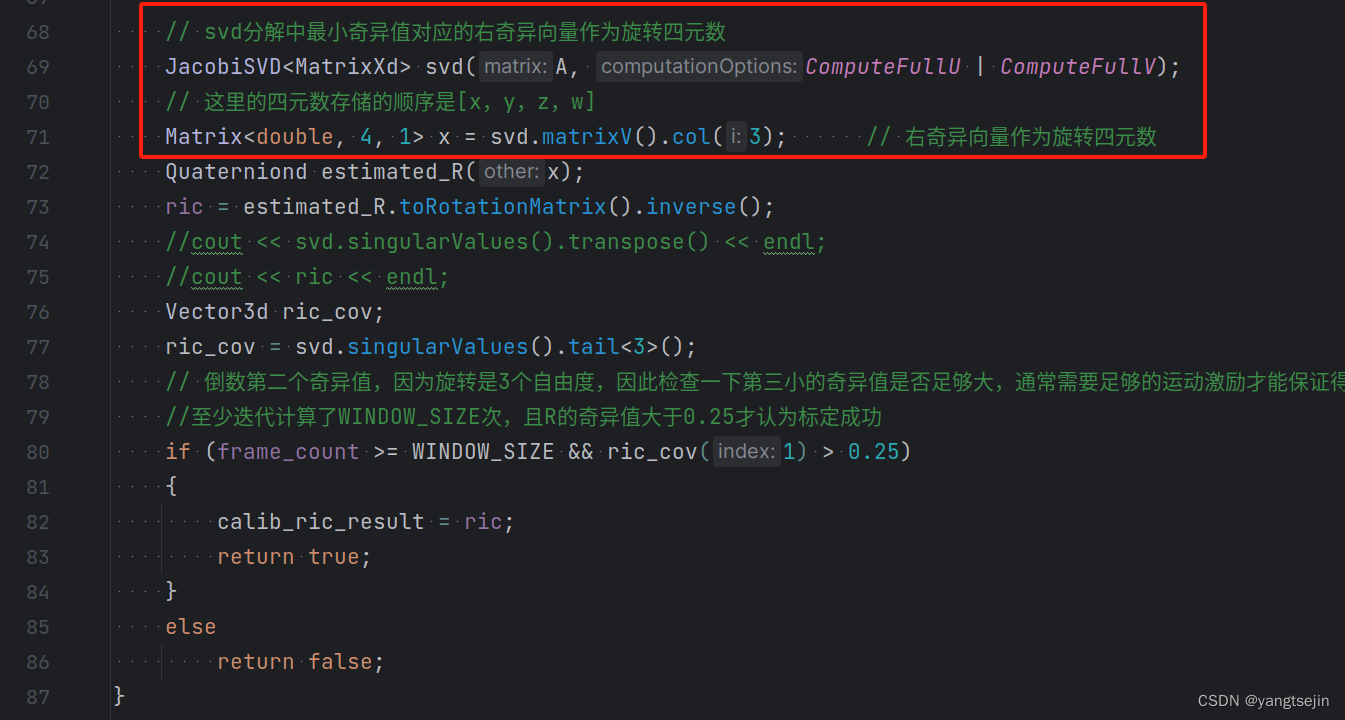
详细证明:
U为正交矩阵,不会改变矩阵x的大小,所以可以约掉
x为单位四元数,因为只有单位四元数才能表示旋转

上图来自 VINS-MONO:VIO初始化部分 原理推导+代码解析
对极几何
对极几何(Epipolar geometry)又叫对极约束,是根据图像二维平面信息来估计单目相机帧间运动或双目相机相对位姿关系的一种算法。直观来讲,当相机在两个不同视角对同一物体进行拍摄时,物体在两幅图像中的成像肯定会有不同,那么,根据这两幅不同的图像,我们如何判断出相机的位姿发生了怎样的变化,这正是对极几何要解决的问题。
需要明确的是,在对极几何中,我们的已知条件仅仅是每幅图像中特征点的像素坐标,当然,计算对极约束的前提是我们必须知道两幅图像中特征点之间准确的匹配关系。
对极几何根据特征点的像素坐标(或者归一化坐标,两者相差一个内参矩阵K)估计本征矩阵 E E E,从而恢复出 R R R 和 t t t

如上图所示,以其中一对匹配点为例。
P
P
P 为空间中的一点(坐标未知),其在左边图像中的投影为
p
l
=
[
u
l
,
v
l
,
1
]
T
\color{#F00}p_l=[u_l,v_l,1]^\text T
pl=[ul,vl,1]T
,在右边图像中的投影为
p
r
=
[
u
r
,
v
r
,
1
]
T
\color{#F00}p_r=[u_r,v_r,1]^\text T
pr=[ur,vr,1]T,当我们以相机坐标系
O
L
O_L
OL 为参考坐标系时,有:
{
s
l
p
l
=
K
P
s
r
p
r
=
K
(
R
P
+
t
)
⟹
{
s
l
K
−
1
p
l
=
P
s
r
K
−
1
p
r
=
R
P
+
t
(1)
\begin{cases}s_lp_l=KP\\s_rp_r=K(RP+t)\end{cases}\implies\begin{cases}s_lK^{-1}p_l=P\\s_rK^{-1}p_r=RP+t\end{cases} \tag{1}
{slpl=KPsrpr=K(RP+t)⟹{slK−1pl=PsrK−1pr=RP+t(1)
其中
s
l
s_l
sl 、
s
r
s_r
sr 分别为点P PP在相机坐标系
O
L
O_L
OL 、
O
R
O_R
OR 中的 $ z$ 坐标值(即深度),
K
K
K 为
3
×
3
3\times 3
3×3 的相机内参矩阵,
R
R
R、
t
t
t 即为
O
L
O_L
OL 与
O
R
O_R
OR 之间的相对位姿关系。取 $\color{#F0F}x_l=K{-1}p_l,,x_r=K{-1}p_r $,则有:
{
s
l
x
l
=
P
s
r
x
r
=
R
P
+
t
⟹
s
r
x
r
=
R
(
s
l
x
l
)
+
t
⟹
s
r
x
r
=
s
l
R
x
l
+
t
(2)
\begin{cases}s_lx_l=P\\s_rx_r=RP+t\end{cases}\implies s_rx_r=R(s_lx_l)+t\implies s_rx_r=s_lRx_l+t \tag{2}
{slxl=Psrxr=RP+t⟹srxr=R(slxl)+t⟹srxr=slRxl+t(2)
上式两边同时左乘
t
t
t 的反对称矩阵
t
∧
t^\wedge
t∧ ,相当于两侧同时与
t
t
t 做外积(
t
t
t 与自身的外积 $ t^\wedge t=\bf 0$):
s
r
t
∧
x
r
=
s
l
t
∧
R
x
l
(3)
s_{r}t^{\wedge}x_{r}=s_{l}t^{\wedge}Rx_{l} \tag{3}
srt∧xr=slt∧Rxl(3)
然后,两侧同时左乘
x
r
T
x_r^{\text T}
xrT:
s
r
x
r
T
t
∧
x
r
=
s
l
x
r
T
t
∧
R
x
l
(4)
s_{r}x_{r}^{\mathrm{T}}t^{\wedge}x_{r}=s_{l}x_{r}^{\mathrm{T}}t^{\wedge}Rx_{l} \tag{4}
srxrTt∧xr=slxrTt∧Rxl(4)
上式左侧中,
t
t
t 与
x
r
x_r
xr 的外积
t
∧
x
r
t^\wedge x_r
t∧xr 是一个与
t
t
t 和
x
r
x_r
xr 都垂直的向量,所以,再将
x
r
T
x_r^{\text T}
xrT 与
t
∧
x
r
t^\wedge x_r
t∧xr 做内积,其结果必为
0
0
0,从而有:
s
l
x
r
T
t
∧
R
x
l
=
0
⟹
s
l
(
K
−
1
p
r
)
T
t
∧
R
(
K
−
1
p
l
)
=
0
⟹
p
r
T
K
T
t
∧
R
K
−
1
p
l
=
0
(5)
\color{red}{s_lx_r^Tt^\wedge Rx_l=0}\implies\color{red}{s_l(K^{-1}p_r)^Tt^\wedge R(K^{-1}p_l)=0}\implies\color{red}{p_r^TK^Tt^\wedge RK^{-1}p_l=0} \tag{5}
slxrTt∧Rxl=0⟹sl(K−1pr)Tt∧R(K−1pl)=0⟹prTKTt∧RK−1pl=0(5)
上式以非常简洁的形式描述了两幅图像中匹配点对
p
l
p_l
pl 和
p
r
p_r
pr 之间存在的数学关系,这种关系就叫对极约束。另外,我们称
E
=
t
∧
R
\color{#F00}E=t^\wedge R
E=t∧R 为本质矩阵(Essential Matrix),称
F
=
K
-T
t
∧
R
K
−
1
=
K
-T
E
K
−
1
\color{#F00}F=K^{\text {-T}}t^\wedge RK^{-1}=K^{\text {-T}}EK^{-1}
F=K-Tt∧RK−1=K-TEK−1 为基础矩阵(Fundamental Matrix),于是(5)式可以进一步简化为:
x
r
T
E
x
l
=
p
r
T
F
p
l
=
0
(6)
x_r^\mathrm{T}Ex_l=p_r^\mathrm{T}Fp_l=0 \tag{6}
xrTExl=prTFpl=0(6)
用像素坐标计算出的是
E
E
E,用归一化坐标计算出的是
F
F
F,注意,这里解得的
R
R
R 和
t
t
t 是从
x
l
x_l
xl 到
x
r
x_r
xr 的变换
对极几何是要利用已知的 n n n 对如上述 p l p_l pl、 p r p_r pr 这样的匹配点(二维像素坐标),来计算相机的运动 R R R、 t t t,即求解本质矩阵 E E E 或基础矩阵 F F F
对极几何存在的问题:根据对极约束求解得到的相机旋转运动 R R R 是准确的,平移运动 t t t 是不具备真实尺度的。
计算方法
三角测量
参考:
三角测量(Triangulation)又叫三角化,是根据前后两帧图像中匹配到的特征点像素坐标以及两帧之间的相机运动 R R R、 t t t,计算特征点三维空间坐标的一种算法。
直观来讲,当有两个相对位置已知的相机同时拍摄到同一物体时,如何根据两幅图像中的信息估计出物体的实际位姿,即通过三角化获得二维图像上对应点的三维结构,这正是三角测量要解决的问题。
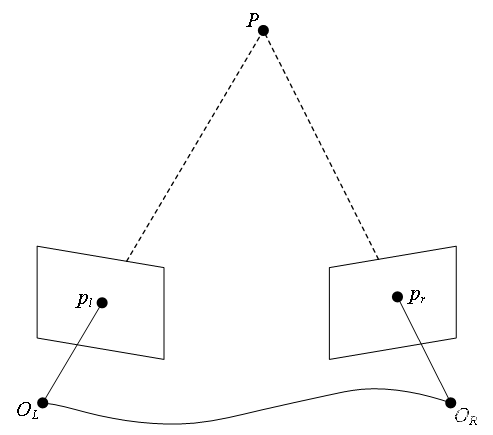
如图所示为三角测量基本原理的示意图,该图与对极几何的图非常相似,但应该注意其中的区别:此时我们已经知道了 O L O_L OL 与 O R O_R OR 的关系, p l p_l pl、 p r p_r pr 也是已知的,要求的是点 P P P 的三维空间坐标。
由(1)式我们知道,要求点 P P P 的三维坐标,需要先求深度 s s s;
由(2)式我们有:
s
r
x
r
=
s
l
R
x
l
+
t
(7)
s_rx_r=s_lRx_l+t \tag{7}
srxr=slRxl+t(7)
对上式两侧左乘一个
x
r
x_r
xr 的反对称矩阵
x
r
∧
x_r^\wedge
xr∧ ,得:
s
r
x
r
∧
x
r
=
s
l
x
r
∧
R
x
l
+
x
r
∧
t
⟹
s
l
x
r
∧
R
x
l
+
x
r
∧
t
=
0
(8)
s_rx_r^{\wedge}x_r=s_lx_r^{\wedge}Rx_l+x_r^{\wedge}t\implies s_lx_r^{\wedge}Rx_l+x_r^{\wedge}t=\mathbf{0} \tag{8}
srxr∧xr=slxr∧Rxl+xr∧t⟹slxr∧Rxl+xr∧t=0(8)
(8)式是一个超定方程组(Overdetermined system),通常只能求得它的最小二乘解。
关于超定方程组见:
当我们求出
s
l
s_l
sl 后,根据(7)式就很容易求出
s
r
s_r
sr ,最后由(1)式,我们有:
{
s
l
K
−
1
p
l
=
P
O
L
,
P
O
L
表示点
P
在相机坐标系
O
L
下的三维坐标
s
r
K
−
1
p
r
=
P
O
R
,
P
O
R
表示点
P
在相机坐标系
O
R
下的三维坐标
(9)
\begin{cases}s_lK^{-1}p_l=P_{O_L},\quad P _{O_L}表示点P在相机坐标系O_ L下的三维坐标 \\\\ s_rK^{-1}p_r=P_{O_R},\quad P _{O_R}表示点P在相机坐标系O_R下的三维坐标 \end{cases} \tag{9}
⎩
⎨
⎧slK−1pl=POL,POL表示点P在相机坐标系OL下的三维坐标srK−1pr=POR,POR表示点P在相机坐标系OR下的三维坐标(9)
上式中
P
O
L
P_{O_L}
POL 与
P
O
R
P_{O_R}
POR 之间的关系为:
P
O
R
=
R
P
O
L
+
t
P_{O_R}=RP_{O_L}+t
POR=RPOL+t
即:以
O
L
O_L
OL 坐标系为参考,
O
R
O_R
OR 经过运动
R
R
R、
t
t
t 变换到
O
L
O_L
OL,那么原来在
O
L
O_L
OL 坐标系下的点
P
P
P 在
O
R
O_R
OR 坐标系下表示为
P
O
R
=
R
P
O
L
+
t
P_{O_R}=RP_{O_L}+t
POR=RPOL+t。如果我们还知道相机与世界坐标系的变换关系
T
T
T,就可以将
P
O
L
P_{O_L}
POL 或
P
O
R
P_{O_R}
POR 转换到世界坐标系下表示,得到点
P
P
P 的世界坐标。
注意:
对于三角化来说,其是由平移得到的,有平移才会有对极几何中的三角形,才谈的上三角测量。这里需要注意的是,纯旋转是无法使用三角测量的,因为对极约束将永远满足。在平移存在的情况下,读者还需要关心三角测量的不确定性,这会引出一个三角测量的矛盾。
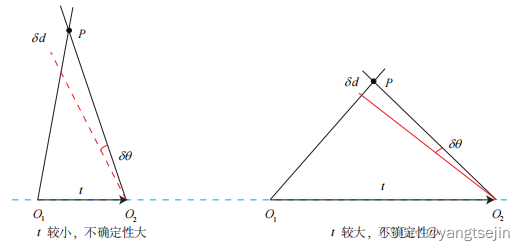
通过上面的图我们来定性分析一下,当物体平移很小时,像素的上不确定性将导致较大的深度不确定性。如上图,可以发现 θ \theta θ 变化相同时, δ d \delta_d δd变化也是相同的,但是很明显右面那个图 δ d \delta_d δd 的占比会更小,这样就说明当 t t t 较大时,深度不确定性就会减小。
通过上面的定性分析,我们自然会想到,增加平移量会减少深度的不确定性,但是这样做有弊端,即随着平移量的增大会导致图像的外观发生明显的变化,比如箱子原先被挡住的侧面显示出来了,比如反射光发生变化了,等等情况。
综上所述,增大平移:会减小深度的不确定性但是会导致匹配失败。减少平移:导致三角化精度不够,但是特征匹配会大概率成功。以上所说的便是三角化的矛盾。
计算方法
三角测量的前提是相机的内参 K K K 已知,且两帧之间的外参 R , t R,t R,t 也已知,并且这些矩阵都比较准确,或者相对干匹配点的像素误差来讲,相对准确。
那么就可以有下面的式子:
P
1
=
{
K
00
K
01
K
02
0
K
10
K
11
K
12
0
K
20
K
21
K
22
1
}
,
P
2
=
K
∗
{
R
00
R
01
R
02
t
0
R
10
R
11
R
12
t
1
R
20
R
21
R
22
t
2
}
P_1=\begin{Bmatrix}K_{00}&K_{01}&K_{02}&0\\K_{10}&K_{11}&K_{12}&0\\K_{20}&K_{21}&K_{22}&1\end{Bmatrix},P_2=K*\begin{Bmatrix}R_{00}&R_{01}&R_{02}&t_0\\R_{10}&R_{11}&R_{12}&t_1\\R_{20}&R_{21}&R_{22}&t_2\end{Bmatrix}
P1=⎩
⎨
⎧K00K10K20K01K11K21K02K12K22001⎭
⎬
⎫,P2=K∗⎩
⎨
⎧R00R10R20R01R11R21R02R12R22t0t1t2⎭
⎬
⎫
x
1
′
=
λ
1
P
1
X
^
,
x
2
′
=
λ
2
P
2
X
^
{x_1}^{\prime}=\lambda_1P_1\hat{X},{x_2}^{\prime}=\lambda_2P_2\hat{X}
x1′=λ1P1X^,x2′=λ2P2X^
其中 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 分别为深度的倒数,即 1 Z 1 \frac{1}{Z_1} Z11 和 1 Z 2 \frac{1}{Z_2} Z21
以
x
1
′
x_1'
x1′ 为例进行推导,首先,式
x
1
′
=
P
1
X
^
x_1^{\prime}=P_1\hat{X}
x1′=P1X^ 展开后其实是
Z
[
u
v
1
]
=
P
1
[
X
Y
Z
1
]
Z\begin{bmatrix}u\\v\\1\end{bmatrix}=P_1\begin{bmatrix}X\\Y\\Z\\1\end{bmatrix}
Z
uv1
=P1
XYZ1
Z
Z
Z 其实就代表了实际地图点深度;
先用叉乘消去尺度因子
Z
Z
Z, 即
x
1
′
×
x
1
′
=
0
→
x
1
′
×
P
1
X
^
=
0
→
[
u
v
1
]
×
[
p
1
T
X
^
p
2
T
X
^
p
3
T
X
^
]
{x_1}^{\prime}\times{x_1}^{\prime}=0\rightarrow{x_1}^{\prime}\times P_1\hat{X}=0\rightarrow\begin{bmatrix}u\\v\\1\end{bmatrix}\times\begin{bmatrix}p^{1T}\hat{X}\\p^{2T}\hat{X}\\p^{3T}\hat{X}\end{bmatrix}
x1′×x1′=0→x1′×P1X^=0→
uv1
×
p1TX^p2TX^p3TX^
向量叉乘公式如下:
a
⃗
×
b
⃗
=
(
a
2
b
3
−
b
2
a
3
,
a
3
b
1
−
a
1
b
3
,
a
1
b
2
−
a
2
b
1
)
\vec{a}\times\vec{b}=(a_2b_3-b_2a_3,a_3b_1-a_1b_3,a_1b_2-a_2b_1)
a×b=(a2b3−b2a3,a3b1−a1b3,a1b2−a2b1)
则对应可以得到式子:
v
∗
p
3
T
X
^
−
p
2
T
X
^
=
0
u
∗
p
3
T
X
^
−
p
1
T
X
^
=
0
u
∗
p
2
T
X
^
−
v
∗
p
2
T
X
^
=
0
\begin{aligned} v*p^{3T}\hat{X}-p^{2T}\hat{X}&=0 \\ u*p^{3T}\hat{X}-p^{1T}\hat{X}&=0 \\ u*p^{2T}\hat{X}-v*p^{2T}\hat{X}&=0 \end{aligned}
v∗p3TX^−p2TX^u∗p3TX^−p1TX^u∗p2TX^−v∗p2TX^=0=0=0
这三个方程其实是线性相关的,从其中可以总结出两个式子,再加上
X
^
\hat{X}
X^ 和
x
2
′
x_{2}^{\prime}
x2′ 的映射关系,可以得到下面四个式子:
u
1
∗
p
3
T
X
^
−
p
1
T
X
^
=
0
v
1
∗
p
3
T
X
^
−
p
2
T
X
^
=
0
u
2
∗
p
′
3
T
X
^
−
p
′
1
T
X
^
=
0
v
2
∗
p
′
3
T
X
^
−
p
′
2
T
X
^
=
0
\begin{gathered} u_1*p^{3T}\hat{X}-p^{1T}\hat{X}=0 \\ v_1*p^{3T}\hat{X}-p^{2T}\hat{X}=0 \\ u_2*p^{\prime{3T}}\hat{X}-p^{\prime{1T}}\hat{X}=0 \\ v_2*p^{\prime{3T}}\hat{X}-p^{\prime{2T}}\hat{X}=0 \end{gathered}
u1∗p3TX^−p1TX^=0v1∗p3TX^−p2TX^=0u2∗p′3TX^−p′1TX^=0v2∗p′3TX^−p′2TX^=0
这就可以转换成其次方程
A
∗
X
^
=
0
A*\hat{X}=0
A∗X^=0,其中
A
=
[
u
1
∗
p
3
T
−
p
1
T
v
1
∗
p
3
T
−
p
2
T
u
2
∗
p
′
3
T
−
p
′
1
T
v
2
∗
p
′
3
T
−
p
′
2
T
]
A=\begin{bmatrix}u_1*p^{3T}-p^{1T}\\v_1*p^{3T}-p^{2T}\\u_2*p^{\prime3T}-p^{\prime{1T}}\\v_2*p^{\prime{3T}}-p^{\prime{2T}}\end{bmatrix}
A=
u1∗p3T−p1Tv1∗p3T−p2Tu2∗p′3T−p′1Tv2∗p′3T−p′2T
转换成齐次方程之后,就可以利用齐次解的方法,也就是取
A
A
A 的最小奇异值对应的单位奇异向量作为解,
三角测量对应的代码
有了上面的理论推导后,就可以来看一下三角测量在SLAM中的应用,这里还是简单一点,以ORBSLAM2为例,假设初始化时相机对应的是近似平面的场景,这时使用H矩阵进行推到;
-
FindHomography() 函数利用两帧图像中的匹配点计算出两张图像对应的单应变换矩阵H;
-
ReconstructH() 函数从H矩阵中恢复出R,t,并对Rt进行验证和取舍
-
CheckRT3D() 利用匹配点对R,t进行验证,具体方法为保证像素点的恢复出的3D点的重投影误差在合理范围内
-
在CheckRT3D()中会先构建投影矩阵P1,P2,然后依次取出众多匹配点中的一对儿点进行三角化
在ORBSLAM2中三角化对应的代码为:
/**
* @brief 给定投影矩阵P1,P2和图像上的点kp1,kp2,从而恢复3D坐标
*
* @param kp1 特征点, in reference frame
* @param kp2 特征点, in current frame
* @param P1 投影矩阵P1
* @param P2 投影矩阵P2
* @param x3D 三维点
* @see Multiple View Geometry in Computer Vision - 12.2 Linear triangulation methods p312
*/
void Initializer::Triangulate(const cv::KeyPoint &kp1, const cv::KeyPoint &kp2, const cv::Mat &P1, const cv::Mat &P2, cv::Mat &x3D)
{
cv::Mat A(4,4,CV_32F);
A.row(0) = kp1.pt.x*P1.row(2)-P1.row(0);
A.row(1) = kp1.pt.y*P1.row(2)-P1.row(1);
A.row(2) = kp2.pt.x*P2.row(2)-P2.row(0);
A.row(3) = kp2.pt.y*P2.row(2)-P2.row(1);
cv::Mat u,w,vt;
cv::SVD::compute(A,w,u,vt,cv::SVD::MODIFY_A| cv::SVD::FULL_UV);
x3D = vt.row(3).t();
x3D = x3D.rowRange(0,3)/x3D.at<float>(3);
}
VINS中 triangulatePoint() 函数原理
void GlobalSFM::triangulatePoint(Eigen::Matrix<double, 3, 4> &Pose0, Eigen::Matrix<double, 3, 4> &Pose1,
Vector2d &point0, Vector2d &point1, Vector3d &point_3d)
作者自己实现了三角化的过程( P c P_c Pc 是归一化相机系下坐标,已知帧的位姿和各自相机系下观测求三维点,为了等号意义成立,填上一个系数 a a a):

上图来自 VINS-MONO:VIO初始化部分 原理推导+代码解析
这个和前面提到的SVD求解 A x = 0 Ax=0 Ax=0 解法是一样的
此处的代码如下,在 vins_estimator/src/initial/initial_sfm.cpp 中的 triangulatePoint() 函数

对A的SVD分解得到其最小奇异值对应的单位奇异向量(x,y,z,w),深度为 z/w,所以最后面要齐次归一化
PnP问题
PnP(Perspective-n-Point)是根据图像中特征点的二维像素坐标及其对应的三维空间坐标,来估计相机在参考坐标系中位姿的一类算法。
直观来讲,当相机观察到空间中的某一物体时,我们已经知道了该物体在某一参考坐标系下的位置和姿态,那么如何通过图片中物体的成像判断出相机此时在参考坐标系下的位姿?这正是PnP要解决的问题,即利用已知三维结构与图像的对应关系求解相机与参考坐标系的相对关系(相机的外参)。
PnP是一类问题,针对不同的情况有不同的解法,常见的算法有:P3P、DLS、EPnP、UPnP等。

如上图所示,考虑空间中某个点
P
P
P,它在世界坐标系
O
w
O_w
Ow 中的齐次坐标为
P
=
[
x
,
y
,
z
,
1
]
T
P=[x,y,z,1]^{\text T}
P=[x,y,z,1]T
,其投影到图像中的像素坐标为
p
=
[
u
,
v
,
1
]
T
p=[u,v,1]^{\text T}
p=[u,v,1]T 。假设此时相机坐标系
O
c
O_c
Oc 与世界坐标系
O
w
O_w
Ow 之间的相对位姿关系由
R
R
R、
t
t
t 来描述,则有:
s
[
u
v
1
]
=
K
[
R
t
]
[
x
y
z
1
]
=
[
f
x
0
u
0
0
f
y
v
0
0
0
1
]
[
r
11
r
12
r
13
t
1
r
21
r
22
r
23
t
2
r
31
r
32
r
33
t
3
]
[
x
y
z
1
]
\color{red}s{\begin{bmatrix}u\\v\\1\end{bmatrix}}=K\color{red}{[\begin{array}{cc}R&t\end{array}]\begin{bmatrix}x\\y\\z\\1\end{bmatrix}}=\begin{bmatrix}f_x&0&u_0\\0&f_y&v_0\\0&0&1\end{bmatrix}\color{red}{\begin{bmatrix}r_{11}&r_{12}&r_{13}&t_1\\r_{21}&r_{22}&r_{23}&t_2\\r_{31}&r_{32}&r_{33}&t_3\end{bmatrix}\color{red}{\begin{bmatrix}x\\y\\z\\1\end{bmatrix}}}
s
uv1
=K[Rt]
xyz1
=
fx000fy0u0v01
r11r21r31r12r22r32r13r23r33t1t2t3
xyz1
其中的
R
=
[
r
1
r
2
r
3
]
=
[
r
11
r
12
r
13
r
21
r
22
r
23
r
31
r
32
r
33
]
,
t
=
[
t
1
t
2
t
3
]
R=\begin{bmatrix}{\mathbf{r}}_{1}&{\mathbf{r}}_{2}&{\mathbf{r}}_{3}\end{bmatrix}=\begin{bmatrix}{r_{11}}&{r_{12}}&{r_{13}}\\{r_{21}}&{r_{22}}&{r_{23}}\\{r_{31}}&{r_{32}}&{r_{33}}\end{bmatrix},t=\begin{bmatrix}{t_{1}}\\{t_{2}}\\{t_{3}}\end{bmatrix}
R=[r1r2r3]=
r11r21r31r12r22r32r13r23r33
,t=
t1t2t3
即为我们要求的旋转矩阵与平移向量,其实它俩就是所谓的相机外参。
通过相机的外参可以将世界坐标系下的点转换到相机坐标系下表示,通过相机的内参可以将相机坐标系下的点转换到像素坐标系下表示。
为了简化表示,我们暂时不考虑相机内参(因为内参 $K $是已知且不变的),并令
T
34
=
[
R
t
]
=
[
r
11
r
12
r
13
t
1
r
21
r
22
r
23
t
2
r
31
r
32
r
33
t
3
]
=
[
t
11
t
12
t
13
t
14
t
21
t
22
t
23
t
24
t
31
t
32
t
33
t
34
]
=
[
τ
1
τ
2
τ
3
]
\begin{aligned} T_{34}&=\left[\begin{array}{cc}R&t\end{array}\right] \\ &=\left.\left[\begin{array}{cccc}r_{11}&r_{12}&r_{13}&t_{1}\\r_{21}&r_{22}&r_{23}&t_{2}\\r_{31}&r_{32}&r_{33}&t_{3}\end{array}\right.\right] \\ &=\left[\begin{array}{ccc}t_{11}&t_{12}&t_{13}&t_{14}\\t_{21}&t_{22}&t_{23}&t_{24}\\t_{31}&t_{32}&t_{33}&t_{34}\end{array}\right] \\ &=\left[\begin{array}{c}\tau_{1}\\\tau_{2}\\\tau_{3}\end{array}\right] \end{aligned}
T34=[Rt]=
r11r21r31r12r22r32r13r23r33t1t2t3
=
t11t21t31t12t22t32t13t23t33t14t24t34
=
τ1τ2τ3
则上式可表示为:
s
[
u
v
1
]
=
[
t
11
t
12
t
13
t
14
t
21
t
22
t
23
t
24
t
31
t
32
t
33
t
34
]
[
x
y
z
1
]
=
[
τ
1
τ
2
τ
3
]
P
s\begin{bmatrix}u\\v\\1\end{bmatrix}=\begin{bmatrix}t_{11}&t_{12}&t_{13}&t_{14}\\t_{21}&t_{22}&t_{23}&t_{24}\\t_{31}&t_{32}&t_{33}&t_{34}\end{bmatrix}\begin{bmatrix}x\\y\\z\\1\end{bmatrix}=\begin{bmatrix}\tau_1\\\tau_2\\\tau_3\end{bmatrix}P
s
uv1
=
t11t21t31t12t22t32t13t23t33t14t24t34
xyz1
=
τ1τ2τ3
P
用最后一行把
s
s
s 消去
(
s
=
τ
3
P
)
(s=\tau_{3}P)
(s=τ3P),得到两个约束:
u
=
τ
1
P
τ
3
P
,
v
=
τ
2
P
τ
3
P
u=\frac{\tau_1P}{\tau_3P}\quad,\quad v=\frac{\tau_2P}{\tau_3P}
u=τ3Pτ1P,v=τ3Pτ2P
于是有:
{
τ
1
P
−
τ
3
P
u
=
0
,
τ
2
P
−
τ
3
P
v
=
0
\left.\left\{ \begin{array}{l}\tau_1P-\tau_3Pu=0,\\\tau_2P-\tau_3Pv=0 \end{array}\right.\right.
{τ1P−τ3Pu=0,τ2P−τ3Pv=0
可以看到,每个特征点提供了两个关于
T
34
T_{34}
T34 的线性约束,而
T
34
T_{34}
T34 中有12个未知数,所以理论上至少需要6对匹配点(每队点的二维和三维坐标)就可以求出
T
34
T_{34}
T34。
如果在已知 R R R 和 t t t 的情况下,即已知 T 3 × 4 T_{3\times 4} T3×4,则需要两个点(一对匹配点)的像素坐标,可以构建4个方程,即可求出三维空间坐标 P P P。(这就是VINS中三角化求特征点3维坐标的方法)
ICP问题
ICP(Iterative Closest Point)是根据前后两帧图像中匹配好的特征点在相机坐标系下的三维坐标,求解相机帧间运动的一种算法。直观来讲,当相机在某处观察某一物体时,我们知道了相机此时与物体之间的相对位姿关系;当相机运动到另一处,我们亦知道此时相机与物体的相对位姿关系,那么,如何通过这两次相机与物体的相对位姿关系来确定相机发生了怎样的运动?这正是ICP要解决的问题。
在ICP问题中,图像信息仅仅用来做特征点的匹配,而并不参与视图几何的运算。也就是说,ICP问题的求解用不到相机的内参与特征点的像素坐标。
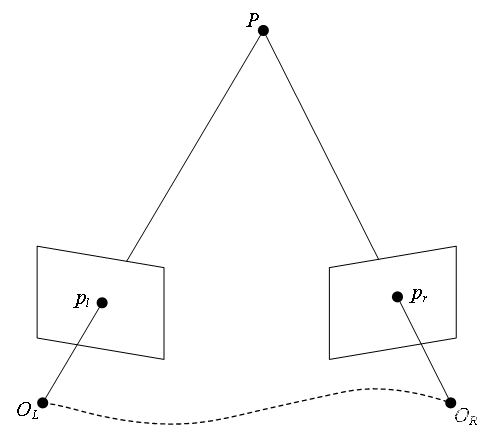
如上图所示,设空间中一点
P
P
P 在相机坐标系
O
L
O_L
OL 下的坐标为
P
O
L
=
[
x
l
,
y
l
,
z
l
]
T
P_{O_L}=[x_l,y_l,z_l]^{\text T}
POL=[xl,yl,zl]T,在相机坐标系
O
R
O_R
OR 下的坐标为
P
O
R
=
[
x
r
,
y
r
,
z
r
]
T
P_{O_R}=[x_r,y_r,z_r]^{\text T}
POR=[xr,yr,zr]T,
O
L
O_L
OL
经过运动
R
R
R、
t
t
t 到达
O
R
O_R
OR ,则
P
O
L
P_{O_L}
POL 与
P
O
R
P_{O_R}
POR 的关系为:
P
O
R
=
R
P
O
L
+
t
P_{O_R}=RP_{O_L}+t
POR=RPOL+t
写成齐次变换的形式:
[
x
l
y
l
z
l
1
]
=
[
R
t
]
[
x
r
y
r
z
r
1
]
=
[
r
11
r
12
r
13
t
1
r
21
r
22
r
23
t
2
r
31
r
32
r
33
l
3
]
[
x
r
y
r
z
r
1
]
\begin{bmatrix}x_l\\y_l\\z_l\\1\end{bmatrix}=\left[\begin{array}{cccc}R&t\end{array}\right]\begin{bmatrix}x_r\\y_r\\z_r\\1\end{bmatrix}=\left[\begin{array}{cccc}r_{11}&r_{12}&r_{13}&t_1\\r_{21}&r_{22}&r_{23}&t_2\\r_{31}&r_{32}&r_{33}&l_3\end{array}\right]\begin{bmatrix}x_r\\y_r\\z_r\\1\end{bmatrix}
xlylzl1
=[Rt]
xryrzr1
=
r11r21r31r12r22r32r13r23r33t1t2l3
xryrzr1
由此可见,每一个点
P
P
P 可以得到3个约束,那么理论上至少需要4个点就可以求得相机的运动
R
R
R、
t
t
t。
总结
1、对极几何(2D-2D)利用两帧图像中 n n n 对特征点的二维像素坐标,估计相机的相对运动 R R R、 t t t,它一般只在单目SLAM初始化的时候用到。
2、三角测量利用两帧图像中匹配特征点的像素坐标以及两个相机之间的相对位姿,估计特征点的三维空间坐标,这在单目以及双目(多目)的SLAM中都非常重要。
3、PnP(2D-3D)利用图像中 n n n 对特征点的二维像素坐标和与之对应的三维空间坐标,估计相机在空间的位置和姿态,是最重要的一种位姿估计方法。
4、ICP(3D-3D)利用 n n n 对特征点在不同相机坐标系下的三维坐标,估计相机之间的相对位姿,适用于RGB-D SLAM和激光SLAM(从原理上来说)。
5、以上种种,要想得到正确的结果,前提是准确的特征匹配以及理想的相机内参(包括针孔模型参数和畸变参数)。然而事实上,我们得到的往往是有误差或者有噪声的结果,所以通常称前面的工作为前端,因为后面还有很多事情要做,那就是后端的优化















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









