







一、逻辑结构
1.定义:具有相同数据类型的数据元素的有限序列。
2.特点:除了第一个数据元素只有一个后继结点,没有前驱结点,最后一个元素只有一个前驱结点,没有后继结点。其他元素只有一个前驱结点和一个后继结点。一对一
3.性质
a.有限性 :元素个数有限
b.抽象性 :元素数据类型抽象
c.顺序性 : 元素排序有先后顺序,集合不是线性表
数据元素之间是一对一的线性结构。元素抽象,个数有限,数据有序。
如sql中的表即为线性表,每一条记录抽象成一个数据元素。各个元素之间有序,记录个数有限。
二、基本操作 List
1.构造一个空的线性表(初始化)。InitList(&L)
2.销毁一个线性表,并释放线性表所占用的空间。DestroyList(&L)
3.判断线性表是否为空。Empty(L)
4.求线性表的表长。Length(L)
5.输出线性表内的所有元素。PrintList(L)
6.按值查找线性表。LocateElem(L,e)
7.按位查找线性表。GetElem(L,e)
8.线性表第i个位置上插入元素。ListInsert(&L,i,e):
9.线性表删除第i个位置上的元素。ListDelete(&L,i,&e)
三、顺序存储--顺序表
将线性表顺序存储,需分配一块连续的内存空间。
1.顺序表的概述
A 表中的逻辑顺序与物理顺序相同。
B 特点
a.随机访问(直接访问),随机存取 L(i)。存储密度高。(优点)
b.需要使用地址连续的存储单元 ,插入删除需要移动大量元素(缺点)
存储密度=数值所占空间 / 结点结构所占空间,
所以顺序表的存储密度是1,链表存储密度<1,需要额外空间存储指针域。
注:随机存取与顺序存取
随机存取,可以通过下标直接访问的那种数据结构,与存储位置无关,例如数组。
非随机存取就是顺序存取了,不能通过下标访问了,只能按照存储顺序存取,与存储位置有关,例如链表。
顺序存取,存取第N个数据时,必须先访问前(N-1)个数据 (list)。
随机存取,存取第N个数据时,不需要访问前(N-1)个数据,直接就可以对第N个数据操作 (array)。
C 结构-顺序存储类型 SqList
顺序表所需内存空间;顺序表表长。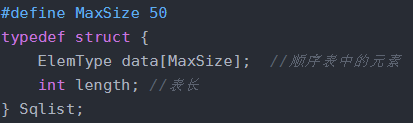
2.顺序表的基本操作与分析
A 插入操作 ListInsert(SqList &L,int i,ElemType e)
思路分析:插入位置及其后面的元素往后移动,空出插入位置插入数据。
插入操作分析:
最好情况:插入位置是最后一个位置,元素不移动,时间复杂度 O(1)
最坏情况:插入位值是第一个位置,元素都移动n次,时间复杂度 O(n)
平均情况:元素在第i个位置插入,元素移动 n - i + 1 个 元素,
共n+1个位置,每个位置被插入元素的概率是 1/(n+1),平均次数为 n/2
n+n-1 + n-2 + n-3 .... + 1 + 0 / n+1 = n/2
B 删除操作 ListDelete(SqList &L,int i,ElemType &e)
思路分析:删除第i个位置的元素,其后数据往前移动。
删除操作分析:
最好情况:删除表尾元素,无需移动元素,时间复杂度为O(1)
最坏情况:删除第一个元素,需移动n-1个元素,时间复杂度O(n)
平均情况:元素在第i个位置删除,其后的 n - i 个 元素移动,共n 个位置,平均次数为 n/2
n-1 + n-2 + n-3 .... + 1 + 0 / n = (n-1)/2
C 按值查找 (顺序查找)LocateElem(SqList L,ElemType e)
思路分析:顺序从第一个元素开始查找,找出满足条件的值。
按值操作分析:
最好情况:查找在第一个元素,时间复杂度为O(1)
最坏情况:查找在最后一个元素,时间复杂度O(n)
平均情况:1+2+3+ ...+ n / n = (n+1)/2
顺序表的具体操作实现,包括结点结构需强化。
四、链式存储-链表
将线性表链式存储,线性表中的各个元素在内存中离散地分布。
1.链表的概述
a.引入:顺序表的插入、删除操作需要移动大量的元素,影响了运行效率,由此引入了线性表的链式存储。
b.优点:不需要使用地址连续的存储单元,通过”链“建立起数据之间的逻辑关系,插入删除也不需要移动元素,只需修改指针。
c.缺点:但是不能实现随机存取,查找元素不方便。需要额外空间存储指针域,存储密度<1。
为此我们在单链表的基础上,又引入循环单链表,双链表,循环双链表,静态链表,设置尾指针等。
2.单链表
A 特点
解决顺序表需要大量的连续存储空间的缺点。
但是单链表引入的指针域需要额外的空间消耗,查找表中某一元素时,需要从表头一次遍历查找 O(n)。
B 结点类型 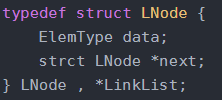
C 头结点 头指针 尾指针
头指针:指向链表第一个结点的指针。(必需的)
尾指针:指向链表最后一个结点的指针。(非必需,表尾结点查询方便)
头结点:在线性表的第一个元素结点之前加一个结点,称为头结点。(非必需,操作方便)
引入头结点的目的:
引入头结点后,头指针指向第一个结点(即头结点),则头指针总是非空的。
a.使得对链表得第一个元素操作同其他元素操作一致。
若没有头结点,对链表第一个元素结点操作(前插入,删除),都需要维护着头指针的指向更新。
引入头结点,更新头指针->next的值,与其他结点操作相同。
b.统一空表和非空表的处理。
头指针->next更新为空即可置空链表,指向新结点即可构造非空表。
D 基本操作实现
a.头插法建立单链表
思路分析:先初始化一个头结点c。然后生成第一个结点s,s->data = a[i],s->next = c->next,
头结点的指针域指向s c->next = s,使s称为新的开始结点c->next = s。i
这样每一个新的结点都被插入在头结点之后,如此循环,可生成一个倒序的单链表。
时间复杂度为O(n)
b.尾插法建立单链表
思路分析:先初始化一个头结点c。定义r指向头结点,r就是终端结点。
生成第一个结点s,s->data = a[i],头结点指向第一个结点,r->next = s,
r指向终端结点,接纳下一个结点。
这样每一个新的结点都被插入在最后一个结点之后,如此循环,可生成一个正序的单链表。
时间复杂度为O(n)
c.按序号查找结点值
思路分析:循环到第i个结点,返回该结点的值。
时间复杂度为O(n)
d.按值查找结点
思路分析:循环查找满足条件的值,返回该结点的位置。
时间复杂度为O(n)
e.插入结点操作
在p结点和q结点间插入结点s。
循环找到p结点,O(n)
先赋值,再断链。s->next = p->next;p->next = s。O(1)
f.删除结点操作
删除第i个结点。
循环找到第i-1个结点p,O(n)
p->next = p->next->next
g.求表长
3.双链表
A 引入双链表
单查找到单链表中的某一结点时,若要访问该结点的前驱结点,还需重新遍历访问。
引入双链表,可以直接找到结点的前驱结点。
B 结点类型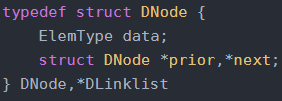
C 双链表的操作
a.尾插法建立单链表
b.查找第一个值为x的结点
c.插入结点
在第i个结点p后插入结点s,p后的结点为q。
先循环找打第i个结点p,O(n)
先赋值:s->next = p->next ; s->prior = p;
再断链:s->next->prior = s; p->next = s ;
d.删除结点
删除第i个结点
先循环找打第i-1个结点p,O(n)
q = p->next;
p->next = q->next;
q->next->prior = p;
free(q);
4.循环单链表
A 引入循环单链表
单链表在对表尾插入删除时,需要遍历到遍历到表尾。为此,引入循环单链表。
在任何一个位置的插入和删除都是等价的,无需判断是否是表尾。
可以设置一个带尾指针的循环单链表,那么可以直接找到表头和表尾,尾指针指向表尾,尾指针->next指向表头,时间复杂度为O(1)
B 操作注意
循环单链表的判空操作是头结点的指针域是否指向头结点。
p->next = p;
5.循环双链表
A 引入循环双链表
不仅能直接表头和表尾,还能找到表尾结点的前驱结点。
B 操作注意
循环双链表为空表时,其头结点的prior域和next域都等于L
6.静态链表
A 引入静态链表
静态链表指针指向结点的相对地址,即数组下标,称为游标。
需要分配一块连续的内存空间。
引入静态链表删除插入操作不需要移动元素,又能随机存取。
B 操作注意
静态链表的插入、删除操作与动态链表相同
五、线性表的综合题目(重点)
A 顺序表
数据排序插入:在一个递增的顺序表中插入一个元素,并保持有序。
删除条件数据: delete frm e_table where min(age)
从顺序表中删除具有最小值的元素(假设唯一)并由函数返回被删元素的值。空出的位置由最后一个元素填补,若顺序表为空则显示出错信息并且推出运行。
删除指定值数据: delete from e_table where name = x
长度为n的顺序表,编写一个时间复杂度为O(n)、空间复杂度为O(1),该算法删除线性表中所有值为x的数据元素。
设计一个高效的算法,将顺序表的所有元素逆置,要求算法的空间复杂度为O(1)。
B 链表
给一个带头节点的单链表,利用原有节点将单链表逆置。
将两个有序表合并. 设有两个递增排列的有序表,和并后, 仍递增有序。
在一个递增的线性表中,有数值相同的元素存在。若存储方式为单链表,设计算法去掉相同的元素,使得表中不再有重复元素。
给定两个链表,编写算法找出两个链表的公共结点。















 5890
5890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









