







目录
mysql存储引擎(本文主要介绍innodb)
主要5种类型
- csv存储引擎:
1.无索引,无自增列
2.在csv文件中编排,数据安全性低
3.应用场景:数据的快速导出和导入 - Archive存储引擎:
1.压缩数据为arz文件格式
2.只支持insert和select,只能在自增id建索引,不支持事务,占用磁盘少
3.应用场景:日志系统、数据采集、减少空间占用、数据备份 - memory heap存储引擎
1.数据存储在内存中,内存数据16M
2.支持hash,b+tree索引
3.作为临时表存储计算数据,超过16M使用Myisam - innodb存储引擎:
1.mysql5.5以后默认使用
2.支持事务,行级锁,聚集索引,支持外键关系 - Myisam存储引擎:
1.mysql5.5以前默认使用
2.表级锁,不支持事务
3.select * 无需进行数据扫描
磁盘存储
主要介绍myisam和innodb,在服务器中,用于存储数据会生成以下文件
- (Myisam)
.frm:表定义文件
.MYD:数据保存
.MYI:索引保存(多个索引保存在同一个文件) - (innodb)
.frm:表定义文件
.idb:索引及数据保存
索引
innodb采用的是b+树作为索引的数据结构
- 默认创建int(6位)的主键索引:也成为聚集索引
- 联合索引创建原则:
- 经常用的列优先(最左匹配原则)
- 离散型高的列优先(离散度高原则)
- 宽度小的列优先(最小空间原则)提高每个节点的路数
-
覆盖索引:查询的列可通过索引节点中的关键字直接返回
比如select col1,col2 from table where col1=?1 其中该表的组合索引是[col1,col2]
则查询的时候,不需要查询到叶子节点即可返回数据,减少io,减少查询时间 -
注意事项:
- 索引按场景建,建多了会导致增删改的时候,需要维护索引的时间,导致语句执行时间增加
- like语句的时候 lke xxx%不一定会用到索引,得看优化器的优化,离散型差会直接全表扫描
- not in,<>操作用不到索引,b+树无法判断走哪路
- rder by可以用索引,叶子节点有顺序
- 最左匹配原则的时候:如果某个列用到范围查询,则右边所有列无法使用索引
事务
开启事务的方式
- mysql手动开启事务,通过start transaction
- jdbc:connection.setAutoCommit
- spring aop 通过切面控制
四大特性(ACID)
- 原子性(Atomicity):事务操作要不全部成功,要不全部失败回滚
- 一致性(Consistency):事务执行前和执行后必须处于一致性状态
- 隔离性(Isolation):多个并发事务之间要相互隔离
- 持久性(Durability):一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的
数据库并发可能导致的问题:
- 脏读:读取到事务未提交的数据(两次读取不一致update或者delete操作)
- 不可重复读:读取到事务已经提交的数据(两次读取不一致update或者delete操作)
- 幻读:读取到事务插入的数据(两次读取不一致insert操作)
四种事务隔离级别:
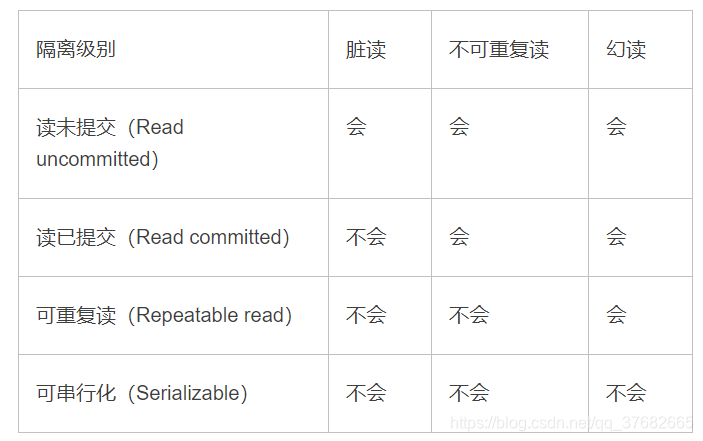
如何实现事务隔离级别
- 通过锁机制+快照读+当前读
- innodb表维护的隐藏字段:
- DB_TRX_ID:最新一次修改本行记录的操作ID
- DB_ROLL_PTR:回滚指针,存储地址配合undo log
- DB_ROW_ID:标识记录
undo log和redo log:
- undo log:事务开始之前的数据备份,用于数据回滚,事务执行前会在缓存中的undo buffer备份旧的数据,当长时间未处理或者未更改则写入磁盘
- redo log:实现事务的持久性,重启mysql可以通过redo log进行重做
- redo log策略(Innodb_flush_log_at_trx_commit):
- 取值 0 每秒提交 Redo buffer --> Redo log OS cache -->flush cache to disk
- 取值 1 默认值,每次事务提交执行Redo buffer --> Redo log OS cache -->flush cache to disk
- 取值 2 每次事务提交执行Redo buffer --> Redo log OS cache 再每一秒执行 ->flush cache to disk操作
快照读
通过mvcc(Multi-Version Concurrent Control多版本并发控制)+Undo log实现
- RC隔离级别下:一次事务下每个读数据的操作都会生成一个新的read view(快照),DB_TRX_ID+1
- RR隔离级别下:一次事务下第一条读数据的操作会生成一个快照
当前读
可认为是加锁读 RR级别下通过临键锁(间隙锁+临界锁)实现
锁机制
(注意点)
- innodb的行锁是通过给索引的索引项加锁来实现的
- 只有通过索引条件进行检索才使用行级锁,否则使用表锁
- 行级锁获取后,会给表加上表锁(意向共享锁和意向排他锁)标记,行锁(表锁标记)可以共存的,表锁标记的作用是阻塞其他表的锁表操作(表也分为共享跟排他、排他会阻塞)
- 自增锁 :默认级别是1,代表连续(取值串行化),事务未提交(比如回滚)id永久丢失
行锁算法
- 临键锁(next-key):当查询条件是范围时,即sql是type是range的时候,首先会根据id划分成多个左开右闭的区间,会锁住命中值得区间以及下一个值的区间,比如一组id分别为1,3,6,7的表数据,当你范围查询4-7时,命中6,则锁住的区间为(3,6]和(6,7]两个区间
- 间隙锁(gap):在RR事务中存在,1.中的列子,如果范围查询(4,6)没命中的话,则锁住查询范围分区内(3,6)的数据,gap锁锁住的是开区间
- 记录锁(record):唯一索引只锁住该记录,普通索引还是锁住两个区间
- 采用临键锁作为innodb默认行锁算法的原因:防止幻读,锁住了下一个区间,无法插入。next-key=gap+record
- 方便理解:意向锁认为是一个标记,表锁时先判断是否有该标记
查询过程
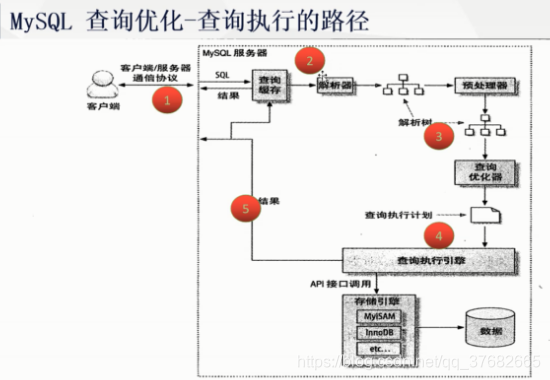
- mysql客户端/服务端通信:半双工->同一时间只有一方可以发送消息(类似踢足球)
全双工:双方可以同时发送消息(电话)
单工:只能单向传输
show processlist指令查看当前连接状态 - 查询缓存:sql和结果集的缓存,如果sql完全一致,则返回缓存(默认关闭)
- 查询优化处理
a. 解析sql:通过 lex此法分析,yacc语法解析成解析树(简单认为解析成可处理的对象)
b. 预处理阶段:mysql语法规则校验,检查表列是否存在,进行权限校验
查询优化器:找到最优执行计划
c. 等价变换规则:比如查询条件是a>b and b=5 就会转换成a>5 and b=5
d. in和or的区分:in(1,2,3)采用二分法比对,相等就返回,or1 or2 or3即使匹配了仍继续比对 复杂度为logn和n,in有做二分优化(排序在二分查找),所以尽量用in语句
e. 外连接查询会转换成内连接
f. 优化count、min、max函数 可以直接找b+树叶子节点的最大值和最小值
g. 覆盖索引(查询一个组合了主键id的列)也是覆盖索引,因为叶子节点也包括主键id
h. limit优化:值查询到limit最后一个节点,之后的数据不在做遍历 - 查询执行引擎:调用执行计划
- 返回客户端:
是否需要做缓存处理
增量返回,在第一次拿到数据后就开始逐量返回
执行计划查看(explain)
- id相同,执行顺序由上到下
- id不同,存在子查询会递增,id高的先执行
- select_type:
(1) SIMPLE:简单查询,没有子查询或者union
(2) PRIMARY:包含子查询,最外层为PRIMARY
(3) SUBQUERY/MATERIALIZED:SUB标识在select或者where中包含子查询,MAT表示where后面in条件的子查询
(4) 若第二个select出现在union之后,标记为union
(5) UNION RESULT:从union表获取的结果的select - table:设计的表
- type:访问类型
- const:一次索引找到数据
sq_ref:唯一索引扫描,对于每个索引键,只有一条记录
possible_keys:可能用到的索引 - key:实际用到的索引
- rows:估算读取的行数
- filtered:返回结果占读取行数的百分比
- extra:额外信息,比如用到临时表,文件排序等
如何定位慢sql
- 慢查询日志
- 慢查询工具:mysqldumpslow














 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









