




 GraphX是Spark中的图形处理组件,支持图形并行计算。它引入了有向多重图的抽象,每个顶点和边都有属性。GraphX提供了一系列基本操作符和Pregel API的优化变体,以及内置的图形算法,适用于复杂的图形分析任务。
GraphX是Spark中的图形处理组件,支持图形并行计算。它引入了有向多重图的抽象,每个顶点和边都有属性。GraphX提供了一系列基本操作符和Pregel API的优化变体,以及内置的图形算法,适用于复杂的图形分析任务。
简介
GraphX是Spark中图形和图形并行计算的新组件。GraphX通过引入一个新的图形抽象来扩展Spark RDD:一个有向多重图,每个顶点和边都有属性。为了支持图形计算,GraphX公开了一组基本操作符(例如,subgraph、joinVertices和aggregateMessages),以及Pregel API的一个优化变体。此外,GraphX还包含了越来越多的图形算法和构建器,用于简化图形分析任务
切分方式
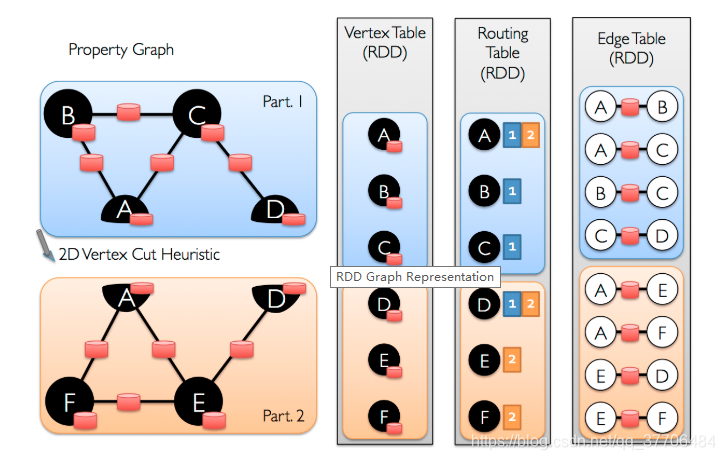
因为一般边属性多于点属性,边数量大于点数量,所以GraphX采用vertex-cut,而不是采用edge-cut,这样能减少通信和存储开销

属性图构建
GraphX由VertexRDD[VD]和EdgeRDD[ED]构成,分别扩展和优化了RDD[(VertexId, VD)]和RDD[Edge[ED]],构建方法有如下三种,实现类为GraphXImpl,其实还引入了一个路由表RoutingTable,其类型为RDD[RoutingTablePartition],作用是为顶点属性传送到边分区提供路由信息。每个顶点必须是唯一的64位Long型ID(VertexId)。
## 第一类,有顶点数据
## 1.根据RDD[(VertexId, VD)],RDD[Edge[ED]]构建,形如Graph(vertexRDD, edgeRDD)
def apply[VD: ClassTag, ED: ClassTag](
vertices: RDD[(VertexId, VD)],
edges: RDD[Edge[ED]],
defaultVertexAttr: VD = null.asInstanceOf[VD],
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[VD, ED] = {
GraphImpl(vertices, edges, defaultVertexAttr, edgeStorageLevel, vertexStorageLevel)
}
## 1 通过GraphImpl的apply方法构建
def apply[VD: ClassTag, ED: ClassTag](
vertices: RDD[(VertexId, VD)],
edges: RDD[Edge[ED]],
defaultVertexAttr: VD,
edgeStorageLevel: StorageLevel,
vertexStorageLevel: StorageLevel): GraphImpl[VD, ED] = {
val edgeRDD = EdgeRDD.fromEdges(edges)(classTag[ED], classTag[VD])
.withTargetStorageLevel(edgeStorageLevel)
val vertexRDD = VertexRDD(vertices, edgeRDD, defaultVertexAttr)
.withTargetStorageLevel(vertexStorageLevel)
GraphImpl(vertexRDD, edgeRDD)
}
## 第二类,无顶点数据
## 2.1根据RDD[Edge[ED]]构建,形如Graph.fromEdges(edgeRDD, "")
def fromEdges[VD: ClassTag, ED: ClassTag](
edges: RDD[Edge[ED]],
defaultValue: VD,
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[VD, ED] = {
GraphImpl(edges, defaultValue, edgeStorageLevel, vertexStorageLevel)
}
## 2.2根据RDD[(VertexId, VertexId)]构建,形如Graph.fromEdgeTuples(edgeRDD, "")
def fromEdgeTuples[VD: ClassTag](
rawEdges: RDD[(VertexId, VertexId)],
defaultValue: VD,
uniqueEdges: Option[PartitionStrategy] = None,
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[VD, Int] =
{
val edges = rawEdges.map(p => Edge(p._1, p._2, 1))
val graph = GraphImpl(edges, defaultValue, edgeStorageLevel, vertexStorageLevel)
uniqueEdges match {
case Some(p) => graph.partitionBy(p).groupEdges((a, b) => a + b)
case None => graph
}
}
## 2.1, 2.2都是通过以下两个方法构建
def apply[VD: ClassTag, ED: ClassTag](
edges: RDD[Edge[ED]],
defaultVertexAttr: VD,
edgeStorageLevel: StorageLevel,
vertexStorageLevel: StorageLevel): GraphImpl[VD, ED] = {
fromEdgeRDD(EdgeRDD.fromEdges(edges), defaultVertexAttr, edgeStorageLevel, vertexStorageLevel)
}
private def fromEdgeRDD[VD: ClassTag, ED: ClassTag](
edges: EdgeRDDImpl[ED, VD],
defaultVertexAttr: VD,
edgeStorageLevel: StorageLevel,
vertexStorageLevel: StorageLevel): GraphImpl[VD, ED] = {
val edgesCached = edges.withTargetStorageLevel(edgeStorageLevel).cache()
val vertices = VertexRDD.fromEdges(edgesCached, edgesCached.partitions.size, defaultVertexAttr)
.withTargetStorageLevel(vertexStorageLevel)
fromExistingRDDs(vertices, edgesCached)
}
来一张官方图,大致对数据存储的方式有个概念
构建边EdgeRDD
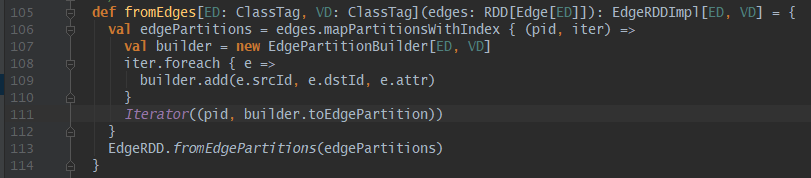
EdgeRDD[ED]是扩展和优化了RDD[Edge[ED]],构建方法只有一个fromEdges,返回EdgeRDDImpl[ED,VD],边分区保留RDD[Edge[ED]]的分区策略(对于默认采用srcId哈希分区存疑),构建过程主要通过EdgePartitionBuilder类对Edge[ED]进行转化处理。
构建EdgePartition
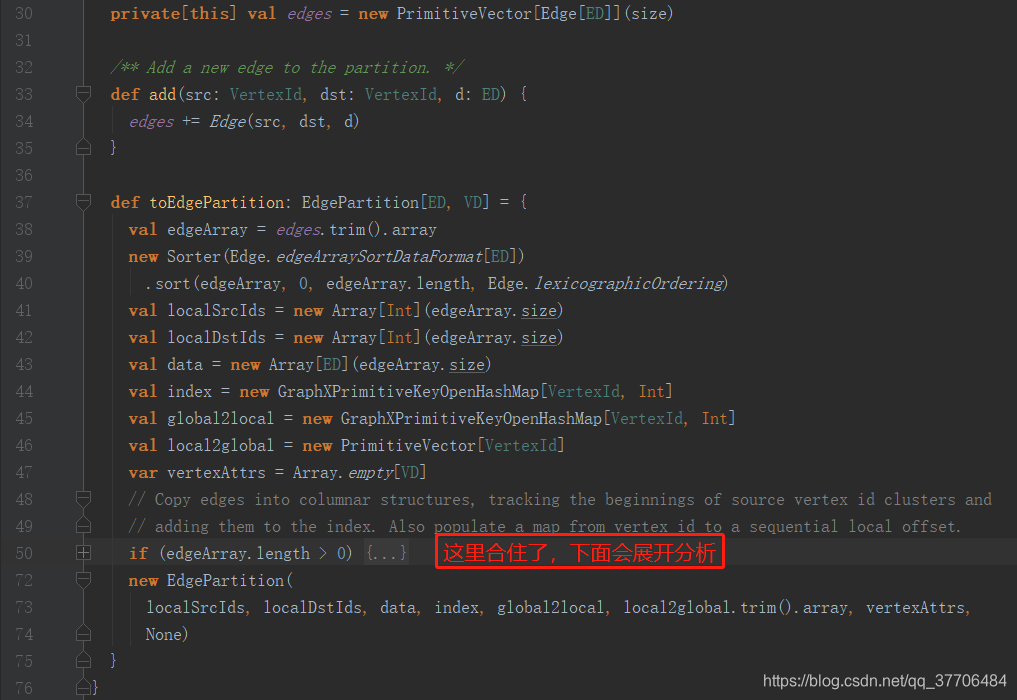
在EdgePartitionBuilder中,通过调用add方法讲数据装载到PrimitiveVector,在toEdgePartition方法中,首先对数据进行重排序,排序规则为先按srcId,后按dstId,从小到大排序。然后利用排序后的数据装载了localSrcIds,local2DstIds,data,index,global2local,local2global,vertexAttrs(下文会分析),最后构造了EdgePartition对象。
其中index,global2local为Map结构,localSrcIds,local2DstIds,data,local2global,vertexAttrs是Array结构
Q:localSrcIds,local2DstIds,data为什么要用Array?
A:网上说是因为内存是连续的,可以顺序访问,保证访问性能,我觉得没说到点上,不容易理解,我觉得是因为一个边有两个点,这两个点分别用数组按顺序存储,相同下标就是同一行数据,且数据下标也一致,这样在取数据时就很方便)
Q:边数据为什么重排序?
A:目前个人能理解到的就是在生成index时有用到,排序是先按srcId排序,所以能保证srcId在分区内全局有序,index存储也是以srcId为key,以第一次出现的边号-1为value存储,如果我们找srcId,,可以很快定位到所在边的位置,访问速度快,为什么没有dstId的index呢?因为desId在分区内不是全局有序
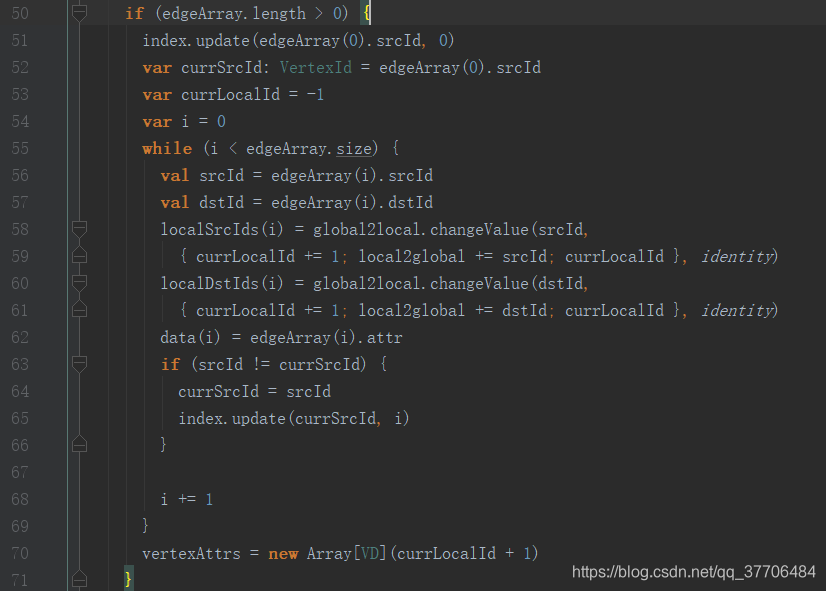
数据装载解析,个人定义两个下标,从0开始,针对于一条边的叫做边标,针对于一个点的叫做点标
global2local.changeValue方法是类似upsert操作,参数(key, value ,mergFunc),如果key存在,则调用mergFun函数,如果key不存在,则放入key,value,最终都会返回global2local中key对应的点标。这里需要注意,value这里传入的是个函数{currLocalId += 1; local2global += srcId/dstId; currLocalId},只有当key不存在的时候,函数才会执行,currLocalId才会加1,local2global才会添加srcId/dstId,local2global数组下标就是点标
index存放的是srcId和srcId出现的第一个边标
localSrcIds,local2DstIds,data:这三个数组的长度等于边数,就是把Edge对象分解等到的srcId,dstId,data分别放入三个数组,只不过localSrcIds,local2DstIds放入的是点ID在local2global对应的点标,而其下标就是排序后边数据的边标,所以相同边标就是一条边信息
最后来个解释,不知道能不能描述清楚,不清楚的看下面的例子:
localSrcIds,localDstIds:存储的数据分别为srcId/dstId在local2global中的下标
data:按遍历边的顺序,存放边的属性
local2global:存放的顶点ID,其下标等于点标(数据选取按先srcId后dstId规则,选择排序后的边数据,放入local2global,数据存在则不会被放入,因为global2local.changeValue方法中的函数没被执行)
global2local:KV => (顶点ID, 点标)
index:KV => (顶点ID, 顶点第一次出现的边标)
vertexAttrs:空数组,长度为点的总数,用于存放local2global中点对应的属性值,思考:为什么是数组?
举栗子:数据如下,前三行数据为分区0,后面三行为分区1,以分区0数据为例
val edge = Array(
Edge(1L, 21L, "1") #part0
, Edge(11L, 12L, "1") #part0
, Edge(1L, 12L, "1") #part0
, Edge(2L, 22L, "1") #part1
, Edge(3L, 33L, "1") #part1
, Edge(4L, 44L, "1") #part1
)
## 构建2个分区
val edgeRDD = sc.parallelize(edge,2)
经过toEdgePartition方法后分区0中数据如下,类似2 = 3 是下标和数据的对应关系,数据本身只有3

各集合的构造都是基于排序后数据。很明显,localSrcIds,localDstIds,data存放的是边拆解数据,local2global(带下标)和global2local是相反的,index是(srcId,边标)。这里再说下local2global中取数原则:1 ,12 ,1(重复),21,11,12(重复) => 1,12,21,11
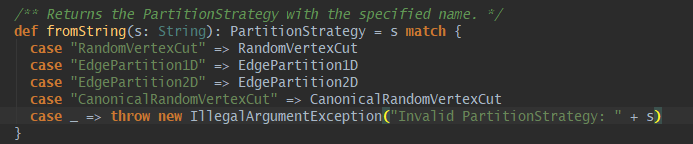
上面得知,边构建过程是保留原始RDD[Edge]的分区策略,如果要更改边分区,不是点,GraphX自身提供了四种边分区策略,如下,也可以自定义实现分区器。

构建点VertexRDD
VertexRDD[VD]扩展和优化了RDD[(VertexId, VD)],构建方法有两个,不同在于构建属性图时是否传入顶点数据。
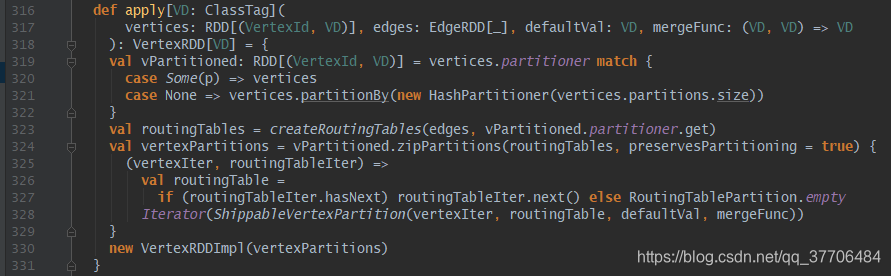
1. 有顶点数据:先获取顶点数据的分区器,没有则对顶点数据按顶点ID哈希分区;在通过边数据和顶点分区器构建路由表RDD[RoutingTablePartition],路由表的分区和顶点一致,最终使用zipPartitions算子将顶点和路由表拉链为RDD[ShippableVertexPartition]
![]()
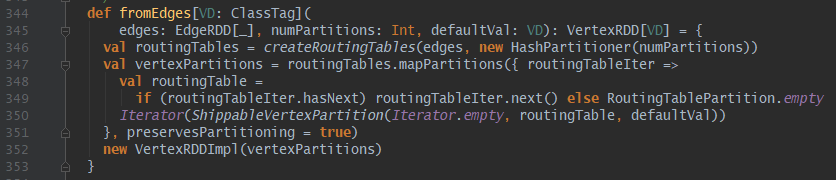
2. 无顶点数据:直接通过边数据和哈希分区器(分区数numPartitions为边的分区数)构建路由表,最终路由表通过mapPartitions算子生成RDD[ShippableVertexPartition]
RDD[RoutingTablePartition]
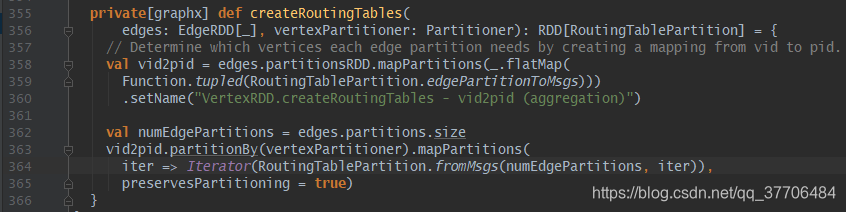
利用边数据生成路由表信息,调用createRoutingTables,这里核心就是两步,第一步:(359行)把每个边分区内的srcId和dstId都转化成RoutingTableMessage对象,记录顶点ID和边分区ID的映射关系(vid2pid),这里路由表分区和边一致,第二步:(363行)将vip2pid按顶点分区器重新分区,这里路由表分区和顶点一致,目的是保证每个顶点分区内都能得到自己含有的顶点到边的路由信息,最后将RoutingTableMessage信息拆解并构建为RoutingTablePartition返回

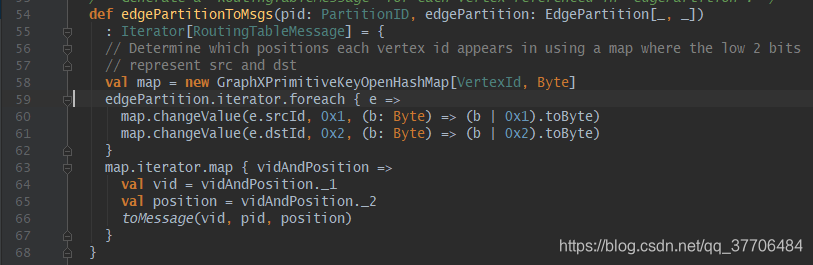
第一步构建RoutingTableMessage:edgePartitionToMsgs方法会接受两个参数,分别为边分区ID(pid)和边分区数据,这里将所有边拆解装载到Map里,用srcId或dstId作为Key,1或2标识作为Value,遍历Map调用toMessage方法转成RoutingTableMessage对象,该对象为(VertexId ,Int)二元组,元素1是顶点ID,元素2是pid和标识pos(1-srcId,2-dstId,3-srcId&dstId)按位运算得到的Int值,0-30位为pid,31-32位为标识位。
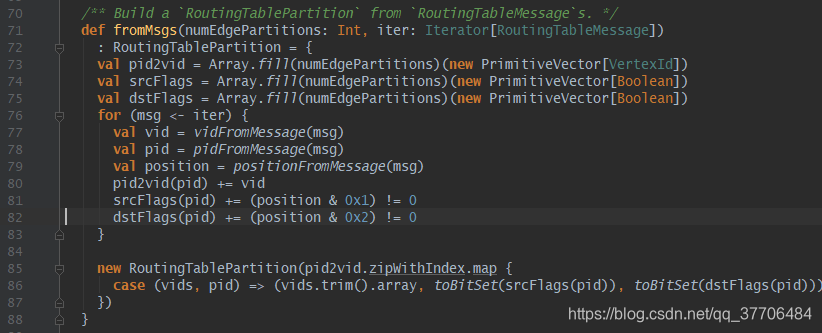
第二步构建RoutingTablePartition:第一步的RoutingTableMessage按顶点分区器分区后,每个分区会获得对应RoutingTableMessage信息,fromMsgs接受两个参数,一个为按顶点分区后的RoutingTableMessage信息,另一个为边partion数。这里初始化了3个二维数组pid2vid,srcFlags,dstFlags,第一维数组长度为边partion数,第二维数组长度默认64,放置策略为,将顶点顺序放入所属边分区对应的数组中,遍历RoutingTableMessage对象,解析得到vid,pid,标识pos,完成数据的装载。
最后pid2vid.zipWithIndex.map操作得到RoutingTablePartition,为数组类型的三元组Array[(Array[vids], srcFlags,dstFlags)],下标即对应边partionId,元素1含义即为该顶点分区内,在该下标边分区内所有vids集合
举栗子:以上面数据为例,将第一步生成的RoutingTableMessage重新分区后(按顶点ID哈希分区),分区0的数据有(2, 1, 1)(4, 1,1)(12, 0,2)(22,1,2)(44,1,2),分别表示(顶点ID, pid , pos),数据不一定有序,这里是按照从小到大装载。2个分区数据如下:

分区0的数据装载后如下:这里pos我直接写的是标识pos(1,2,3),其实解析出来对应关系是(1 = 1,2 = -2,3 = -1)
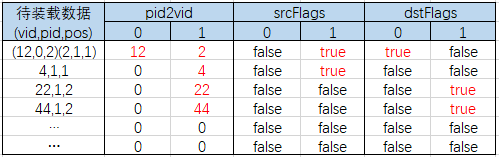
上面的解释为,顶点分区0有2,4,12,22,44这些顶点,在边分区0上有12,且为目标点;在边分区1上有2,4,22,44,,且分别为源点,源点,目标点,目标点
RDD[ShippableVertexPartition]


有了RoutingTablePartition后,开始构造ShippableVertexPartition,有两种方式,原理一样,没有顶点数据的使用Iterator.empty代替了
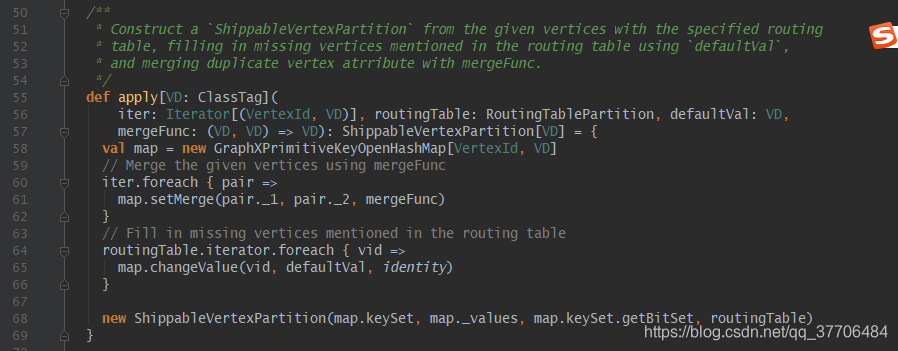
ShippableVertexPartition对象构建很简单,如果有顶点数据,先将顶点数据装载进Map里(60-62行),然后用路由表里的顶点(通过routingTable.iterator获取)补全顶点数据,用默认值填充补全顶点value(64-66行)。
最终构建ShippableVertexPartition对象,构造参数(vids,values,vidsBitSet, routingTable),也就是(分区内点集合,分区内点属性,Bitset,路由表信息)。
小结
边构建,就是将边对象Edge拆解后载入localSrcIds,local2DstIds,data,index,并且生成索引global2local,local2global,提升访问速度,这里值得一提的是索引可以重用。最终构建为EdgePartition
点构建,首先利用边数据生成路由表信息,按点分区器分区,然后补全点分区数据,组合路由表,最终构建为ShippableVertexPartition
构建Graph
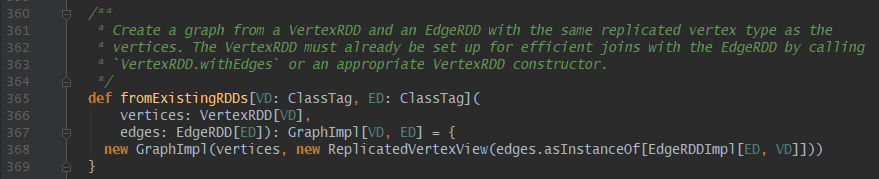
上面已经构建好EdgeRDD[ED]和VertexRDD[VD],最终利用GraphImpl.fromExistingRDDs构建属性图。至此属性图构建完成。在构建属性图引入了ReplicatedVertexView对象,也就是常说的重复顶点视图,直译为可搬运顶点视图,其实就是顶点搬运。
ReplicatedVertexView
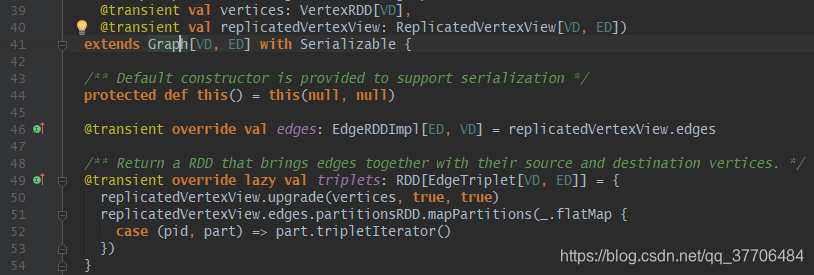
在GraphImpl中有三个变量,分别为vertices:VertexRDD,edges:EdgeRDD,triplets:RDD[EdgeTriplet],前两个就是上面构建的,第三个triplets为边三元组,在边的基础上多了源点和目标点的属性,后面大部分算法都是操作边三元组,例如pageRank等算法,这里先简单看下GraphX是如何构建EdgeTriplet的,其他的算法需要构建边三元组的过程都差不多。
构建EdgeTriplet
EdgeTriplet继承Edge,属性值有srcId,dstId,attr,srcAttr,dstAttr,其实就是在边上添加源点和目标点的属性值,共同组成了EdgeTriplet对象,所以如果用到边三元组就会发生顶点数据到边的迁移,即点数据移动。
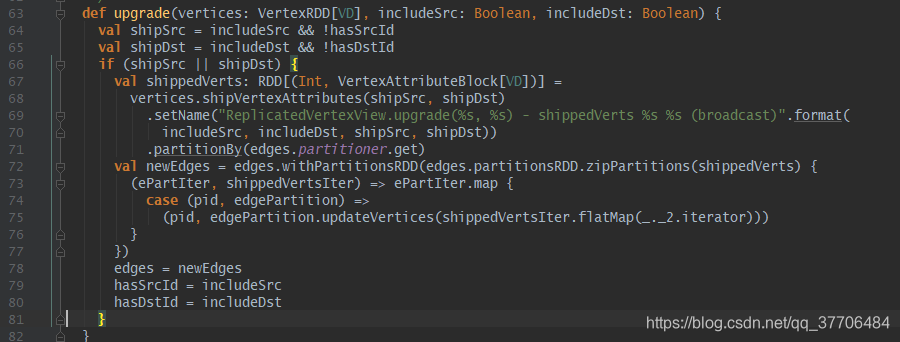
在replicatedVertexView.upgrade中核心完成了EdgePartition对象中的VertexAttrs数组的数据装载。在开始构建的EdgeRDD中VertexAttrs是空集合。upgrade方法中重点分析下vertices.shipVertexAttributes方法,利用VertexRDD中携带着的路由表信息构建出RDD[Int, VertexAttributeBlock],其数据释义为RDD[边分区ID(pid), Array[vids], Array[attrs]],其实就是构建每个顶点分区到各个边分区的顶点ID以及数据,顶点ID和数据都用数组存储,下标为对应关系,且对构建出的数据采用边分区器进行分区(还记得构建路由表是采用点分区器吧,反向过程),最终使用zipPartitions算子与edges拉链起来,装载了VertexAttrs,构建出newEdges。最后拆解边封装为EdgeTriplet。
思考:
1.如果一个顶点被分布在n个边分区,那么在构建边三元组的时候,该顶点则会被复制n份,假如该顶点属性值很大,为了避免占用大量内存和带宽,应该减少复制次数,也就是减少该点的所属分区,此时,我们应该根据大属性点对边重新分区,尽量避免这种大属性点被分到多个边分区。
2.在GraphX构建过程中,涉及数据对应关系都使用了数组,而不是Map,仔细想想,反而能理解localSrcId等装载为什么也用Array,以及网上说的内存是连续的,提升访问速度,因为同样取一条数据,使用下标取两个数组要比hash取一个Map快,这中间减少了Hash过程,所以提升了访问速度

















 2767
2767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









