









前言
已经搭建起来一个Hadoop-HA集群,上面也搭建了Hive以及MySQL搭建方法直通车!点我!!。既然万事俱备,那么开始认识下Hive框架吧!
高版本hive配置介绍
从wordcount认识hive
前面手写过很多MR程序,也对MR有一定的认识。hive框架是将每一句insert类型的HQL转换成为一个MR程序!虽然提供的模板不能完全的覆盖所有生产环境,但是框架的强大依然让它非常流行。下面以简单的wordcount程序来认识下hive的强大吧!
分隔符
hive的数据是存储在hdfs,hive建表后要和数据关联,关联后,每次对hive表的查询,实质是运行一个MR!
MR程序默认将表目录作为输入目录,MR在读取输入目录的数据时,需要根据数据的样式正确的把数据封装到指定的列上!
hive中默认的分隔符:
| 分割目标 | 标识符 |
|---|---|
| 行 | \n |
| 字段 | ^A |
| map,array和struct每个元素 | ^B |
| map中key-value的分隔符 | ^C |
特殊字符输入方式
-
^A: 在vim中,先进入编辑模式,再按ctrl+V,再按ctrl+A
-
大小写: hive中SQL语句是不区分大小写,除非是一些关键的属性名(严格区分大小写)!
-
如果数据没有使用默认的分隔符,需要在建表时,手动指定当前表使用什么分隔符可以读取数据!
数据准备
数据展示
here you are
where is it
i am king
kevin go to
hadoop hive zookeeper
.........
需要对数据进行ETL,转为结构化的数据
转换以后的数据命名为test.txt,每一个单词和数字用 ‘\t’ 分割。
here 1
you 1
are 1
where 1
is 1
it 1
i 1
am 1
king 1
kevin 1
go 1
to 1
hadoop 1
hive 1
zookeeper 1
kevin 1
kevin 1
kevin 1
kevin 1
kevin 1
king 1
在hive中用HQL创建表
create table wordcount(word string,num int) row format delimited fields terminated by '\t';

数据与表关联
 在当前路径启动的hive
在当前路径启动的hive
bin/hive
关联数据(每执行一次,相当于追加一次)
load data local inpath 'test.txt' overwrite into table wordcount;

查询结果
select word,sum(num) from wordcount group by word;


修改hive-site.xml
<!-修改默认路径-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/zhengkw</value>
<description>location of default database for the warehouse</description>
</property>
<!- 显示表头-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!- 显示当前库名字-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
测试

Hive的JDBC访问方式
hive提供了JDBC的访问方式,需要启动对应的hive2服务。
切换目录到HIVE_HOME目录!执行后台启动hive2服务!
bin/hiveserver2 &

beeline
Beeline是一个支持JDBC连接的客户端工具!
启动beeline,创建一个新的连接
!connect 'jdbc:hive2://hadoop103:10000'

之后回车,输入用户名(必须和集群里的Owner一致!),密码随意!
连接
连接关系数据库所在的端口10000,协议是hive2协议!
 连接成功!
连接成功!
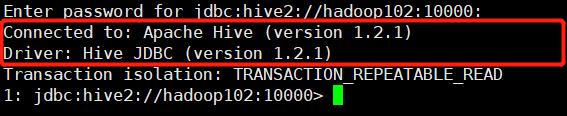
注意
不能加分号!!
 加分号会报错!!!
加分号会报错!!!
使用Java程序访问Hive
创建Maven工程,引入hive-jdbc的驱动
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
import java.sql.*;
/**
* @ClassName:HiveJdbcTest
* @author: zhengkw
* @description:
* @date: 20/03/04下午 9:35
* @version:1.0
* @since: jdk 1.8
*/
public class HiveJdbcTest {
public static void main(String[] args) throws SQLException {
//hive已经智能化的注册驱动
// Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection connection = DriverManager.
//user 保证和hdfs集群的所有者用户一致!!
getConnection("jdbc:hive2//hadoop102:10000",
"atguigu",
"");
//准备sql
String sql = "select * from person";
PreparedStatement ps = connection.prepareStatement(sql);
//执行查询
ResultSet resultSet = ps.executeQuery();
//遍历结果
while (resultSet.next()) {
System.out.println("name:" + resultSet.getString("name") + " age:" +
resultSet.getInt("age"));
}
//关闭资源
resultSet.close();
ps.close();
connection.close();
}
}
Hive交互命令
1.查看hive中的变量
查看hive启动后加载的所有的变量
set
查看某个指定的参数的值
set 属性名
对加载的参数进行修改,此次修改只有当前的cli有效,一旦退出就需要重新设置
set 属性名=属性值;
使用hive -d 变量名=变量值,启动后,可以在cli使用 ${变量名} 引用变量名,获取它的值!(这个是java程序所以是 ${变量名},而linux获取变量值是用 $变量名 )!!!
2.hive交互命令
hive
-d key=value: 定义一个变量名=变量值
--database 库名: 让hive初始化连接指定的库
-e <quoted-query-string> : hive读取命令行的sql语句执行,结束后退出cli
-f sql文件: hive读取文件中的sql语句执行,结束后退出cli
--hivevar <key=value> : 等价于-d
--hiveconf <property=value>: 在启动hive时,定义hive中的某个属性设置为指定的值
-i <filename> : 在启动hive后,先初始化地执行指定文件中的sql,不退出cli
-S,--silent : 静默模式,不输出和结果无关的信息
3.hive中属性加载的顺序
a)hive依赖于hadoop,hive启动时,默认会读取Hadoop的8个配置文件
(core,yarn,mapred,hdfs的默认和自定义配置文件共8个)
b)加载hive默认的配置文件hive-default.xml
c)加载用户自定义的hive-site.xml
d)如果用户在输入hive命令时,指定了–hiveconf,那么用户指定的参数会覆盖之前已经读取的同名的参数!
数据类型
1.集合数据类型
JSON格式的数据
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}
处理数据
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
| 分隔符 | 分割位置 |
|---|---|
| , | 逗号分割字段 |
| _ | 下划线分割集合类型的元素 |
| : | 冒号分割map中的key和value |
基于以上数据建表
create table t1(name string,friends array<string>,children map<string,int>,
address struct<street:string,city:string> )
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':';
注意:
只要有对应关系的数据,可以使用struct和map,区别在于如果是struct要求每条数据的属性名是一致的!
map则没有要求!
一个表对应的数据中,所有的集合类型,元素的分隔符必须是一致的!否则会造成集合无法识别!
从集合中取数据
select
friends[1],
children['xiaoxiao song'],
address.street
from
t1
where
name='songsong';
2.上传数据到表目录
load data [local] inpath '路径名' [overwrite] into table '表名'
不加local则路径为hdfs上的路径!
加入overwrite则为覆盖,不加则为追加!
3.类型转换
任何低精度类型在和高精度类型运算时,可以自动向上转型!
布尔类型无法转为其他类型!
使用强制类型转换:
cast('值' as 类型)
如果强转失败,则为NULL!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









