







 本文详细探讨了Tensorflow中tf.metrics模块的使用,特别是精确率(precision)的计算,通过实例解释了如何计算整体样本准确率和批次准确率,以及在使用过程中的常见问题和注意事项,包括更新操作update_op的正确位置和precision_at_k的理解与应用。
本文详细探讨了Tensorflow中tf.metrics模块的使用,特别是精确率(precision)的计算,通过实例解释了如何计算整体样本准确率和批次准确率,以及在使用过程中的常见问题和注意事项,包括更新操作update_op的正确位置和precision_at_k的理解与应用。
【续】–Tensorflow踩坑记之tf.metrics
欠下的帐总归还是要还的,之前一直拖着,总是懒得写tf.metrics这个API的一些用法,今天总算是克服了懒癌,总结一下tf.metrics遇到的一些坑。
插一句闲话,这一次的博客基本上用的都是 Jupyter,感觉一级好用啊。可以一边写代码,一边记markdown,忍不住上一张效果图,再次欢迎大噶去我的Github上看一看,而且Github支持 jupyter notebook 显示,真得效果很好。
在这篇伪Tensorflow-tf-metrics中,澜子介绍了tf.metrics中涉及的一些指标和概念,包括:精确率(precision),召回率(recall),准确率(accuracy),AUC,混淆矩阵(confusion matrix)。下面先给出官方的API文档,看看这个模块中都有哪些隐藏秘笈。
看了官方文档之后,大噶可能会发现其中有好多可以调用的函数,不仅有precision / accuracy/ auc/ recall,还有precision_at_k / recall_at_k,更有precision_at_thresholds/ precision_at_top_k/ sparse_precision_at_k…天啦噜,这都是什么呀,澜子已经彻底晕了,到底要怎么用啊(眼冒金星中)。别急,让我一个坑一个坑地告诉你。
划重点
首先,这篇文章是受到Ronny Restrepo的启发,
这是一篇很好的文章,将tf.metrics.accuracy()讲解滴很清楚,本文就模仿他的思路,验证一下precision的计算。
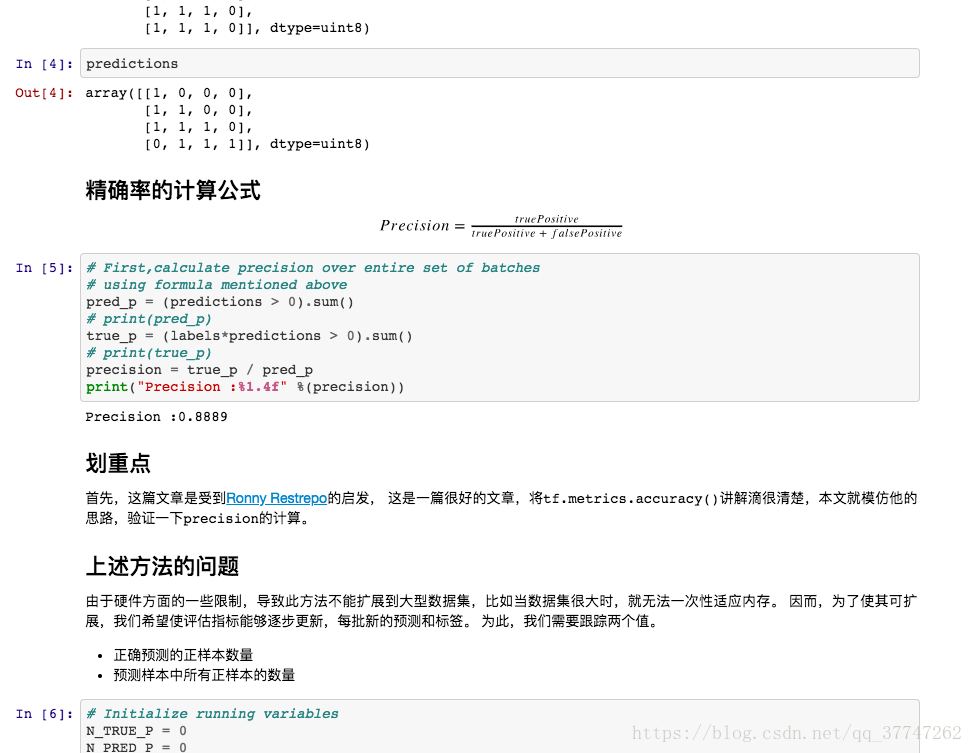
精确率的计算公式
Precision=truePositivetruePos
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









