







 本文详细介绍了自然语言处理(NLP)的各个方面,包括NLU(自然语言理解)和NLG(自然语言生成)。NLU致力于让计算机理解人类语言,涉及分词、词性标注、句法分析等任务。NLG则是将结构化数据转化为自然语言的过程,包括内容确定、文本结构等六个步骤。NLP的分析层面涵盖词法、句法和语义分析。文章还探讨了NLP在大规模内容生成、数据洞察和内容生产加速等方面的用途。
本文详细介绍了自然语言处理(NLP)的各个方面,包括NLU(自然语言理解)和NLG(自然语言生成)。NLU致力于让计算机理解人类语言,涉及分词、词性标注、句法分析等任务。NLG则是将结构化数据转化为自然语言的过程,包括内容确定、文本结构等六个步骤。NLP的分析层面涵盖词法、句法和语义分析。文章还探讨了NLP在大规模内容生成、数据洞察和内容生产加速等方面的用途。
一、NLP是什么
NLP(Natural Language Processing,自然语言处理)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法(摘自百度百科)。
不同的语言之间是无法直接沟通的,比如说人类就无法听懂狗叫,甚至不同语言的人类之间都无法直接交流,需要翻译才能理解各自的意思。

而对于人类与计算机来说,NLP就是在机器语言和人类语言之间沟通的桥梁,用以实现人机交流的目的。
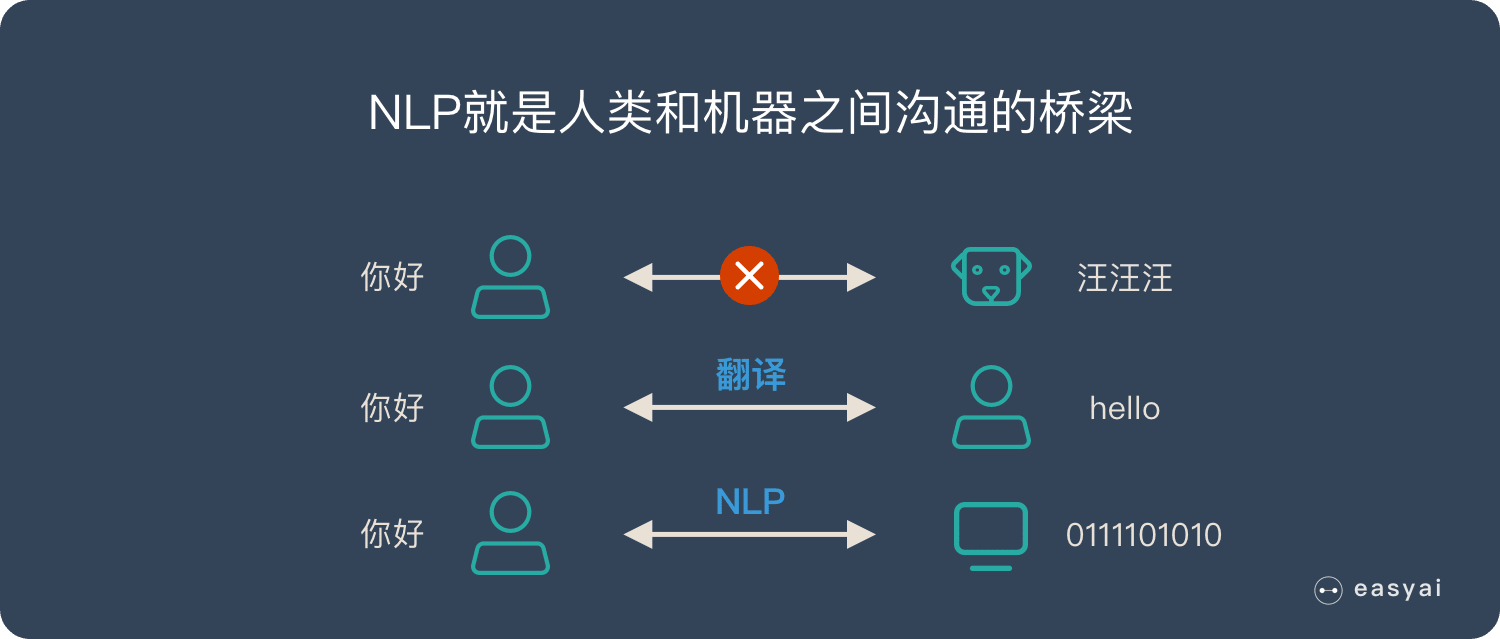
NLP由以下两个部分组成:
- NLU(Natural Language Understanding,自然语言理解)
- NLG(Natural Language Generation,自然语言生成)

二、NLU 自然语言理解
NLU(Natural Language Understanding,自然语言理解)是所有支持机器理解文本内容的方法模型或任务的总称,包括分词,词性标注,句法分析,文本分类/聚类,信息抽取/自动摘要等任务。简单来说,就是希望计算机能够像人一样,具备正常的语言理解能力。
举个“订机票”的例子:对于订机票这件事情,我们可以有很多种表达方式
- 有去上海的航班吗?
- 订一张机票去上海,下周二出发。
- 下周二要出差上海,帮我看下机票。
- 我要搭最近的飞机去上海。
- ……
可以说,自然语言对于“订机票”的表达是无穷多的,而这对于计算机来说是一种巨大的挑战。在没有引入人工智能前,计算机只能基于规则去识别意图。比如将“订机票”作为关键词,如果文本中没有该关键词,将无法准确识别用户的意图。或者只要出现了关键词,比如“我要退订机票”,那么也会被处理成用户想要订机票。

而自然语言理解目的就是准确识别用户的意图。

自然语言理解跟整个人工智能的发展历史类似,一共经历了3次迭代:

- 基于规则的方法 :通过总结规律来判断自然语言的意图,常⻅的⽅法有:CFG(下文无关文法)、JSGF(JSpeech Grammar Format)等。
- 基于统计的方法 :对语言信息进行统计和分析,并从中挖掘出语义特征,常⻅的方法有:SVM(支持向量机)、HMM(隐马尔科夫模型)、MEMM(最大熵马尔可夫模型)、CRF(条件随机场)等。
- 基于深度学习的⽅法:CNN(卷积神经网络),RNN(循环神经网络),LSTM(长短期记忆网络),Transformer等。
三、NLG 自然语言生成
NLG(Natural Language Generation,自然语言生成)是一种自动将结构化数据转换为人类可读文本的软件过程。
NLG的6个步骤

第一步:内容确定 – Content Determination
作为第一步,NLG 系统需要决定哪些信息应该包含在正在构建的文本中,哪些不应该包含。通常数据中包含的信息比最终传达的信息要多。
第二步:文本结构 – Text Structuring
确定需要传达哪些信息后,NLG 系统需要合理的组织文本的顺序。例如在报道一场篮球比赛时,会优先表达“什么时间”“什么地点”“哪2支球队”,然后再表达“比赛的概况”,最后表达“比赛的结局”。
第三步:句子聚合 – Sentence Aggregation
不是每一条信息都需要一个独立的句子来表达,将多个信息合并到一个句子里表达可能会更加流畅,也更易于阅读。
第四步:语法化 – Lexicalisation
当每一句的内容确定下来后,就可以将这些信息组织成自然语言了。这个步骤会在各种信息之间加一些连接词,看起来更像是一个完整的句子。
第五步:参考表达式生成 – Referring Expression Generation|REG
这个步骤跟语法化很相似,都是选择一些单词和短语来构成一个完整的句子。不过他跟语法化的本质区别在于“REG需要识别出内容的领域,然后使用该领域(而不是其他领域)的词汇”。
第六步:语言实现 – Linguistic Realisation
最后,当所有相关的单词和短语都已经确定时,需要将它们组合起来形成一个结构良好的完整句子。
NLG 的不管如何应用,大部分都是下面的3种目的:
- 能够大规模的产生个性化内容
- 帮助人类洞察数据,让数据更容易理解
- 加速内容生产

四、NLP处理的三个分析层面
第一层面:词法分析
词法分析包括汉语的分词和词性标注这两部分。
- 分词:将输人的文本切分为单独的词语
- 词性标注:为每一个词赋予一个类别。类别可以是名词(noun)、动词(verb)、形容词(adjective)等;属于相同词性的词,在句法中承担类似的角色。
第二层面:句法分析
句法分析是对输人的文本以句子为单位,进行分析以得到句子的句法结构的处理过程。
三种比较主流的句法分析方法:
- 短语结构句法体系,作用是识别出句子中的短语结构以及短语之间的层次句法关系(介于依存句法分析和深层文法句法分析之间)
- 依存结构句法体系(属于浅层句法分析),作用是识别句子中词与词之间的相互依赖关系;实现过程相对来说比较简单而且适合在多语言环境下应用,但是其所能提供的信息也相对较少
- 深层文法句法分析,利用深层文法,对句子进行深层的句法以及语义分析。例如词汇化树邻接文法,组合范畴文法等都是深层文法;深层文法句法分析可以提供丰富的句法和语义信息;深层文法相对比较复杂,分析器的运行复杂度也比较高,不太适合处理大规模的数据
第三个层面:语义分析
语义分析的最终目的是理解句子表达的真实语义。语义表示形式至今没有一个统一的方案。
1. 语义角色标注(semantic role labeling)是目前比较成熟的浅层语义分析技术。
语义角色标注一般都在句法分析的基础上完成,句法结构对于语义角色标注的性能至关重要。通常采用级联的方式,逐个模块分别训练模型。
- 分词
- 词性标注
- 句法分析
- 语义分析
2. 联合模型(新发展的方法)将多个任务联合学习和解码,联合模型通常都可以显著提高分析质量,联合模型的复杂度更高,速度也更慢。
- 分词词性联合
- 词性句法联合
- 分词词性句法联合
- 句法语义联合等
五、参考文档
一文看懂自然语言处理NLP(4个应用+5个难点+6个实现步骤)
一文看懂自然语言生成 - NLG(6个实现步骤+3个典型应用) - 产品经理的人工智能学习库
人工智能导论(9)——自然语言处理(Natural Language Processing)_hustlei的博客-CSDN博客_人工智能自然语言处理


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









