







Transformer 就是一个Sequence-to-sequence (Seq2seq) 的model。
Sequence-to-sequence 的model就是 input是一个sequence,由机器自己决定output的长度
Seq2seq模型
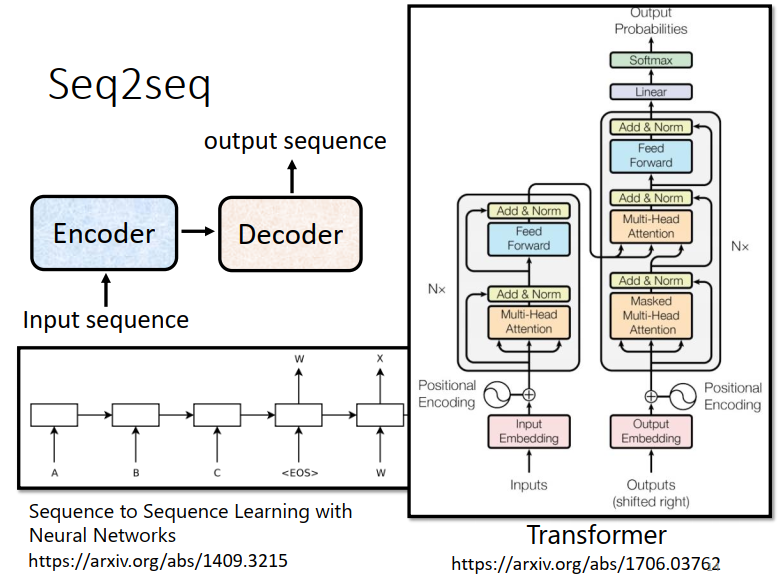
一般的Seq2seq model 它里面会分成两块,一块是Encoder一块是Decoder
input一个sequence 由Encoder 负责处理这个sequence ,再把处理好的结果丢给Decoder
由Decoder决定,它要输出什么样的sequence
Seq2seq的model起源于14年(上图左下角链接)
Encoder
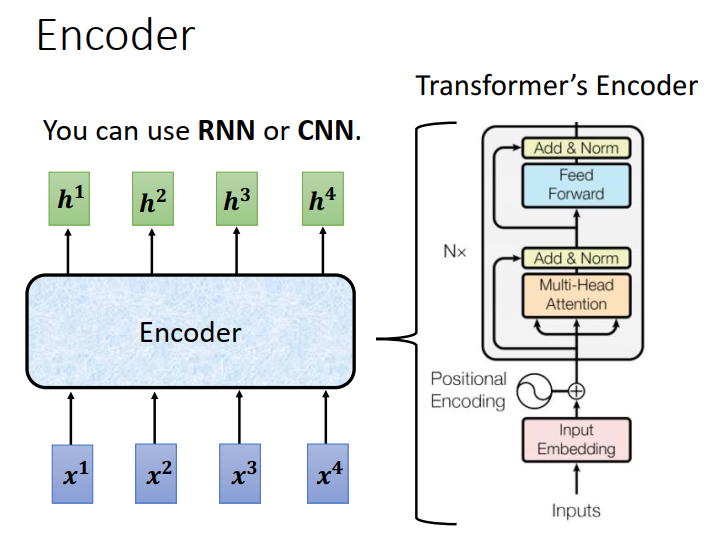
Seq2seq 的Encoder要做的事情就是给一排向量输出另外一排向量。
这件事情很多模型都可以做,比如self-attention,RNN,CNN都可以做到
Transformer的Encoder用的就是self-attention,上图左半部分就是了。
具体如下:
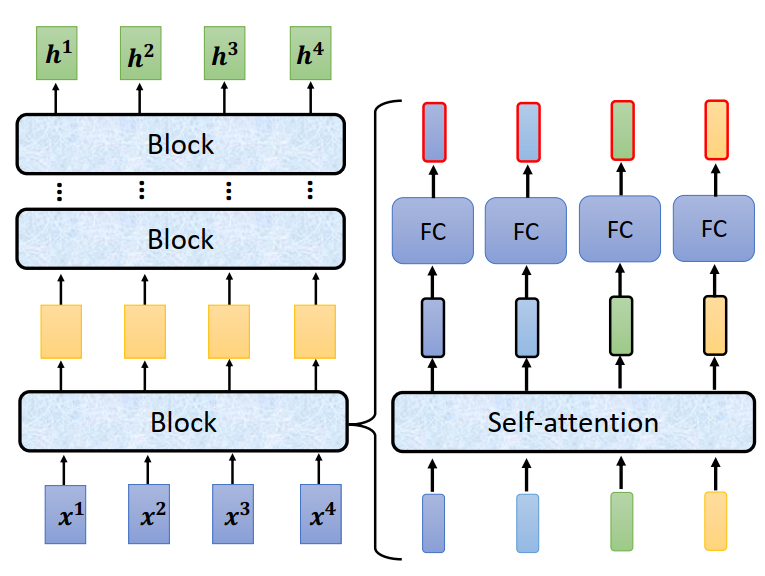
Encoder里面会分成很多很多的Block,每一个block都是输入一排向量,输出一排向量
每一个block其实并不是neural network的一层,之所以不说每一个block是一个layer是因为每一个block做的事情是好几个layer在做的事情。
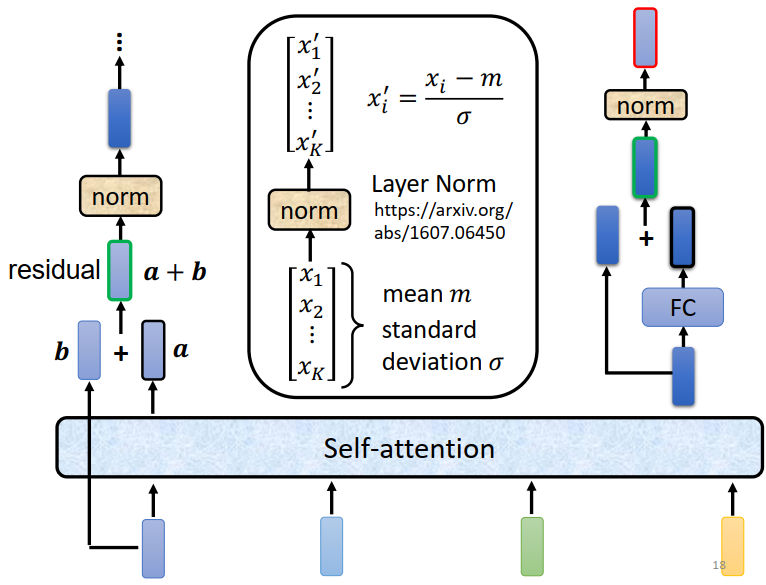
Encoder的block是先做一个self-attention input一排vector以后考虑整个sequence的资讯 output另外一排vector,这排vector在丢到fully connected的feed forward network里面,output另外一排vector ,这排vector就是block的输出。
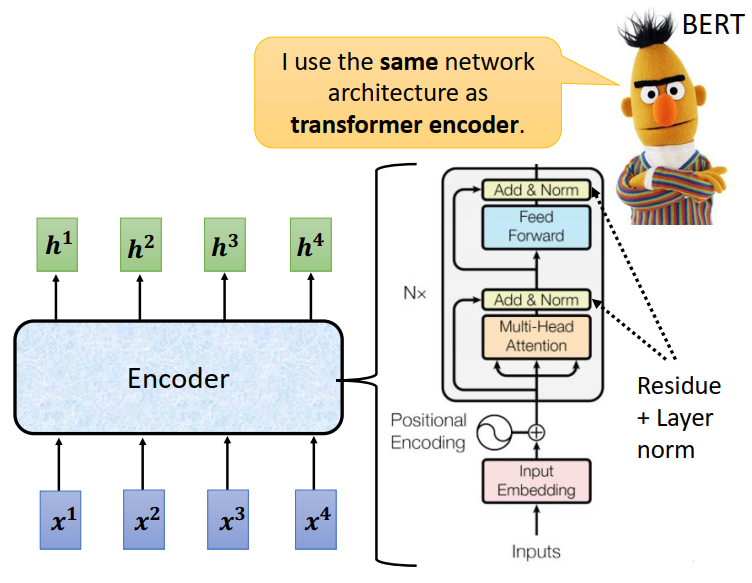
这个复杂的block在BERT里面会在用到,BERT其实就是Transformer的Encoder。
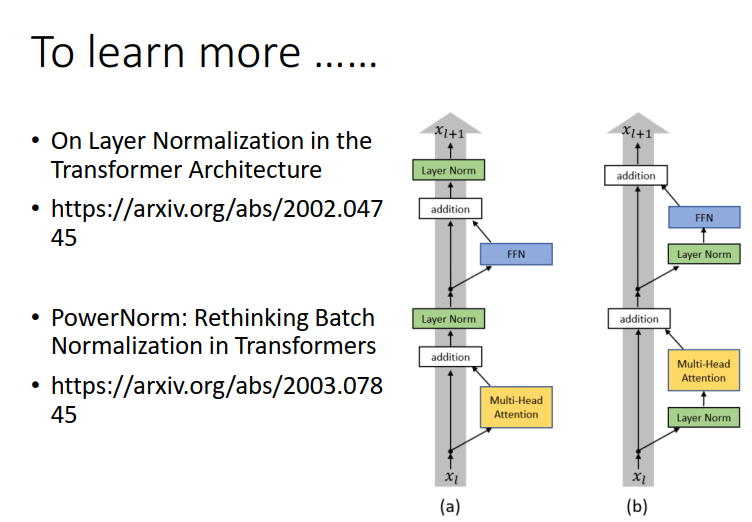
Encoder的network架构设计还有其他方式…
Decoder
Autoregressive(AT)
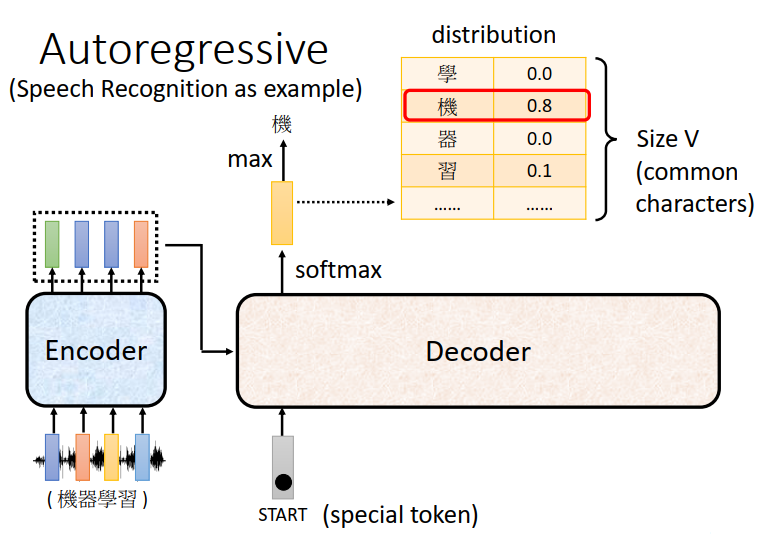
Decoder其实有两种,下面重点介绍比较常见的Autoregressive的Decoder。
以语音辨识为例:
你会把一段声音输入Encoder,声音讯号进入Encoder以后,输出会变成一排Vector
接下来Decoder产生这个语音辨识的结果。
Decoder做的事情就是把Encoder的输出先读进去,然后产生一段文字
首先你要给他一个特殊的符合(special token),代表着开始。(表示成一个one-hot的vector)
Decoder会吐出一个向量,它的长度跟你的Vocabulary的size是一样的。
举例来说,如果你觉得这个Decoder能够输出常见的3000个方块字就好了,那你就把他列在这个位置。
在产生这个向量之前还会跑一个softmax(softmax的意义:对向量进行归一化,凸显其中最大的值并抑制远低于最大值的其他分量。)跟做分类一样,在得到结果之前先跑一个softmax,所以这个向量里面的分数它是一个distribution。
得到这个向量还不是最终结果,这个向量会给每一个中文的字一个分数,分数最高的那个中文字它就是最终的输出,在这个例子里面分数最高的就是“机”。
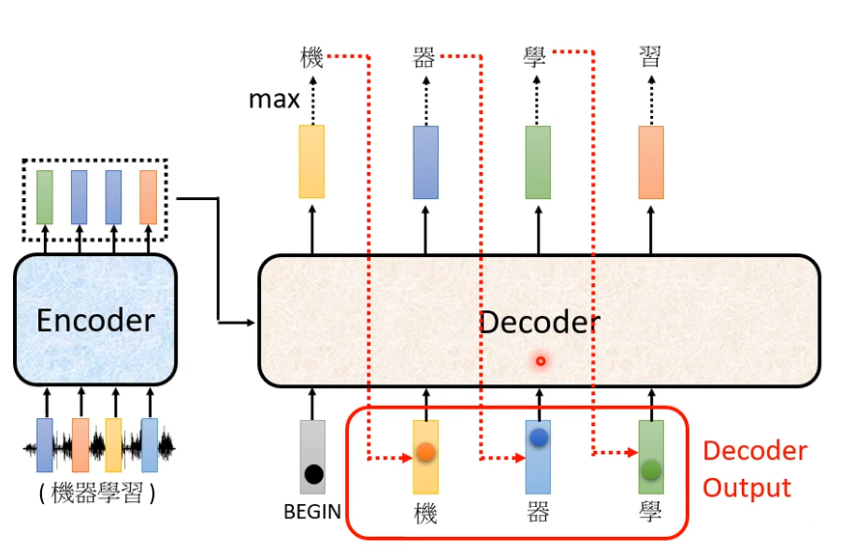
接下来 你把“机”当做Decoder新的input,原来Decoder的input只有start这个特殊的符合,现在除了这个开始符合,它还有“机”作为它的input(都表示成一个one-hot的vector),所以Decoder现在有两个输入,根据这两个输入它就要得到一个输出(蓝色的向量),根据这个蓝色向量里面的分数,在决定第二个输出是什么,Decoder接下来会拿“器”当做输入 ,现在就是三个输入…这一过程就反复进行下去。
有一个关键的地方已经用红色虚线标出来:Decoder看到的输入其实是它在前一个时间点自己的输出。
所以当Decoder在产生一个句子的时候,它是有可能看到错误的东西。比如把机器的“器”看成是天气的“气”
那这样会不会造成Error Propagation(一步错,步步错)的问题呢?
有一个思路是给Decoder的输入加一些错误的东西,这一招叫做Scheduled Sampling
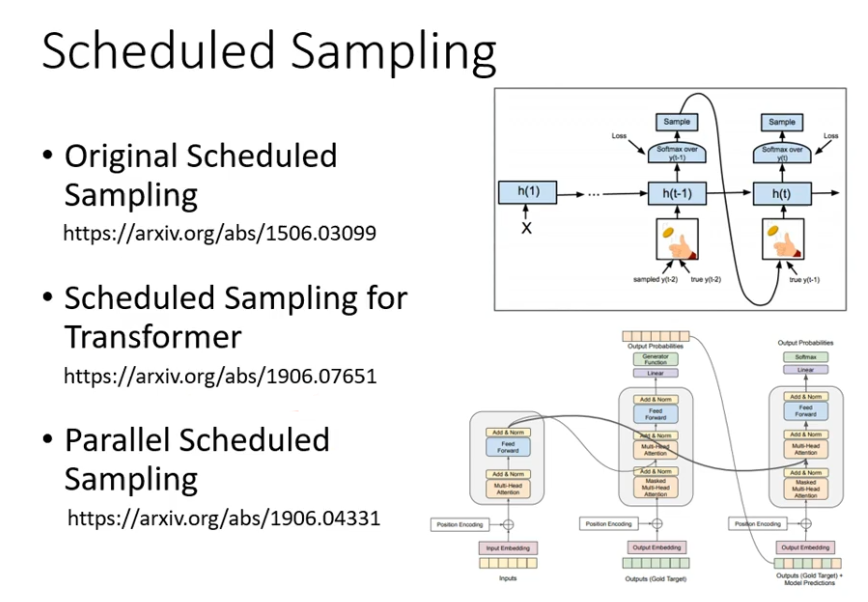
Decoder的内部结构:
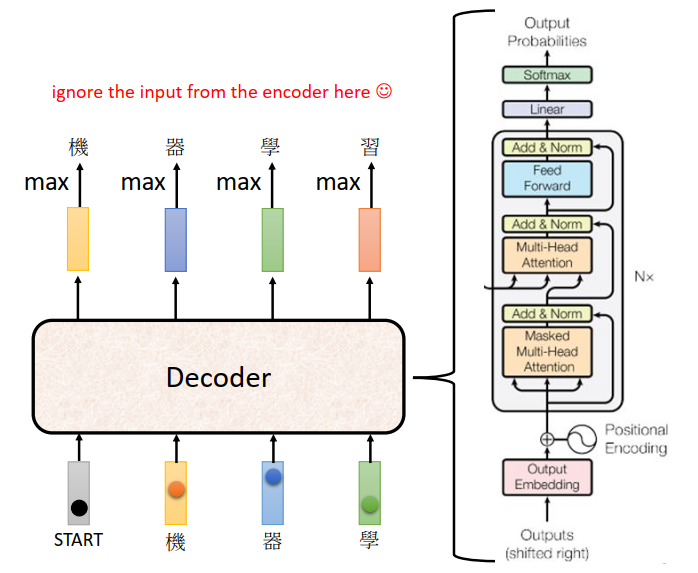
我们把Encoder和Decoder放在一起对比一下。
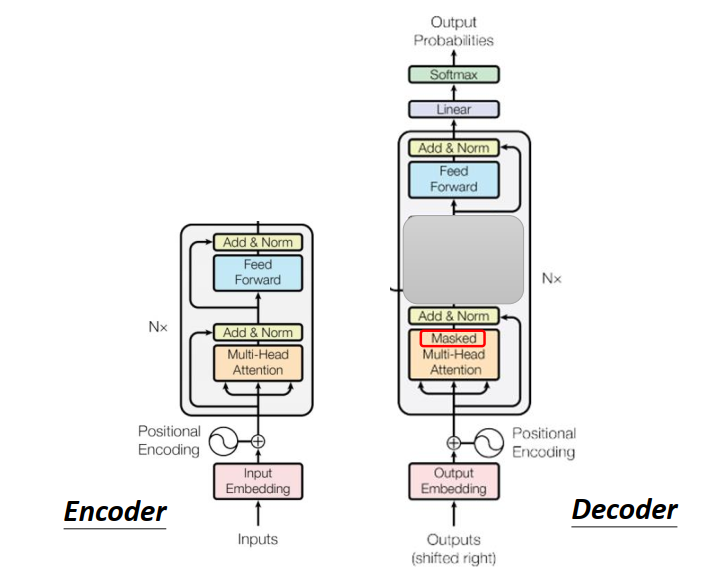
如果我们把Decoder中间这一块盖起来,其实Encoder跟Decoder并没有那么大的差别
稍微不一样的地方是Multi-Head Attention这一个Block上面还加了一个Masked。
这个Masked如下:
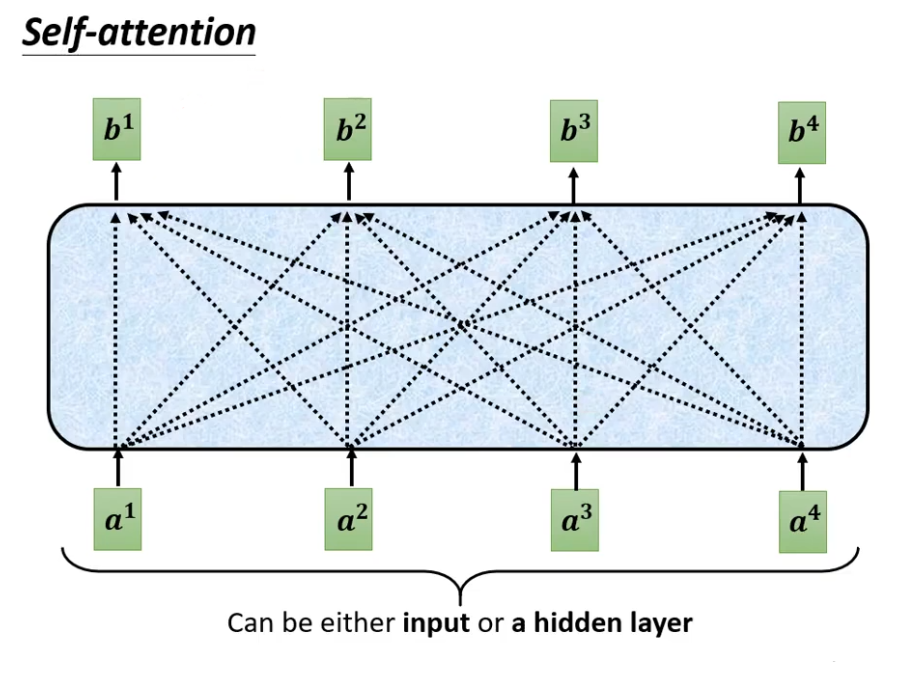
这是我们原来的self-attention,这一排Vector每一个输出,都要看过完整的Input以后才做决定。
输出的b1的时候,是根据a1到a4所有的资讯去输出b1。
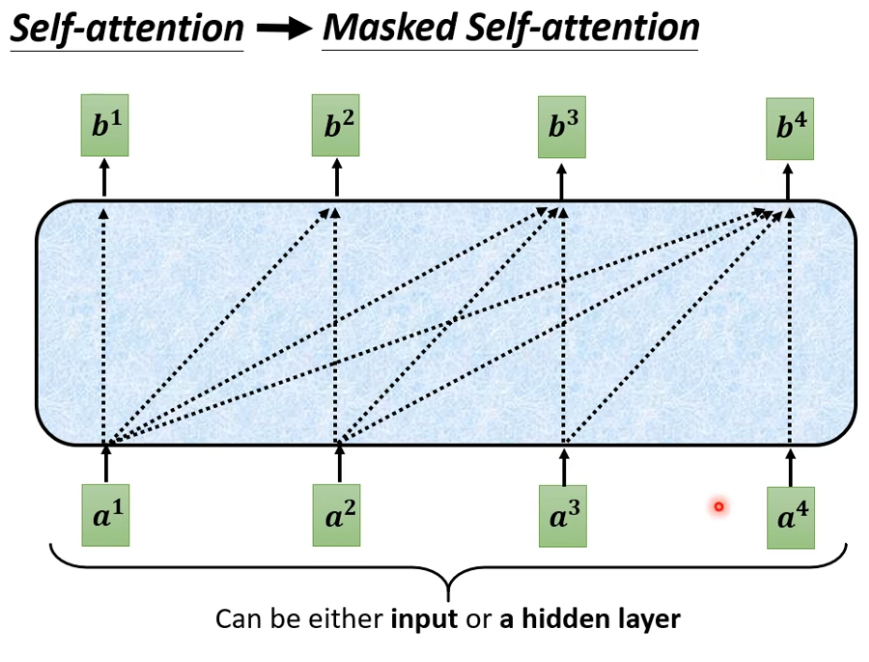
当我们把self-attention转成 Masked Attention的时候,它的不同点在哪里呢?
不同点是:现在我们不能再看右边的部分。
产生b1的时候,不能再考虑a2 a3 a4了;
产生b2的时候,只能考虑a1 a2的资讯,不能再考虑a3 a4 了
为什么需要加Masked呢?
因为decoder的运作方式,它是一个一个输出的,是先有a1 再有a2
原来的self-attention,a1至a4是一次整个读进model里面的。
Encoder是一次把a1到a4整个都读进去。
但是对Decoder而言,先有a1 再有a2 才有a3 才有a4
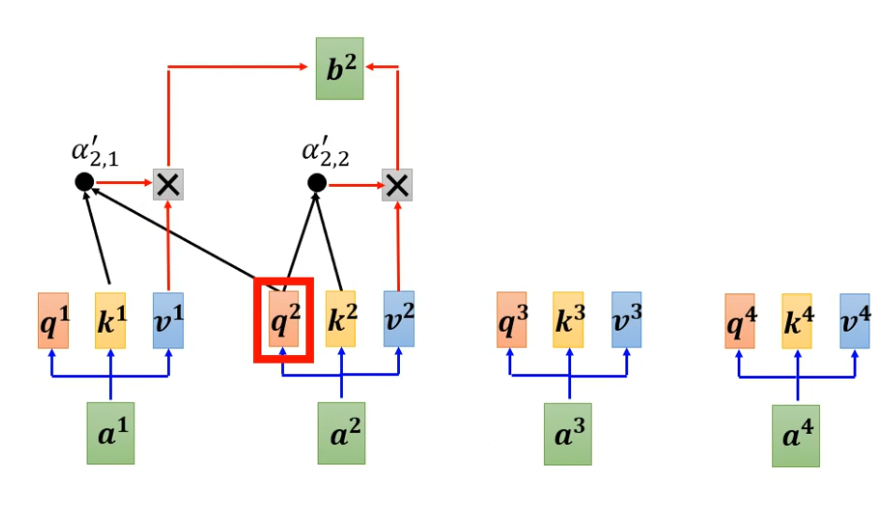
所以实际上当你有a2 你要计算b2的时候,你是没有a3 跟a4的。
这就是为什么在Decoder的Multi-Head Attention这一个Block上面还加了一个Masked的原因。
还有一个关键的问题:Decoder必须自己决定输出的长度。
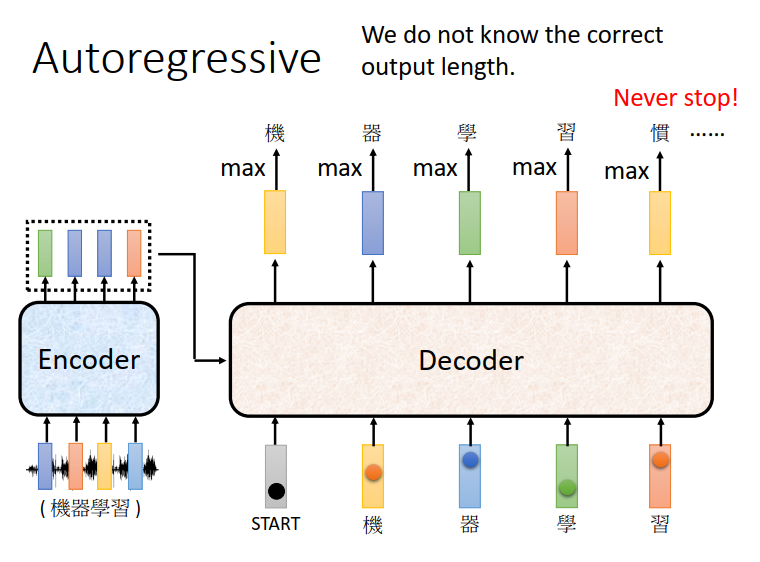
我们期待机器自己能学到,但在目前的运作机制里面机器根本不知道它什么时候应该停下来。
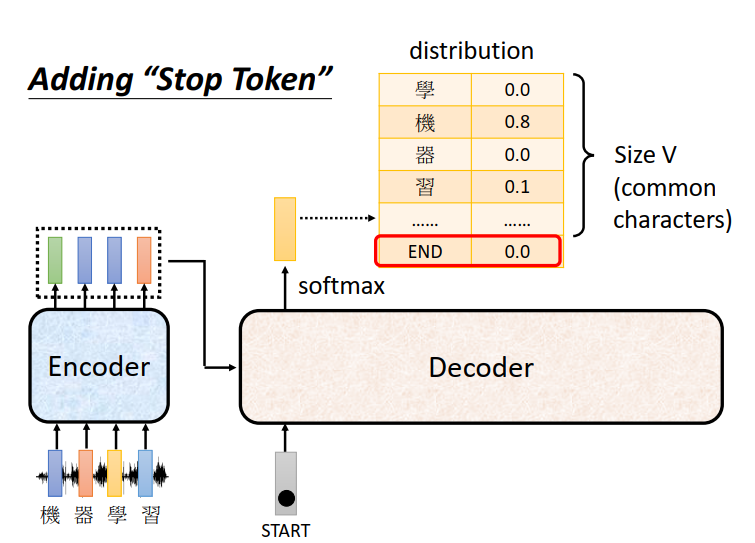
所以我们要特别准备一个符号,就叫做断 我们用END来表示这个特殊的符合。
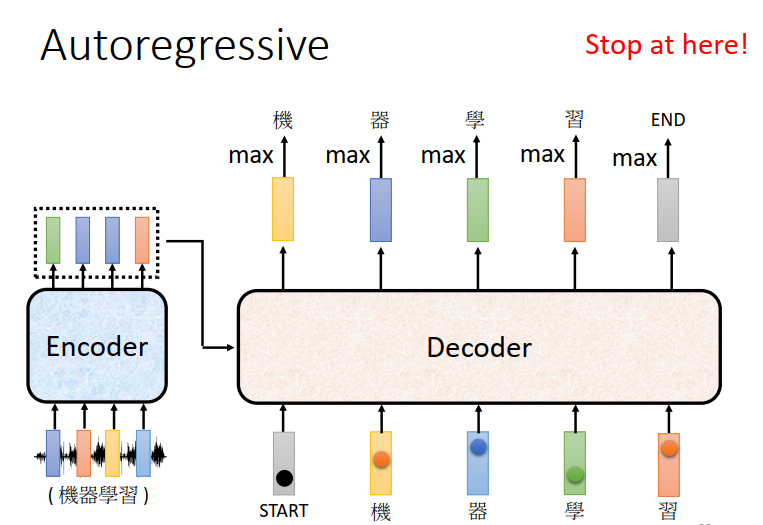
我们期待 当把“习”当做输入以后 ,Decoder看到Encoder输出的这个Embedding ,看到“STAET” “机” “器” “学” “习 ” 后,它就知道这个语音辨识的结果已经结束了。
Non-autoregressive(NAT)
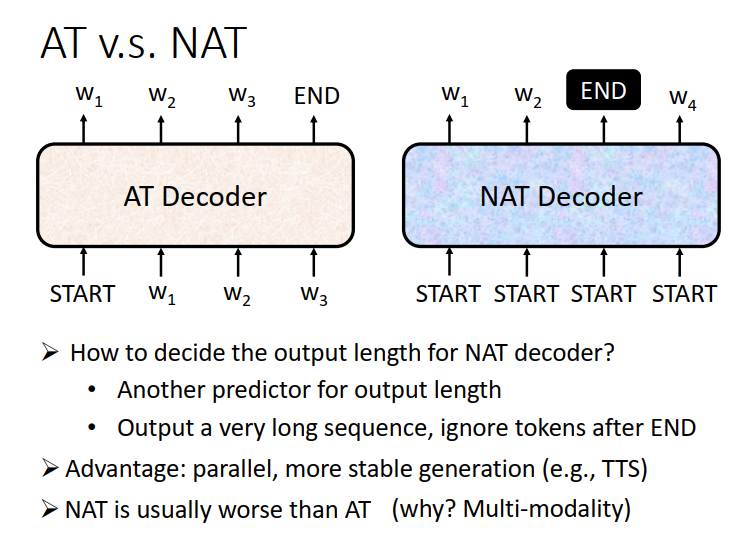
NAT不是一次产生一个字,它是一次把整个句子都产生出来,有多少个START就产出多少个字。
问题来了,怎么确定输出长度该是多少呢?
方案1:另外learn一个classifier,它吃Encoder的input,输出是一个数字,代表Decoder应该要输出的长度。
方案2:直接给它一堆START的token,比如现在你知道输出结果绝对不会超过300个字,你就给它300个START,再看看什么地方输出了END,输出END的右边,就当做它没有输出就结束了。
==好处:==平行化(并行)比较快 在速度比AT的Decoder跑的快;比较能够控制输出的长度
如果你在做语音合成的时候,你现在突然想要让你的系统讲快一点 加速 那你就可以把那个Classifier(方案一)的output除以二 讲话速度就变两倍快了。
坏处:但是performance并没有AT的好。
接下来介绍刚才 盖起来这一块。
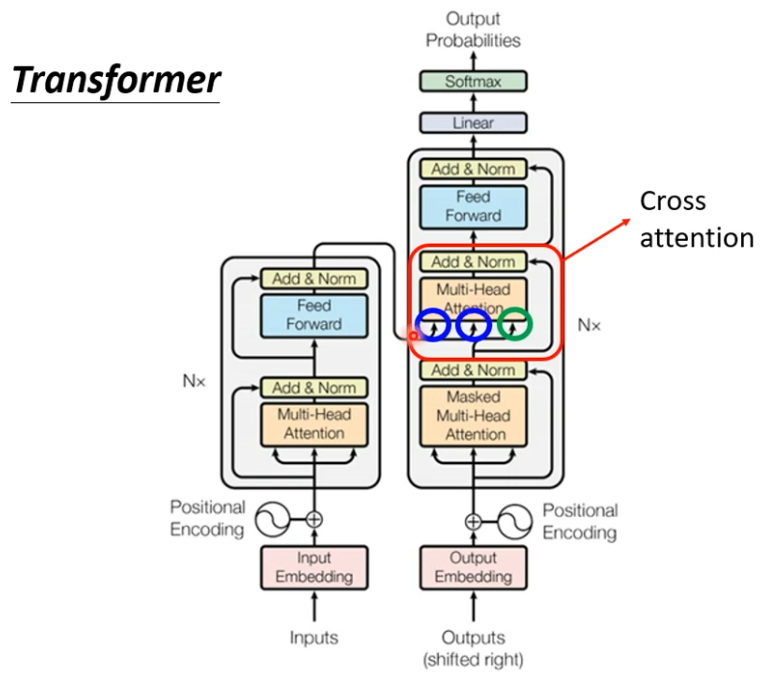
这一块叫做Cross Attention,它是连接Encoder 跟Decoder之间的桥梁。
有两个输入来自Encoder 一个输入来自Decoder
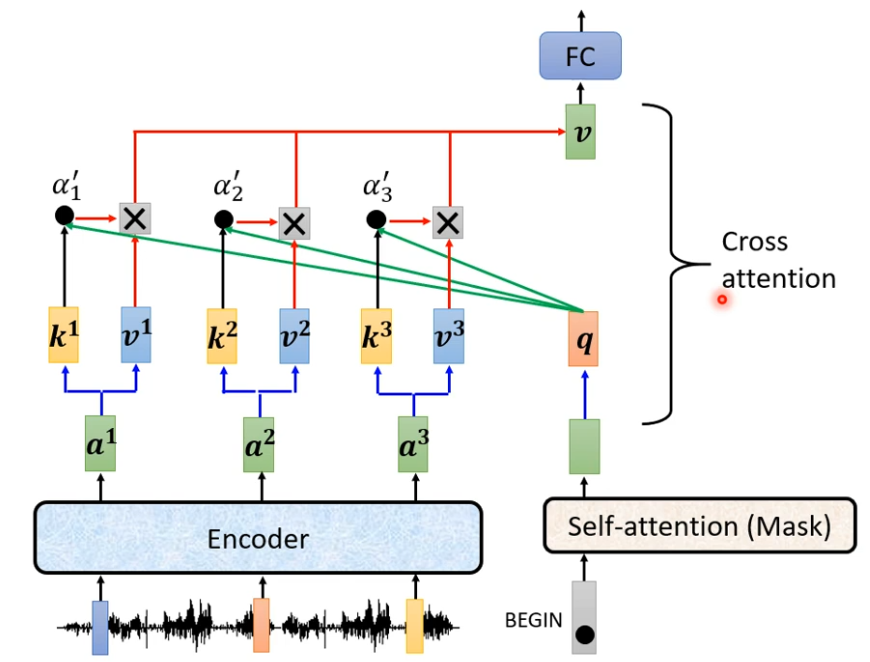
Decoder就是凭借着产生一个q 去Encoder抽取资讯出来,当做接下来的Decoder里面的Fully-Connected的Network的input。
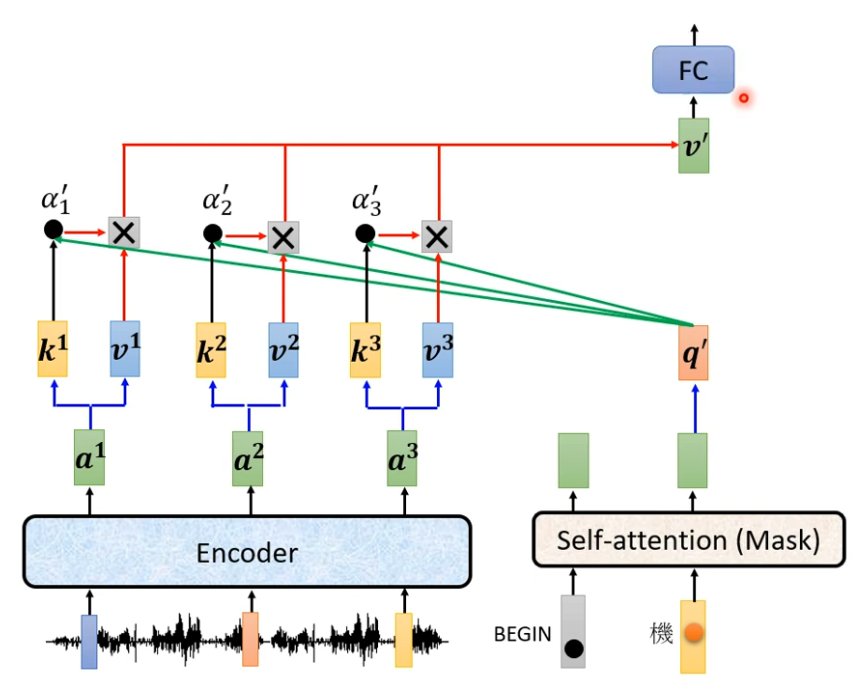
接下来的动作都是一样的。
我们已经讲了Encoder 讲了Decoder 讲了Encoder Decoder怎么互动,已经清楚了input一个Sequence 是怎么得到最终的输出。
接下来就进入训练的部分:
训练资料是什么样的呢?
收集一大堆声音讯号,每个声音讯号都要有人工来标记出他这个对应的词汇是什么
怎么让机器学习到这件事呢?
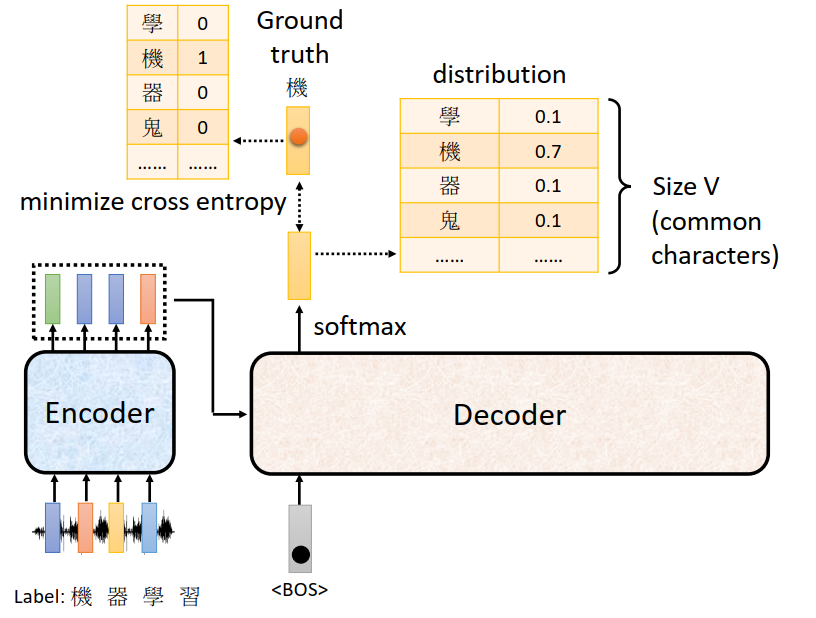
比如这段声音讯号,第一个应该要输出的中文是“机”
所以当我们把START丢给这个Decoder的时候,它第一个输出应该跟“机”越接近越好
“机”这个字被表示成一个one-hot 的vector 在这个vector里面只有“机”对应的那个维度是1。
我们的Decoder的输出是一个概率的分布,我们希望这个分布分这个one-hot 的vector 越接近越好 。计算Ground truth跟distribution的Cross Entropy ,希望这个Cross Entropy的值越小越好
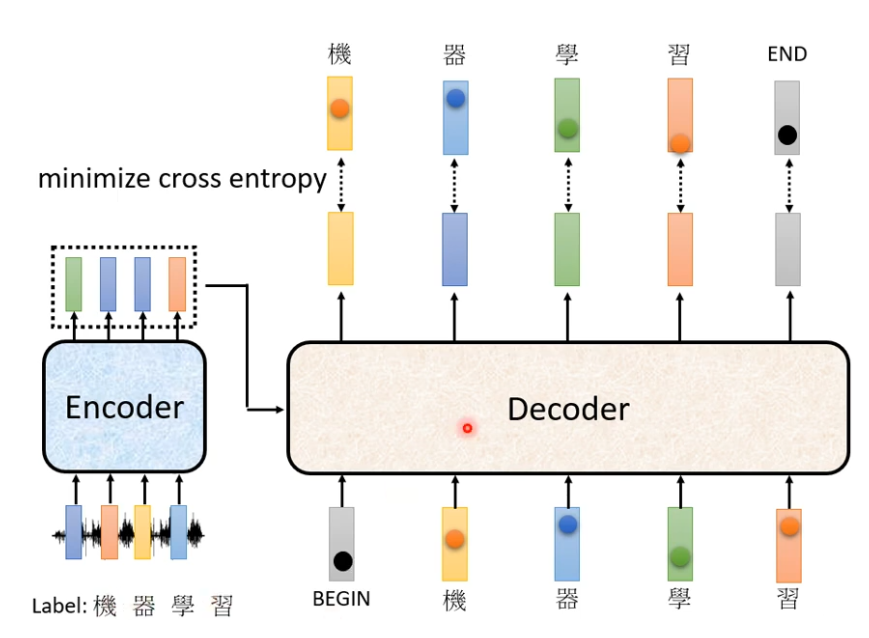
我们希望它综合起来的Cross Entropy越小越好。
假设今天只有机器学习这四个字,但不要忘了还有END,所以Decoder的输出不只是四个中文字,还要叫它记得说四个中文字输出完以后,还要记得输出断 这个特别的符号的vector 要与正确的END的vector Cross Entropy越小越好。
Seq2seq的应用
有什么样的应用是Seq2seq的model呢?
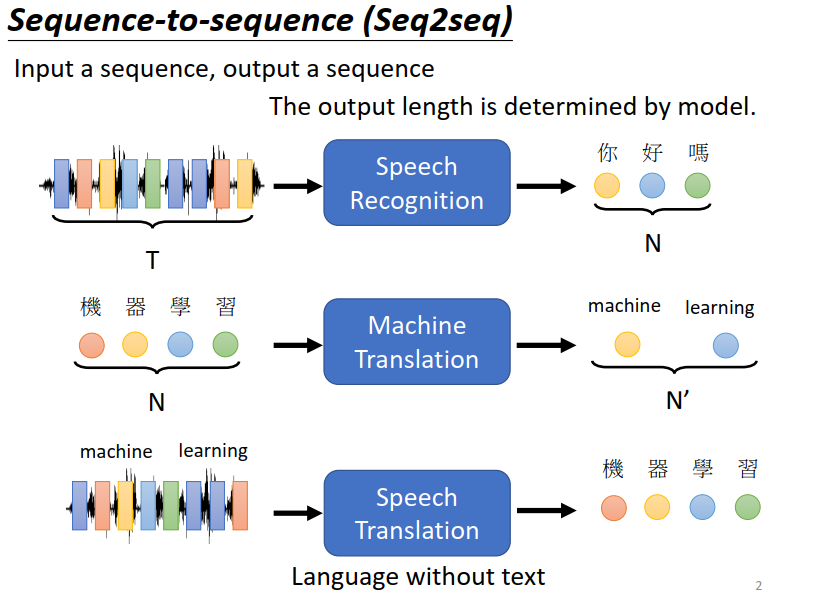
举例来说一个很好的应用,就是语音辨识 输入是声音讯号,输出是语音辨识的结果
输入和输出的长度是有一些关系,但是却没有绝对的关系,由机器自己决定要输出多少字。
还有机器翻译,和语音翻译
你可能会说,有了语音辨识和机器翻译,把它俩接起来不就好了 为什么还要语音翻译呢?
这是因为世界上有很多语音,根本连文字都没有,世界上有超过七千种语言,其中有超过半数是没有文字的。对这些没有文字的语言,根本没办法做语音辨识,因为它没有文字。
但我们有没有可能对这些语言做语音翻译,直接把它翻译成我们有办法阅读的文字。
另外在文字上也很广泛的应用了Seq2seq
举例来说你可以用一个Seq2seq的model来训练一个聊天机器人。
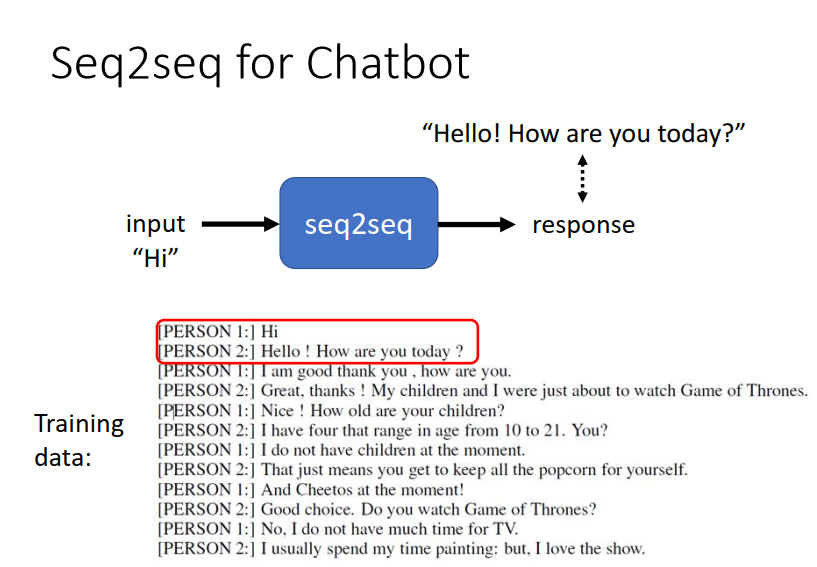
Seq2seq在NLP的应用更为广泛
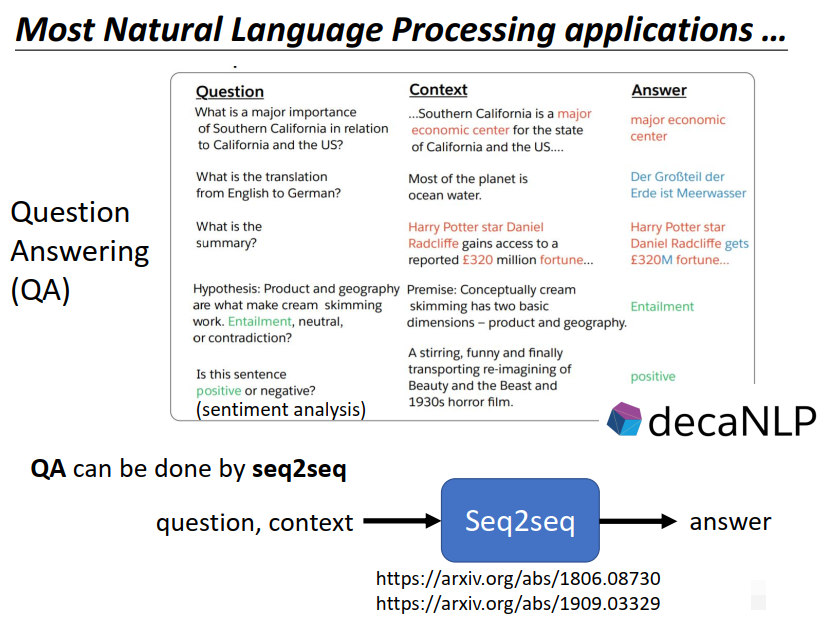
因为很多NLP的任务都可以想成是question answering的任务。
所谓question answering就是给机器读一段文字,然后你问机器一个问题,希望他可以给你一个正确的问题。
很多你觉得跟QA没什么关系的任务都可以想成是QA。
举例来说,假设你想做的翻译,做自动摘要,做sentiment analysis…
QA的问题又可以用seq2seq的model来解,输入是问题和文章,输出是答案。
所以但是对各式各样的NLP的任务,其实都有机会使用Seq2seq model来解。
但是,对多数NLP的任务,往往为这些任务做客制化模型,你会得到更好的结果。
(就好比瑞士刀什么都能做,但不一定最好用)
其实还有很多应用你不觉得他是一个Seq2seq model的问题,但你可以用Seq2seq model的问题硬解它,举例来说:文法解析
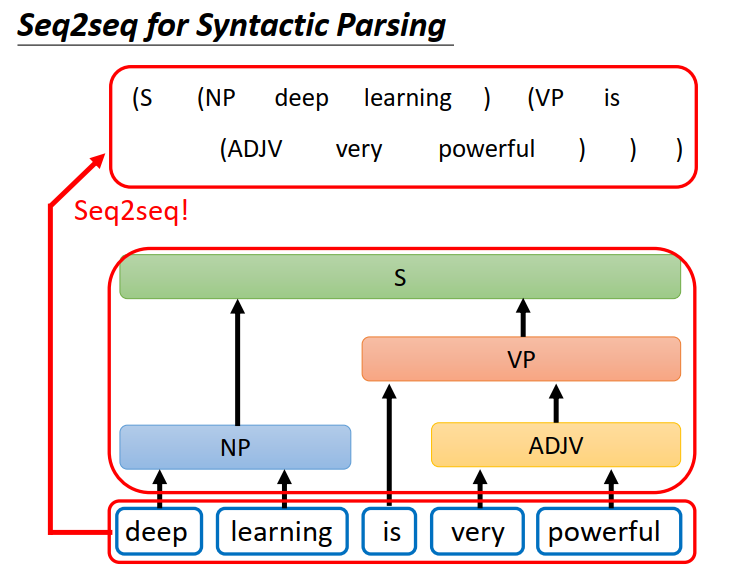
文法解析要做的就是给机器一段文字,机器要做的问题是产生一个文法的剖析树 告诉我们其各个词汇含义。输出看起来不像是一个sequence,但事实上一个树状的结构,可以硬是把它看做是一个sequence,如上图所示 (paper链接:https://arxiv.org/abs/1412.7449 ) 。
还有一些任务可以用seq2seq的model,举例来说multi-label 的Classification。
multi-class Classification跟multi-label Classification听起来很像,但他们其实是不一样的事情。
multi-class Classification是说我们有不只一个class,机器要做的事情从数个class里面选择某一个class出来。
multi-label Classification是说同一个东西,它可以属于多个,不只一个class。
举例来说 文章分类就是一个multi-label Classification 同一个文章可能属于多个class
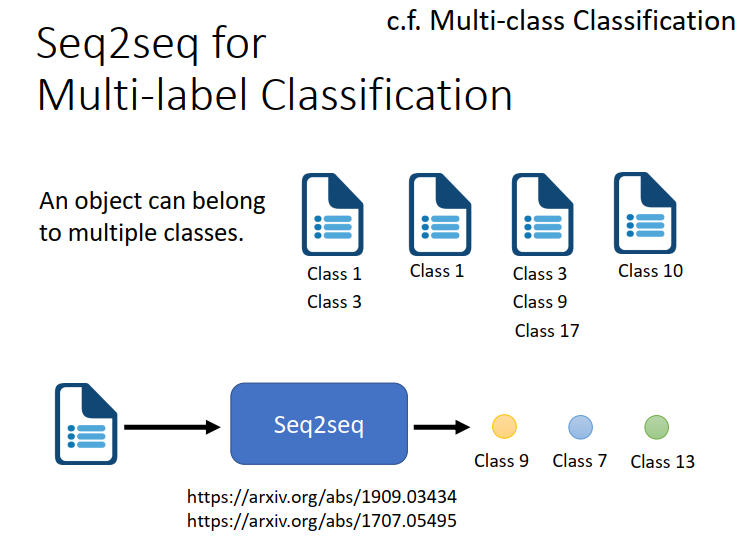
可以用seq2seq硬做,输入一篇文章 由机器自己决定输出几个class。
讲了这么多 就是为了说明它是一个很有用的model。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











