







 文章讲述了如何通过在Playwright中使用`stealth.min.js`库和调整headless浏览器设置来隐藏webdriver属性,以防止网站检测到自动化工具并限制信息获取。作者展示了两种方法:一是修改navigator.webdriver属性为假,二是使用无界面浏览器并调整User-Agent和视口大小。
文章讲述了如何通过在Playwright中使用`stealth.min.js`库和调整headless浏览器设置来隐藏webdriver属性,以防止网站检测到自动化工具并限制信息获取。作者展示了两种方法:一是修改navigator.webdriver属性为假,二是使用无界面浏览器并调整User-Agent和视口大小。
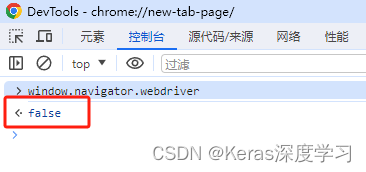
现在很多网站为了保护信息不被爬取,添加了一些防护手段,比如直接打开谷歌浏览器,在控制台输入window.navigator.webdriver,可以看到该属性为false
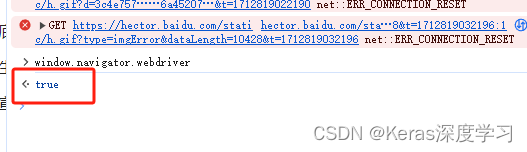
当用selenium或者playWright打开浏览器,该属性为true
因此网站很容易在前端根据这些属性判断是否使用了playwright,从而阻止用户采用自动化工具获取信息,那么如何屏蔽掉这些属性,让网站无法识别是否使用了playwright了。
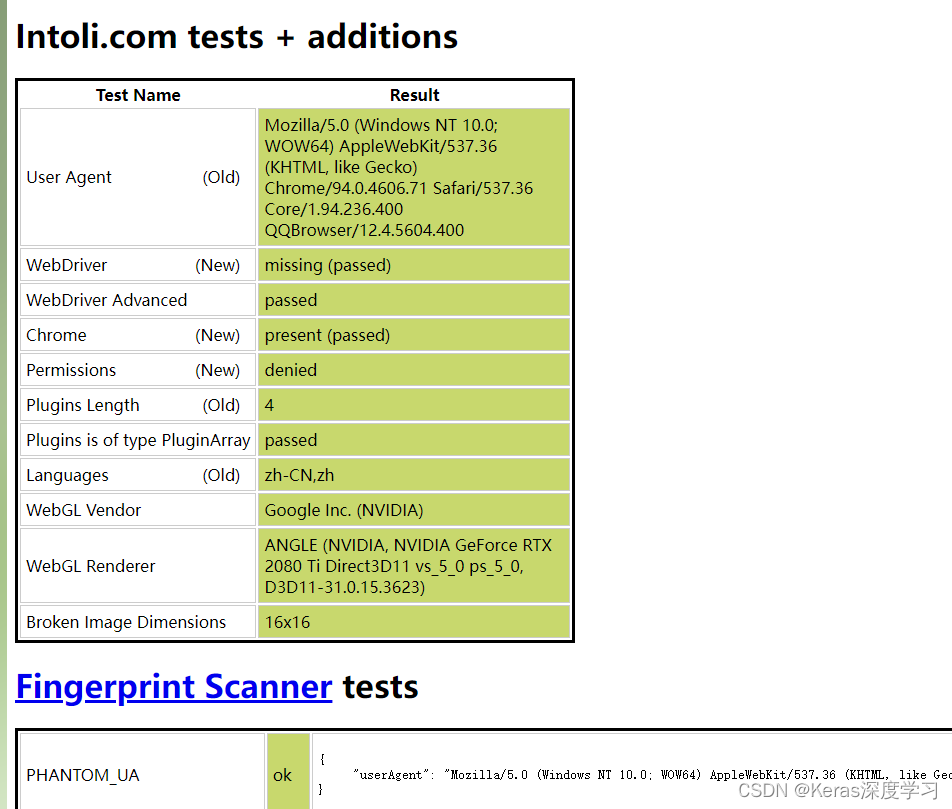
我们用浏览器打开这个网站https://bot.sannysoft.com/,这个网站列出了常用的一些检测属性,下图是直接打开浏览器这个网站显示的一些特性
当用playwright打开这个网站,代码如下:
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as p:
'''
防止被浏览器检测的处理方法
'''
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://bot.sannysoft.com/')
time.sleep(100)
browser.close()
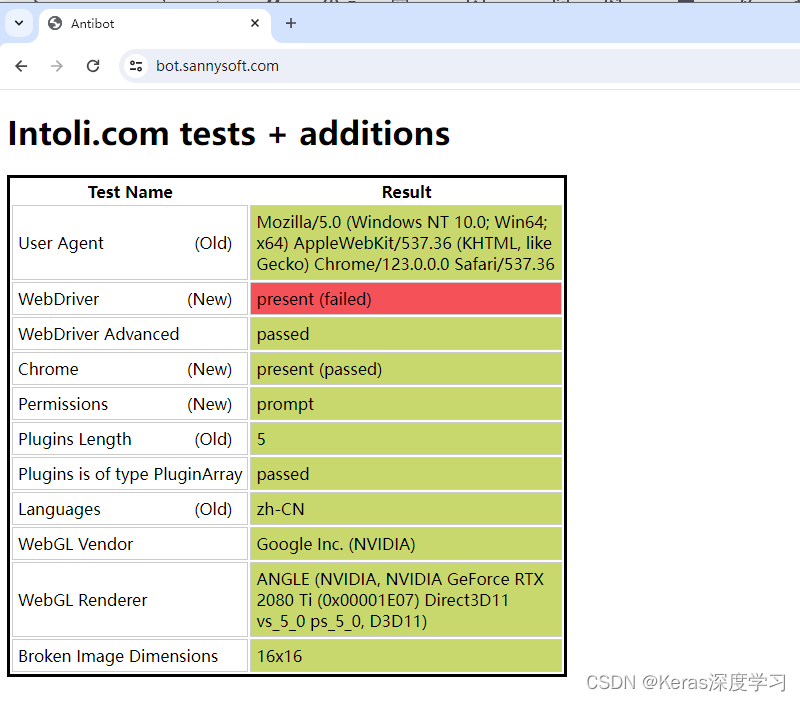
发现webdriver果然没有通过。
1 防止webdriver被检测
第一种写法:
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as p:
'''
防止被浏览器检测的处理方法
'''
browser = p.chromium.launch(headless=False)
page = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2633
2633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











