1.下载
结巴分词包下载地址:http://download.csdn.net/detail/robin_xu_shuai/9691188
2.安装
将其解压到任意目录下,然后打开命令行进入该目录执行:python setup.py install 进行安装
(放到任意目录执行安装即可,setup.py会帮你安装到相应位置)
3.测试
安装完成后,进入python交互环境,import jieba 如果没有报错,则说明安装成功。如下图所示
4.使用
(1)分词
结巴分词支持3中分词模式:
1,全模式:把句子中的所有可以成词的词语都扫描出来,
2, 精确模式:试图将文本最精确的分开,适合于做文本分析。
3,搜索引擎模式:在精确的基础上对长词进行进一步的切分。
函数jieba.cut接受两个输入参数,第一个是将要分词的对象,第二个是采用的模式。该函数返回的是一个可以迭代的generator, 可以使用for循环得到分词后得到的每一个词语。
示例:
-
- import jieba
-
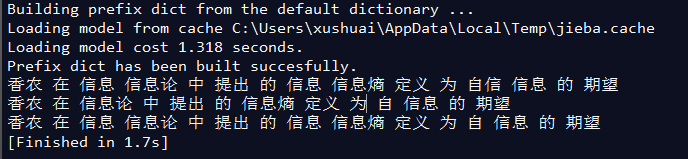
- seg_list = jieba.cut("香农在信息论中提出的信息熵定义为自信息的期望", cut_all=True)
- print(" ".join(seg_list))
- seg_list = jieba.cut("香农在信息论中提出的信息熵定义为自信息的期望")
- print(" ".join(seg_list))
-
- seg_list = jieba.cut_for_search("香农在信息论中提出的信息熵定义为自信息的期望")
- print(" ".join(seg_list))
其分词的结果分别为:
(2)添加自定义词典
用户可以添加自定义的词典来包含结巴词库中没有的词。(在以上示例中没有分出“自信息”这个词)
用法: jieba.load_userdict("userdict1.txt")
在文件userdict1.txt中添加以下的内容:自信息 5
- import jieba
- import jieba.analyse
- jieba.load_userdict("userdict1.txt")
-
- seg_list = jieba.cut("香农在信息论中提出的信息熵定义为自信息的期望", cut_all=True)
- print(" ".join(seg_list))

(原来识别不出来的“自信息”现在可以了)
(3)提取关键词
用法:tags = jieba.analyse.extract_tags("sentence", topK=k),其中topK默认值是20
在关键词提取时,可以添加停用词:jieba.analyse.set_stop_words("extra_dict/stop_words.txt"),目的是将一些没有意义的词去掉。
- import jieba
- import jieba.analyse
- jieba.load_userdict("userdict1.txt")
- jieba.analyse.set_stop_words("extra_dict/stop_words.txt")
-
- seg_list = jieba.cut("香农在信息论中提出的信息熵定义为自信息的期望", cut_all=True)
- print(" ".join(seg_list))
- print('关键词提取的结果如下:')
- tags = jieba.analyse.extract_tags("香农在信息论中提出的信息熵定义为自信息的期望", topK=10)
- print(",".join(tags))

(4)实例:对文件进行分词
-
-
- import jieba
- import jieba.analyse
- jieba.load_userdict("userdict1.txt")
- jieba.analyse.set_stop_words("extra_dict/stop_words.txt")
-
- def splitSentence(inputFile, outputFile):
- fin = open(inputFile, 'r', encoding='utf-8')
- fout = open(outputFile, 'w', encoding='utf-8')
- for line in fin:
- line = line.strip()
- line = jieba.analyse.extract_tags(line)
- outstr = " ".join(line)
- print(outstr)
- fout.write(outstr + '\n')
- fin.close()
- fout.close()
-
- splitSentence('input.txt', 'output.txt')
详细使用请见另一篇文章:python中结巴分词快速入门
























 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











