







简洁版可以按照这个回答:
1. 浏览器根据请求的 url 交给 dns 域名解析,找到真实的 ip, 向服务器发送请求;
2. 服务器交给后台处理完成后返回数据,浏览器接收文件( html, js, css,图像等);
3. 浏览器对加载到的资源( HTML, JS, CSS等)进行语法解析,建立对应的内部数据结构(如 HTML 的DOM );
4. 载入解析到的资源文件,渲染页面,完成
简易流程分析图:

常见的http请求方法区别
这里主要展示 POST 和 GET 的区别
基本区别
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST么有
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中。
重点区别
GET会产生一个TCP数据包,而POST会产生两个TCP数据包。详细的说就是
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
注意一点,并不是所有的浏览器都会发送两次数据包,Firefox就发送一次重点区别
更重要的事情-HTTP缓存
http缓存是客户端缓存, 我们常认为浏览器有一个缓存数据库,用来存放静态文件,
下面我们分为以下几个方面来简单介绍HTTP缓存
- 缓存的规则
- 缓存的方案
- 缓存的优点
- 不同刷新的请求执行过程
1: 缓存规则:
缓存规则分为: 强缓存 和 协商缓存
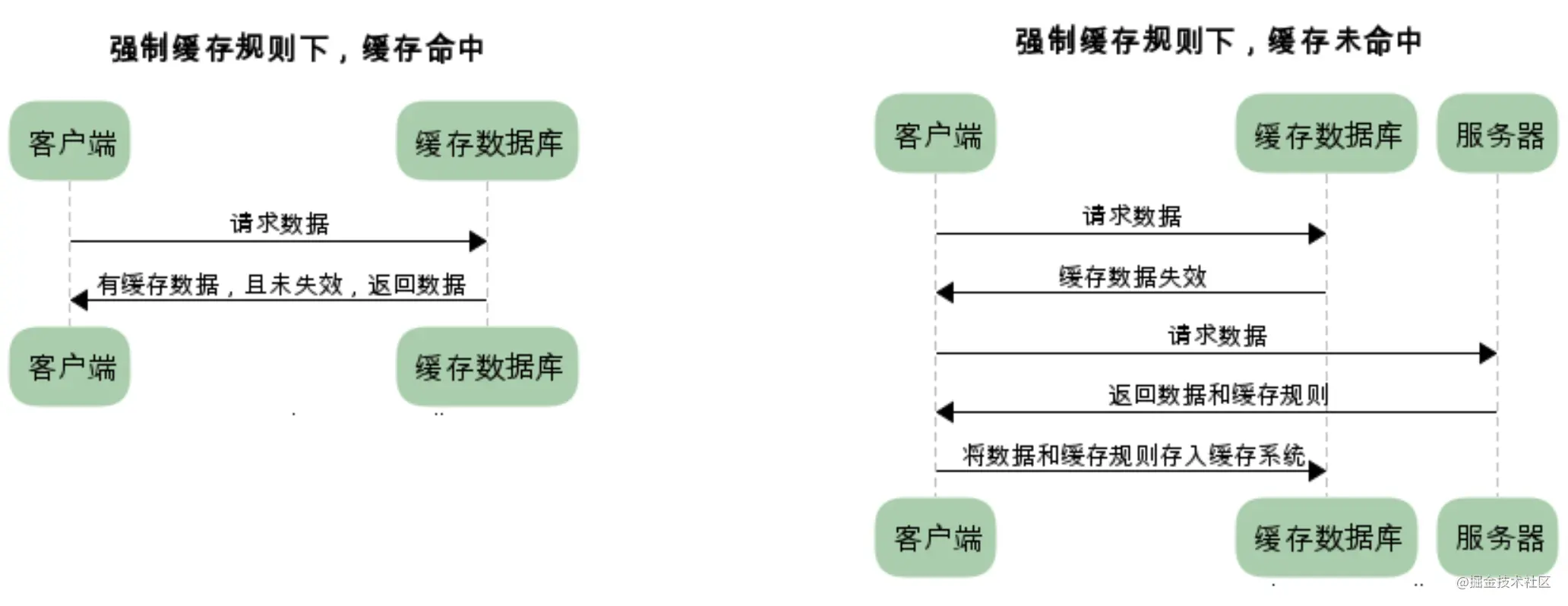
强缓存:
当 缓存数据库 中有 客户端需要的数据 时,客户端会从直接从缓存数据库中取数据使用【如果数据未失效】 ,当缓存数据库中没有 客户端需要的数据时,才会向服务端发送请求。
协商缓存:
客户端会先从缓存数据库拿一个缓存的标识,然后向服务端验证标识是否失效,如果没有失效,服务端会返回304,客户端会从直接去缓存数据库拿出数据, 如果标识失效,服务端会返回新的数据,
需要对比判断是否可使用缓存,浏览器第一次请求数据时,服务端就将 缓存标识 和数据一起返回给客户端,客户端将他们备份至缓存中,再次请求时,客户端会将缓存中的标识发送给服务端,服务端根据此标识判断,若未失效,返回304状态码,浏览器拿到此状态码可直接使用缓存数据
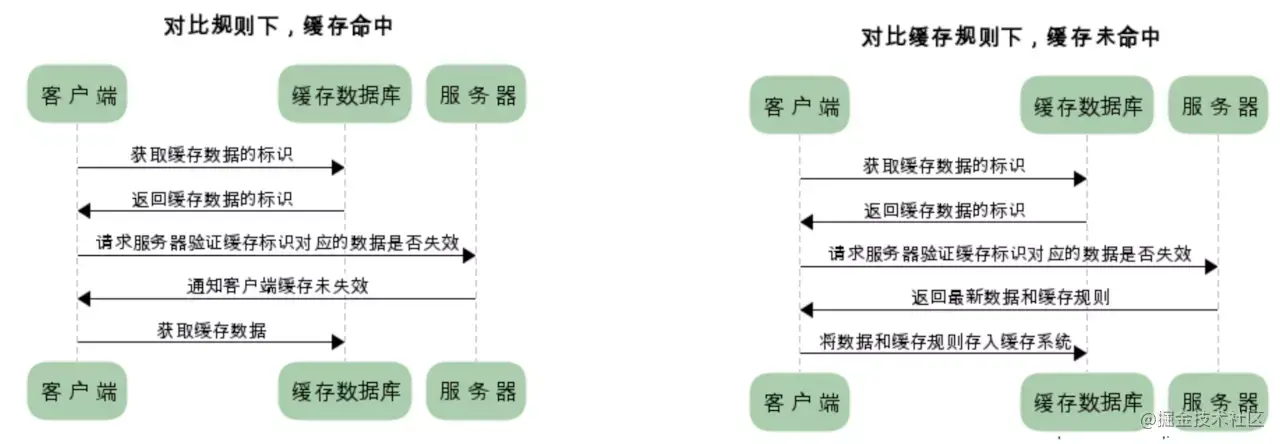
强制缓存 的优先级高于 协商缓存,若两种缓存皆存在,且强制缓存命中目标,则协商缓存不再验证标识。
2: 缓存的方案
服务器是如何判断缓存是否失效呢???
彻底理解浏览器的缓存机制 和 服务端到底是咋 判断缓存是否失效的呢???
我们知道浏览器和服务器进行交互时,会发送一些请求数据和响应数据,我们称为HTTP报文.
报文中包含 首部 header 【存放与缓存相关的规则信息】和 主体部分 body【存放http请求真正要传输的部分】 。
我们分别以。强缓存 和 协商缓存 来分析
强缓存:当浏览器向服务器发起请求时,服务器会将缓存规则放入 HTTP响应报文的HTTP头(response中) 中和请求结果一起返回给浏览器,
如何开启强缓存:设置强制缓存的字段分别是: Expires 和 Cache-Control,它俩可以在 服务端配置(且可同时启用),同时启用的时候 Cache-Control 优先级高于 Expires
Expires:是HTTP/1.0控制网页缓存的字段,其值为服务器返回该请求结果缓存的到期时间,即再次发起该请求时,如果客户端的时间小于Expires的值时,直接使用缓存结果。
Expires是HTTP/1.0的字段,但是现在浏览器默认使用的是HTTP/1.1,那么在HTTP/1.1中网页缓存还是否由Expires控制?
到了HTTP/1.1,Expire已经被Cache-Control替代,原因在于Expires控制缓存的原理是使用客户端的时间与服务端返回的时间做对比,那么如果客户端与服务端的时间因为某些原因(例如时区不同;客户端和服务端有一方的时间不准确)发生误差,那么强制缓存则会直接失效,这样的话强制缓存的存在则毫无意义,那么Cache-Control又是如何控制的呢?
Cache-Control
在HTTP/1.1中,Cache-Control是最重要的规则,主要用于控制网页缓存,主要取值为:
public:所有内容都将被缓存(客户端和代理服务器都可缓存)
private:所有内容只有客户端可以缓存,Cache-Control的默认取值
no-cache:客户端缓存内容,但是是否使用缓存则需要经过协商缓存来验证决定
no-store:所有内容都不会被缓存,即不使用强制缓存,也不使用协商缓存
max-age=xxx (xxx is numeric):缓存内容将在xxx秒后失效

由上面的例子我们可以知道:
HTTP响应报文中expires的时间值,是一个绝对值
HTTP响应报文中Cache-Control为max-age=600,是相对值
由于Cache-Control的优先级比expires,那么直接根据Cache-Control的值进行缓存,意思就是说在600秒内再次发起该请求,则会直接使用缓存结果,强制缓存生效。
注:在无法确定客户端的时间是否与服务端的时间同步的情况下,Cache-Control相比于expires是更好的选择,所以同时存在时,只有Cache-Control生效。
浏览器的缓存存放在哪里,如何在浏览器中判断 强制缓存是否生效?
2个概念 内存缓存(from memory cache) 和 硬盘缓存(from disk cache)
from memory cache代表使用内存中的缓存,
from disk cache则代表使用的是硬盘中的缓存,
浏览器读取缓存的顺序为memory –> disk
内存缓存(from memory cache):内存缓存具有两个特点,分别是快速读取和时效性:
1: 快速读取:内存缓存会将编译解析后的文件,直接存入该进程的内存中,占据该进程一定的内存资源,以方便下次运行使用时的快速读取。
2: 时效性:一旦该进程关闭,则该进程的内存则会清空。
硬盘缓存(from disk cache):硬盘缓存则是直接将缓存写入硬盘文件中,读取缓存需要对该缓存存放的硬盘文件进行I/O操作,然后重新解析该缓存内容,读取复杂,速度比内存缓存慢。
总结:
在浏览器中,浏览器会在 js 和 图片 等文件解析执行后直接存入内存缓存中,那么当刷新页面时只需直接从内存缓存中读取(from memory cache);
而css文件则会存入硬盘文件中,所以每次渲染页面都需要从硬盘读取缓存(from disk cache)。
协商缓存:
同样,协商缓存的标识也是在 响应报文的HTTP头 (response) 中 和 请求结果一起返回给浏览器的,控制协商缓存的字段分别有:Last-Modified / If-Modified-Since 和 Etag / If-None-Match,其中Etag / If-None-Match的优先级比Last-Modified / If-Modified-Since高。
Etag:是服务器响应请求时,返回当前请求的资源文件的一个唯一标识(由服务器生成)
Last-Modified:是服务器响应请求时,返回该资源文件在服务器最后被修改的时间,

服务端如何判断协商缓存失效,分析如下 ?
If-Modified-Since则是客户端再次发起该请求时,携带上次请求返回的Last-Modified值,通过此字段值告诉服务器该资源上次请求返回的最后被修改时间。服务器收到该请求,发现请求头含有If-Modified-Since字段,则会根据If-Modified-Since的字段值与该资源在服务器的最后被修改时间做对比,若服务器的资源最后被修改时间大于If-Modified-Since的字段值,则重新返回资源,状态码为200;否则则返回304,代表资源无更新,可继续使用缓存文件。
If-None-Match是客户端再次发起该请求时,携带上次请求返回的唯一标识Etag值,通过此字段值告诉服务器该资源上次请求返回的唯一标识值。服务器收到该请求后,发现该请求头中含有If-None-Match,则会根据If-None-Match的字段值与该资源在服务器的Etag值做对比,一致则返回304,代表资源无更新,继续使用缓存文件;不一致则重新返回资源文件,状态码为200
3: 缓存的优点:
- 减少了冗余的数据传输,节省宽带流量
- 减少了服务端的负担,大大提高了网站性能
- 加快了客户端加载网页的速度,这也正是http缓存属于客户端缓存的原因
不同刷新页面方式,对应浏览器请求过程
1: 浏览器 输入 URL 回车
- 浏览器发现缓存中有这个文件了,就不用继续请求了,直接去缓存拿 【最快】
2: F5
- F5就是告诉浏览器别偷懒,好歹去服务器看看这个文件是否有过期了,于是 浏览器就战战兢兢的发送一个请求带上 if-Modify-since
3: Ctrl + F5
就是告诉浏览器, 你先把缓存中的这个文件给删了,再去服务器请求个完整的资源文件下来, 于是客户端就完成了 强行更新 的操作
浏览器解析HTML代码-渲染页面
- 解析 HTML 形成 DOM树
- 解析 CSS 成 CSSOM树
- 合并 DOM 树 和 CSSOM 树 形成渲染树
- 浏览器开始 渲染并绘制 页面,这里涉及到2个比较重要的概念 回流 和 重绘 。
回流:DOM结点都是以盒子模型形式存在,需要浏览器去计算位置和宽度等,这个过程就是回流
重绘:等页面的宽高,大小,颜色等属性确定下来后,浏览器就开始绘制页面,这个过程称为重绘
备注:
浏览器打开页面一定是要经过这2个过程的,但是这个过程是非常非常非常消耗性能的,所有我们应该减少页面的回流和重绘
性能优化-【回流 重绘】
当Render Tree(渲染树)中部分或者全部元素的尺寸,结构,或者某些属性发生改变时,浏览器重新渲染 部分或者全部文档的过程称为-----回流
会导致回流的操作:
- 页面首次加载
- 浏览器窗口大小发生改变
- 元素的尺寸或位置发生改变
- 元素的内容改变(文字数量或图片大小等)
- 元素的字体大小改变
- 可见元素的添加或删除
- 激活CSS伪类( :hover)
- 查询某些属性或调用某些方法
当页面中元素的样式改变,不影响它在文档流中的位置时,(color, backgrond-color, visibility等),
浏览器会将新样式赋予给元素,并重新绘制它。这个过程称为-------重绘
优化:
1: css
避免使用table布局
尽可能在DOM树的末端改变class
避免设置多层内联样式
将动画效果应用在position属性的,absolate 和 fixed元素上
避免使用CSS表达式(例如:calc())。
2: JS
1: 避免频繁操作样式,最好一次性重写style属性,或将样式列表定义为class,并 一次性更改class属性
2: 避免频繁操作DOM,创建一个documentFragment,在它上面应用所有DOM操 作,最后将它添加到文档中
3: 也可以先将元素设置display:none, 操作结束后再将它显示出来,因为在 display:none的元素上进行DOM操作,不会引发回流和重绘
4: 避免频繁读取会引发回流/重绘,如果确实需要多次使用,可用一个变量缓存起来
5: 对具有复杂动画效果的元素,可使用绝对定位,使它脱离文档流,否则会引起父元素以及后续元素频繁回流
js解析
JS的解析 是由浏览器的 JS引擎 完成的。
由于JS是单线程运行的,一个时间只能干一件事件,干这个事情时其他事情需要排队,有些事情比较耗时(如IO操作),所以将任务分为 同步任务 和 异步任务
所有的同步任务放在主线程上执行,形成执行栈,而异步任务等待,
等执行栈上的任务执行完清空执行栈后,才去看看异步任务有没有东西要执行,
有 再提取到执行栈上执行,这样往复循环就形成了 Event Lopp 事件循环。
Event Loop
既然是单线程,每个事件的执行就要有顺序,比如你去银行取钱,前面的人在进行,后面的就得等待,要是前面的人弄个一两个小时,估计后面的人都疯了,因此,浏览器的JS引擎处理JavaScript时分为同步任务和异步任务
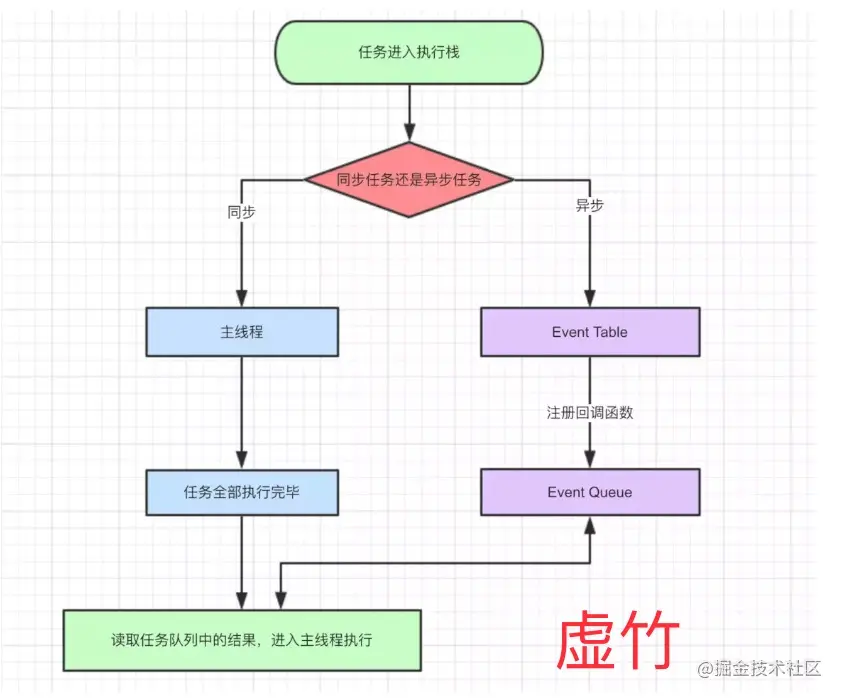
这张图我们可以清楚看到
- 同步和异步任务分别进入不同的执行"场所",同步的进入主线程,异步的进入Event Table并注册函数。
- 当指定的事情完成时,Event Table会将这个函数移入Event Queue。
- 主线程内的任务执行完毕为空,会去Event Queue读取对应的函数,进入主线程执行。
- 上述过程会不断重复,也就是常说的Event Loop(事件循环)。
除了同步任务和异步任务,我们还分为宏任务和微任务,常见的有以下几种
- (宏任务):包括整体代码 script,setTimeout,setInterval,
setImmediate,I/O,UI rendering - (微任务):process.nextTick, Promise, Object.observe, MutationObserver 不同任务会进入不同的任务队列来执行。
Tip:微任务会全部执行,而宏任务会一个一个来执行
下面来看一段代码
setTimeout(function() {
console.log('setTimeout');
})
new Promise(function(resolve) {
console.log('promise');
}).then(function() {
console.log('then');
})
console.log('console');
我们看看它的执行情况
- 第一轮
- 这段代码进入主线程
- 遇到setTimeout,将其回调函数注册后分发到宏任务
- 第二轮
- 遇到Promise,new Promise立即执行,输出
promise,- 遇到
then,将其分发到微任务- 第三轮
- 遇到
console.log("console"),直接输出console- 第四轮
- 主线程执行栈已经清空,先去微任务看看,
- 执行then函数,输出
then- 第五轮
- 微任务执行完了,看看宏任务,有个setTimeout,输出
setTimeout,- 整体执行完毕。 具体的执行过程大致就是这样,可能我有疏忽的地方,还望指正。
再来看看一段复杂的代码
console.log('1');
setTimeout(function() {
console.log('2');
process.nextTick(function() {
console.log('3');
})
new Promise(function(resolve) {
console.log('4');
resolve();
}).then(function() {
console.log('5')
})
})
process.nextTick(function() {
console.log('6');
})
new Promise(function(resolve) {
console.log('7');
resolve();
}).then(function() {
console.log('8')
})
setTimeout(function() {
console.log('9');
process.nextTick(function() {
console.log('10');
})
new Promise(function(resolve) {
console.log('11');
resolve();
}).then(function() {
console.log('12')
})
})
我们来分析一下
- 整体script进入主线程,遇到
console.log('1'),直接输出- 遇到
setTimeout,将其回调函数分发到宏任务事件队列,暂时标记为setTimeout1- 遇到
process.nextTick(),将其回调函数分发到微任务事件队列,标记为process.nextTick1(这个地方有点出入,我一般认为```process.nextTick()推入主线程执行栈栈底,作为执行栈最后一个任务执行)- 遇到Promise,立即执行,输出
7,then函数分发的微任务事件队列,标记为Promise1。- 遇到setTimeout,将其回调函数分发到微任务事件队列,标记为setTimeout2。
- 现在已经输出了
1,7,宏任务和微任务的事件队列 情况如下我们接着来看
- 现在主线程执行栈被清空,去微任务看看,发现有两个事件等待,由于队列是先进先出,执行
process.nextTick1,输出6,接着执行Promise1,输出8。至此,第一轮循环已经结束,输出了
1,7,6,8,接下来执行第二轮循环 ,先从宏任务的
setTimeout1开始
- 遇到
console.log('2'),执行输出。- 遇到
process.nextTick(),将其回调函数分发到微任务,标记为process.nextTick2,又遇到Promise,立即执行,输出4,将then函数推入微任务事件队列,标记为Promise2- 到此宏任务的一个任务执行完毕,输出了
2,4,来看看事件队列
- 去微任务看看,我们先处理
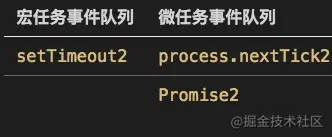
process.nextTick2,输出3,接着再来执行Promise2,输出5。- 第二轮循环执行完毕。现在一共输出了
1,7,6,8,2,4,3,5- 从
setTimeout2开始第三轮循环 ,先直接输出9,- 遇到
process.nextTick(),将其回调函数分发到微任务事件队列,标记为process.nextTick3,又遇到恶心的Promise,立即执行输出11,将then函数分发到微任务,标记为Promise3。- 执行微任务,看看还有撒子事件
居然还有事件,能咋办,接着执行呗,输出
10,12。 至此,全部任务执行完毕,输出顺序为1,7,6,8,2,4,3,5,9,11,10,12.


详细可点击下面链接查看:














 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









