







最近一直在看Honey Badger BFT共识协议,看了很多博客和一些相关的论文,但是发现有些博客存在着部分理解错误的地方,或者就是直接翻译2016年的那一篇论文,在经过半个多月的细读之后,打算整理出这篇博客,方便给学习这个共识协议的人学习,同时自己也留存一份笔记,以下仅是笔者通过阅读论文和博客等方式,描述自己对Honey Badger的理解。如有错误,还请指正。
Miller等人提出的Honey Badger BFT是一种在异步网络环境下可以正常运行的BFT协议。
- 异步,比PBFT的吞吐量和延迟性能好
- 仅支持封闭网络,即主机个数已知,协议执行过程中没有新的主机接入网络。
- 无Leader,每个节点都可作为共识的发起者。
Honey Badger BFT使用了两个方法来提升共识效率: - 通过纠删码分割交易来环节单节点带宽瓶颈。
- 通过在批量交易中选择随机交易块,并配合门限加密来提升交易的吞吐量。
基础知识
纠删码
(我是在一篇博客上面看到的关于RS纠删码的介绍,这里只是粗略的介绍一个概念,让大家知道是用来干什么的,以及是一个什么原理。纠删码技术在后面的RBC阶段会使用到,主要是用于均分带宽,缓解提出共识交易节点的带宽瓶颈。)
纠删码工作原理简介:
RS(Reed-solomom)码是一种比较常见的纠删码,它的两个参数m和n分别代表校验块个数和原始数据块个数(课容忍m个数据块的丢失,拜占庭共识中,设m = 2f,原始数据块为f+1),我们可以使用n数据块就恢复出原始的数据块。
纠删码编码过程:C代表校验块,D代表原始的数据块。
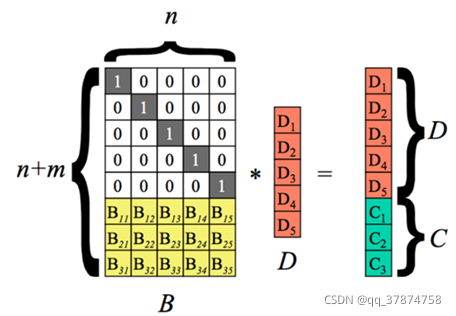
假设我丢失了D1、D4、C2数据块:
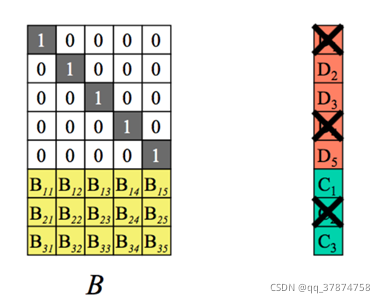
解码过程:(一共三步)
Step1:在编码矩阵中去掉求实数据块以及该数据块对应的行。即B矩阵变为了n*n维度的方阵,C和D组合的矩阵由(n+m)行变为n行,在上诉假设过程中,我们得到新的矩阵以及对应的矩阵运算关系式,其中在丢失了部分数据块后,D所代表的原始数据块成为了要求的目标。
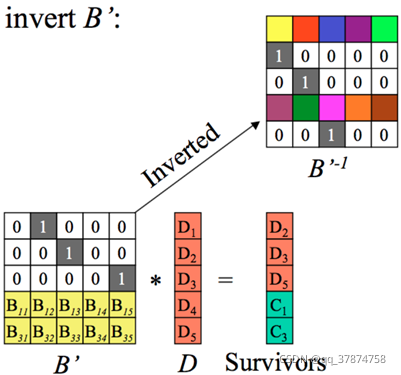
step2:求B’的逆矩阵:
如下图所示:
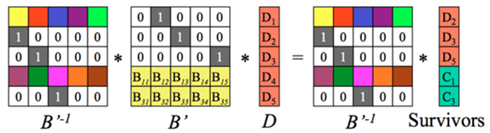
step3:可以采用对等式两边同时乘上B’的逆矩阵,于是得到所求解。
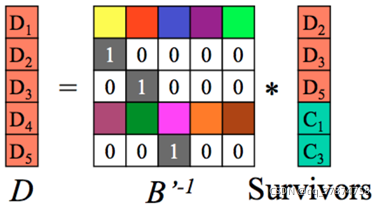
如果大家没太看懂,我贴上关于纠删码部分原作者的博客链接&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2537
2537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









