







文章目录
资源
代码
https://github.com/ouyangxizhu/ArtConcurrentBook.git
书籍
链接:https://pan.baidu.com/s/18xLExmEllaowDsXbulH-iw
提取码:ttln
一、并发编程的挑战
1.1 上下文切换
即使是单核也支持多线程执行代码,CPU通过给每个线程分配CPU时间片来实现这个机制。时间片一般几十毫秒(ms) ,非常短,所以用户感觉是同时执行的。
CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后会切换到下一个任务。但是在切换前会保存上一个任务的状态,一边下次切换回这个任务时,可以在加载这个任务的状态。所以任务从保存到再加载的过程就是一次上下文切换。
1.1.1 多线程一定快吗
chapter01.ConcurrencyTest
public class ConcurrencyTest {
private static final long count = 10000l;
public static void main(String[] args) throws InterruptedException {
//并行
concurrency();
//串行
serial();
}
private static void concurrency() throws InterruptedException {
long start = System.currentTimeMillis();
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
int a = 0;
for (long i = 0; i < count; i++) {
a += 5;
}
System.out.println(a);
}
});
thread.start();
int b = 0;
for (long i = 0; i < count; i++) {
b--;
}
thread.join();
long time = System.currentTimeMillis() - start;
System.out.println("concurrency :" + time + "ms,b=" + b);
}
private static void serial() {
long start = System.currentTimeMillis();
int a = 0;
for (long i = 0; i < count; i++) {
a += 5;
}
int b = 0;
for (long i = 0; i < count; i++) {
b--;
}
long time = System.currentTimeMillis() - start;
System.out.println("serial:" + time + "ms,b=" + b + ",a=" + a);
}
}
答案是不一定

即循环次数比较少的时候,单线程比较快,因为有线程创建和上下文切换的开销。
1.1.2 测试上下文切换次数和时长
- 使用Lmbench(性能测试工具)可以测量上下文切换次数
- 使用vmstat可以测量上下文切换次数
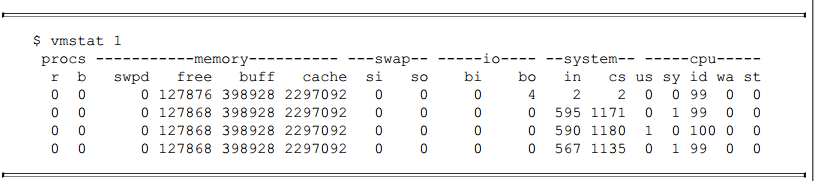
CS(content switch)便是上下文切换次数,上下文每秒切换1000多次,即时间片在1ms左右。
1.1.3 如何减少上下文切换
1.1.3.1 无锁并发编程
可以用一些办法来避免使用锁,比如将数据的id按照hash算法取模分段,不同的线程处理不同段的数据。
1.1.3.2 CAS算法
java的atomic包使用CAS算法来更新数据,而不需要加锁
1.1.3.3 使用最少线程
避免创建不需要的线程,比如任务很少,但是创建了很多线程来处理,这样会造成大量线程都处于等待状态。
1.1.3.4 使用协程
在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。
1.1.4 减少上下文切换实战
1.1.4.1 用jstack命令dump线程信息
看看pid为3117的进程里的线程都在做什么
sudo -u admin /opt/ifeve/java/bin/jstack 31177 > /home/tengfei.fangtf/dump17
1.1.4.2 统计所有线程分别处于什么状态
发现300多个线程处于WAITING(onobjectmonitor)状态
[tengfei.fangtf@ifeve ~]$ grep java.lang.Thread.State dump17 | awk '{print $2$3$4$5}'
| sort | uniq -c
39 RUNNABLE
21 TIMED_WAITING(onobjectmonitor)
6 TIMED_WAITING(parking)
51 TIMED_WAITING(sleeping)
305 WAITING(onobjectmonitor)
3 WAITING(parking)
1.1.4.3 打开dump文件查看处于WAITING(onobjectmonitor)的线程在做什么
发
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









