










大数量级mongo翻页Java代码
一、准备的基础环境
- 主要jar包依赖:
<mongo.version>3.12.7</mongo.version>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>${mongo.version}</version>
</dependency>
-
mongo compass可视化工具

我这里大概40万数据,不算特别多mongo采用的是mongoCollection:
private static MongoCollection<Document> mongoCollection = MongoDBTemplate.getCollection("索引名", "集合名");
二、 传统skip 、limit 相同条件下遍历的性能对比
-
mongo操作的dao代码图片:

-
测试方法
/**
* SkipAndLimit分页测试(20万数据12-14秒,40万数据大概43-50秒左右)------->也不推荐
*/
@Test
public void testMongoSkipAndLimitPage() {
long startTime = System.currentTimeMillis()/1000;
List<T> dataEntityList = new ArrayList<>(1000000);
long totalSize = topicDao.getTotalSize();
log.info("totalSize:{}",totalSize);
int page = 1;
int pageSize = 1000;
int pages = (int) Math.ceil(totalSize / (double) pageSize);
while (page <= pages) {
List<T> byPage = topicDao.findDataWithSkip(page, pageSize);
dataEntityList.addAll(byPage);
page++;
log.info("size:{}",dataEntityList.size());
// if (page>200){
// break;
// }
}
log.info("spend time:{} 秒",System.currentTimeMillis()/1000-startTime);
}
上面的T改为自己的实体类
测试结果:

3. 结论:
传统的skip与limit翻页性能在数据量很大的时候,遍历的时候就会花费非常久的时间,我这里只有40万数据,就已经花了将近50秒钟,当数据量更大几个量级,那就有的等了。
二、方式二:每次翻页之前,查询到上一页的最后一条数据,然后从刚好比这条数据大的地方开始下一页遍历
- 主要mongo操作的dao代码图片
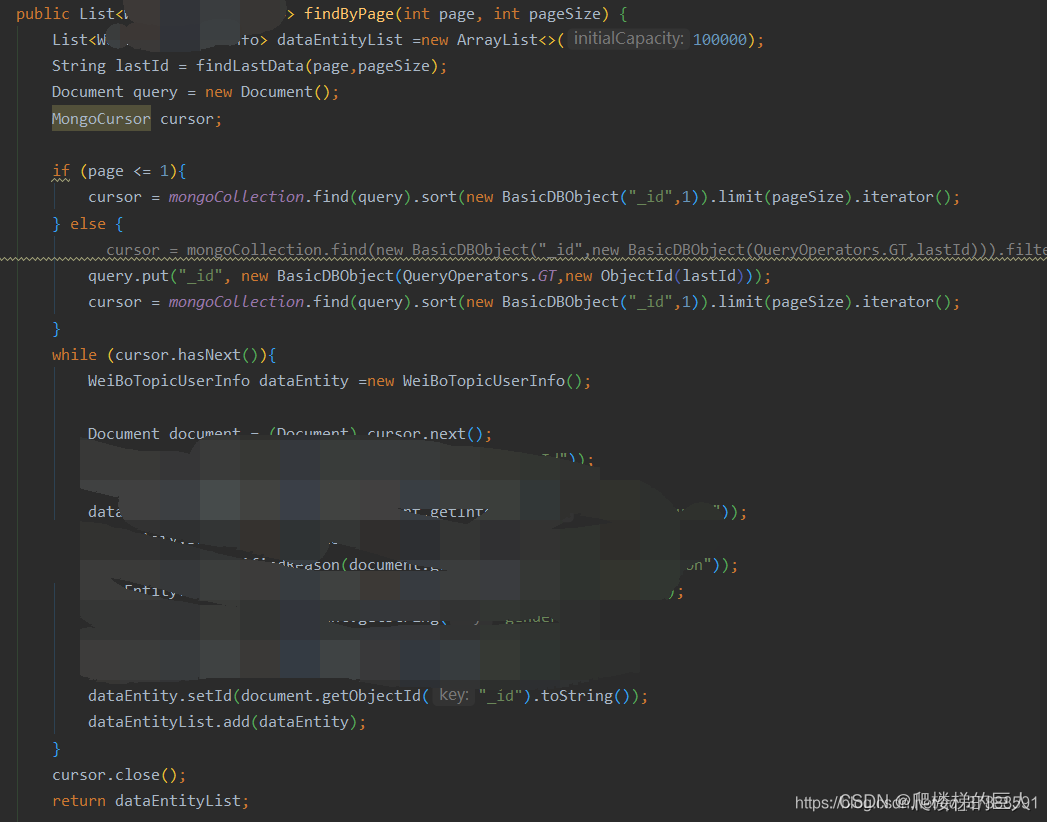
/**
* 查询某一页最后一条数据的objectid
* @return
*/
public String findLastData(int page, int pageSize) {
try {
//url,commentId,name,userId,time,level,source,content,commentNum,likerNum,disLikerNum,parentCommentId
Document document = mongoCollection.find().skip((page - 1) * pageSize).limit(pageSize).sort(new BasicDBObject("_id", 1)).first();
String id = document.getObjectId("_id").toString();
// log.info("id: {}",id);
return id;
}catch (Exception e){
logger.error("mongo查询失败");
}
return null;
}
- 测试方法
/**
* 依赖分页测试1(20万数据26-29秒,40万数据大概86-100秒左右)------->不推荐
*/
@Test
public void testMongoSomePage() {
long startTime = System.currentTimeMillis()/1000;
List<T> dataEntityList = new ArrayList<>(1000000);
long totalSize = topicDao.getTotalSize();
log.info("totalSize:{}",totalSize);
int page = 1;
int pageSize = 1000;
// String lastId = "";
int pages = (int) Math.ceil(totalSize / (double) pageSize);
while (page <= pages) {
List<T> byPage = topicDao.findByPage(page, pageSize);
dataEntityList.addAll(byPage);
log.info("size:{}",dataEntityList.size());
page++;
// if (page>200){
// break;
// }
}
log.info("spend time:{} 秒",System.currentTimeMillis()/1000-startTime);
}
上面代码中的T换成自己的实体类就行
测试图片如下:

- 结论
这种方式是我第一次按照网上其他人的博客写的,但是很明显,每次翻页都需要查询一次上一页的最后一条objectid,本质上跟skip没什么区别,甚至多出了其他耗时的代码操作,最不推荐
三、大数据量依赖分页分页方式2:
- 翻页dao代码:
/**
* 依赖翻页mongo (速度快,推荐)
* @param lastId 上一页最后一个 ObjectId
* @param pageSize 每页大小
* @return
*/
public List<T> queryDataByPage(String lastId, int pageSize) {
List<T> dataEntityList =new ArrayList<>(3000);
// DBCursor dbObjects=null;
MongoCursor<Document> cursor;
BasicDBObject query=new BasicDBObject();
if(StringUtils.isBlank(lastId)) {
cursor = mongoCollection.find(query).sort(new BasicDBObject("_id",1)).limit(pageSize).iterator();
} else {
query.put("_id", new BasicDBObject(QueryOperators.GT,new ObjectId(lastId)));
cursor = mongoCollection.find(query).limit(pageSize).sort(new BasicDBObject("_id",1)).iterator();
}
while (cursor.hasNext()){
TdataEntity =new T();
Document document = cursor.next();
dataEntity.setUserId(document.getString("userId"));
......
dataEntity.setId(document.getObjectId("_id").toString());
dataEntityList.add(dataEntity);
}
cursor.close();
return dataEntityList;
}
2. **测试代码:**
```java
/**
* 依赖分页性能测试(20万数据4-6秒,40万数据大概10-12秒)---------------->推荐
*/
@Test
public void testMongoQueryByPage() {
long startTime = System.currentTimeMillis()/1000;
List<T> dataEntityList = new ArrayList<>(1000000);
long totalSize = topicDao.getTotalSize();
log.info("totalSize:{}",totalSize);
int page = 1;
int pageSize = 1000;
//总页数
long totalPage = totalSize/pageSize==0?totalSize/pageSize:totalSize/pageSize+1;
String lastId = null;
while (page <= totalPage) {
List<T> byPage = topicDao.queryDataByPage(lastId,pageSize);
if (!byPage.isEmpty()){
dataEntityList.addAll(byPage);
lastId = byPage.get(byPage.size()-1).getId();
page++;
log.info("size:{}",dataEntityList.size());
// if (page>200){
// break;
// }
}
}
log.info("spend time:{} 秒",System.currentTimeMillis()/1000-startTime);
}
同样,上面代码中的T换成自己的实体类就行
翻页花费时间的截图如下:
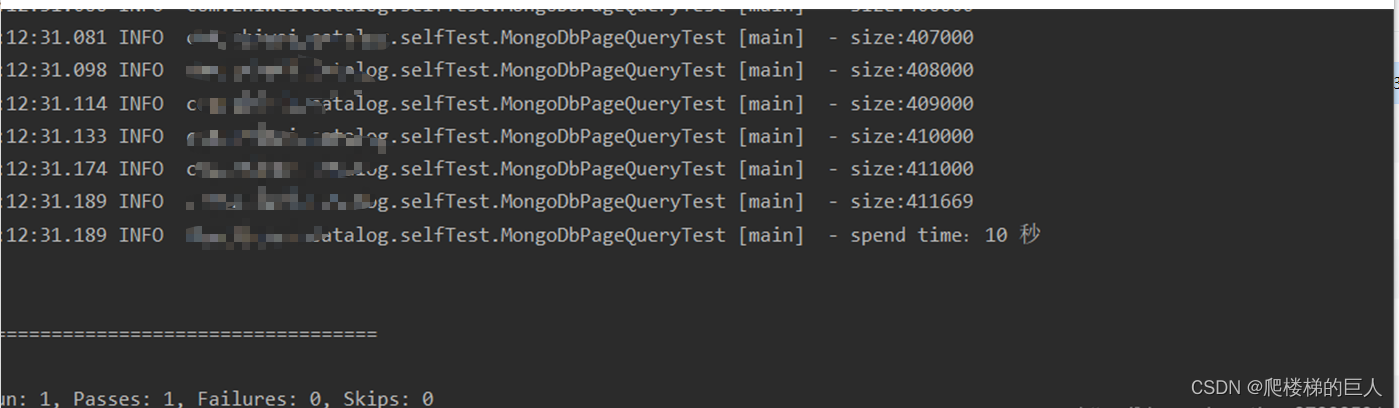
- 结论:
这里的逻辑跟第二种方法类似,只不过是每次翻页时直接返回最后一条数据,取其objectId(当然第一次的lastId为null,第一次翻页还是直接按照传统的skip与limit来翻页,当然如果你知道第一次翻页之前的objectId可以直接修改为传入就行),然后将其传入条件中,就可以达到更好的性能
我上面测试的都是以1000为一页的翻页大小,测试下来比之前的翻页快很多,当然如果你们有更好的方法,欢迎留言,留下代码,共同进步。
参考文献与博客:
【1】参考博客:亿级别记录的mongodb分页查询java代码实现















 1103
1103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









