







选择customers的
first_name, last_name, points,列
添加新的列 points+10
列名就是points+10
意思是将points列的每个数值加10*/
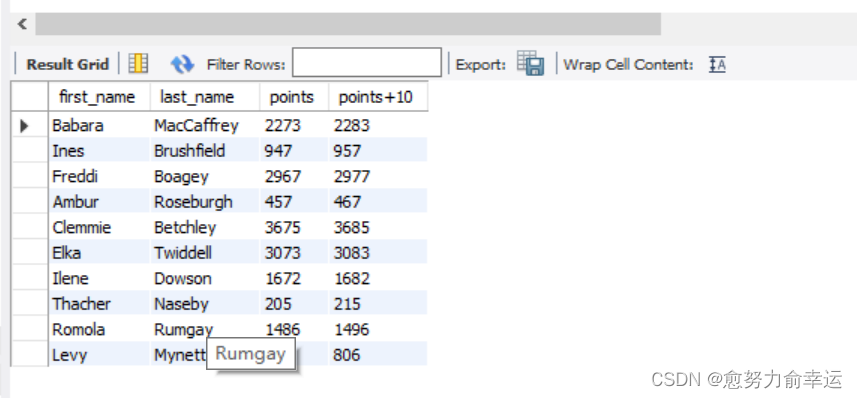
/*选择customers的
first_name, last_name, points,列
添加新的列 points+10
列名就是points+10
意思是将points列的每个数值加10*/
SELECT first_name, last_name, points, points + 10
FROM customers
选择customers的
first_name, last_name, points,列
添加新的列 (points+10)*100
给新的列起别名为discount_factor
意思是将points列的每个数值加10然后在扩大100倍
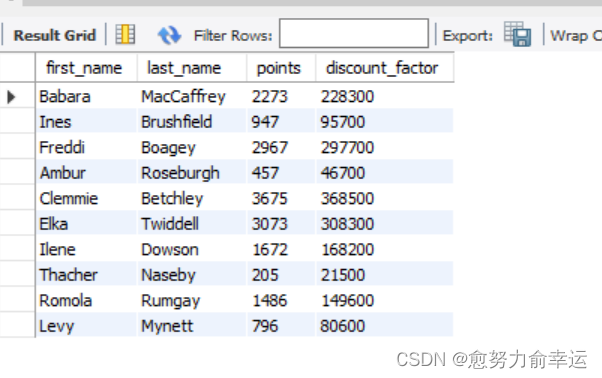
/*选择customers的
first_name, last_name, points,列
添加新的列 (points+10)*100
给新的列起别名为discount_factor
意思是将points列的每个数值加10然后在扩大100倍*/
SELECT
first_name,
last_name,
points,
(points + 10)*100 AS discount_factor
FROM customers
如果想在新的列名里加空格,需要在两侧加上引号,单引号,双引号都可
/*选择customers的
first_name, last_name, points,列
添加新的列 (points+10)*100
给新的列起别名为discount factor
意思是将points列的每个数值加10然后在扩大100倍
如果想在新的列名里加空格,需要在两侧加上引号,单引号,双引号都可*/
SELECT
first_name,
last_name,
points,
(points + 10)*100 AS 'discount factor'
FROM customers

总结:
select后面
可以用*返回所有列
或者指定我们想要返回的列
我们也可以使用算术表达式
可以选择给每列和结果集一个别名
distinct删去重复项
SELECT state
FROM customers
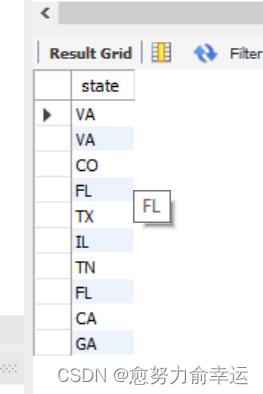
可以看到结果中有两个VA洲。
我们可以使用distinct删去重复的项
SELECT DISTINCT state
FROM customers

在使用distinct的过程中主要注意一下几点:
在对字段进行去重的时候,要保证distinct在所有字段的最前面,
1.distinct必须放在开头
即select id, distinct name from A; 会提示错误,因为distinct必须放在开头
2.
如果列具有
NULL值,并且对该列使用DISTINCT子句,MySQL将保留一个NULL值,并删除其它的NULL值,因为DISTINCT子句将所有NULL值视为相同的值。
3.如果distinct关键字后面有多个字段时,则会对多个字段进行组合去重,只有多个字段组合起来的值是相等的才会被去重。什么意思呢看例子
也就是必须得state与city都相同的才会被排除


select子句不能使用as后面的别名,因为这个时候程序还没跑,还没有这个别名
想使用第一种方法
SELECT invoice_id, invoice_total, (SELECT AVG(invoice_total) FROM invoices) AS invoice_average, invoice_total - (SELECT AVG(invoice_total) FROM invoices) FROM invoices第二种方法,在别名前加select
如果是聚合函数起的别名也不能用select


















 1494
1494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









