






 本文介绍如何使用R语言的rvest包和SelectorGadget插件从豆瓣网站爬取2017年热门电影的排名、标题、评分、描述及详细信息,并进行数据预处理。
本文介绍如何使用R语言的rvest包和SelectorGadget插件从豆瓣网站爬取2017年热门电影的排名、标题、评分、描述及详细信息,并进行数据预处理。
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
本文我们会用R来爬取豆瓣网上2017年最热门电影的一些特征。
1)前期准备:CSS源查找器--Selector Gadget插件,这个插件可以弥补HTML知识的不足。使用这个插件可以通过点击任一网页中你需要的数据就能获得相应的标签,也可以学习HTML和CSS的知识并且手动实现这一过程。
安装Rvest包,rvest是R语言一个用来做网页数据抓取的包,包的介绍就是“更容易地收割(抓取)网页”
豆瓣网TOP250电影网址https://movie.douban.com/top250?start=0&filter=
2)基本思路:下图是该网站的截图,观察网站后我们可以从网站爬取电影排名rank,电影名称title,电影描述description,电影评分score,电影信息di五大方面的内容

3)具体过程:
Step1:爬取排名rank
爬取的第一步是使用 selector gadget获得排名的CSS选择器。你可以点击浏览器中的插件图标并用光标点击排名的区域。
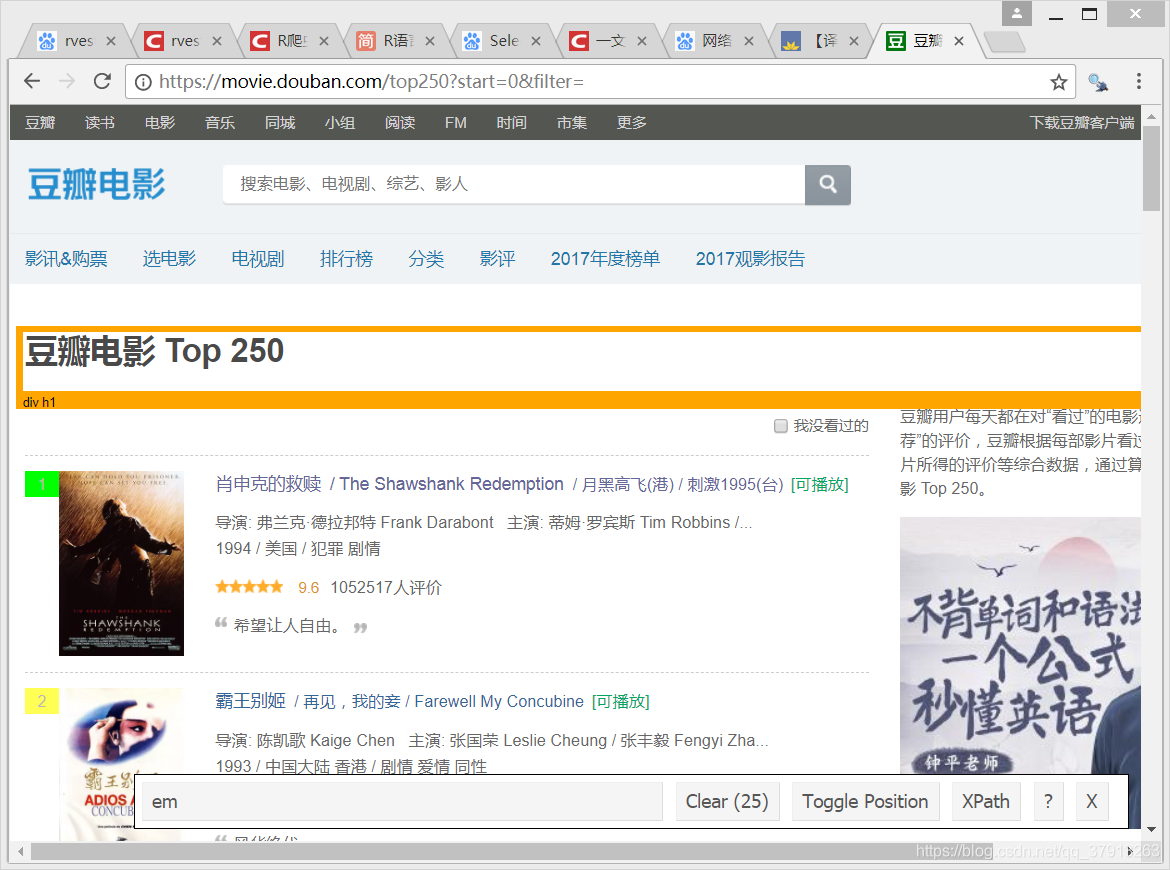
一旦你已经选择了正确的区域,你需要把在底部中心显示的相应的CSS选择器复制下来,
# 加载包
library(xml2)
library(rvest)
site <- "https://movie.douban.com/top250?start=200&filter="# 从网页读取html代码
webpage <- read_html(site)# 指定要爬取的url
# 用CSS选择器获取排名部分
rank_data_html <- html_nodes(webpage,'em')
# 把排名转换为文本
rank_data <- html_text(rank_data_html)
# 检查一下数据
head(rank_data)

# 数据预处理:把排名转换为数值型
rank_data<-as.numeric(rank_data)
# 再检查一遍
head(rank_data)

得到电影排名rank
Step2:爬取电影标题title
现在可以开始选择电影标题了,可以看见所有的标题都被选择了,你依据个人需要做一些增删。
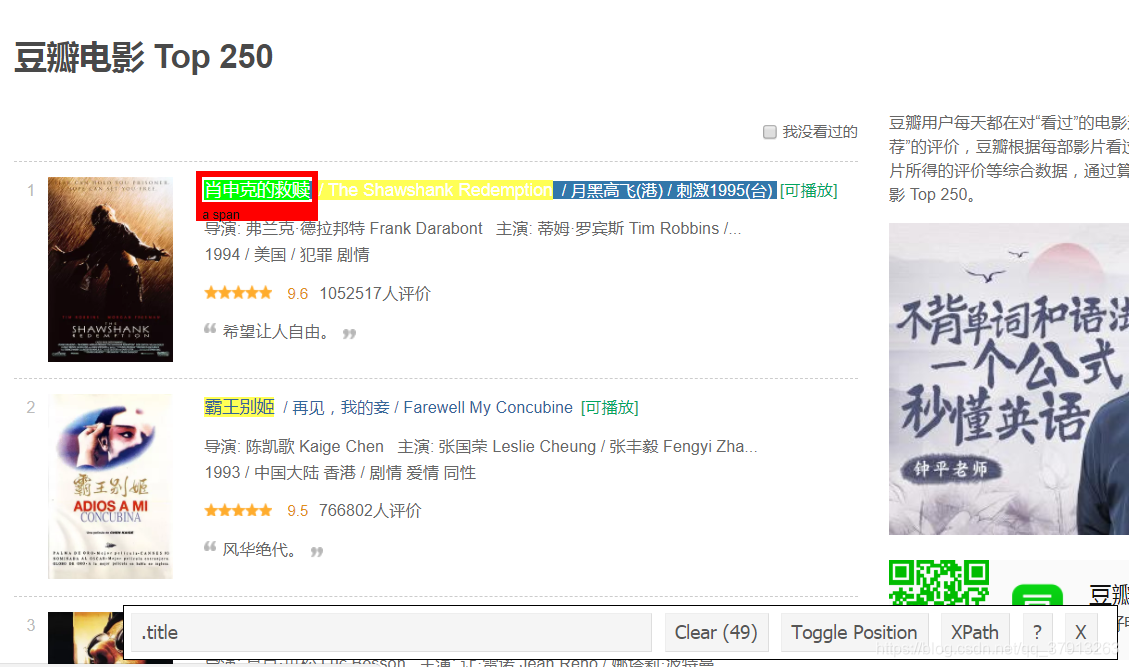
我们通过selector gadget得到电影标题的源代码.title
#用CSS选择器获取标题部分
title_data_html <- html_nodes(webpage,'.title:nth-child(1)')
# 转换为文本
title_data <- html_text(title_data_html)
# 检查一下
head(title_data)

我们成功的得到了电影标题title,排名第一的电影是肖申克的救赎,第二的是霸王别姬
Step3:爬取电影评分score
与前两步相同利用CSS源查找器获得电影描述的源代码.rating_num
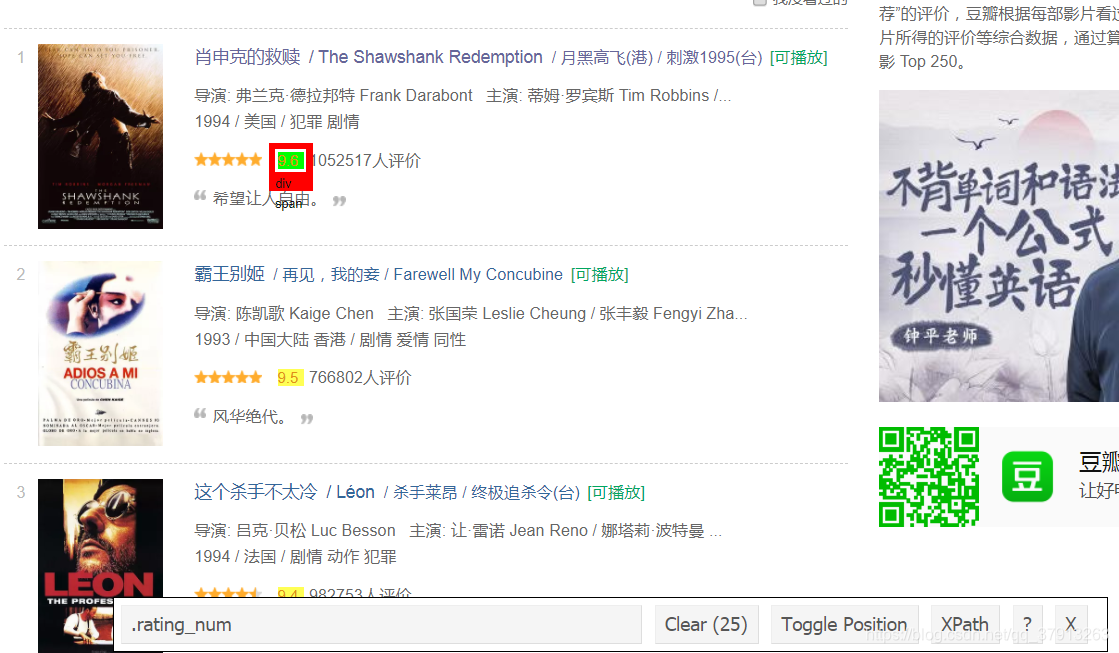
# 爬取评分
score_data_html <- html_nodes(webpage,'.rating_num')
# 转为文本
score_data <- html_text(score_data_html)
# 检查一下
head(score_data)
# 数据预处理:把评分转换为数值型
score_data<-as.numeric(score_data)
head(score_data)

这样我们就得到了电影的评分,正如网站,肖申克的救赎排名第一,得分9.6
Step4:爬取电影描述description
利用CSS源查找器获得电影描述的源代码.inq
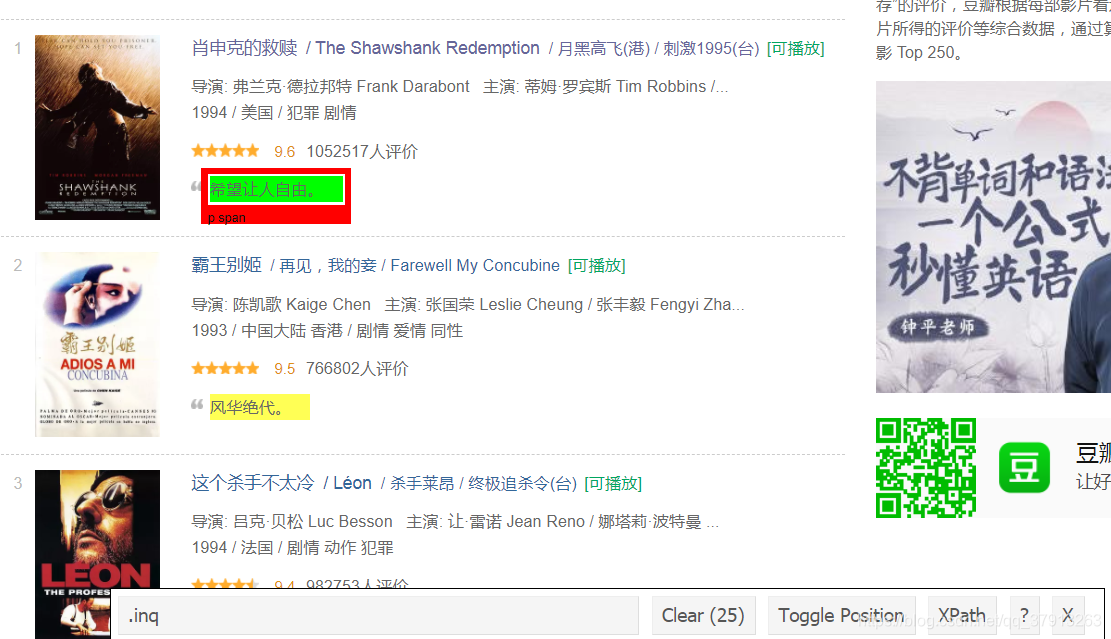
#爬取描述
description_data_html <- html_nodes(webpage,'.inq')
# 转为文本
description_data <- html_text(description_data_html)
#查看一下
description_data
description_data=data.frame(description_data)

我们得到电影描述description
Step5:爬取电影详细信息
利用CSS源查找器获得电影描述的源代码p:nth-child(1)
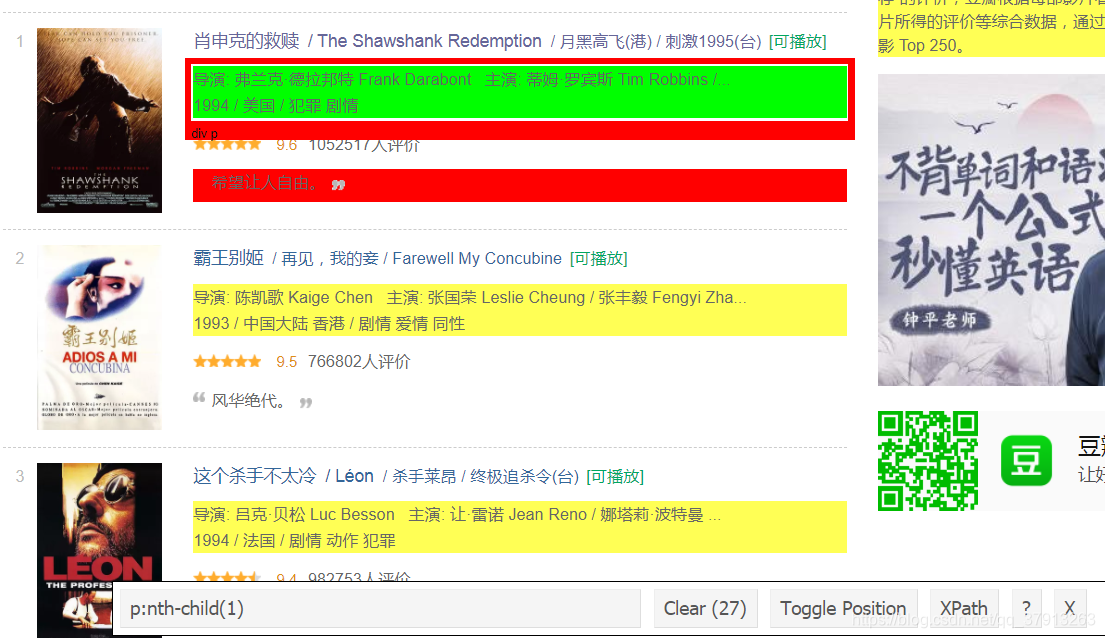
#爬取详细信息
di_data_html <- html_nodes(webpage,'.bd p:nth-child(1)')
# 转为文本
di_data <- html_text(di_data_html)
# 检查一下
head(di_data)

此时我们看到详细信息有很多没用的空格和乱码
我们使用gsub函数剔除
# 移除 '\n' 空格
di_data<-gsub("\n"," ",di_data)
di_data<-gsub(" "," ",di_data)
di_data<-gsub("/...","",di_data)
di_data<-gsub("<U+00A0><U+00A0><U+00A0>","",di_data)
di_data<-gsub("<U+00A0><U+00A0> ","",di_data)
head(di_data)
di=di_data[!di_data=="豆瓣"]
#再检查一下
head(di_data)

再看电影详细信息已经没有多余的空格和 '\n'
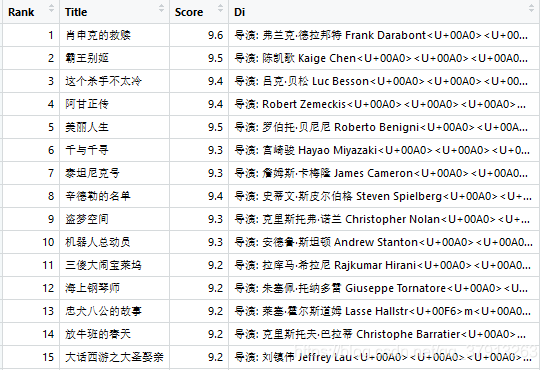
Step6:我们已经成功爬取了250部电影的5个特征,创建一个数据框并看看结构。
movies_df <- data.frame(
Rank=rank_data,
Title=title_data,
Score=score_data,
Di=di_data)
movies_df
得到下列数据框
将数据框数据写入Excel
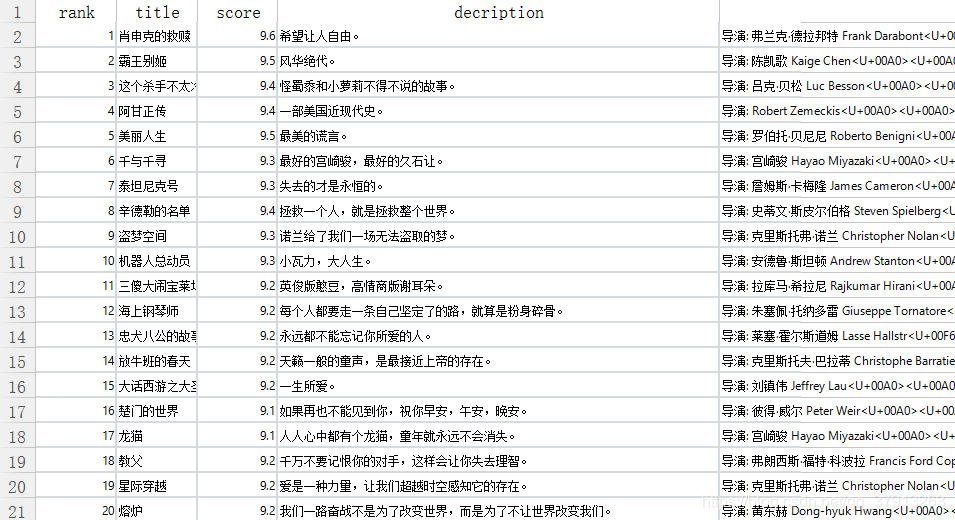
现在2017年上映的最流行的250部故事片在豆瓣网上的数据已经爬取成功了!
我们可以利用这些数据进行一些分析
下一节会进行词云图分析


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









