



 本文是关于条件式变换自编码机(CVAE)的学习笔记,介绍了VAE作为生成模型的功能、结构,以及隐空间的结构。通过重参数化训练解决VAE的反向传播问题,并探讨了CVAE如何利用条件信息生成不同图像。
本文是关于条件式变换自编码机(CVAE)的学习笔记,介绍了VAE作为生成模型的功能、结构,以及隐空间的结构。通过重参数化训练解决VAE的反向传播问题,并探讨了CVAE如何利用条件信息生成不同图像。
前言
本文为自学VAE时做的阅读笔记。
原文链接:https://ijdykeman.github.io/ml/2016/12/21/cvae.html
原文
Introduction
原文作者苦于没有通俗易懂的VAE资料,所以在自学之后,借用MNIST作为例子,希望为后来者提供一份易懂的VAE入门读物。
若想继续深入,可阅读:Tutorial on Variational Autoencoders
VAE的功能
VAE是一个生成模型(generative model),用来生成和训练数据的样本很像的、让人可信的假样本。以MNIST为例,生成的便是手写数字图像。具体而言,VAE可以提供一个隐空间(latent space),我们可以从中采样。每一个点都可以被解码为一个合理的手写数字图像。
VAE的结构
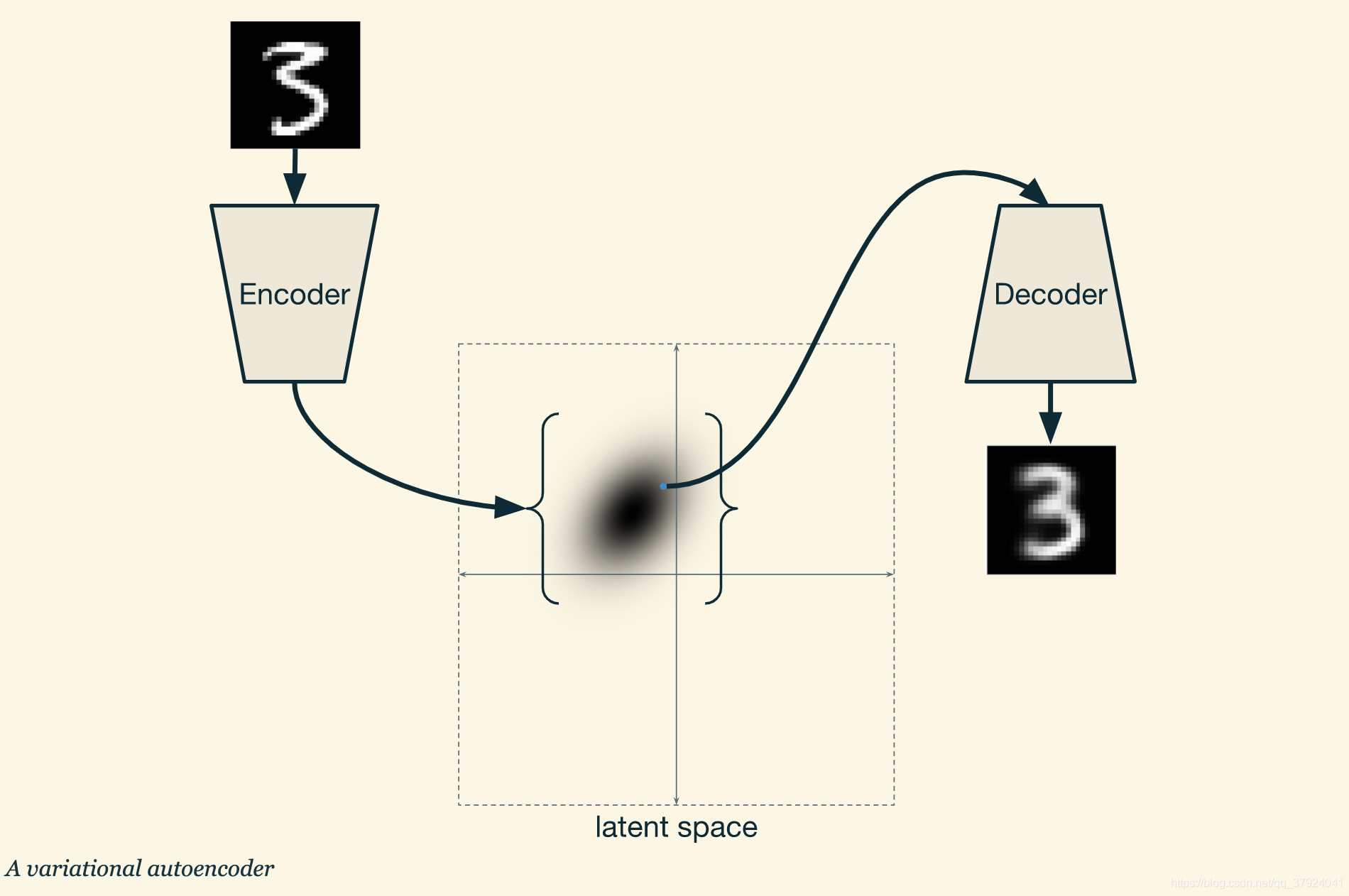
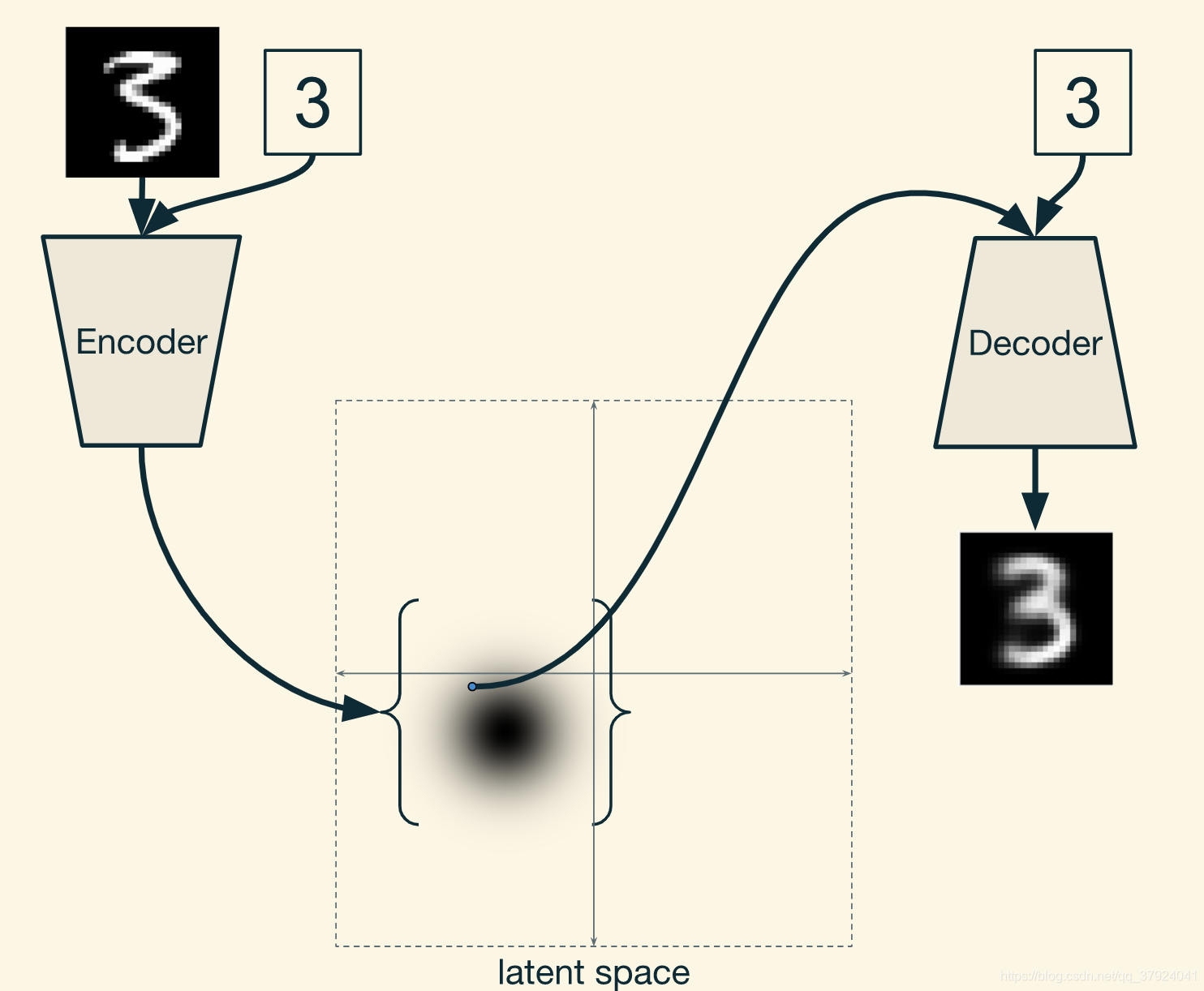
任何一个自编码机的目的都是重构他的输入。 它先将输入压缩为一个更小的结构,然后再解压为一个和输入较为相似的输出。压缩功能由编码器(Encoder)完成,解压功能则是由(Decoder)负责。此处两者皆为神经网络。

诚然,如果只是把输入重构,标准的自编码机够用。但它不足以被称为生成模型(generative model),因为一个随机的输入图像V’ 就可能最后输出一张完全不可读的图片(这是由于V’ 可能完全不像之前读入过的任何图像)。我们需要不管输入输入任何图像,都可以输出一张合理的图像。
那么该怎么做?我们可以先定义好解码器应该得到的输入的分布(如果读到的都是类似于同分布的,那么采样结果大概率就会落在可以解读的区域上)。接下来我们会用标准正态分布来定义解码器该得到的数据的分布。
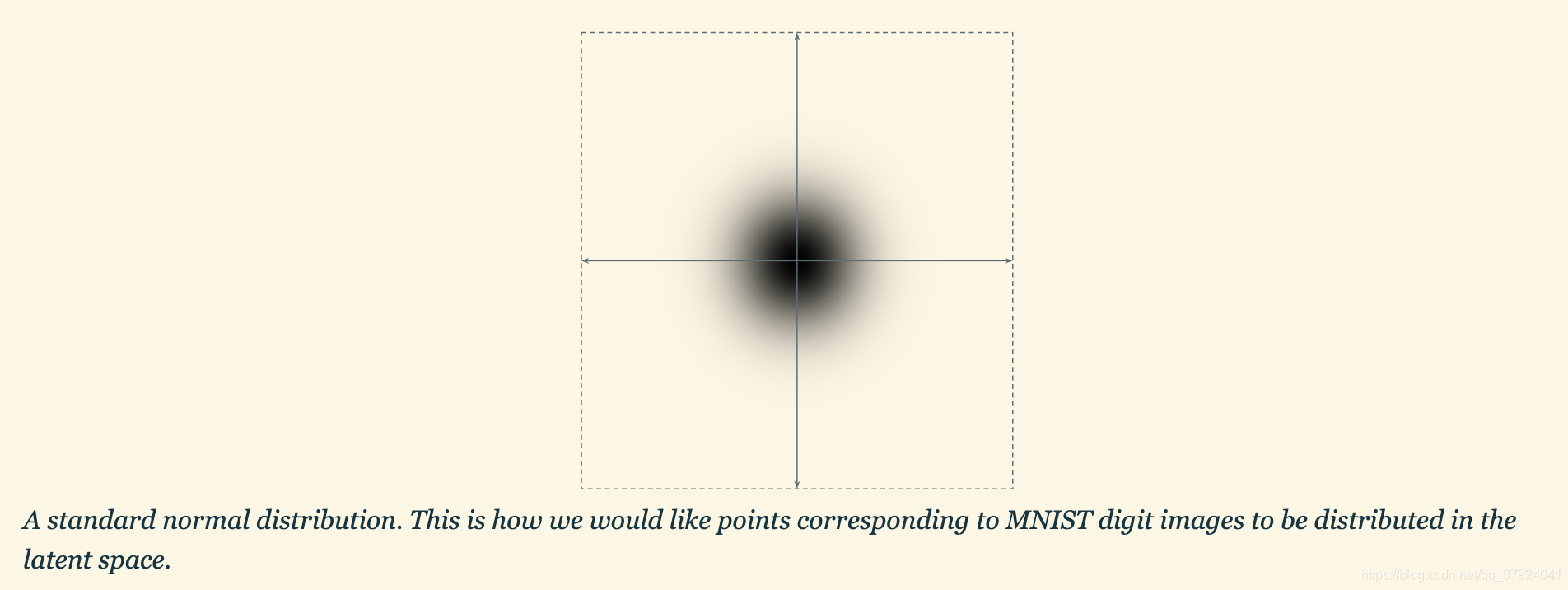
我们想要让任何从这个分布中采样的一个点都能被解码器解码为一张合理的图像。
接下来我们来设计编码器。传统的编码器都是读入数据,然后转化为隐空间中的一个点,但在VAE中,编码器生成的是隐空间中的一个概率分布。
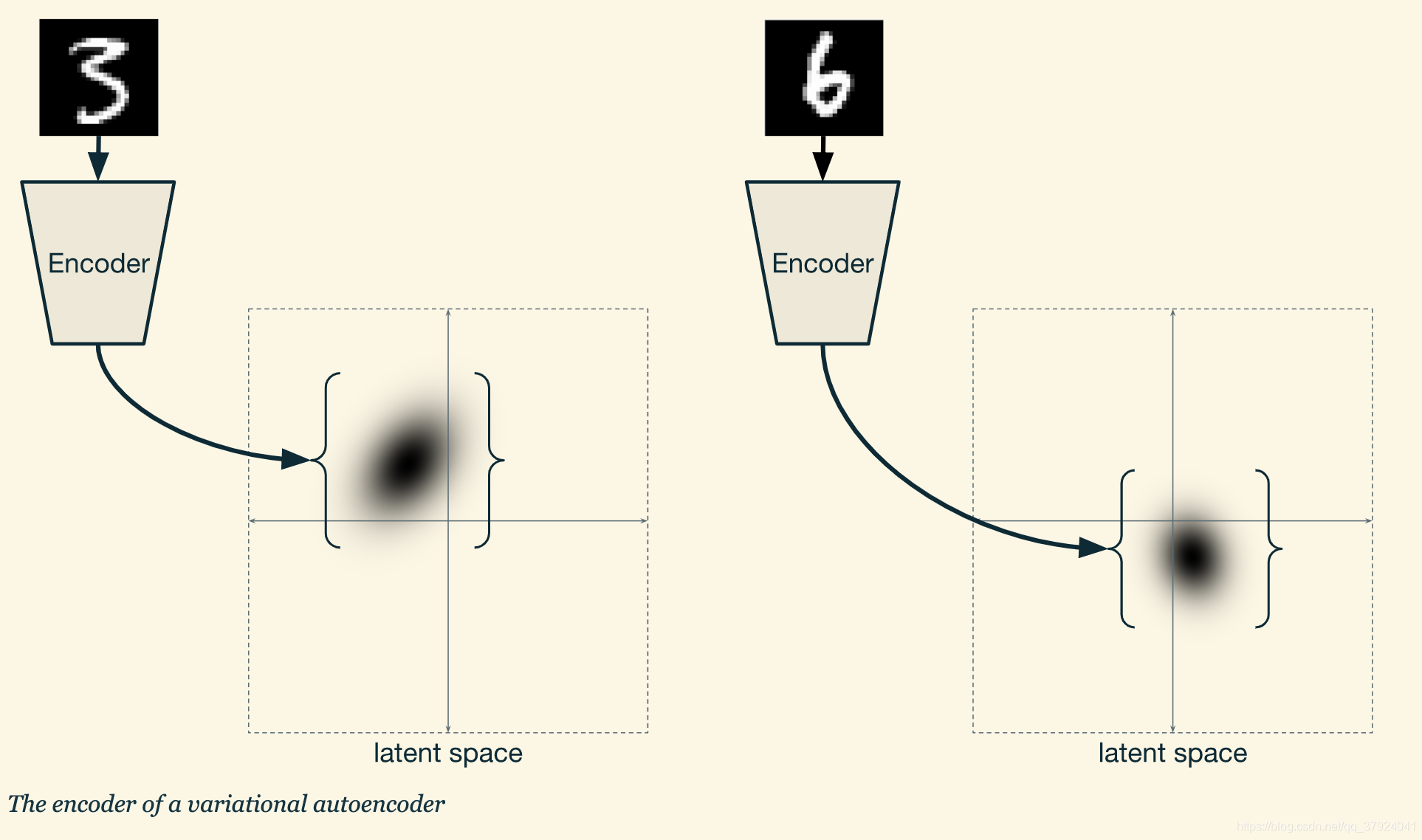
编码器在隐空间输出的概率分布是拥有与隐空间相同维度的高斯分布。所以编码器只需要输出这个高斯分布的参数即可。
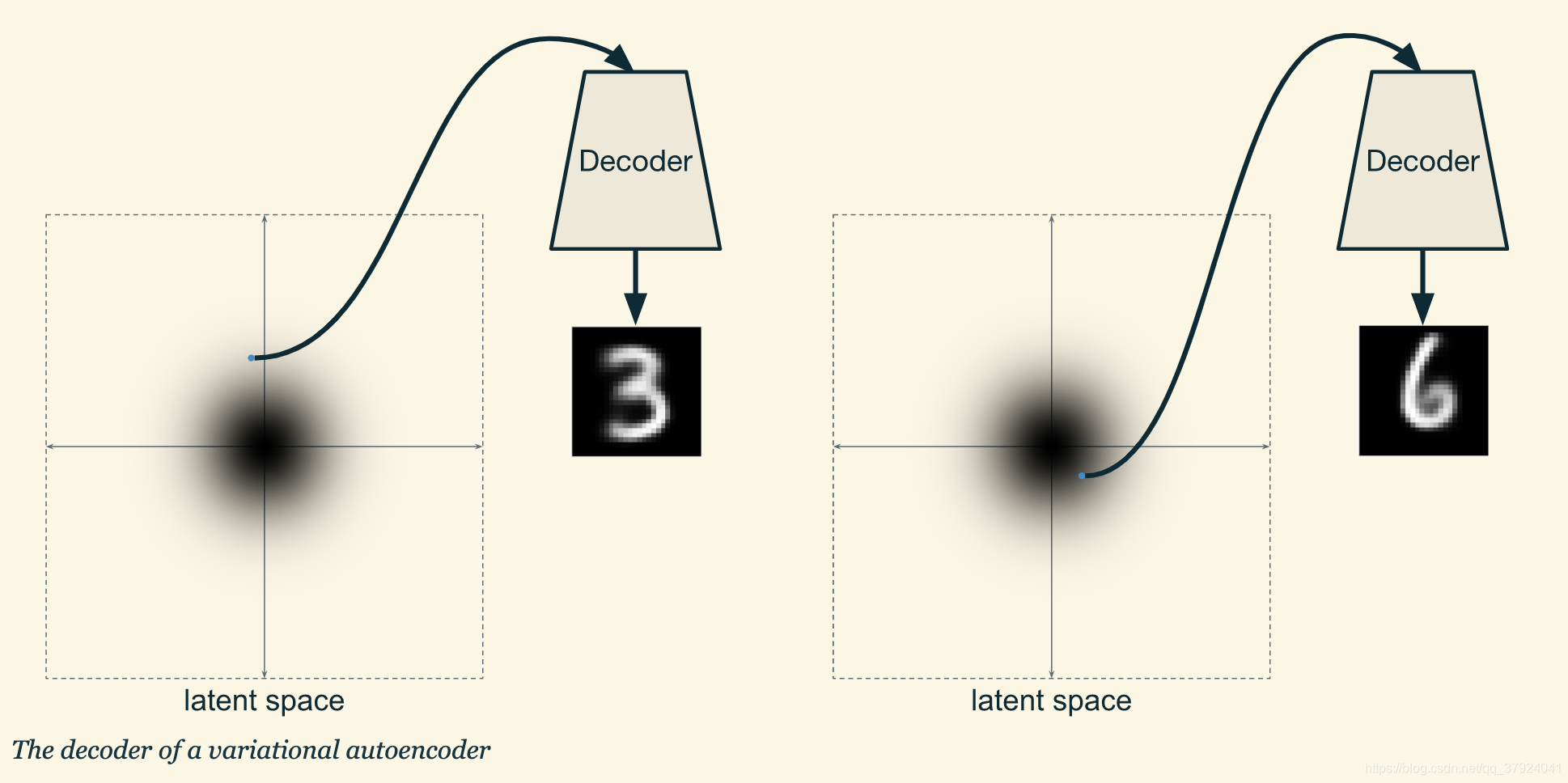
综上所述,我们有了一个可以将输入数据转化为概率分布的编码器,又有了一个将隐空间中的一个点转化为图像的解码器。所以每次输入一张手写数字图像,编码器产生一个分布,然后我们在这个分布上采样,再将这个点输入解码器,就能得到一个合适的图像。
隐空间的结构
注意:前面说过解码器读入的点需要从一个标准正态分布中采样,但我们又说编码器产生的概率分布不一定是标准正态分布,似乎发生了矛盾。但其实不然。我们现在只需要保证:从编码器产生的概率分布中被采样的点集仍然接近标准正态分布即可。也就是:
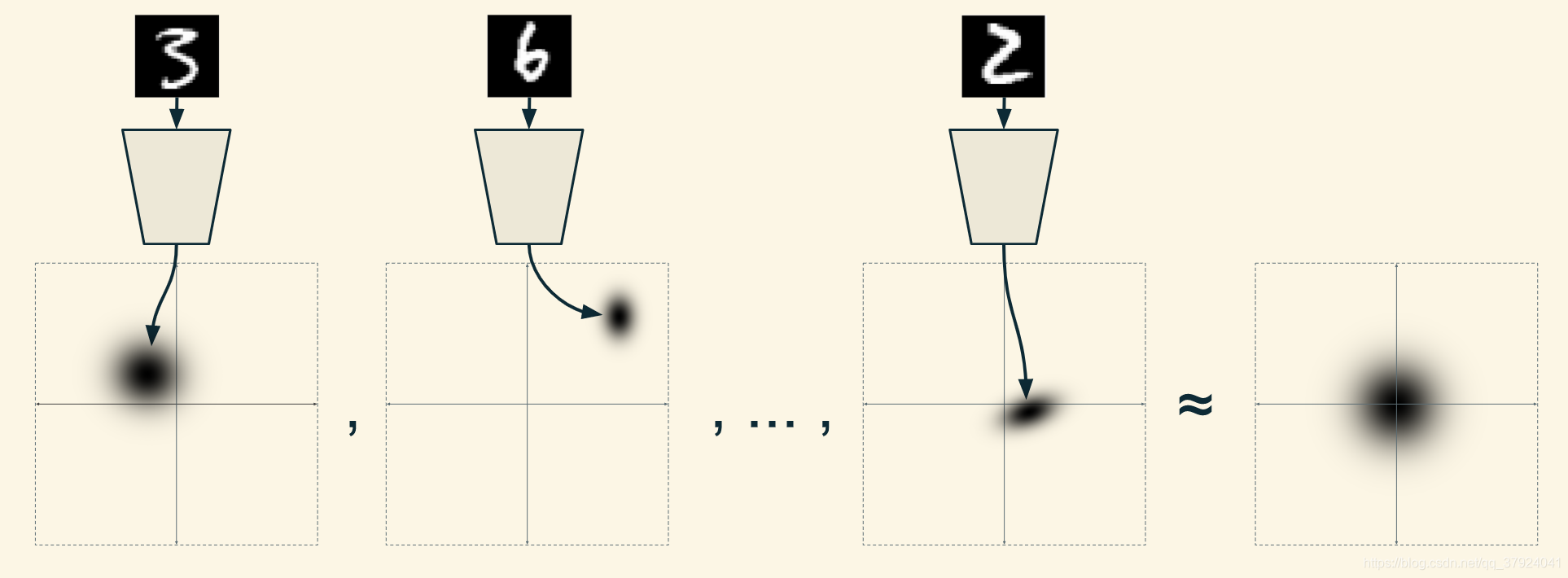
也就是说,(对于同一种数字而言)我们只需要保证不同训练样本产生的概率分布的平均值符合标准正态分布即可。这样解码器读入的点需要从一个标准正态分布中采样这个假设也就成立了。
显然,我们需要有一个方法来评价每一类概率分布的总和有多接近标准正态分布。KL散度(Kullback-Leibler divergence)便是一个方法。KL散度可以用来评价两个分布之间的区别有多大。这在Doersch的论文中有更为详细的解释。
用重参数化训练VAE
VAE的训练存在一个问题:由于编码器和解码器中存在一个随机化参数(随机采样),这直接导致我们无法使用BP(backpropagate,反向传播)来训练网络。这里,VAE使用了一个特别的方法:将隐分布的参数和随机化参数分离开来,这就使得反向传播得以进行。稍微具体一些,就是利用了这个公式:
N
(
μ
,
Σ
)
=
μ
+
Σ
N
(
0
,
I
)
N(μ,Σ) = μ + Σ N(0, I)
N(μ,Σ)=μ+ΣN(0,I)
详情请见其他文档。
由于有随机变量在反向传播的过程中,所以这个方法的名字是变分贝叶斯推断(stochastic gradient variational Bayes, SGVB),而不再是随机梯度下降
条件式变换自编码机(conditional variational autoencoders,CVAE)
CVAE只比VAE多了一个东西:条件。具体而言,可以拿MNIST举例:
每次输入编码器和解码器的时候,都输入一个标签(label),这样机器学习训练的时候就可以变成一个热词的向量了。即使两个点在相同位置,根据标签的不同,我们也就可以得到不同的生成图像。
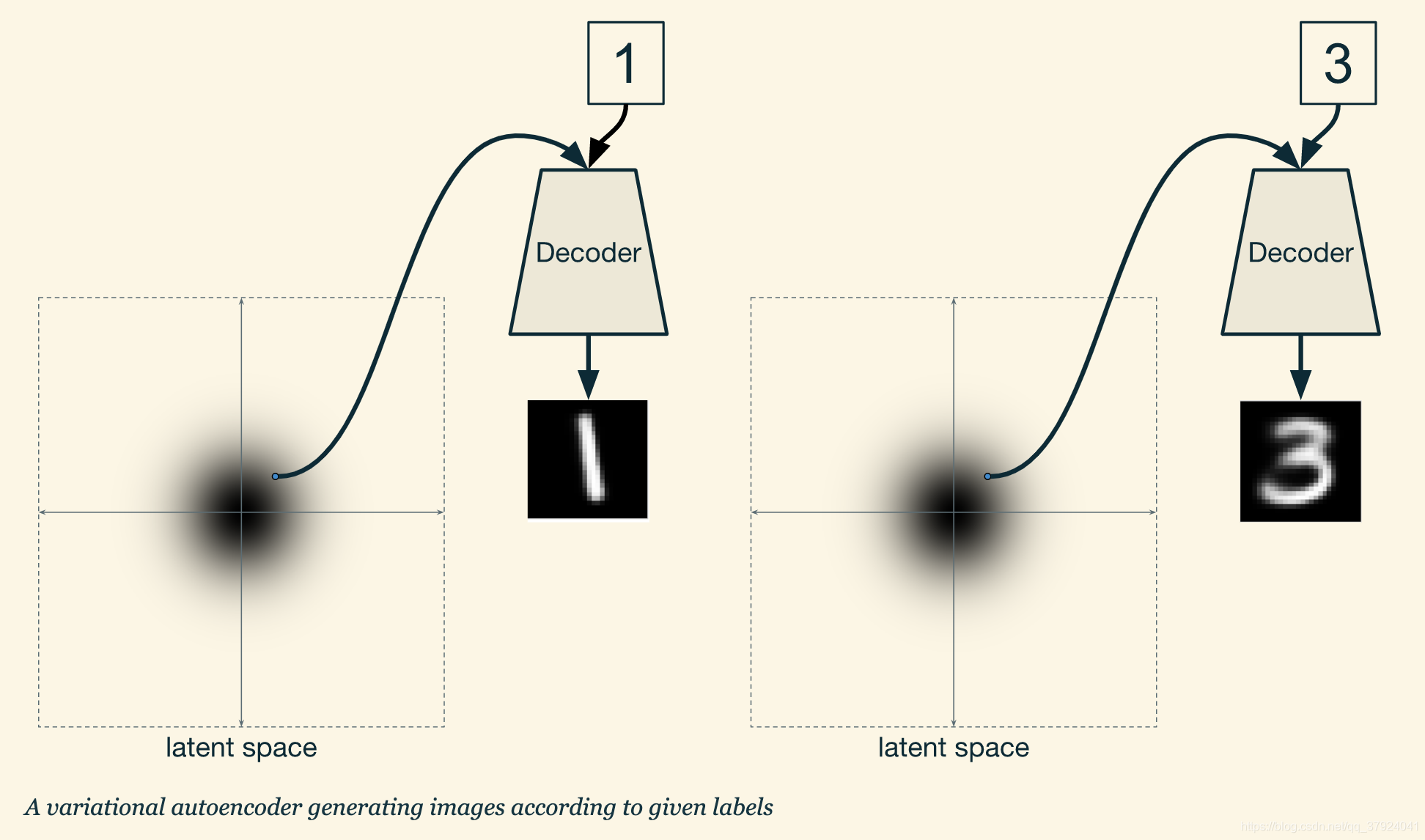
下图便是使用CVAE生成的MNIST结果图:


















 4546
4546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









