







目录
一、Spring Cloud 综述
(一)Spring Cloud 是什么

Spring Cloud是一系列框架的有序集合(Spring Cloud是一个规范)
开发服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等
利用Spring Boot的开发便利性简化了微服务架构的开发(自动装配)

这里,我们需要注意,Spring Cloud其实是一套规范,是一套用于构建微服务架构的规范,而不是一个可以拿来即用的框架(所谓规范就是应该有哪些功能组件,然后组件之间怎么配合,共同完成什么事情)。在这个规范之下第三方的Netflix公司开发了一些组件、Spring官方开发了一些框架/组件,包括第三方的阿里巴巴开发了一套框架/组件集合Spring Cloud Alibaba,这些才是Spring Cloud规范的实现。
Netflix搞了一套 简称SCN
Spring Cloud 吸收了Netflix公司的产品基础之上自己也搞了几个组件
阿里巴巴在之前的基础上搞出了一堆微服务组件,Spring Cloud Alibaba(SCA)
(二)Spring Cloud 解决什么问题
Spring Cloud 要解决的问题是微服务架构实施过程中存在的一些问题:
比如微服务架构中的服务注册发现问题、网络问题(比如熔断场景)、统一认证安全授权问题、负载均衡问题、链路追踪等问题。
(三)Spring Cloud 架构
如前所述,Spring Cloud是一个微服务相关规范,这个规范意图为搭建微服务架构提供一站式服务,采用组件(框架)化机制定义一系列组件,各类组件针对性的处理微服务中的特定问题,这些组件共同来构成Spring Cloud微服务技术栈。
1、Spring Cloud 核心组件
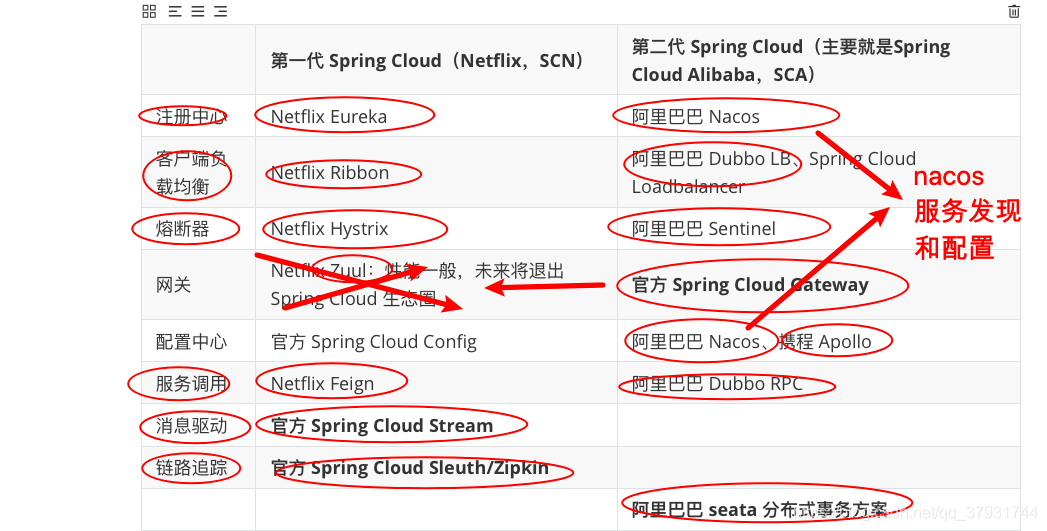
2、Spring Cloud 体系结构(组件协同⼯作机制)
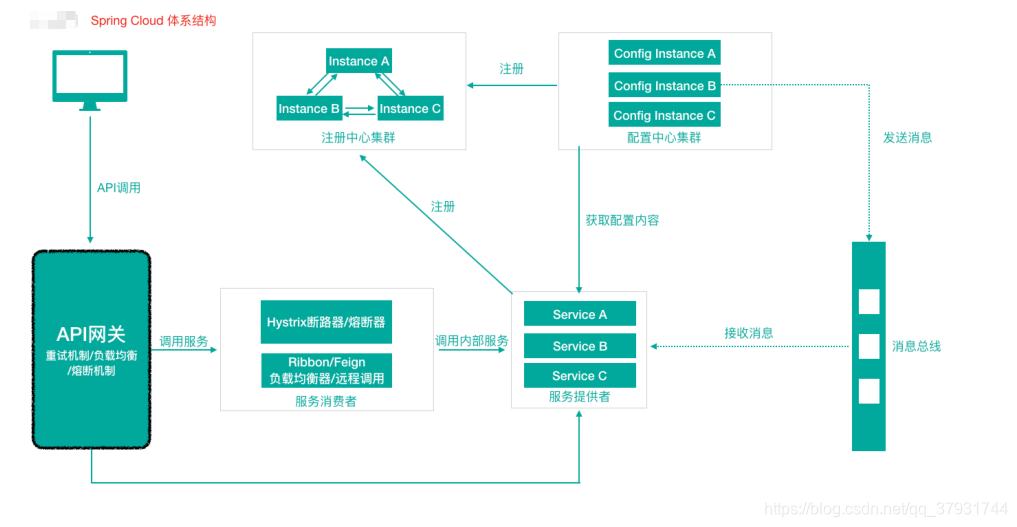
Spring Cloud中的各组件协同⼯作,才能够支持一个完整的微服务架构。比如
- 注册中心负责服务的注册与发现,很好将各服务连接起来
- API网关负责转发所有外来的请求
- 断路器负责监控服务之间的调用情况,连续多次失败进行熔断保护。
- 配置中心提供了统一的配置信息管理服务,可以实时的通知各个服务获取最新的配置信息
(四)Spring Cloud 与 Dubbo 对比

(五)Spring Cloud 与 Spring Boot 的关系

二、第一代 Spring Cloud 核心组件
(一)Eureka服务注册中心
1、关于服务注册中心
注意:服务注册中心本质上是为了解耦服务提供者和服务消费者。
对于任何一个微服务,原则上都应存在或者支持多个提供者(比如简历微服务部署 多个实例),这是由微服务的分布式属性决定的。
更进一步,为了支持弹性扩缩容特性,一个微服务的提供者的数量和分布往往是动 态变化的,也是⽆法预先确定的。因此,原本在单体应用阶段常用的静态LB机制就 不再适用了,需要引入额外的组件来管理微服务提供者的注册与发现,而这个组件 就是服务注册中心。
①服务注册中心一般原理
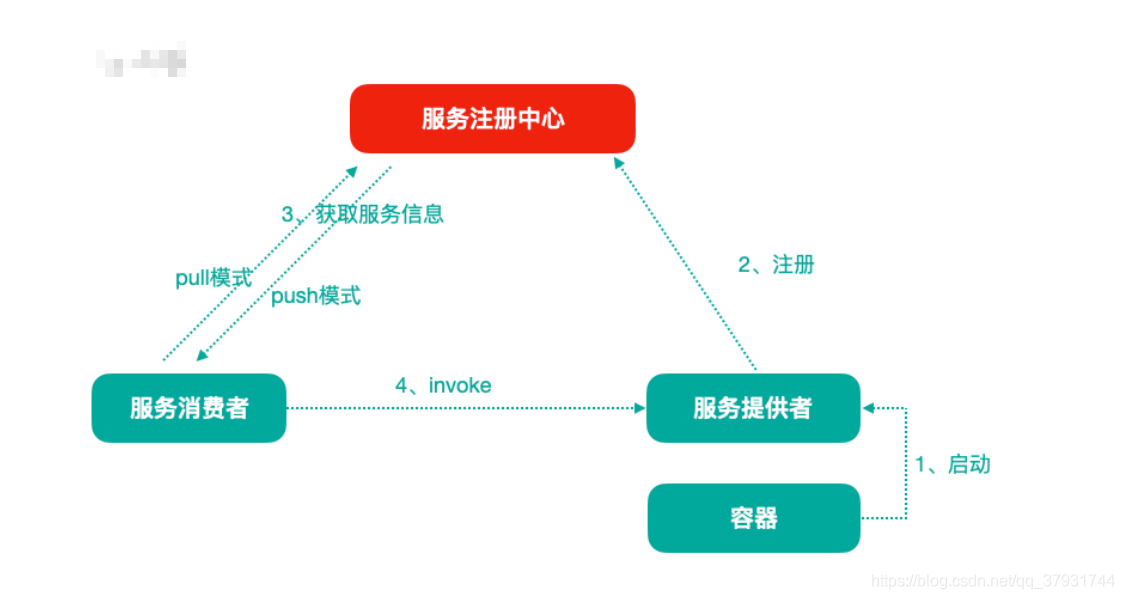
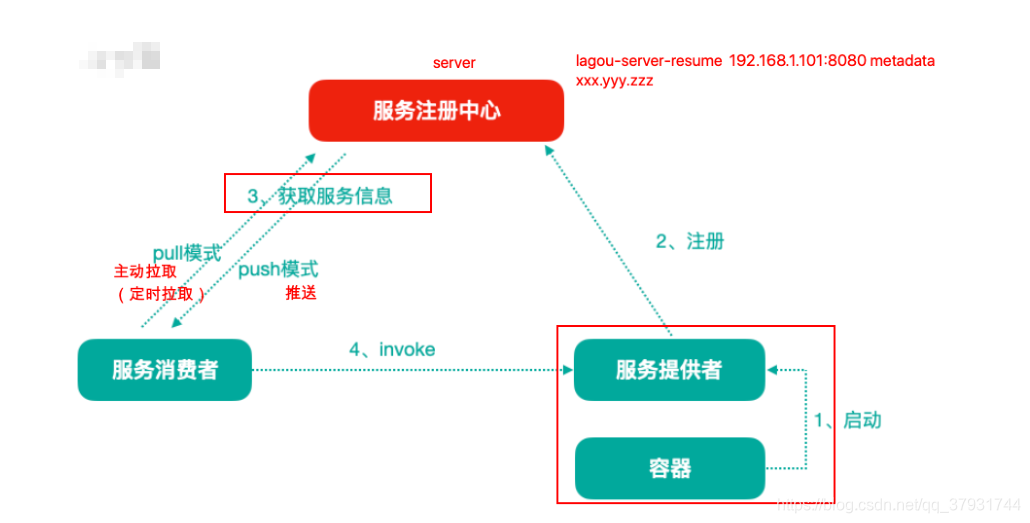
分布式微服务架构中,服务注册中心用于存储服务提供者地址信息和服务发布相关 的属性信息,消费者通过主动查询和被动通知的方式获取服务提供者的地址信息, 而不再需要通过硬编码方式得到提供者的地址信息。消费者只需要知道当前系统发 布了那些服务,而不需要知道服务具体存在于什么位置,这就是透明化路由。
- 服务提供者启动
- 服务提供者将相关服务信息主动注册到注册中心
- 服务消费者获取服务注册信息:
- pull模式:服务消费者可以主动拉取可用的服务提供者清单
- push模式:服务消费者订阅服务(当服务提供者有变化时,注册中心也会主动推送 更新后的服务清单给消费者
- 服务消费者直接调用服务提供者
另外,注册中心也需要完成服务提供者的健康监控,当发现服务提供者失效时需要 及时剔除;
②主流服务中心对比
Zookeeper
Zookeeper它是一个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
简单来说zookeeper本质=存储+监听通知。 znode Zookeeper 用来做服务注册中心,主要是因为它具有节点变更通知功能,只要客户端监听相关服务节点,服务节点的所有变更,都能及时的通知到监听客户端,这样作为调用方只要使用 Zookeeper 的客户端就能实现服务节点的订阅和变更通知功能了,⾮常方便。
另外,Zookeeper 可用性也可以,因为只要半数以上的选举节点存活,整个集群就是可用的。
Eureka
由Netflix开源,并被Pivatal集成到SpringCloud体系中,它是基于 RestfulAPI ⻛格开发的服务注册与发现组件。
Consul
Consul是由HashiCorp基于Go语⾔开发的支持多数据中心分布式⾼可用的服务 发布和注册服务软件,采用Raft算法保证服务的一致性,且支持健康检查。
Nacos
Nacos是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平 台。简单来说 Nacos 就是 【注册中心 + 配置中心】的组合,帮助我们解决微服务开发必会涉及到的服务注册与发现,服务配置,服务管理等问题。
Nacos 是 Spring Cloud Alibaba 核心组件之一,负责服务注册与发现,还有配置。
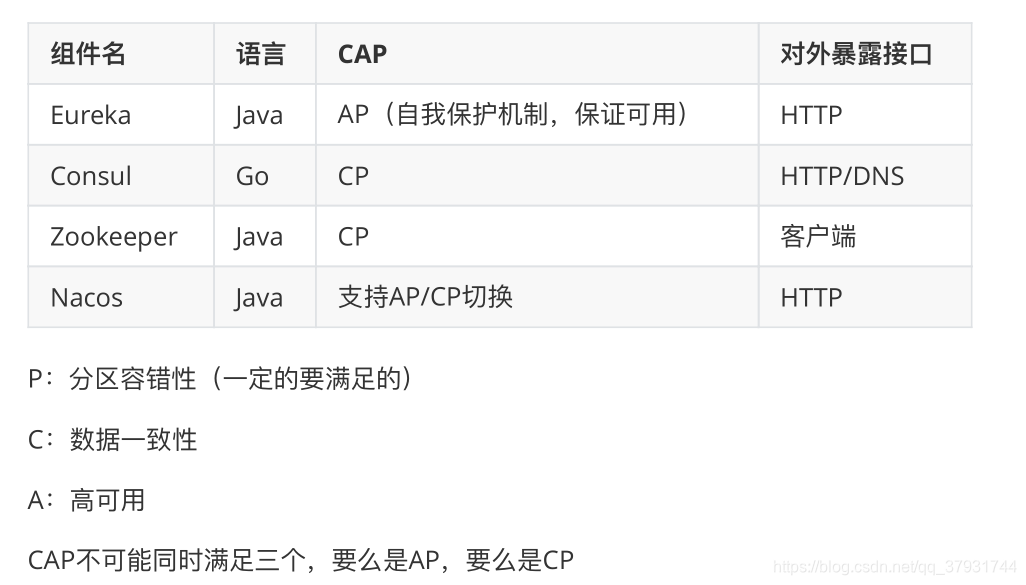
2、服务注册中心组件 Eureka
①Eureka 基础架构
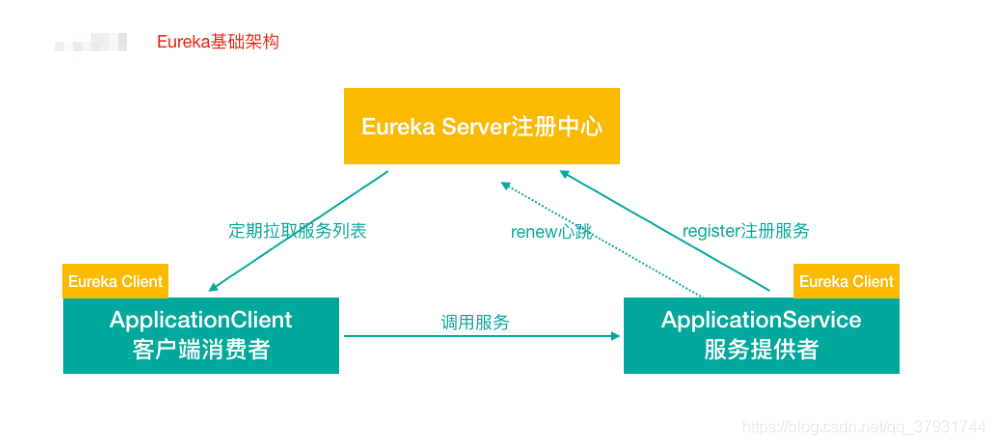
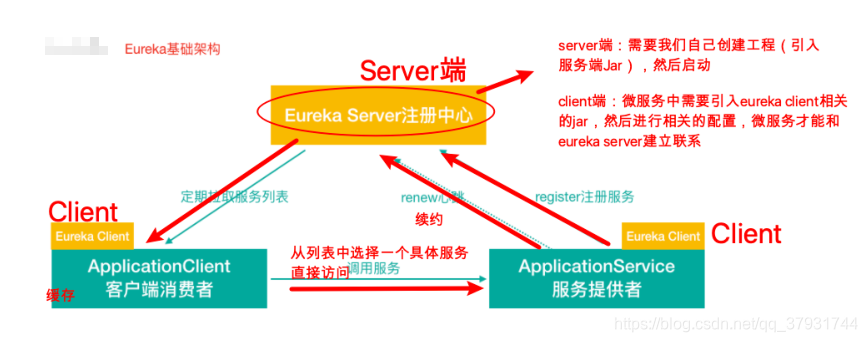
②Eureka 交互流程及原理
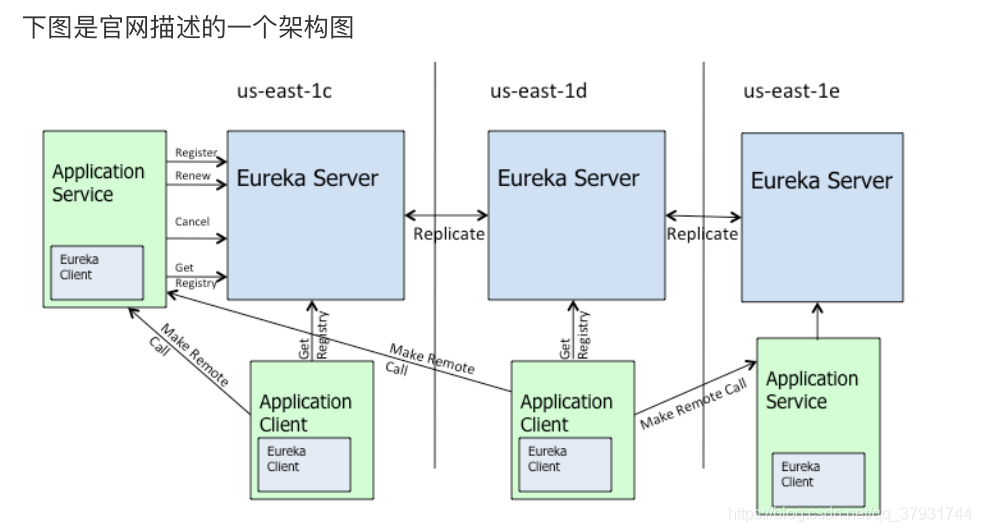
Eureka 包含两个组件:Eureka Server 和 Eureka Client,Eureka Client是一个 Java客户端,用于简化与Eureka Server的交互;Eureka Server提供服务发现的 能⼒,各个微服务启动时,会通过Eureka Client向Eureka Server 进行注册自己 的信息(例如网络信息),Eureka Server会存储该服务的信息;
- 图中us-east-1c、us-east-1d,us-east-1e代表不同的区也就是不同的机房
- 图中每一个Eureka Server都是一个集群。
- 图中Application Service作为服务提供者向Eureka Server中注册服务, Eureka Server接受到注册事件会在集群和分区中进行数据同步,Application Client作为消费端(服务消费者)可以从Eureka Server中获取到服务注册信 息,进行服务调用。
- 微服务启动后,会周期性地向Eureka Server发送心跳(默认周期为30秒) 以续约自己的信息
- Eureka Server在一定时间内没有接收到某个微服务节点的心跳,Eureka Server将会注销该微服务节点(默认90秒)
- 每个Eureka Server同时也是Eureka Client,多个Eureka Server之间通过复 制的方式完成服务注册列表的同步
- Eureka Client会缓存Eureka Server中的信息。即使所有的Eureka Server节 点都宕掉,服务消费者依然可以使用缓存中的信息找到服务提供者
Eureka通过心跳检测、健康检查和客户端缓存等机制,提⾼系统的灵活性、可伸缩性和可用性。
3、实例演示
(二)Ribbon负载均衡
(三)Hystrix熔断器
(四)Feign远程调用组件
feign介绍及基本应用
Feign支持的其他组件介绍及配置
(五)GateWay网关组件
(六)Spring Cloud Config 分布式配置中心
(七)Spring Cloud Stream消息驱动组件
三、常见问题及解决方案
Eureka 服务发现慢的原因,Spring Cloud 超时设置问题。
问题场景
- 上线一个新的服务实例,但是服务消费者⽆感知,过了一段时间才知道
- 某一个服务实例下线了,服务消费者⽆感知,仍然向这个服务实例在发起请求
这其实就是服务发现的一个问题,当我们需要调用服务实例时,信息是从注册中心Eureka获取的,然后通过Ribbon选择一个服务实例发起调用,如果出现调用不到或者下线后还可以调用的问题,原因肯定是服务实例的信息更新不及时导致的。
(一)Eureka 服务发现慢的原因
Eureka 服务发现慢的原因主要有两个,一部分是因为服务缓存导致的,另一部分是因为客户端缓存导致的。
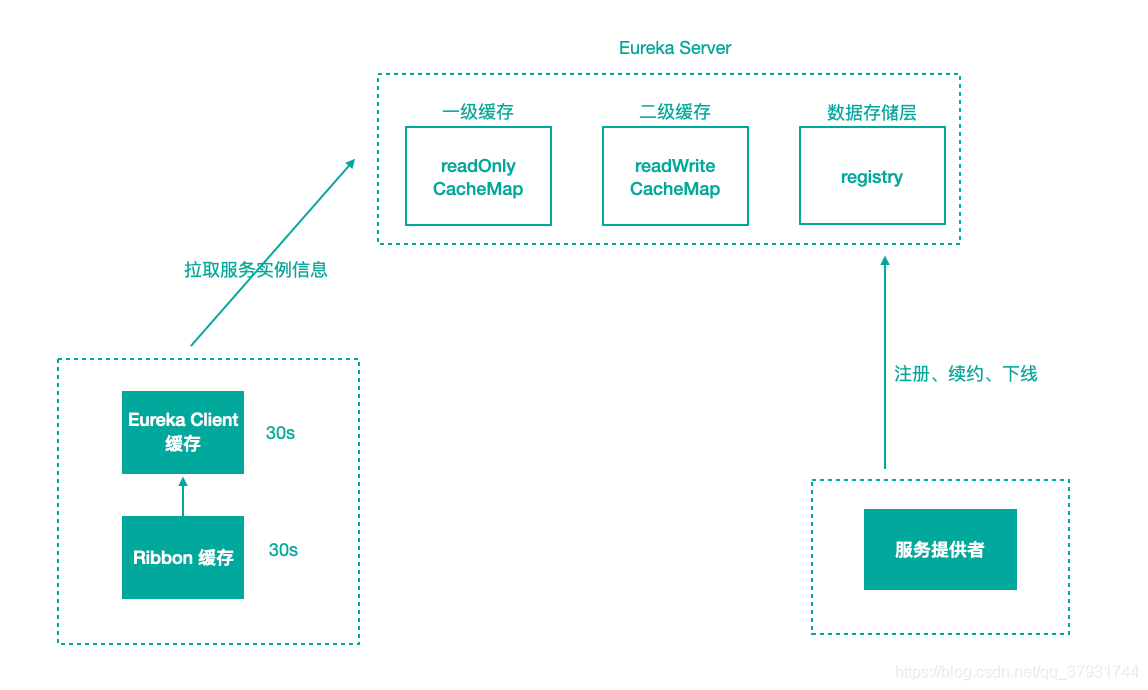
1、服务端缓存
服务注册到注册中心后,服务实例信息是存储在注册表中的,也就是内存中。但Eureka为了提⾼响应速度,在内部做了优化,加入了两层的缓存结构,将Client需要的实例信息,直接缓存起来,获取的时候直接从缓存中拿数据然后响应给 Client。
第一层缓存是readOnlyCacheMap。readOnlyCacheMap是采用ConcurrentHashMap来存储数据的,主要负责定时与readWriteCacheMap进行数据同步,默认同步时间为 30 秒一次。
第二层缓存是readWriteCacheMap。readWriteCacheMap采用Guava来实现缓存。缓存过期时间默认为180秒,当服务下线、过期、注册、状态变更等操作都会清除此缓存中的数据。Client获取服务实例数据时,会先从一级缓存中获取,如果一级缓存中不存在,再从二级缓存中获取,如果二级缓存也不存在,会触发缓存的加载,从存储层拉取数据到缓存中,然后再返回给 Client。
Eureka 之所以设计二级缓存机制,也是为了提⾼ Eureka Server 的响应速度,缺点是缓存会导致 Client 获取不到最新的服务实例信息,然后导致⽆法快速发现新的服务和已下线的服务。
了解了服务端的实现后,想要解决这个问题就变得很简单了,我们可以缩短只读缓存的更新时间(eureka.server.response-cache-update-interval-ms)让服务发现变得更加及时,或者直接将只读缓存关闭(eureka.server.use-read-only-response-cache=false),多级缓存也导致C层面(数据一致性)很薄弱。
Eureka Server 中会有定时任务去检测失效的服务,将服务实例信息从注册表中移除,也可以将这个失效检测的时间缩短,这样服务下线后就能够及时从注册表中清除。
2、客户端缓存
客户端缓存主要分为两块内容,一块是 Eureka Client 缓存,一块是Ribbon 缓存。
①Eureka Client 缓存
EurekaClient负责跟EurekaServer进行交互,在EurekaClient中的com.netflix.discovery.DiscoveryClient.initScheduledTasks() 方法中,初始化了一个 CacheRefreshThread 定时任务专⻔用来拉取 Eureka Server 的实例信息到本地。
所以我们需要缩短这个定时拉取服务信息的时间间隔(eureka.client.registryFetchIntervalSeconds)来快速发现新的服务。
②Ribbon 缓存
Ribbon会从EurekaClient中获取服务信息,ServerListUpdater是Ribbon中负责服务实例更新的组件,默认的实现是PollingServerListUpdater,通过线程定时去更新实例信息。定时刷新的时间间隔默认是30秒,当服务停止或者上线后,这边最快也需要30秒才能将实例信息更新成最新的。我们可以将这个时间调短一点,比如 3 秒。
刷新间隔的参数是通过 getRefreshIntervalMs 方法来获取的,方法中的逻辑也是从Ribbon 的配置中进行取值的。将这些服务端缓存和客户端缓存的时间全部缩短后,跟默认的配置时间相比,快了很多。我们通过调整参数的方式来尽量加快服务发现的速度,但是还是不能完全解决报错的问题,间隔时间设置为3秒,也还是会有间隔。所以我们一般都会开启重试功能,当路由的服务出现问题时,可以重试到另一个服务来保证这次请求的成功。
(二)Spring Cloud 各组件超时
在SpringCloud中,应用的组件较多,只要涉及通信,就有可能会发生请求超时。那么如何设置超时时间? 在 Spring Cloud 中,超时时间只需要重点关注 Ribbon 和Hystrix 即可。
1、Ribbon
如果采用的是服务发现方式,就可以通过服务名去进行转发,需要配置Ribbon的超时。Rbbon的超时可以配置全局的ribbon.ReadTimeout和ribbon.ConnectTimeout。也可以在前面指定服务名,为每个服务单独配置,比如user-service.ribbon.ReadTimeout。
2、Hystrix
其次是Hystrix的超时配置,Hystrix的超时时间要大于Ribbon的超时时间,因为Hystrix将请求包装了起来,特别需要注意的是,如果Ribbon开启了重试机制,比如重试3 次,Ribbon 的超时为 1 秒,那么Hystrix 的超时时间应该大于 3 秒,否则就会出现 Ribbon 还在重试中,而 Hystrix 已经超时的现象。
Hystrix全局超时配置就可以用default来代替具体的command名称。hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=3000 如果想对具体的 command 进行配置,那么就需要知道 command 名称的生成规则,才能准确的配置。
如果我们使用 @HystrixCommand 的话,可以自定义 commandKey。如果使用FeignClient的话,可以为FeignClient来指定超时时间:hystrix.command.UserRemoteClient.execution.isolation.thread.timeoutInMilliseconds = 3000
如果想对FeignClient中的某个接口设置单独的超时,可以在FeignClient名称后加上具体的方法:hystrix.command.UserRemoteClient#getUser(Long).execution.isolation.thread.timeoutInMilliseconds = 3000
3、Feign
Feign本身也有超时时间的设置,如果此时设置了Ribbon的时间就以Ribbon的时间为准,如果没设置Ribbon的时间但配置了Feign的时间,就以Feign的时间为准。Feign的时间同样也配置了连接超时时间(feign.client.config.服务名称.connectTimeout)和读取超时时间(feign.client.config.服务名称.readTimeout)。
建议,我们配置Ribbon超时时间和Hystrix超时时间即可。
四、Spring Cloud⾼级进阶
(一)微服务监控之 Turbine 聚合监控
参考之前的hystrix高级应用进阶
(二)微服务监控之分布式链路追踪技术 Sleuth + Zipkin
1、 分布式链路追踪技术适用场景(问题场景)
①场景描述
为了支撑日益增长的庞大业务量,我们会使用微服务架构设计我们的系统,使得我们的系统不仅能够通过集群部署抵挡流量的冲击,又能根据业务进行灵活的扩展。
那么,在微服务架构下,一次请求少则经过三四次服务调用完成,多则跨越几十个甚至是上百个服务节点。那么问题接踵而来:
- 如何动态展示服务的调用链路?(比如A服务调用了哪些其他的服务—依赖关系)
- 如何分析服务调用链路中的瓶颈节点并对其进行调优?(比如A—>B—>C,C服务处理时间特别长)
- 如何快速进行服务链路的故障发现?
这就是分布式链路追踪技术存在的目的和意义
②分布式链路追踪技术
如果我们在一个请求的调用处理过程中,在各个链路节点都能够记录下日志,并最终将日志进行集中可视化展示,那么我们想监控调用链路中的一些指标就有希望了~~~比如,请求到达哪个服务实例?请求被处理的状态怎样?处理耗时怎样?这些都能够分析出来了…
分布式环境下基于这种想法实现的监控技术就是就是分布式链路追踪(全链路追踪)。
③市场上的分布式链路追踪方案
分布式链路追踪技术已然成熟,产品也不少,国内外都有,比如
- Spring Cloud Sleuth + Twitter Zipkin
- 阿里巴巴的“鹰眼”
- 大众点评的“CAT”
- 美团的“Mtrace”
- 京东的“Hydra”
- 新浪的“Watchman”
另外还有最近也被提到很多的Apache Skywalking。
只不过,常用的还是Sleuth + Zipkin以及Skywalking。其他的都是各家自己用的多,因为社区不活跃,文档也不完善。
2、分布式链路追踪技术核心思想
本质:记录日志,作为一个完整的技术,分布式链路追踪也有自己的理论和概念。微服务架构中,针对请求处理的调用链可以展现为一棵树。
示意如下:
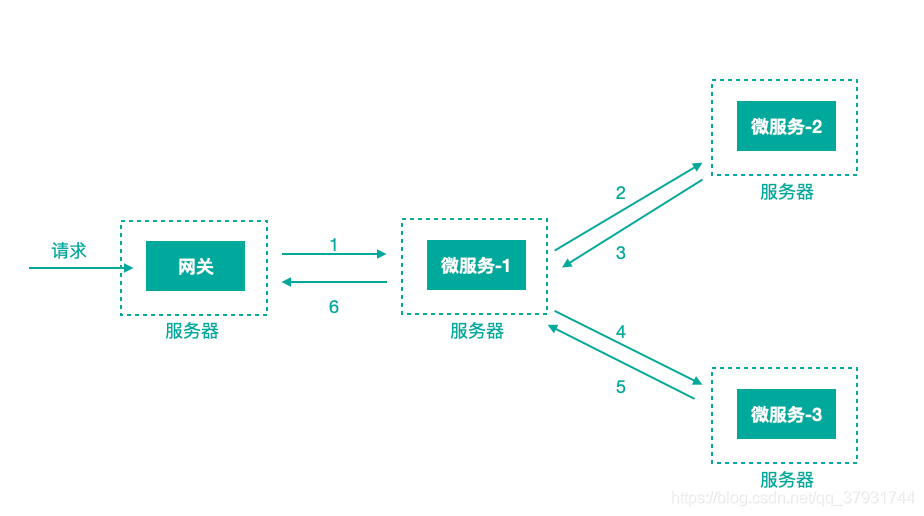
上图描述了一个常见的调用场景,一个请求通过网关服务路由到下游的微服务-1,然后微服务-1调用微服务-2,拿到结果后再调用微服务-3,最后组合微服务-2和微服务-3的结果,通过网关返回给用户
为了追踪整个调用链路,肯定需要记录日志,日志记录是基础,在此之上肯定有一些理论概念,当下主流的的分布式链路追踪技术/系统所基于的理念都来自于Google的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,这里面涉及到的核心理念是什么,我们来看下,还以前面的服务调用来说
上图标识一个请求链路,一条链路通过TraceId唯一标识,span标识发起的请求信息,各span通过parrentId关联起来。
Trace:服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程
Trace ID:是每次请求的唯一标识。为了实现请求跟踪,当请求发送到分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的跟踪标识Trace ID,同时在分布式系统内部流转的时候,框架始终保持该唯一标识,直到返回给请求方
一个Trace由一个或者多个Span组成,每一个Span都有一个SpanId,Span中会记录TraceId,同时还有一个叫做ParentId,指向了另外一个Span的SpanId,表明父子关系,其实本质表达了依赖关系
Span ID:每个时机点唯一。为了统计各处理单元的时间延迟,当请求到达各个服务组件时,也是通过一个唯一标识Span ID来标记它的开始,具体过程以及结束。对每一个Span来说,它必须有开始和结束两个节点,通过记录开始Span和结束Span的时间戳,就能统计出该Span的时间延迟,除了时间戳记录之外,它还可以包含一些其他元数据,比如时间名称、请求信息等。
每一个Span都会有一个唯一跟踪标识 Span ID,若干个有序的 span 就组成了一个trace。
Span可以认为是一个日志数据结构,在一些特殊的时机点会记录了一些日志信息,比如有时间戳、spanId、TraceId,parentIde等,Span中也抽象出了另外一个概念,叫做事件.
核心事件如下
CS:client send(/start)。 客户端(/消费者)发出一个请求,描述的是一个span开始SR: server received(/start)。 服务端(/生产者)接收请求。 SR-CS属于请求发送的网络延迟SS: server send(/finish )。服务端(/生产者)发送应答。 SS-SR属于服务端消耗时间CR:client received(/finished)。 客户端(/消费者)接收应答。 CR-SS表示回复需要的时间(响应的网络延迟)
Spring Cloud Sleuth (追踪服务框架)可以追踪服务之间的调用,Sleuth可以记录一个服务请求经过哪些服务、服务处理时长等,根据这些,我们能够理清各微服务间的调用关系及进行问题追踪分析。
耗时分析:通过 Sleuth 了解采样请求的耗时,分析服务性能问题(哪些服务调用比较耗时)链路优化:发现频繁调用的服务,针对性优化等Sleuth就是通过记录日志的方式来记录踪迹数据的
注意:我们往往把Spring Cloud Sleuth 和 Zipkin 一起使用,把 Sleuth 的数据信息发送给 Zipkin 进行聚合,利用 Zipkin 存储并展示数据。

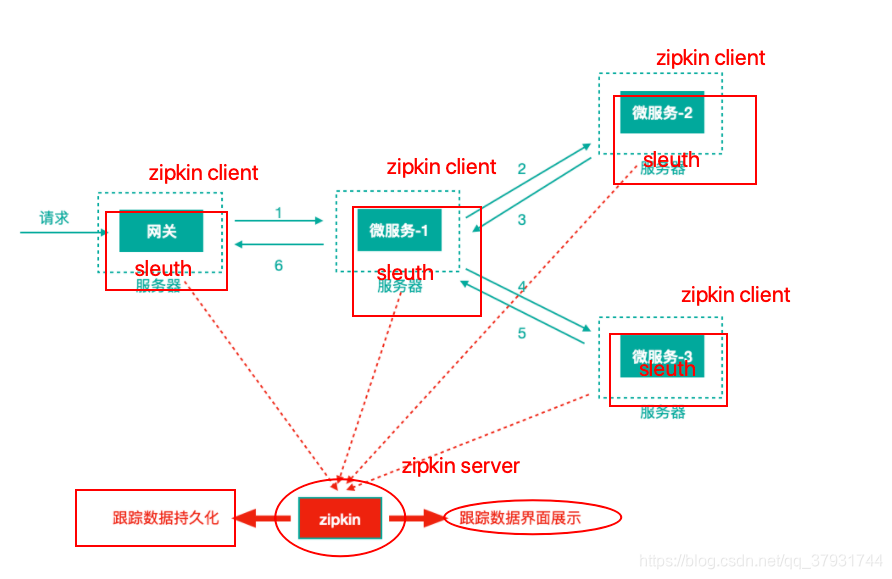
3、Sleuth + Zipkin
(三)微服务统一认证方案 Spring Cloud OAuth2 + JWT
1、微服务架构下统一认证思路
①基于Session的认证方式
在分布式的环境下,基于session的认证会出现⼀个问题,每个应用服务都需要在session中存储用户身份信息,通过负载均衡将本地的请求分配到另⼀个应用服务需要将session信息带过去,否则会重新认证。我们可以使用Session共享、Session黏贴等方案。
Session方案也有缺点,比如基于cookie,移动端不能有效使用等
②基于token的认证方式
基于token的认证方式,服务端不用存储认证数据,易维护扩展性强, 客户端可以把token 存在任意地方,并且可以实现web和app统⼀认证机制。
其缺点也很明显,token由于自包含信息,因此⼀般数据量较大,而且每次请求都需要传递,因此比较占带宽。
另外,token的签名验签操作也会给cpu带来额外的处理负担。
2、OAuth2开放授权协议/标准
微服务统⼀认证 Spring Cloud OAuth2 + JWT–》oauth
3、Spring Cloud OAuth2 + JWT 实现
微服务统⼀认证 Spring Cloud OAuth2 + JWT–》JWT














 2626
2626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









