






高并发深入理解

大数据 小数据
对数据技术的随意思考
“高数据库并发”要求到底意味着什么?
“”您必须在数据库中演示对1000个并发SQL的支持“
在Oracle和Greenplum工作期间,我在数据仓库POC规划期间多次听到类似的声明(在100到5000之间)。在每种情况下,所遵循的内容或多或少都是相同的。我努力了解它们的含义 - 真正的要求是什么 - 然后尝试调整POC指标以反映真实的客户目标。
回顾过去,这似乎是两个反复出现的混乱点。第一个是关于我们在谈论哪种类型的并发性。第二个问题是关于预期工作负载最终如何转换为数据库并发性。在这篇文章中,我将详细阐述第一点,后续讨论将讨论另一点。
要理解的关键是,在大多数客户中,大多数时候,当不同的人谈论并发时,每个人都可能意味着不同的事情。那么,它们意味着什么呢?这里有一些选择:
- 潜在用户 - 该应用程序的用户总数是多少?例如,有200名分析师可以访问BI系统,或者有50,000名外部用户可以访问该网站。
- 并发用户 - 在平均(或高峰)小时内连接到应用程序的用户数量是多少?例如,在高峰时段,120名分析师正在连接到该系统,或者有5,000名外部用户正在访问该网站。
- 并发活动用户 - 在任何给定时间有多少用户正在等待数据库?例如,在120位分析师中,在任何特定时刻,可能有20位正在等待,其余的正在分析报告输出(在应用程序中或外部使用excel或word等),接听电话和电子邮件或煮咖啡。
正如我将在下一篇文章中展示的那样,这是一个难以估计的事情,实际上是错误的问题。 - 并发数据库会话 - 从应用服务器到数据库的打开连接数量是多少?这通常是技术工件,源自应用程序服务器的连接池设置。它在帮助优化资源使用(重用连接)方面发挥了一定作用。
- 并发数据库SQL - 数据库看到和处理的活动SQL数量是多少?这里有一些复杂情况。例如,可能当用户打开仪表板时,应用程序打开十个数据库连接并提交十个并发SQL。
无论如何,再次估计这是一个棘手的问题,实际上是另一个错误的问题。
根据我的经验,在大多数情况下,初始并发要求基于并发用户,由于某种原因,它们被直接转换为并发数据库SQLs要求...
为什么这有关系?在许多情况下,初始引用并发要求与实际实际要求之间至少存在一个数量级的差异。因此,在POC期间,供应商和客户浪费了大量时间和精力来构建和测试在现实世界中不相关的大型场景。因此,所有决策过程都基于不相关的结果而存在偏差。
此外,这可能导致客户购买比实际需要更大的系统,浪费了大量资金,有时由于预算限制而不得不减少项目的其他关键方面(如专业服务)。这也是一种耻辱。
目前的结论 - 在规划POC时,三重检查客户IT和业务方面的并发性意味着什么,以及可能的预计工作量。如果新系统取代现有系统,请帮助他们从当前系统收集一些实际指标以验证其要求。哪些指标很重要?这是下一篇文章。
为什我们关心高并发的MySQL性能?
为什么我们关心高并发的MySQL性能?
在许多MySQL 基准测试中,我们可以看到性能与相当高的并发性水平相比。在某些情况下,达到4,000个或更多并发线程,这些线程尽可能快地敲击数据库,导致数百甚至数千个并发活动查询。
问题是它在生产中有多常见?用于并发定义为实际处理的查询数的典型度量标准是“Threads_Running”,您可以轻松地在生产系统中看到它:
| 1 2 3 4 5 6 7 | root@smt2:/mnt/data/ mysqladmin extended -i1 | grep Threads_running | Threads_running | 60 | | Threads_running | 61 | | Threads_running | 63 | | Threads_running | 62 | | Threads_running | 62 | | Threads_running | 46 | |
根据我的经验,该领域的大多数系统将以并发运行的速度不超过正常负载的低十。如果运行的线程数超过50-100并且在那里停留了很长时间,许多人都会设置监控设置。
因此,如果人们没有真正运行具有高并发性的MySQL,那么MySQL在高并发性方面的表现真的很重要,还是只是推广噱头来推广新的软件版本?
高并发性能很重要,但出于其他原因。真实世界系统与基准测试不同,它们通常没有固定的并发性,相反,它们必须服务于请求,因为它们可以接近“随机到达”但实际上在实践中可能要复杂得多。有可能几乎同时出现查询突发并且几乎同时命中数据库服务器(通常在外部系统上发生某些停顿时,例如memcached服务器)或数据库服务器本身都要经历“微停顿”可能导致查询的累积。这样的构建可以很快发生。
想象一下例如一些高容量的Web系统。它可能有100个Web服务器,每个服务器都配置了Apache,最多可以同时运行100个apache子节点,每个子节点可能会打开与MySQL服务器的连接...这最终会产生大量高达10K的连接并可能运行查询。现在想象一下,通常我们从Web级别进入30K查询/秒,平均延迟大约为1ms,这需要同时运行大约30个查询。想象一下,现在数据库的停顿时间只有100毫秒 - 你很可能甚至不会用肉眼看到它。考虑到我们的流入速率,预计会有3000个查询需要备份,这很可能来自1000个或更多连接。
这就是High Concurrency的表现是生与死之间的差异。看一下这些图表 MySQL社区服务器的蓝线只有其1/4的峰值并发性能为1000,而带有线程池插件的MySQL企业版红线仍然非常接近峰值。
在实践中,这将意味着一个服务器将能够非常快速地处理积压并且在这样的停顿之后恢复,其他服务器将被压低并且可能无法服务于在水下越来越高的请求的流入。在这种情况下,某些系统可能永远无法恢复,直到Web服务器重新启动或从其他方式卸载它们,其他系统将恢复但需要花费更多时间并且会产生更多用户影响 - 在所有较慢响应之后将导致用户提交较少的请求系统减少负荷。
是的。高并发性能很重要,因为它可以帮助系统处于困境。但是,低中和并发性能也很重要,因为这将在正常运行期间定义系统性能。
PS我认为有兴趣的人可以看到高并发人员在现场运行服务器的程度。如果您可以为加载的生产服务器运行上面的命令(但是没有遇到困难),我认为这将非常有趣。
实际案例
问题:在高并发Web应用程序中扩展锁定
提问者:
我们的Web应用程序具有一定的资源类型,可以在多个用户之间共享,因此任何人都可以随时读取和写入。我们采用了通常的嫌疑人,数据库事务和具有到期时间的软件锁,并且用户基数低,并发性低,这种方法运行良好,并且防止了本来会发生的许多种族情况。
我们现在正在慢慢开始扩展并且发现有几百个并发用户,偶尔(大约每天一次)请求因为超时等待锁定而失败(我假设当许多人试图获取或是等待同一个锁)或数据库死锁。今天,这只是一个小麻烦,因为它仍然相对不频繁,受影响的用户可以重新尝试请求,它通常会通过。但我们自然担心这不会很好地扩展。
这种情况通常如何解决?我只能想象这是一个相对常见的问题,但我不确定在不必重新设计整个应用程序的情况下可以应用哪些具体技术。我们目前正在研究无锁设计,但乍一看似乎重写我们的应用程序是无锁的将是一项艰巨的任务。任何形式的建议将不胜感激。
回答:
欢迎来到并行和并发的深沉,黑暗的深处!这是许多应用开发者担心的地方 - 并且有充分的理由担心它。
这不是一个问题,而是一个非常大,非常棘手的问题。
大多数硬并发问题可以通过足够的努力和投资在规模上得到解决。然而,没有一个特别简单,容易或便宜。世界上所有的高并发解决方案 - 例如操作系统和数据库的内部,高规模的消息传递和交易系统,金融市场,旅行预订系统,全球网络应用程序 - 已经获得了大量持续的开发工作和投资,大多数情况多年或几十年。他们中的大多数都需要进行基本的引擎重写/旋转以达到新的规模平台。
听起来好像你处于其中一个高原状态。你对“不得不重新设计整个应用程序”和“乍一看它似乎是一项巨大的任务”的恐惧是有根据的。如果您对扩展高度并发的应用程序所涉及的工作没有感到沮丧,那么您只是不了解并发性。
我首先要重新考虑“多个用户共享的某种资源类型,因此可以随时由任何人阅读和编写”。是否真的可以让任何用户共享此资源/这些资源?或者只是许多用户可能分享每个?这是一个微妙的区别。如果真的每个人都可以分享(M:1),那就是真正的个人瓶颈。如果更准确地M:N,并且可以对可以共享N中的每一个的用户进行分组或分区,则可以更容易地解决它,例如通过
- Sharding Sharding会将用户及其相关的关键资源划分到不同的服务器上。通过分片/分区进行组织并不是自动化的简单方法,但它比许多其他并发策略更容易,因为它可以很好地降低强度将问题转化为较小的子问题,每个子问题都更易于管理和处理。如果纯分片不够,有时可以将分片与功能或数据传送相结合:即共享常见情况,然后将共享计算移动到数据所在位置,或动态识别可以更好地迁移到其他用户的用户分片,就像它们与之交互的其他资源一样被发现。和/或如果您的中央共享资源是主要读取或读取更多通常而不是写入,它也可以跨分片进行复制。
真正完整的共享问题更难 - 特别是如果您对关键共享资源进行了大量更新。
- 放大。对于某些比例范围,这可以通过“向上扩展”服务器来解决 - 购买更大的共享内存服务器。这些服务器比传统的网络设备贵很多,但是大内存补充和极高速的系统互连在解决通信/协调问题方面有很长的路要走。即使装备昂贵,您也不必担心软件重写,这可能使它们成为经济上的胜利。(“在大型机中发送!”)
- 并行放大。从那里回退的是逻辑上扩展的数据存储:并行数据库和中间件引擎(例如DB2,NonStop SQL,Teradata),虽然在内部并行,但在您的代码中看起来是统一的,不太并行的服务。(内部此类服务器通常使用InfiniBand或专有的低权限系统到系统互连,使它们成为完全“向上扩展”和分布式服务器之间的混合。)
然而,许多网络应用程序跳过各种级别的“向上扩展”解决方案并直接进入最后的边界:
- 完全分布。重写以使用具有公开并行性的中间件/服务。例如,Hadoop,Amazon Web Services的SimpleDB数据库和SQS排队服务,许多NoSQL数据库的并行模型,以及大多数高级Web服务(例如Twitter)的API语义。要使用这些,开发人员必须拥有与传统数据库提供的不同且通常更弱的并发语义(例如“最终一致性”),并且必须接受应用程序管理并发的责任(也是应用程序开发人员习惯的较弱的语义和服务级别)至)。这种对Web应用程序中暴露的并行性的偏好通常是文化的,因为许多Web应用程序都是“ 绿色领域”“并且强烈倾向于横向扩展策略和”并行一切“(实际上,”分发一切“,因为即使是扩展系统也是高度并行的)。
这个最终的“完全分布式,并行性暴露”基础设施在最高规模的网络应用程序(例如谷歌,Facebook,Twitter)中很受欢迎,但它也是你的“大型重写努力”恐惧最直接的地方,因为采用这些可能会改变您的应用管理互动/共享的级别。我建议在深入研究完全“最终一致性”和“重写不同共享语义”丛书之前,先审查更适度的分片和/或扩展策略的机会。
并发真的会提高性能吗?


如果您想提高程序的性能,一种可能的解决方案是添加并发编程技术。基本上,在并发执行中,同一程序的多个线程同时执行。它类似于添加更多工人来完成工作。
“并行性”是另一个经常用于并发的词。并行性是并发的一个子集。并发是指尝试同时执行多个操作,而并行操作指的是同时执行多个操作。
即使在单核处理器上,通过在线程之间切换也可以实现并发。在某个时刻,执行一个线程。然而,通过在线程之间切换并作为一个整体向前发展,会发生多种事情。
并行性发生在多核处理器上。由于存在多个核心,因此可以一次执行多个线程。在单核处理器上,实际的并行性是不可能的。但是,它试图通过快速切换线程来存档并行性。


同时解决问题似乎会极大地减少计算时间。但是,一切都需要付出代价。即使我们认为一次做很多事情会加快速度,但由于线程之间的通信以及确保它们不会崩溃或输出错误而导致成本增加。并发编程必须非常小心,它会导致编程不可避免的开销。
- 是时候初始化了
- 时间敲定
- 外部库导致的开销
- 线程之间的通信成本
通常,在编写并发程序时将使用外部库(例如,pThreads,OpenMP)。加载这些库会有一些开销。此外,将使用并发编程构建块(如信号量,互斥锁,锁),它们将花费初始化和最终确定时间。
其中最大的开销是由于线程之间的相互通信引起的。在并发设计中,产生错误结果的可能性很高,并且需要处理互斥以避免死锁或饥饿情况。
为了满足所有上述条件,需要大量的同步和信令,并且它将增加计算时间。这些开销是不可避免的,并且需要设计程序以尽可能最小化。
以下是用于演示与串行执行相比使用不同机制的并发编程的强大功能的示例。此处使用链接列表来执行插入,删除和成员操作。测量执行时间以比较性能。
在包含不同数量的插入,删除和成员操作的LinkedList上执行1000个操作。所有任务也以串行和并行方式执行。使用互斥锁和锁再次实现并行执行。
以下是使用pThreads库以C语言实现程序的代码段。
串行程序
#包括 < stdio.h中>
#包括 < stdlib.h中>
#包括< math.h中>
#包括 “ timer.h ”
struct Node {
int值;
struct Node * next;
};
int initialEntries; //初始插入到链表
int operationsCount; // totoal操作
float memberFraction; //成员操作分数
float insertFraction; //插入操作分数
float deleteFraction; //删除操作分数
int insertOperations; //插入操作
int memberOperations; //成员操作
int deleteOperations; //删除操作
void display_list(struct Node ** head_pp);
int insert(int val,struct Node ** head_pp);
int delete(int val,struct Node ** head_pp);
int member(int val,struct Node * head_p);
//将初始条目添加到linkedlist
void initial_insert(struct Node ** head_pp){
int inserts = 0 ;
while(inserts!= initialEntries){
int randVal = rand()%65536 ;
int result = member(randVal,* head_pp);
if(result == 0){
insert(randVal,head_pp);
插入++;
}
}
}
//插入操作
void add_operation(struct Node ** head_pp){
for(int i = 0 ; i <insertOperations; i ++){
int randVal = rand()%65536 ;
insert(randVal,head_pp);
}
}
//成员操作
void member_operation(struct Node * head_p){
for(int i = 0 ; i <memberOperations; i ++){
int randVal = rand()%65536 ;
成员(randVal,head_p);
// printf(“\ nsearching%d found%d \ n”,randVal,result);
}
}
//删除操作
void delete_operation(struct Node ** head_pp){
for(int i = 0 ; i <deleteOperations; i ++){
int randVal = rand()%65536 ;
删除(randVal,head_pp);
}
}
void clear_list(struct Node ** root){
struct Node * curr_p;
struct Node * succ_p;
if(* root == NULL){
回归 ;
}
curr_p = * root;
succ_p = curr_p-> next ;
while(succ_p!= NULL){
免费(curr_p);
curr_p = succ_p;
succ_p = curr_p-> next ;
}
免费(curr_p);
* root = NULL ;
}
// param 1 = #initial entries
// param 2 = #operations m
// param 3 = #member fraction
// param 4 = #insert fractoin
// param 5 = #delete fraction
int main(int argc,char * argv []){
int iterations = 100 ;
double sampleTime [iterations];
double totalTime = 0 ;
双倍平均时间;
double sumOfSquare = 0 ;
double stdDev;
双重开始,结束;
struct Node * head_p = NULL ;
struct Node ** head_pp =&head_p;
if(argc!= 6){
printf(“ \ n只输入5个参数\ n ”);
退出(0);
}
//读取命令行参数
initialEntries = strtol(argv [ 1 ],NULL,10);
operationsCount = strtol(argv [ 2 ],NULL,10);
memberFraction = strtod(argv [ 3 ],NULL);
insertFraction = strtod(argv [ 4 ],NULL);
deleteFraction = strtod(argv [ 5 ],NULL);
memberOperations = memberFraction * operationsCount;
insertOperations = insertFraction * operationsCount;
deleteOperations = deleteFraction * operationsCount;
for(int x = 0 ; x < 100 ; x ++){
//初始插入
initial_insert(head_pp);
// display_list(head_pp);
GET_TIME(开始);
member_operation(head_p); //成员操作
add_operation(head_pp); //插入操作
delete_operation(head_pp); //删除操作
GET_TIME(结束);
clear_list(head_pp);
sampleTime [x] =(end-start);
totalTime + =(end-start);
}
avgTime = totalTime / iterations;
for(int i = 0 ; i <iterations; i ++){
sumOfSquare + =(sampleTime [i] -avgTime)*(sampleTime [i] -avgTime);
}
stdDev = sqrt(sumOfSquare /(iterations- 1));
printf(“ \ n摘要...... \ n ”);
printf(“ ---------- MEMBERING %d ITEMS COMPLETE -------------- \ n ”,memberOperations);
printf(“ ---------- INSERTING %d ITEMS COMPLETE -------------- \ n ”,insertOperations);
printf(“ ---------- DELETING %d ITEMS COMPLETE --------------- \ n ”,deleteOperations);
printf(“总时间(ms):%f \ n ”,totalTime * 1000);
printf(“平均时间(毫秒):%f \ n ”,avgTime * 1000);
printf(“ Standerd Deviation(ms):%f ”,stdDev);
}
//显示当前的链表
void display_list(struct Node ** head_pp){
if(head_pp!= NULL){
struct Node * current = * head_pp;
while(current!= NULL){
printf(“ %d,”,current-> value);
current = current-> next ;
}
} else {
printf(“空列表”);
}
}
//插入元素功能
int insert(int val,struct Node ** head_pp){
struct Node * current = * head_pp;
struct Node * prev = NULL ;
struct Node * temp;
while(current!= NULL && current-> value <val){
prev =当前;
current = current-> next ;
}
if(current == NULL || current-> value > val){
temp = malloc(sizeof(struct Node));
temp-> value = val;
temp-> next = current;
if(prev == NULL){
* head_pp = temp;
} else {
prev-> next = temp;
}
返回 1 ;
} else {
返回 0 ;
}
}
//删除元素功能
int delete(int val,struct Node ** head_pp){
struct Node * current = * head_pp;
struct Node * prev = NULL ;
while(current!= NULL && current-> value <val){
prev =当前;
current = current-> next ;
}
if(current!= NULL && current-> value == val){
if(prev == NULL){
//删除头部
* head_pp = current-> next ;
免费(当前);
} else {
prev-> next = current-> next ;
免费(当前);
}
返回 1 ;
} else {
返回 0 ;
}
}
//成员元素功能
int member(int val,struct Node * head_p){
struct Node * current = head_p;
while(current!= NULL && current-> value <val){
current = current-> next ;
}
if(current == NULL || current-> value > val){
返回 0 ;
} else {
返回 1 ;
}
}
使用Mutex的并行程序
#包括 < stdio.h中>
#包括 < stdlib.h中>
#包括 < pthread.h >
#包括< math.h中>
#包括 “ timer.h ”
struct Node {
int值;
struct Node * next;
};
int initialEntries; //初始插入到链表
int operationsCount; // totoal操作
float memberFraction; //成员操作分数
float insertFraction; //插入操作分数
float deleteFraction; //删除操作分数
int threadCount; //正在执行的线程数
struct Node * head_p = NULL ;
struct Node ** head_pp =&head_p;
pthread_mutex_t mutexLock; //互斥的实例
int insertOperations;
int memberOperations;
int deleteOperations;
void display_list(struct Node ** head_pp);
int insert(int val,struct Node ** head_pp);
int delete(int val,struct Node ** head_pp);
int member(int val,struct Node * head_p);
//由线程执行的方法
void * run_threads(void * rank){
long id =(long)rank;
int operationType;
int localRun = operationsCount / threadCount;
for(int i = 0 ; i <localRun; i ++){
operationType =(id * localRun)+ i;
if(operationType <memberOperations){
//成员操作
pthread_mutex_lock(&mutexLock);
int randVal = rand()%65536 ;
成员(randVal,head_p);
pthread_mutex_unlock(&mutexLock);
} else if(operationType <(memberOperations + insertOperations)){
//插入操作
pthread_mutex_lock(&mutexLock);
int randVal = rand()%65536 ;
insert(randVal,head_pp);
pthread_mutex_unlock(&mutexLock);
} else {
//删除操作
pthread_mutex_lock(&mutexLock);
int randVal = rand()%65536 ;
删除(randVal,head_pp);
pthread_mutex_unlock(&mutexLock);
}
}
返回 0 ;
}
//将初始元素插入到链表
void initial_insert(struct Node ** head_pp){
int inserts = 0 ;
while(inserts!= initialEntries){
int randVal = rand()%65536 ;
int result = member(randVal,* head_pp);
if(result == 0){
insert(randVal,head_pp);
插入++;
}
}
}
void clear_list(struct Node ** root){
struct Node * curr_p;
struct Node * succ_p;
if(* root == NULL){
回归 ;
}
curr_p = * root;
succ_p = curr_p-> next ;
while(succ_p!= NULL){
免费(curr_p);
curr_p = succ_p;
succ_p = curr_p-> next ;
}
免费(curr_p);
* root = NULL ;
}
// param 1 = #initial entries
// param 2 = #operations m
// param 3 = #member fraction
// param 4 = #insert fractoin
// param 5 = #delete fraction
// param 6 = #number of threads
int main(int argc,char * argv []){
int iterations = 100 ;
double sampleTime [iterations];
double totalTime = 0 ;
双倍平均时间;
double sumOfSquare = 0 ;
double stdDev;
双重开始,结束;
长线程;
pthread_t * thread_handles;
if(argc!= 7){
printf(“ \ n只输入6个参数\ n ”);
退出(0);
}
//读取命令行参数
initialEntries = strtol(argv [ 1 ],NULL,10);
operationsCount = strtol(argv [ 2 ],NULL,10);
memberFraction = strtod(argv [ 3 ],NULL);
insertFraction = strtod(argv [ 4 ],NULL);
deleteFraction = strtod(argv [ 5 ],NULL);
threadCount = strtol(argv [ 6 ],NULL,10);
memberOperations = memberFraction * operationsCount;
insertOperations = insertFraction * operationsCount;
deleteOperations = deleteFraction * operationsCount;
for(int i = 0 ; i <iterations; i ++){
//初始插入
initial_insert(head_pp);
thread_handles = malloc(threadCount * sizeof(pthread_t)); //为线程分配内存
pthread_mutex_init(&mutexLock,NULL); //初始化互斥锁
GET_TIME(开始);
//执行线程
for(thread = 0 ; thread <threadCount; thread ++)
pthread_create(&thread_handles [thread],NULL,run_threads,(void *)thread);
for(thread = 0 ; thread <threadCount; thread ++){
pthread_join(thread_handles [thread],NULL);
}
GET_TIME(结束);
pthread_mutex_destroy(&mutexLock); //销毁互斥锁
sampleTime [i] =(end-start);
totalTime + =(end-start);
clear_list(head_pp);
free(thread_handles); //释放获得的记忆
}
avgTime = totalTime / iterations;
for(int i = 0 ; i <iterations; i ++){
sumOfSquare + =(sampleTime [i] -avgTime)*(sampleTime [i] -avgTime);
}
stdDev = sqrt(sumOfSquare /(iterations- 1));
printf(“ \ n摘要...... \ n ”);
printf(“ ---------- MEMBERING %d ITEMS COMPLETE -------------- \ n ”,memberOperations);
printf(“ ---------- INSERTING %d ITEMS COMPLETE -------------- \ n ”,insertOperations);
printf(“ ---------- DELETING %d ITEMS COMPLETE --------------- \ n ”,deleteOperations);
printf(“总时间(ms):%f \ n ”,totalTime * 1000);
printf(“平均时间(毫秒):%f \ n ”,avgTime * 1000);
printf(“ Standerd Deviation time(ms):%f \ n ”,stdDev);
}
//显示链表的元素
void display_list(struct Node ** head_pp){
if(head_pp!= NULL){
struct Node * current = * head_pp;
while(current!= NULL){
printf(“ %d,”,current-> value);
current = current-> next ;
}
} else {
printf(“空列表”);
}
}
//将元素插入到链表
int insert(int val,struct Node ** head_pp){
struct Node * current = * head_pp;
struct Node * prev = NULL ;
struct Node * temp;
while(current!= NULL && current-> value <val){
prev =当前;
current = current-> next ;
}
if(current == NULL || current-> value > val){
temp = malloc(sizeof(struct Node));
temp-> value = val;
temp-> next = current;
if(prev == NULL){
* head_pp = temp;
} else {
prev-> next = temp;
}
返回 1 ;
} else {
返回 0 ;
}
}
//从链表中删除元素
int delete(int val,struct Node ** head_pp){
struct Node * current = * head_pp;
struct Node * prev = NULL ;
while(current!= NULL && current-> value <val){
prev =当前;
current = current-> next ;
}
if(current!= NULL && current-> value == val){
if(prev == NULL){
//删除头部
* head_pp = current-> next ;
免费(当前);
} else {
prev-> next = current-> next ;
免费(当前);
}
返回 1 ;
} else {
返回 0 ;
}
}
//链表中的成员元素
int member(int val,struct Node * head_p){
struct Node * current = head_p;
while(current!= NULL && current-> value <val){
current = current-> next ;
}
if(current == NULL || current-> value > val){
返回 0 ;
} else {
返回 1 ;
}
}
并行程序使用锁
#包括 < stdio.h中>
#包括 < stdlib.h中>
#包括 < time.h中>
#包括 < pthread.h >
#包括< math.h中>
#包括 “ timer.h ”
struct Node {
int值;
struct Node * next;
};
int initialEntries; //初始插入到链表
int operationsCount; // totoal操作
float memberFraction; //成员操作分数
float insertFraction; //插入操作分数
float deleteFraction; //删除操作分数
int threadCount; //正在执行的线程数
struct Node * head_p = NULL ;
struct Node ** head_pp =&head_p;
pthread_rwlock_t rwlock; //读写锁的实例
int insertOperations;
int memberOperations;
int deleteOperations;
void display_list(struct Node ** head_pp);
int insert(int val,struct Node ** head_pp);
int delete(int val,struct Node ** head_pp);
int member(int val,struct Node * head_p);
//由线程执行的方法
void * run_threads(void * rank){
long id =(long)rank;
int operationType;
int localRun = operationsCount / threadCount;
for(int i = 0 ; i <localRun; i ++){
operationType =(id * localRun)+ i;
if(operationType <memberOperations){
//成员
pthread_rwlock_rdlock(&rwlock);
int randVal = rand()%65536 ;
成员(randVal,head_p);
pthread_rwlock_unlock(&rwlock);
} else if(operationType <(memberOperations + insertOperations)){
//插入
pthread_rwlock_wrlock(&rwlock);
int randVal = rand()%65536 ;
insert(randVal,head_pp);
pthread_rwlock_unlock(&rwlock);
} else {
//删除
pthread_rwlock_wrlock(&rwlock);
int randVal = rand()%65536 ;
删除(randVal,head_pp);
pthread_rwlock_unlock(&rwlock);
}
}
返回 0 ;
}
//将初始元素插入到链表
void initial_insert(struct Node ** head_pp){
int inserts = 0 ;
while(inserts!= initialEntries){
int randVal = rand()%65536 ;
int result = member(randVal,* head_pp);
if(result == 0){
insert(randVal,head_pp);
插入++;
}
}
}
void clear_list(struct Node ** root){
struct Node * curr_p;
struct Node * succ_p;
if(* root == NULL){
回归 ;
}
curr_p = * root;
succ_p = curr_p-> next ;
while(succ_p!= NULL){
免费(curr_p);
curr_p = succ_p;
succ_p = curr_p-> next ;
}
免费(curr_p);
* root = NULL ;
}
// param 1 = #initial entries
// param 2 = #operations m
// param 3 = #member fraction
// param 4 = #insert fractoin
// param 5 = #delete fraction
// param 6 = #number of threads
int main(int argc,char * argv []){
int iterations = 100 ;
double sampleTime [iterations];
double totalTime = 0 ;
双倍平均时间;
double sumOfSquare = 0 ;
double stdDev;
双重开始,结束;
长线程;
pthread_t * thread_handles;
if(argc!= 7){
printf(“ \ n只输入6个参数\ n ”);
退出(0);
}
//读取命令行参数
initialEntries = strtol(argv [ 1 ],NULL,10);
operationsCount = strtol(argv [ 2 ],NULL,10);
memberFraction = strtod(argv [ 3 ],NULL);
insertFraction = strtod(argv [ 4 ],NULL);
deleteFraction = strtod(argv [ 5 ],NULL);
threadCount = strtol(argv [ 6 ],NULL,10);
memberOperations = memberFraction * operationsCount;
insertOperations = insertFraction * operationsCount;
deleteOperations = deleteFraction * operationsCount;
for(int i = 0 ; i <iterations; i ++){
//初始插入
initial_insert(head_pp);
thread_handles = malloc(threadCount * sizeof(pthread_t)); //为线程分配内存
pthread_rwlock_init(&rwlock,NULL); //初始化读写锁
GET_TIME(开始);
//执行线程
for(thread = 0 ; thread <threadCount; thread ++)
pthread_create(&thread_handles [thread],NULL,run_threads,(void *)thread);
for(thread = 0 ; thread <threadCount; thread ++){
pthread_join(thread_handles [thread],NULL);
}
GET_TIME(结束);
sampleTime [i] =(end-start);
totalTime + =(end-start);
clear_list(head_pp);
pthread_rwlock_destroy(&rwlock); //销毁锁
free(thread_handles); //免费获得的记忆
}
avgTime = totalTime / iterations;
for(int i = 0 ; i <iterations; i ++){
sumOfSquare + =(sampleTime [i] -avgTime)*(sampleTime [i] -avgTime);
}
stdDev = sqrt(sumOfSquare /(iterations- 1));
printf(“ \ n摘要...... \ n ”);
printf(“ ---------- MEMBERING %d ITEMS COMPLETE -------------- \ n ”,memberOperations);
printf(“ ---------- INSERTING %d ITEMS COMPLETE -------------- \ n ”,insertOperations);
printf(“ ---------- DELETING %d ITEMS COMPLETE --------------- \ n ”,deleteOperations);
printf(“总时间(ms):%f \ n ”,totalTime * 1000);
printf(“平均时间(毫秒):%f \ n ”,avgTime * 1000);
printf(“ Standerd Deviation time(ms):%f \ n ”,stdDev);
}
//显示链表的元素
void display_list(struct Node ** head_pp){
if(head_pp!= NULL){
struct Node * current = * head_pp;
while(current!= NULL){
current = current-> next ;
}
} else {
printf(“空列表”);
}
}
//将元素插入到链表
int insert(int val,struct Node ** head_pp){
struct Node * current = * head_pp;
struct Node * prev = NULL ;
struct Node * temp;
while(current!= NULL && current-> value <val){
prev =当前;
current = current-> next ;
}
if(current == NULL || current-> value > val){
temp = malloc(sizeof(struct Node));
temp-> value = val;
temp-> next = current;
if(prev == NULL){
* head_pp = temp;
} else {
prev-> next = temp;
}
返回 1 ;
} else {
返回 0 ;
}
}
//从链表中删除元素
int delete(int val,struct Node ** head_pp){
struct Node * current = * head_pp;
struct Node * prev = NULL ;
while(current!= NULL && current-> value <val){
prev =当前;
current = current-> next ;
}
if(current!= NULL && current-> value == val){
if(prev == NULL){
//删除头部
* head_pp = current-> next ;
免费(当前);
} else {
prev-> next = current-> next ;
免费(当前);
}
返回 1 ;
} else {
返回 0 ;
}
}
//链表中的成员元素
int member(int val,struct Node * head_p){
struct Node * current = head_p;
while(current!= NULL && current-> value <val){
current = current-> next ;
}
if(current == NULL || current-> value > val){
返回 0 ;
} else {
返回 1 ;
}
}
以下是观察到的结果
执行代码并采集100个样本以确保结果在95%置信区间内。
情况1:
- 插入操作:5
- 删除操作:5
- 会员业务:990


案例2:
- 插入操作:50
- 删除操作:50
- 会员业务:900


案例3:
- 插入操作:250
- 删除操作:250
- 会员业务:500
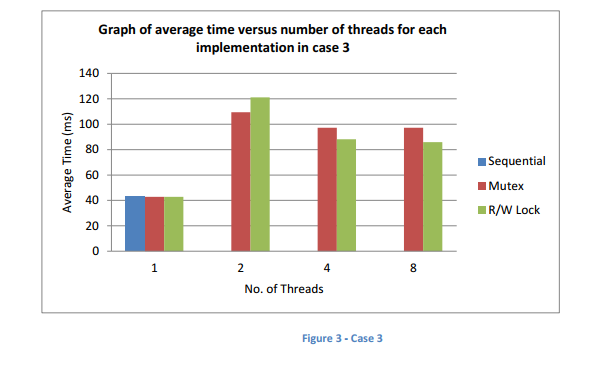

如图1和图2所示,当使用一个线程时,使用互斥锁和读/写锁具有比顺序编程更高的处理时间。主要原因是当执行互斥锁和读/写锁操作时,需要额外的时间来获取和释放锁或互斥锁。但是在顺序编程中,没有这种情况下获取或释放锁或互斥锁。但是,在图3中,顺序编程方法和一个线程的并行编程方法存在滑动偏差。可能的原因可能是由于操作中的分数变化。
根据图1和图2,对于任意数量的线程,使用读/写锁显示出比互斥锁更高的性能。这是因为读/写锁允许执行读操作的线程同时访问关键区域。但是对于互斥锁,它只允许一个线程一次访问临界区而不考虑操作类型。这种机制减慢了互斥锁而不是读/写锁。
与情况1,2,3相比,执行读/写执行所花费的时间增加。可能的原因是,案例3的成员操作正在减少。因此,减少了并发读取操作,同时增加了插入和删除操作,这导致总处理时间增加。
在图1中,在多个线程的情况下,与互斥和顺序方法相比,执行读/写操作所花费的时间显着减少。这是因为在这种情况下有更多的读操作导致读/写锁的并发读操作。这表现出实际的并行性,并显示了读/写执行的平均执行时间。
结论
根据结果,并行执行显然已经显示出显着的改进。但是我们需要在这里考虑某些事情。
永远不应该使用并发方法来加速小的计算问题。原因是初始化和最终确定库,互斥体,信号量等所需的时间对输出有很大影响。
另一方面,对于大的计算问题,即使存在额外的开销,整体性能也会增加。
另一个重要的设计决策是选择正确的构建块(信号量,监视器,互斥体)来实现该程序。即使在上面的例子中,我们也可以看到锁的性能比互斥锁更好。为此,我们应该正确了解要正确应用的基础知识。
使用并发编程可以获得相当大的加速。天气预报系统,视频渲染程序,模拟程序具有并发编程的巨大优势。但是,需要了解适用性和适当的设计和实施以享受性能
本文引用如下文章:
https://ofirm.wordpress.com/2013/01/17/high-concurrency-or-high-throughput/
https://www.percona.com/blog/2013/02/26/why-do-we-care-about-performance-at-high-concurrency/
https://towardsdatascience.com/is-concurrency-really-increases-the-performance-8cd06dd762f6
https://towardsdatascience.com/is-concurrency-really-increases-the-performance-161616311efft
欢迎转载,转载需备注作者:开发猫
出处:https://blog.csdn.net/qq_37939251/article/details/83044153















 2953
2953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









