






一、运行环境
Go 1.17 Linux Docker生产环境 ffmpeg 5.1.6. 8核14G
二、问题背景
服务器处理视频链接请求使用ffmpeg进行视频压缩,fasthttp处理视频链接请求,使用Channel存视频链接,Goroutine处理。视频下载到本地,后通过ffmpeg进行视频压缩。
三、错误问题
当请求突然增加,有一定并发量,就会产生错误
panic: id (30) <= evictCount (31) goroutine 29490 [running]: vendor/golang.org/x/net/http2/hpack.(*headerFieldTable).idToIndex(0xc000cfa480, 0xc0011fa990?)
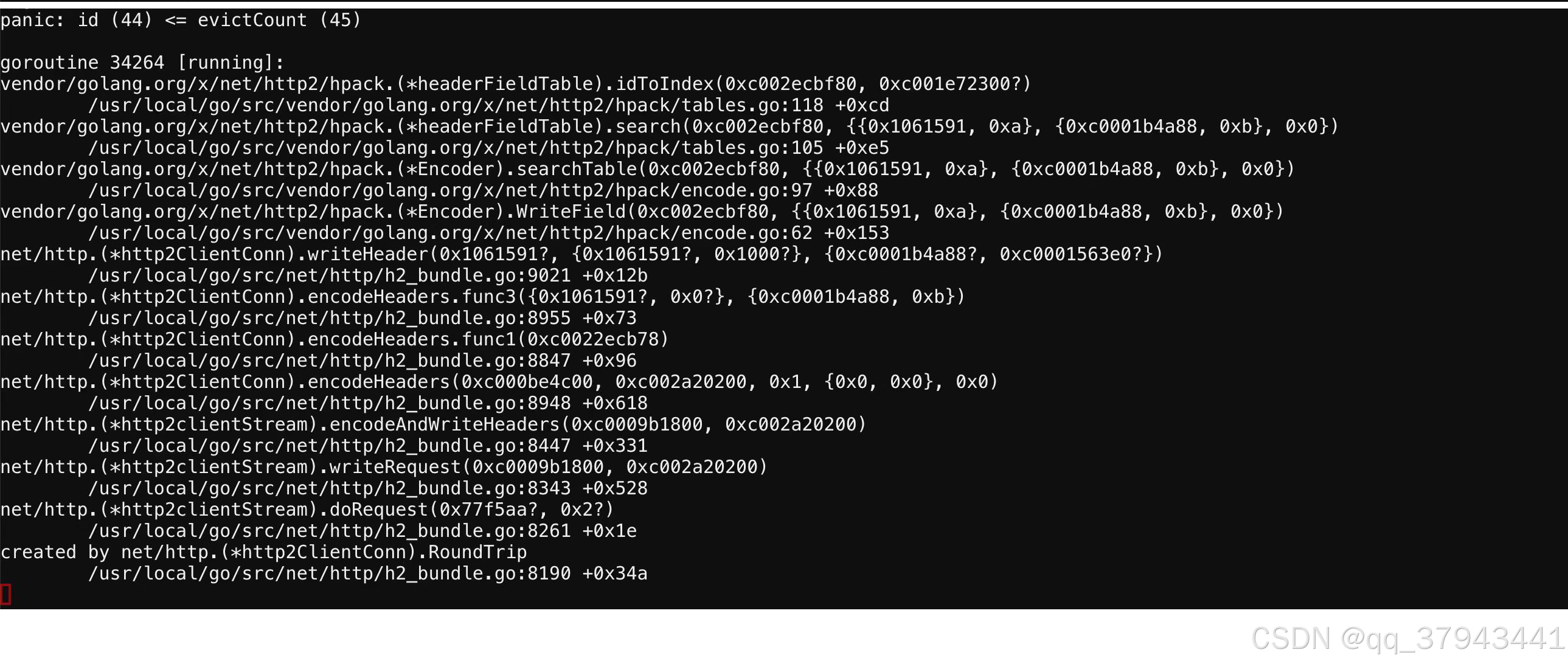
问题可稳定复现,在并发量很低情况下也会偶发。在突然提升并发量必发,缓慢提升并发量维持短暂时间也会必发现象。
四、问题定位
首先怀疑并发引起的数据竞争问题(因为堆栈信息并不能在程序中定位,HPACK也不太清楚具体问题),大模型查询提示是修改http头中信息,怀疑是处理fasthttp时解析的数据线程安全问题,经查数据仅取值无并发冲突,数据类型也是简单string不存在并发产生的影响。
其次怀疑是对http的response处理产生的协程问题,添加了对response的处理,并发执行select->channel,并且原本就有default处理 不会阻塞,而且response只会影响客户端而不会导致服务端panic,
之后怀疑到ffmpeg对CPU和内存的压力、或者是channel过大造成的存储问题,重复多次试验发现在并发量较低时也会发生,对channel长度进行监控限制,发现存储较低时仍会产生panic。
查询相关资料发现有人说GO1.17版本对于hpack的支持可能有问题,在go1.18中官方有一定修复,于是为了验证是不是fasthttp版本问题,直接将Go升级到1.21,已达到fasthttp1.56版本,全部升级版本后
对视频压缩进程进行分析,依次排除分布式锁、KV缓存等产生的性能和竞争问题,终于意识到问题是堆栈信息HPACK可能是问题产生的源头。这里简单介绍一下HPACK。
那就不得不说到HTTP1.1和HTTP2的区别了,HTTP2在下面这些地方做出更新:
1. 多路复用(Multiplexing)
- HTTP/1.x:每个请求/响应对都需要独立的 TCP 连接,且一个连接只能处理一个请求/响应,导致了阻塞和低效。
- HTTP/2:支持多路复用,一个 TCP 连接可以同时传输多个请求和响应,避免了由于 TCP 连接数限制和阻塞带来的性能瓶颈。不同的请求可以并发传输,通过流标识符(stream identifier)区分,极大提高了效率。
2. 头部压缩(Header Compression)
- HTTP/1.x:每个请求都必须重复发送大量的头部信息,即使这些头部信息在多个请求中是相同的,造成了冗余。
- HTTP/2:采用 HPACK 算法进行头部压缩,避免了重复发送相同的头部信息,从而减少了带宽占用和延迟。
3. 二进制协议(Binary Protocol)
- HTTP/1.x:基于文本的协议,易于人类阅读和理解,但这种文本格式增加了解析和传输的复杂性。
- HTTP/2:使用二进制格式进行数据传输,数据包被分解为帧(frame),每个帧都有明确的标头和有效载荷。二进制协议的优势在于处理效率高,容易实现流控制和数据分段。
其中HPACK可以大大降低http头部的大小,主要是静态表、动态表和哈夫曼编码压缩。详情可以参考本站很多博客,hpack是http2独有的,在http1中不会使用,fasthttp是基于http1的高并发场景下包,所以定位到不是处理http请求的问题,而是访问http出的问题。
定位到视频压缩部分,于是合理怀疑ffmpeg访问网址时的问题,ffmpeg访问网址时依靠libcurl库,对于http1/http2貌似按编译设置,对于ffmpeg的网址访问模式比较复杂,但此时突然发现代码处理逻辑未使用ffmpeg访问,而是使用net/http官方库进行下载。所以问题定位到,是文件下载时发生的问题。
五、问题分析
其中的动态表压缩时,使用的tables.go如下
func (t *headerFieldTable) search(f HeaderField) (i uint64, nameValueMatch bool) {
if !f.Sensitive {
if id := t.byNameValue[pairNameValue{f.Name, f.Value}]; id != 0 {
return t.idToIndex(id), true
}
}
if id := t.byName[f.Name]; id != 0 {
return t.idToIndex(id), false
}
return 0, false
}
// idToIndex converts a unique id to an HPACK index.
// See Section 2.3.3.
func (t *headerFieldTable) idToIndex(id uint64) uint64 {
if id <= t.evictCount {
panic(fmt.Sprintf("id (%v) <= evictCount (%v)", id, t.evictCount))
}
k := id - t.evictCount - 1 // convert id to an index t.ents[k]
if t != staticTable {
return uint64(t.len()) - k // dynamic table
}
return k + 1
}完整代码参见net/http2/hpack/tables.go at master · golang/net · GitHub
这就是报错的问题所在,让我们完整分析一下动态表压缩这个过程:
-
初始化:
- 动态表开始时是空的。
evictCount初始化为0,它记录了动态表中已经驱逐的条目数量。
-
添加条目:
- 当一个新的头字段被解码时,如果需要,它会被添加到动态表的开头。
- 每个添加的条目都被赋予一个唯一的
id,这个id从1开始递增。
-
索引和引用:
- 动态表中的条目可以被用来构建索引,以便在后续的头字段中引用,从而减少需要传输的数据量。
id用于唯一标识动态表中的条目。
-
动态表大小管理:
- 动态表有一个最大大小限制,由HTTP/2的设置参数
SETTINGS_HEADER_TABLE_SIZE决定。 - 当动态表的大小超过这个限制时,需要进行条目驱逐。
- 动态表有一个最大大小限制,由HTTP/2的设置参数
-
条目驱逐:
- 当添加新条目前,如果动态表已满,最老的条目(即索引最大的条目)会被逐出,以确保表的大小不超过限制。
- 驱逐条目时,
evictCount会增加,以跟踪已经驱逐的条目数量。
-
id和evictCount的关系:id是动态表中条目的唯一标识符,而evictCount是已经从动态表中驱逐的条目数量。- 当一个条目被驱逐后,它的
id不再有效,因为该条目不再存在于表中。 - 如果一个
id小于或等于evictCount,这意味着该id指向的条目已经被驱逐,因此使用该id是非法的。
-
解码和索引转换:
- 解码器在处理头字段时,会使用
id来查找动态表中的条目。 - 如果
id对应的条目已经被驱逐(即id小于或等于evictCount),解码器必须识别这种情况并处理错误。
- 解码器在处理头字段时,会使用
-
动态表更新:
- 动态表的大小可以通过发送动态表大小更新指令来调整,这会导致表中一些条目的驱逐。
- 动态表大小的更新必须在新的头块的第一个字节中进行。
总结来说,id是动态表中条目的唯一标识,而evictCount跟踪了已经驱逐的条目数量。如果尝试访问一个id小于或等于evictCount的条目,就会发生错误,因为这样的id指向的是一个已经不再存在的条目。
对于索引index, RFC 7541 HPACK: Header Compression for HTTP/2(https://www.rfc-editor.org/rfc/rfc7541)文章是如此说明的,
Index Address Space The static table and the dynamic table are combined into a single index address space. Indices between 1 and the length of the static table (inclusive) refer to elements in the static table (see Section 2.3.1). Indices strictly greater than the length of the static table refer to elements in the dynamic table (see Section 2.3.2). The length of the static table is subtracted to find the index into the dynamic table. Indices strictly greater than the sum of the lengths of both tables MUST be treated as a decoding error. For a static table size of s and a dynamic table size of k, the following diagram shows the entire valid index address space. <---------- Index Address Space ----------> <-- Static Table --> <-- Dynamic Table --> +---+-----------+---+ +---+-----------+---+ | 1 | ... | s | |s+1| ... |s+k| +---+-----------+---+ +---+-----------+---+ ^ | | V Insertion Point Dropping Point Figure 1: Index Address Space
对于静态表和动态表的描述,在tables.go的注释中这样写到
对于静态表,条目永远不会被删除。对于动态表,条目将从ents[0]中删除并添加到末尾。
每个条目都有一个唯一的id,从1开始,并为每个条目递增添加的条目。这个独特的id在驱逐过程中是稳定的,这意味着它可以用作指向特定条目的指针。与hpack一样,唯一ID
是1-base。ents[k]的唯一id是k+evictCount+1。零不是有效的唯一id。evictCount在任何远程实际情况下都不应溢出。In在实践中,我们将为每个HTTP/2连接提供一个动态表。如果我们假设一个非常强大的服务器,每个连接和每个连接处理1M QPS请求从表中添加(然后删除)100个条目,它仍然需要200万年后,驱逐数量将溢出。
对于HPACK通过以下机制来限制内存空间的使用,详情请见4.2节:
-
动态表的最大大小限制:
- HPACK规范允许使用HPACK的协议(如HTTP/2)定义动态表的最大大小。在HTTP/2中,这个值由SETTINGS_HEADER_TABLE_SIZE设置参数确定。
- 编码器(发送方)必须确保动态表的大小不超过这个最大值。如果编码器选择使用小于最大值的容量,它必须确保所选大小不超过协议设定的最大值。
-
动态表大小更新:
- 编码器可以通过发送动态表大小更新指令来调整动态表的大小,这会导致表中的一些条目被逐出。
- 动态表大小的更新必须在第一个随后的头块的开始处进行,以确保解码器(接收方)能够根据大小变化进行适当的条目驱逐。
-
内存使用的监控和控制:
- 规范建议实现应该监控内存使用情况,并在必要时调整动态表的大小,以避免内存耗尽。
由此可见,HPACK是对内存有进行限制的。但参考大模型相关说法,虽然 HPACK 本身设计了防止资源耗尽的机制,但是实现的质量、系统的资源管理以及网络条件等因素仍然会影响到程序的稳定性。正确实现和测试 HPACK,以及监控和调整系统资源的使用,是确保在高负载情况下避免程序 panic 的关键。那么问题产生的原因可能存在多种方面了,由于缺乏相关研究资料,我们只能进行分析各种可能性。
六、可能的原因
1.从资源占用的角度上,可能存在ffmpeg大量占用资源,导致在极端环境下造成HPACK的内存资源占用产生问题,在高负载情况下资源管理实现不当,可能会导致内存泄漏或溢出,从而触发 panic。可能存在net/http2包在资源处理上有潜在问题。
2.在高并发和同步角度上,对动态表的访问没有适当的同步机制,可能会导致竞态条件。竞态条件可能导致动态表的状态不一致,例如,一个线程可能在另一个线程驱逐条目后仍然使用旧的 id,可能导致 id <= evictCount 错误。在并发激烈的条件下,存在潜在问题。
3.有理由怀疑版本兼容性问题,可能存在各种包产生的版本不兼容产生潜在问题的情况。
七、解决方法
最简单有效的办法就是使用http包下载时,禁用HTTP2,具体方法如下:
transport := &http.Transport{
// 禁用 HTTP/2
TLSNextProto: map[string]func(authority string, c *tls.Conn) http.RoundTripper{},
}
client := &http.Client{
Transport: transport,
}
八、总结
分析了id(*)<=evictcount(*)产生 panic的原因,怀疑在内存和并发上存在潜在问题。github上也有相关的issue提出,但对于该问题都没有明确的分析和处理方法,有关于该错误相关的资料和论坛信息较少,能够进行研究的方法过程也相对较为困难,如各位大佬有相关的经验和解决方法,亦或是出现过相关的问题,请多多交流指教,我也会在之后对该问题文章进行追踪和完善。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









