







Python程序设计 第六章
数字类型及操作
整数类型的无限范围及4种进制表示
浮点数类型的近似无限范围、小尾数及科学计数法
+、-、*、/、//、%、**、二元增强赋值操作符
abs()、divmod()、pow()、round()、max()、min()
int()、float、complex()
字符串类型及操作
正向递增序号、反向递增序号、<字符串>[M:N:K]
+、*、len()、str()、hex()、oct()、ord()、chr()
.lower()、.upper()、.split()、.count()、.replace()
.center()、.strip()
组合数据类型

组合类型,包括、集合类型、序列类型、字典类型
6.1 集合类型及操作
6.2 序列类型及操作 元组类型 列表类型
6.3 实例9:基本统计值计算
6.4 字典类型及操作
6.5 模块5:jieba库的使用
6.6 实例10:文本词频统计
方法论
python 三种主流组合数据类型的使用方法
实践能力
学会编写处理一组数据的程序
6.1 集合类型及操作
集合类型定义
集合类型与数学中的集合概念一致
集合元素之间无序,每个元素唯一,不存在相同元素
集合元素不可更改,不能是可变数据类型
为什么?如果元素改变,可能与原来的元素相同
集合是多个元素的无序组合
集合用大括号{}表示,元素间用逗号分隔
建立集合类型用{}或set()
建立空集合类型,必须使用set()
集合类型的定义
>>> A = {"python",123,("python",123)}#使用{}建立集合
{123,'python',("python",123)}
>>> B = set("pypy123") #使用set()建立集合
{'1','p','2','3','y'}
>>> C = {"python",123,"python",123}
{'python',123}
集合操作符
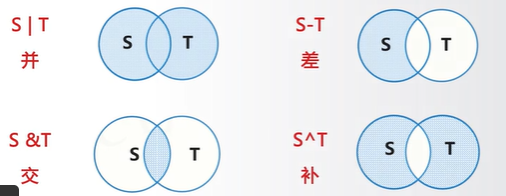
集合操作符
操作符及应用,以及描述
S|T 返回一个新集合,包括在集合S和T中的所有元素
S-T 返回一个新集合,包括在集合S但不在T中的元素
S&T 返回一个新集合,包括同时在集合S和T中的元素
S^T 返回一个新集合,包括集合S和T中的非相同元素
S <= T或S < T 返回True/False,判断S和T的子集关系
S >= T或S > T 返回True/False,判断S和T的包含关系
集合操作符
4个增强操作符
操作符及应用还有描述
S |= T 更新集合S,包括在集合S和T中的所有元素
S -= T 更新集合S,包括在集合S但不在T中的元素
S &= T 更新集合S,包括同时在集合S和T中的元素
S ^= T 更新集合S,包括集合S和T中的非相同元素
集合类型的定义
>>> A = {"p","y",123}
>>> B = set("pypy123")
>>> A-B
{123}
>>> A&B
{'p', 'y'}
>>> A^B
{'3', 123, '2', '1'}
>>> B-A
{'2', '1', '3'}
>>> A|B
{'3', '2', 'p', '1', 123, 'y'}
集合处理方法
操作函数或方法以及描述
S.add(x) 如果x不在集合S中,将x增加到S
S.discard(x) 移除S中元素x,如果x不在集合S中,不报错
S.remove(x) 移除S中元素x,如果x不在集合S中,产生KeyError异常
S.clear() 移除S中所有元素
S.pop() 随机返回S的一个元素,更新S,若S为空产生KeyError异常
S.copy() 返回集合S的一个副本
len(S) 返回集合S的元素个数
x in S 判断S中元素x,x在集合S中,返回True,否则返回False
x not in S 判断S中元素x,x不在集合S中,返回true,否则返回False
set(x) 将其他类型变量x转变为集合类型
>>> A = {"p","y",123}
>>> for item in A:
print(item,end="")
123py
>>> A
{123, 'p', 'y'}
集合处理方法
>>> try:
while true:
print(A.pop(),end="")
except:
pass
p123y
>>>A
set()
集合类型应用场景
>>> "p" in {"p","y",123}
True
>>> {"p","y"}>={"p","y",123}
False
包含关系比较
数据去重:集合类型所有元素无重复
>>> ls = ["p","p","y","y",123]
>>> s = set(ls) #利用了集合无重复元素的特点
>>> s
{123, 'p', 'y'}
>>> lt = list(s) #将集合转换为列表.
>>> lt
[123, 'p', 'y']
6.2 序列类型及操作 元组类型 列表类型
序列类型定义
序列是具有先后关系的一组元素
序列是一维元素向量,元素类型可以不同
类似数学元素序列:s0,s1,s2,s3…sn-1
元素间由序号引导,通过下标访问序列的特定元素
序列是一个基类类型
序列类型包括字符串类型、元组类型、列表类型
序列类型通用操作符
操作符及应用、描述
x in s 如果x是序列s的元素,返回True,否则返回False
x not in s 如果x是序列s的元素,返回False,否则返回True
s+t 连接2个序列s和t
sn或ns 将序列s复制n次
s[i] 索引,返回s中的第i个元素,i是序列的序号
s[i:j]或s[i:j:k] 切片,返回序列s中第i到j以k为步长的元素子序列
序列类型操作实例
>>> ls = ["python",123,".io"]
>>> ls[::-1]
['.io', 123, 'python']
>>> s = "python123.io"
>>> s[::-1]
'oi.321nohtyp'
字符串本身也是序列类型的一种扩展形式
序列处理函数及方法
函数和方法及描述
元组类型及操作
元组继承了序列类型的全部通用操作
元组是序列类型的一种扩展
元组是一种序列类型,一旦创建就不能被修改
使用小括号()或者tuple()创建,元素间用逗号,分隔
可以使用或者不使用小括号
def func():
return 1,2
#返回的1,2是一个元组
>>> creature = "cat","dog","tiger","human"
>>> creature
('cat', 'dog', 'tiger', 'human')
>>> color = (0x001100,"blue",creature)
>>> color
(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
元组类型就是将元素进行有序的排列,用()形式来组织
>>> creature = "cat","dog","tiger","human"
>>> creature[::-1]
('human', 'tiger', 'dog', 'cat')
>>> color = (0x001100,"blue",creature)
>>> color[-1][2]
'tiger'
列表类型及操作
列表是序列类型的一种扩展,十分常用
列表是一种序列类型,创建后可以随意被修改
使用方括号[]或者list()创建,元素间用逗号,分隔
列表中各元素类型可以不同,无长度限制
列表类型定义

列表类型操作函数和方法
函数或方法 以及 描述
ls[i] = x 替换列表ls第i元素为x
ls[i:j:k] = lt 用列表lt替换ls切片后所对应元素子列表
del ls[i] 删除列表ls中第i元素
del ls[i:j:k] 删除列表ls中第i到第j以k为步长的元素
ls += lt 更新列表ls,将列表lt元素增加到列表ls中
ls *= n 更新列表ls,其元素重复n次
列表类型操作
>>> ls = ["cat","dog","tiger",1024]
>>> ls[1:2] = [1,2,3,4]
['cat', 1, 2, 3 , 4, 'tiger', 1024]
>>> del ls[::3]
[1, 2, 4, 'tiger']
>>> ls*2
[1, 2, 4, 'tiger', 1, 2, 4, 'tiger']
列表类型操作
列表类型操作函数和方法
函数或方法以及描述
ls.append(x) 在列表ls最后增加一个元素x
ls.clear() 删除列表ls中所有元素
ls.copy() 生成一个新列表,赋值ls中所有元素
ls.insert(i,x) 在列表ls的第i位置增加元素x
ls.pop(i) 将列表ls中第i位置元素取出并删除该元素
ls.remove(x) 将列表ls中出现的第一个元素x删除
ls.reverse() 将列表ls中的元素反转
序列类型应用场景
元组用于元素不改变的应用场景,更多用于固定搭配场景
列表更加灵活,它是最常用的序列类型
最主要作用:表示一组有序数据,进而操作它们
元素遍历
for item in ls:
<语句块>
for item in tp:
<语句块>
数据保护
如果不希望数据被程序所改变,转换成元组类型
>>> ls = ["cat","dog","tiger",1024]
>>> lt = tuple(ls)
>>> lt
('cat', 'dog', 'tiger', 1024)
序列类型及操作
序列是基类类型,扩展类型包括:字符串、元组和列表
元组用()和tuple()创建,列表用[]和list()创建
元组操作与序列操作基本相同
列表操作在序列操作基础上,增加了更多地灵活性
6.3 实例9:基本统计值计算
基本统计值
需求:给出一组数,对它们有个概要理解
该怎么做呢?
总个数、求和、平均值、方差、中位数
总个数:len()
求和:for … in
平均值:求和/总个数
方差:个数据和平均数差的平方和的平均数
中位数:排序,然后… 奇数中间1个,偶数找中间2个取平均值
基本统计值计算
#CalStatisticsV1.py
def getNUM(): #获取用户不定长度的输入
nums = []
iNumStr = input("请输入数字(回车退出):")
while iNumStr != "":
nums.append(eval(iNumStr))
iNumStr = input("请输入数字(回车退出):")
return nums
def mean(numbers): #计算平均值
s = 0.0
for num in numbers:
s = s+num
return s/len(numbers)
def dev(numbers,means): #计算方差
sdev = 0.0
for num in numbers:
sdev = sdev + (num - mean)**2
return pow(sdev/(len(numbers)-1),0.5)
def median(numbers): 计算中位数
sorted(numbers)
size = len(numbers)
if size % 2 == 0
med = (numbers[size//2-1]+numbers[size//2])/2
else:
med = numbers[size//2]
return med
n = getNum()
m = mean(n)
print("平均值:{},方差:{:.2},中位数:{}.".format(m,dev(n,m),median(n)))
6.4 字典类型及操作
字典类型定义


字典类型是“映射”的体现
键值对:键是数据索引的扩展
字典是键值对的集合,键值对之间无序
采用大括号{}和dict()创建,键值对用冒号:表示
{<键1>:<值1>,<键2>:<值2>,…,<键n>:<值n>}
字典类型的用法
在字典变量中,通过键获得值
<字典变量> = {<键1>:<值1>,<键2>:<值2>,…,<键n>:<值n>}
<值> = <字典变量>[<键>] <字典变量>[<键>] = <值>
[]用来向字典变量中索引或增加元素
字典类型操作函数和方法
函数或方法以及描述
del d[k] 删除字典d中键k对应的数据值
k in d 判断键k是否在字典d中,如果在返回true,否则返回false
d.keys() 返回字典d中所有的键信息
d.values() 返回字典d中所有的值信息
d.items() 返回字典d中所有的键值对信息
d.get(k,) 键k存在,则返回相应值,不在则返回值
d.pop(k,) 键k存在,则取出相应值,不在则返回值
d.popitem() 随机从字典d中取出一个键值对,以元组形式返回
d.clear() 删除所有的键值对
len(d) 返回字典d中元素的个数
字典类型操作
>>> d = {"中国":"北京","美国":"华盛顿","法国":"巴黎"}
>>> d.get("中国","伊斯兰堡")
'北京'
>>> d.get("巴基斯坦","伊斯兰堡")
'伊斯兰堡'
>>> d.popitem()
('法国', '巴黎')
字典功能
定义空字典d
>>>d = {}
修改第二个元素
>>>d["b"] = 3
向d新增2个键值对元素
>>>d["a"] = 1;d["b"] = 2
判断字符"c"是否是d的键
>>>"c" in d
计算d的长度
>>>len(d)
清空d
>>>d.clear()
字典类型的应用场景
映射的表达
映射无处不在,键值对无处不在
例如:统计数据出现的次数,数据是键,次数是值
最主要作用:表达键值对数据,进而操作它们
元素遍历
for k in d:
<语句块>
6.5 模块5:jieba库的使用
jieba是优秀的中文分词第三方库
中文文本需要通过分词获得单个的词语
jieba是优秀的中文分词第三方库。需要额外安装
jieba库提供三种分词模式,最简单只需掌握一个函数
利用一个中文词库,确定汉字之前的关联概率
汉字间概率大的组成词组,形成分词结果
除了分词,用户还可以添加自定义的词组
jieba分词的三种模式
精确模式:把文本精确的切分拉开,不存在冗余单词
全模式:把文本所有可能的词语都扫描出来,有冗余
搜索引擎模式:在精确模式基础上,对长词再次切分
函数及描述
jieba.lcut(s) 精确模式,返回一个列表类型的分词结果
>>> jieba.lcut("中国是一个伟大的国家")
['中国', '是', '一个', '伟大', '的', '国家']
jieba.lcut(s,cut_all = True) 全模式,返回一个列表类型的分词结果,存在冗余
>>> jieba.lcut("中国是一个伟大的国家",cut_all=True)
['中国', '国是', '一个', '伟大', '的', '国家']
jieba.lcut_for_search(s) 搜索引擎模式,返回一个列表类型的分词结果,存在冗余
>>> import jieba
>>> jieba.lcut_for_search("中华人民共和国是伟大的")
['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']
jieba.add_word(w) 向分词词典增加新词w
>>> jieba.add_word("蟒蛇语言")
6.6 实例10:文本词频统计
问题分析
文本词频统计
需求:一篇文章,出现了哪些词?哪些词出现的最多?
该怎么做呢?
英文文本->中文文本
英文文本:Hamet 分析词频
中文文本:《三国演义》 分析人物

#CalHamletV1.py
def getText():
txt = open("hamlet.txt","r").read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_{|}~.‘’':
txt = txt.replace(ch," ")
return txt
hamletTxt = getText()
words = hamletTxt.split()
counts = {}
for word in words:
counts[word] = counts.get(word,0)+1
items = list(count.items())
items.sort(key = lambda x::[1],reverse=True)
for i in range(10):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
《三国演义》人物出场统计
#CalHamletV1.py
import jieba
txt = open("threekingdoms.txt","r",encoding="utf-8").read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0)+1
items = list(counts.items())
items.sort(key = lambda x:x[1],reverse=True)
for i in range(15):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
#CalThreeKingdomsV2.py
import jieba
txt = open("threekingdoms.txt","r",encoding = "utf-8").read()
excludes = {"将军","却说","荆州","二人","不可","不能","如此"}
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))














 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









