







一.精确度的定义
精确度:机器学习领域中一项至关重要的评价指标,其专注于评估模型对正样本的预测准确性。
相对于准确率而言,精确度更为细致,它关注的是模型在将实例预测为正样本的情况下,实际为正样本的比例。换句话说,精确度回答了一个关键问题:“当模型预测一个实例为正样本时,这个预测有多大的可能性是准确的?”一种高精确度的模型意味着,在其预测某个实例为正样本时,这个实例很有可能真的是正样本。这个评价指标在二分类问题中尤为重要,因为不同任务可能对模型对正类别的预测更为关注。下面我们将更详细地探讨精确度的定义、计算方式以及在实际应用中的重要性。
二.精确度的计算示例
考虑一个二分类问题,模型对一组实例进行预测。结果表明,模型正确预测了150个实例为正类别(真正例数),但也错误地将30个实例预测为正类别,实际上它们是负类别(假正例数)。那么,该模型的精确度计算如下:
精确度 = T P / ( T P + F P ) = 150 / ( 30 + 150 ) ≈ 0.8333 精确度=TP/(TP+FP)=150/(30+150)≈0.8333 精确度=TP/(TP+FP)=150/(30+150)≈0.8333
这说明该模型在其预测为正类别的情况下,有83.33%的概率是准确的。
其中,TP 表示真正例(模型正确预测为正样本的实例数),FP 表示假正例(模型错误预测为正样本的实例数)。这个公式展示了在所有被模型预测为正样本的实例中,有多少实际上是正样本。因此,一个高精确度值表示模型在正样本的预测上更为准确。
如下图所示:
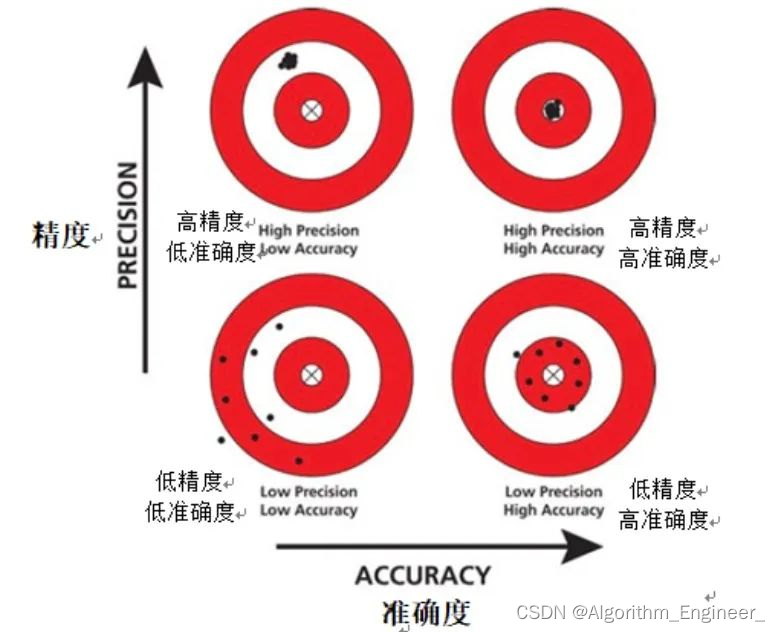
三.精确度的局限性
虽然精确度在许多情况下是一个有力的工具,但也存在一些局限性需要考虑。
其中之一是对类别不平衡敏感。当正样本和负样本的比例差异较大时,模型可能更倾向于预测样本数量更多的类别,导致高精确度但对少数类别的性能评估不足。
解决这个问题的方法包括使用其他评价指标,如查准率-查全率曲线下面积(AUC-PR)或F1分数。
四.精确度的重要性:
关注正类别的准确性: 在一些应用场景中,对正类别的准确性更为关键。
例如,在医学诊断中,我们更关心模型准确地识别出患有某种疾病的患者,而不太关心模型如何处理健康的情况。
处理类别不平衡问题: 当类别分布不平衡时,准确率可能不足以提供全面的评估。
精确度能够帮助我们更好地理解模型在关注的类别上的性能。
权衡召回率: 精确度与召回率之间存在一种权衡关系。
在一些场景中,我们希望高精确度,即使这可能导致较低的召回率。在其他情况下,我们可能更关心召回率,即使精确度较低。
五.精确度的未来发展方向:
随着机器学习领域的不断发展,我们可以期待精确度在未来的一些方向上取得更多进展:
结合多指标评估: 未来的研究可以更加注重结合多个评价指标,以更全面地评估模型性能。不同任务可能需要不同的指标,结合使用可以提供更丰富的信息。
定制化评价: 针对不同应用场景,可以定制化评价指标,考虑不同错误类型的权衡。这种个性化的评价可以更好地适应特定任务的需求。
概率化评价: 考虑模型输出的概率信息,而不仅仅是二元分类结果。这有助于更好地理解模型的不确定性和可靠性。
对抗鲁棒性评估: 随着对抗性机器学习的兴起,未来的评价指标可能更加关注模型对抗性攻击的鲁棒性。在真实世界的应用中,模型需要能够处理各种不确定性和攻击。
六.代码实现
精确度的代码实现通常是根据其定义进行计算。以下是一个简单的Python代码示例,用于计算二分类任务的精确度:
def accuracy(true_positive, false_positive):
# 计算精确度
precision = true_positive / (true_positive + false_positive)
return precision
# 示例使用
true_positive = 80 # 真正例的数量
false_positive = 20 # 假正例的数量
precision = accuracy(true_positive, false_positive)
print(f'Precision: {precision}')
在上面的代码中,true_positive 表示真正例的数量,false_positive 表示假正例的数量。通过调用 accuracy 函数,可以计算并输出精确度的值。请注意,这里的计算是基于精确度的定义:真正例的数量除以真正例和假正例的总和。
在实际应用中,可能会使用机器学习库(如Scikit-learn)提供的函数来计算精确度。例如,Scikit-learn 中的 precision_score 函数可以用于计算精确度。以下是一个示例:
from sklearn.metrics import precision_score
# 真实标签
true_labels = [1, 1, 0, 1, 0, 0, 1, 0, 1, 1]
# 模型预测的标签
predicted_labels = [1, 1, 0, 0, 0, 1, 1, 1, 1, 1]
# 使用precision_score计算精确度
precision = precision_score(true_labels, predicted_labels)
print(f'Precision: {precision}')
这里的 true_labels 是实际的标签,predicted_labels 是模型的预测标签。通过调用 precision_score 函数,可以得到相应的精确度值。
七.总结:
总体而言,精确度作为一个基础而直观的评价指标,在机器学习任务中发挥着关键作用。然而,在使用时需要谨慎考虑其局限性,并结合其他评价指标以获取更全面的模型评估。未来的研究将进一步推动评价指标的发展,以适应不断变化的应用需求。通过更深入的理解和创新,我们将能够更准确地评估和优化机器学习模型的性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











